使用elasticsearch定时删除索引数据
1、有的时候我们在使用ES
由于资源有限或业务需求,我们只想保存最近一段时间的数据,所以有必要做定时删除数据。
2、编写脚本
vim del_es_by_day.sh #!/bin/bash #定时删除elasticsearch索引 #author menard 2019-3-25 date=`date -d "-7 days" "+%Y.%m.%d"` /usr/bin/curl -v --user elastic:password -XDELETE "http://192.168.10.201:9200/*-$date"
增加可执行权限 chmod +x del_es_by_day.sh
3、创建用于测试的索引
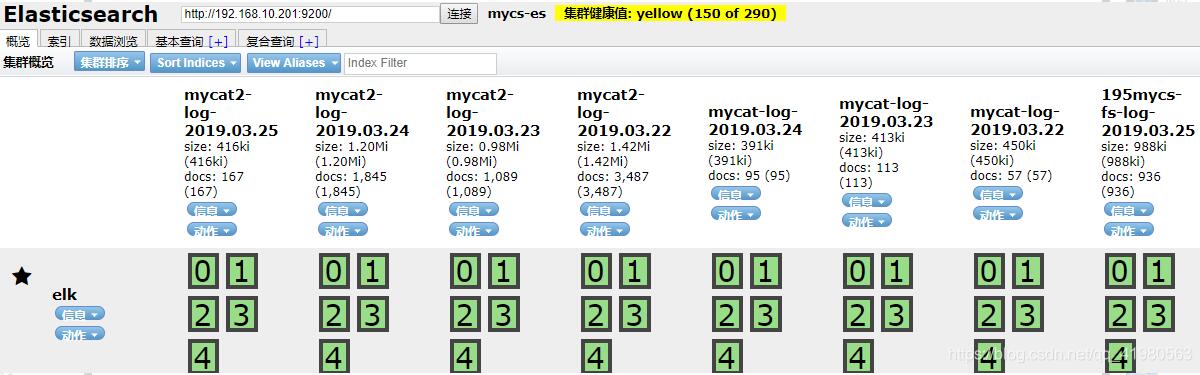
put test-2019.03.18 put index-2019.03.18


4、执行脚本测试结果,可以看到删除成功

5、做定时任务
crontab -e 00 01 * * * /workspace/script/del_es_by_day.sh
补充:Elasticsearch定时备份索引数据与恢复
定时备份脚本
Linux定时任务功能使用cron服务来进行
编写定时任务的cron表达式
crontab -e #进入cron定时任务编辑
定时任务
*/1 * * * * /opt/scheduler/es_bk.sh >> /opt/scheduler/bk_log.txt 2>&1
每隔1分钟定时执行 /opt/scheduler/目录下的es_bk.sh脚本,将数据内容写入到 /opt/scheduler目录下的bk.log.txt文件中
查看一下es_bk.sh脚本内容
#! /bin/bash echo '=================================start======================================' #删除备份的快照 curl -i -X DELETE localhost:9200/_snapshot/es_backup/snapshot01 #再次备份 curl -i -X PUT localhost:9200/_snapshot/es_backup/snapshot01 echo '==================================end======================================='
ES备份数据需要将要备份的索引数据快照一份,需要指定一个快照名,且不能使用相同的快照,所以在每次备份之前需要删除旧的快照,再备份。
ES备份与恢复
创建一个备份仓库(目录)
mkdir -p /bk/es/data #修改权限 chmod -R 777 bk
修改elasticsearch.yml文件,指定仓库位置

发送初始化仓库请求
curl -i -H ""'Content-Type:application/json;charset=UTF-8'"" -X PUT --data '{"type": "fs","settings": {"location": "/bk/es/data"}}' localhost:9200/_snapshot/es_backup
es_backup是备份命名空间,可以随意指定
创建第一份快照
curl -i -X PUT localhost:9200/_snapshot/es_backup/snapshot01
将使用es_backup这个备份将es的所有索引数据备份到snapshot01这个快照下,当然也可以只备份指定索引
curl -i -H ""'Content-Type:application/json;charset=UTF-8'"" -X PUT --data '{"indices": "'bk_user_index_server'"}' localhost:9200/_snapshot/es_backup/snapshot01
重启定时任务
systemctl restart cron
恢复索引
恢复指定
curl -i -H ""'Content-Type:application/json;charset=UTF-8'"" -X POST --data '{"indices": "'bk_user_index_server'"}' localhost:9200/_snapshot/es_backup/snapshot01/_restore
恢复所有
curl -i -X POST localhost:9200/_snapshot/es_backup/snapshot01/_restore
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
ElasticSearch添加索引代码实例解析
1. 编写索引内容 节点解释: settings:配置信息 "number_of_replicas": 0 不需要备份(单节点的ElasticSearch使用) "mappings": 映射内容 "dynamic":false 是否动态索引,这里使用的是false,表示索引的固定的,不需要修改. "properties": 属性结构内容 "index":"true" 需要分词处理的结构
-

