用Python代码自动生成文献的IEEE引用格式的实现
今天尝试着将引用文献的格式按照IEEE的标准重新排版,感觉手动一条一条改太麻烦,而且很容易出错,所以尝试着用Python写了一个小程序用于根据BibTeX引用格式来生成IEEE引用格式。
先看代码,如下:
import re
def getIeeeJournalFormat(bibInfo):
"""
生成期刊文献的IEEE引用格式:{作者}, "{文章标题}," {期刊名称}, vol. {卷数}, no. {编号}, pp. {页码}, {年份}.
:return: {author}, "{title}," {journal}, vol. {volume}, no. {number}, pp. {pages}, {year}.
"""
# 避免字典出现null值
if "volume" not in bibInfo:
bibInfo["volume"] = "null"
if "number" not in bibInfo:
bibInfo["number"] = "null"
if "pages" not in bibInfo:
bibInfo["pages"] = "null"
journalFormat = bibInfo["author"] + \
", \"" + bibInfo["title"] + \
",\" " + bibInfo["journal"] + \
", vol. " + bibInfo["volume"] + \
", no. " + bibInfo["number"] + \
", pp. " + bibInfo["pages"] + \
", " + bibInfo["year"] + "."
# 对格式进行调整,去掉没有的信息,调整页码格式
journalFormatNormal = journalFormat.replace(", vol. null", "")
journalFormatNormal = journalFormatNormal.replace(", no. null", "")
journalFormatNormal = journalFormatNormal.replace(", pp. null", "")
journalFormatNormal = journalFormatNormal.replace("--", "-")
return journalFormatNormal
def getIeeeConferenceFormat(bibInfo):
"""
生成会议文献的IEEE引用格式:{作者}, "{文章标题}, " in {会议名称}, {年份}, pp. {页码}.
:return: {author}, "{title}, " in {booktitle}, {year}, pp. {pages}.
"""
conferenceFormat = bibInfo["author"] + \
", \"" + bibInfo["title"] + ",\" " + \
", in " + bibInfo["booktitle"] + \
", " + bibInfo["year"] + \
", pp. " + bibInfo["pages"] + "."
# 对格式进行调整,,调整页码格式
conferenceFormatNormal = conferenceFormat.replace("--", "-")
return conferenceFormatNormal
def getIeeeFormat(bibInfo):
"""
本函数用于根据文献类型调用相应函数来输出ieee文献引用格式
:param bibInfo: 提取出的BibTeX引用信息
:return: ieee引用格式
"""
if "journal" in bibInfo: # 期刊论文
return getIeeeJournalFormat(bibInfo)
elif "booktitle" in bibInfo: # 会议论文
return getIeeeConferenceFormat(bibInfo)
def inforDir(bibtex):
#pattern = "[\w]+={[^{}]+}" 用正则表达式匹配符合 ...={...} 的字符串
pattern1 = "[\w]+=" # 用正则表达式匹配符合 ...= 的字符串
pattern2 = "{[^{}]+}" # 用正则表达式匹配符合 内层{...} 的字符串
# 找到所有的...=,并去除=号
result1 = re.findall(pattern1, bibtex)
for index in range(len(result1)) :
result1[index] = re.sub('=', '', result1[index])
# 找到所有的{...},并去除{和}号
result2 = re.findall(pattern2, bibtex)
for index in range(len(result2)) :
result2[index] = re.sub('\{', '', result2[index])
result2[index] = re.sub('\}', '', result2[index])
# 创建BibTeX引用字典,归档所有有效信息
infordir = {}
for index in range(len(result1)):
infordir[result1[index]] = result2[index]
return infordir
def inputBibTex():
"""
在这里输入BibTeX格式的文献引用信息
:return:提取出的BibTeX引用信息
"""
bibtex = []
print("请输入BibTeX格式的文献引用:")
i = 0
while i < 15: # 观察可知BibTeX格式的文献引用不会多于15行
lines = input()
if len(lines) == 0: # 如果输入空行,则说明引用内容已经输入完毕
break
else:
bibtex.append(lines)
i += 1
return inforDir("".join(bibtex))
if __name__ == '__main__':
bibInfo = inputBibTex() # 获得BibTeX格式的文献引用