Django利用elasticsearch(搜索引擎)实现搜索功能
1.在Django配置搜索结果页的路由映射 """pachong URL Configuration The `urlpatterns` list routes URLs to views. For more information please see: https://docs.djangoproject.com/en/1.10/topics/http/urls/ Examples: Function views 1. Add an import: from my_ap
-
分布式全文检索引擎ElasticSearch原理及使用实例
一 什么是 ElasticSearch Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎.当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作: 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索. 可实现亿级数据实时查询 实时分析的分布式搜索引擎. 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据. 二 安装(wind
-
Django项目之Elasticsearch搜索引擎的实例
1.使用Docker安装Elasticsearch及其扩展 获取镜像,可以通过网络pull sudo docker image pull delron/elasticsearch-ik:2.4.6-1.0 或者加载镜像文件 sudo docker load -i elasticsearch-ik-2.4.6_docker.tar 修改elasticsearch的配置文件 elasticsearc-2.4.6/config/elasticsearch.yml第54行,更改ip地址为本机ip地址 n
-
python elasticsearch从创建索引到写入数据的全过程
python elasticsearch从创建索引到写入数据 创建索引 from elasticsearch import Elasticsearch es = Elasticsearch('192.168.1.1:9200') mappings = { "mappings": { "type_doc_test": { #type_doc_test为doc_type "properties": { "id": { "
-
ElasticSearch合理分配索引分片原理
Elasticsearch 是一个非常通用的平台,支持各种用户实例,并为组织数据和复制策略提供了极大的灵活性.但是,这种灵活性有时会使我们很难在早期确定如何很好地将数据组织成索引和分片,尤其是不熟悉 Elastic Stack.虽然不一定会在首次启动时引起问题,但随着数据量的增长,它们可能会导致性能问题.群集拥有的数据越多,纠正问题也越困难,因为有时可能需要重新索引大量数据. 因此,当我们遇到性能问题时,往往可以追溯到索引方式以及集群中分片的数量.那么就会遇到问题,我们应该有多少分片以及我的分片
-
使用elasticsearch定时删除索引数据
1.有的时候我们在使用ES 由于资源有限或业务需求,我们只想保存最近一段时间的数据,所以有必要做定时删除数据. 2.编写脚本 vim del_es_by_day.sh #!/bin/bash #定时删除elasticsearch索引 #author menard 2019-3-25 date=`date -d "-7 days" "+%Y.%m.%d"` /usr/bin/curl -v --user elastic:password -XDELETE "
-
pandas删除部分数据后重新生成索引的实现
目录 pandas删除部分数据后重新索引 原数据 删除部分数据后 附件:网上查到的格式化用的编码 pandas常用的index索引设置 1.读取时指定索引列 2. 使用现有的 DataFrame 设置索引 3. 一些操作后重置索引 4. 将索引从 groupby 操作转换为列 5.排序后重置索引 6.删除重复后重置索引 7. 索引的直接赋值 8.写入CSV文件时忽略索引 pandas删除部分数据后重新索引 在使用pandas时,由于隔行读取删除了部分数据,导致删除数据后的索引不连续: 原数据 删
-
Elasticsearch的删除映射类型操作示例
目录 一 前言 二 什么是映射类型? 三 为什么要删除映射类型? 四 映射类型的替代方法 4.1 将映射类型分开存储在索引中 4.2 自定义类型字段回到顶部 五 没有映射类型的父/子 六 删除映射类型的计划 七将多类型索引迁移到单一类型 7.1 每种文档类型的索引 7.2 自定义类型字段 八 总结 一 前言 官方解释:https://www.elastic.co/guide/en/elasticsearch/reference/6.0/removal-of-types.html 在elastic
-
Elasticsearch文档索引基本操作增删改查示例
接口幂等性 接口幂等性:数学概念,多次请求,相当于一次请求 get,put,delete都是幂等性的接口 post 存在幂等性的问题 前端速度很快,点了两次,会生成两个订单 用户在访问新增页面时(提交订单)--->接口返回一个唯一id,提交订单,携带唯一id过来,后端判断这个唯一id是否被用过--->没用过,创建订单 你在项目中碰到的问题和如何解决(项目收获)下订单,经常重复订单,点得快,幂等性问题,如何解决的 倒排索引 1.es介绍10个点 2.安装 -jdk :java开发环境 官网下载e
-
MongoDB性能篇之创建索引,组合索引,唯一索引,删除索引和explain执行计划
一.索引 MongoDB 提供了多样性的索引支持,索引信息被保存在system.indexes 中,且默认总是为_id创建索引,它的索引使用基本和MySQL 等关系型数据库一样.其实可以这样说说,索引是凌驾于数据存储系统之上的另一层系统,所以各种结构迥异的存储都有相同或相似的索引实现及使用接口并不足为 奇. 1.基础索引 在字段age 上创建索引,1(升序);-1(降序): db.users.ensureIndex({age:1}) _id 是创建表的时候自动创建的索引,此索引是不能够删除的.当
-
MySQL查看、创建和删除索引的方法
本文实例讲述了MySQL查看.创建和删除索引的方法.分享给大家供大家参考.具体如下: 1.索引作用 在索引列上,除了上面提到的有序查找之外,数据库利用各种各样的快速定位技术,能够大大提高查询效率.特别是当数据量非常大,查询涉及多个表时,使用索引往往能使查询速度加快成千上万倍. 例如,有3个未索引的表t1.t2.t3,分别只包含列c1.c2.c3,每个表分别含有1000行数据组成,指为1-1000的数值,查找对应值相等行的查询如下所示. SELECT c1,c2,c3 FROM t1,t2,t3
-
Windows和Linux下定时删除某天前的文件的脚本
以前做到最多的定时我们就是定时备份功能了,我们常用利用定时功能来备份网站数据或备份数据库了,下面我来给(www.jb51.net)大家介绍几个Linux与Windows中定时删除某天前的文件方法,这个与备份有点区别,但大同小义了. Windows下bat文件内容如下: 复制代码 代码如下: @echo off forfiles -p "D:\servers\apache2.2\logs" -s -m *.log -d -15 -c "cmd /c del @path"
-
sql删除重复数据的详细方法
一. 删除完全重复的记录 完全重复的数据,通常是由于没有设置主键/唯一键约束导致的.测试数据: 复制代码 代码如下: if OBJECT_ID('duplicate_all') is not nulldrop table duplicate_all GO create table duplicate_all ( c1 int, c2 int, c3 varchar(100) ) GO insert into duplicate_all select 1,100,'aaa' union allse