print(getIeeeFormat(bibInfo)) # 输出ieee格式
下面我来详细说说这个代码怎么使用。
首先,我们需要获取到文献的BibTeX引用格式,可以在百度学术,或者谷歌学术的应用栏中找到,例如这里以谷歌学术举例:
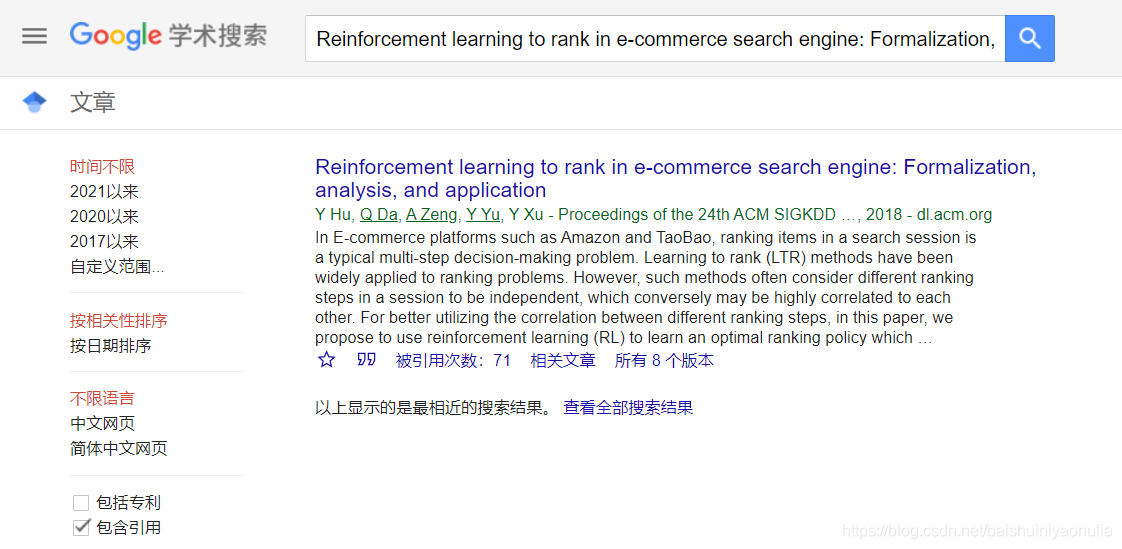
在搜索框搜索论文:Reinforcement learning to rank in e-commerce search engine: Formalization, analysis, and application,跳转到以下页面:
点击“引用”,再点击“BibTex”
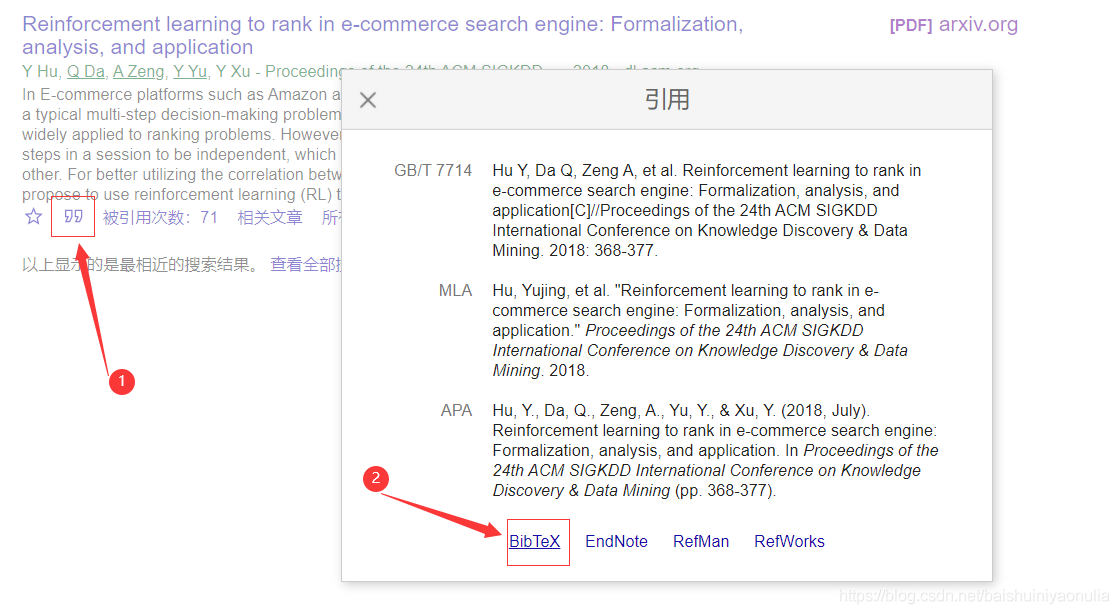
跳转到以下页面,复制所有字符串

运行我们上面给出的代码,在交互窗口把我们复制的字符串粘贴过去:
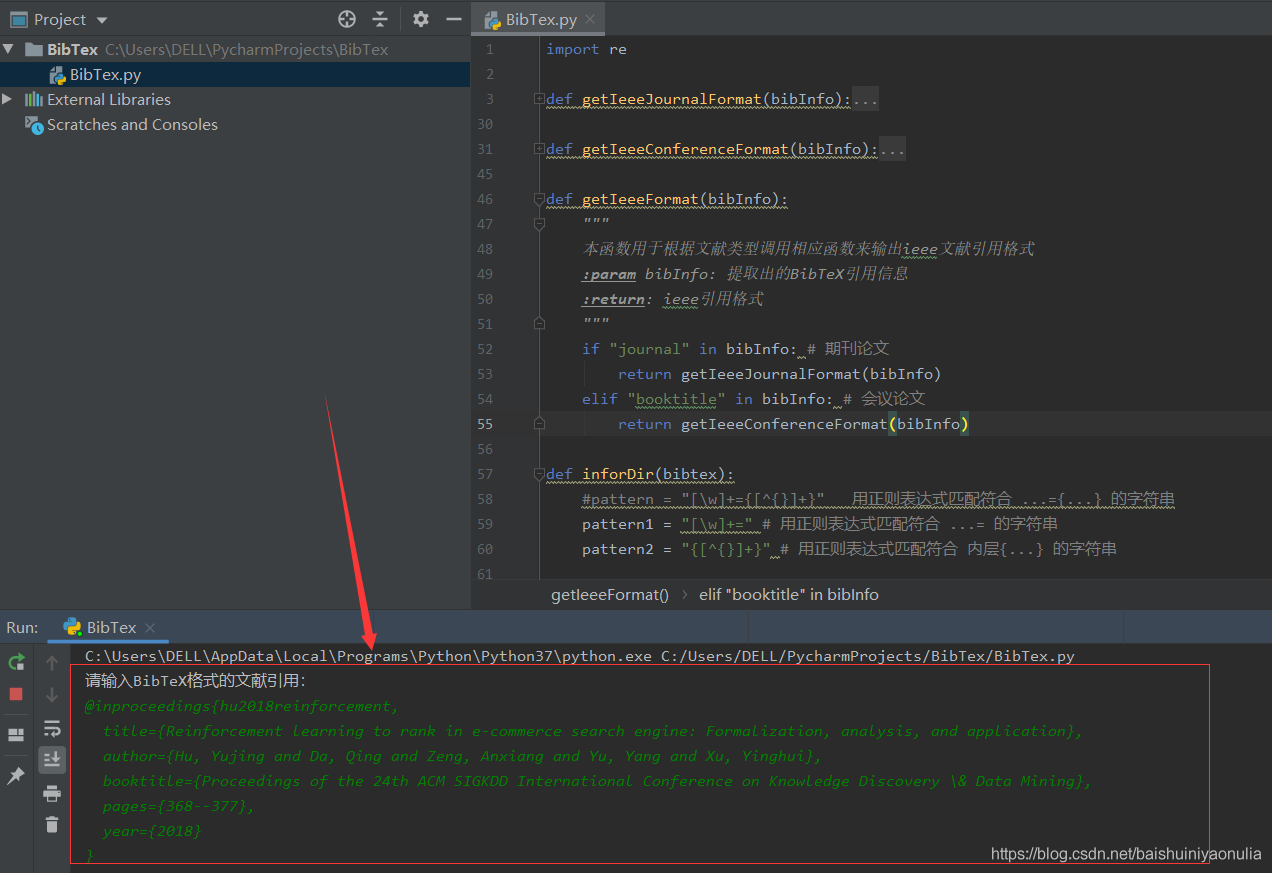
之后点击两下回车,即可得到IEEE格式的文献引用了:
这里我分了会议论文和期刊论文种格式,大家如果想要其他引用格式,可以在我的代码的基础上进行增删改,下面我放一些引用格式转换的例子:
会议论文1:
Reinforcement learning to rank in e-commerce search engine: Formalization, analysis, and application
BibTeX格式:
@inproceedings{hu2018reinforcement,
title={Reinforcement learning to rank in e-commerce search engine: Formalization, analysis, and application},
author={Hu, Yujing and Da, Qing and Zeng, Anxiang and Yu, Yang and Xu, Yinghui},
booktitle={Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining},
pages={368–377},
year={2018}
}
IEEE格式:
Hu, Yujing and Da, Qing and Zeng, Anxiang and Yu, Yang and Xu, Yinghui, “Reinforcement learning to rank in e-commerce search engine: Formalization, analysis, and application,” , in Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2018, pp. 368-377.
会议论文2:
A contextual-bandit approach to personalized news article recommendation
BibTeX格式:
@inproceedings{li2010contextual,
title={A contextual-bandit approach to personalized news article recommendation},
author={Li, Lihong and Chu, Wei and Langford, John and Schapire, Robert E},
booktitle={Proceedings of the 19th international conference on World wide web},
pages={661–670},
year={2010}
}
IEEE格式:
Li, Lihong and Chu, Wei and Langford, John and Schapire, Robert E, “A contextual-bandit approach to personalized news article recommendation,” , in Proceedings of the 19th international conference on World wide web, 2010, pp. 661-670.
期刊论文1:
Infrared navigation-Part I: An assessment of feasibility
BibTeX格式:
@article{duncombe1959infrared,
title={Infrared navigation—Part I: An assessment of feasibility},
author={Duncombe, JU},
journal={IEEE Trans. Electron Devices},
volume={11},
number={1},
pages={34–39},
year={1959}
}
IEEE格式:
Duncombe, JU, “Infrared navigation—Part I: An assessment of feasibility,” IEEE Trans. Electron Devices, vol. 11, no. 1, pp. 34-39, 1959.
期刊论文2(arXiv):
Reinforcement learning for slate-based recommender systems: A tractable decomposition and practical methodology
BibTeX格式:
@article{ie2019reinforcement,
title={Reinforcement learning for slate-based recommender systems: A tractable decomposition and practical methodology},
author={Ie, Eugene and Jain, Vihan and Wang, Jing and Narvekar, Sanmit and Agarwal, Ritesh and Wu, Rui and Cheng, Heng-Tze and Lustman, Morgane and Gatto, Vince and Covington, Paul and others},
journal={arXiv preprint arXiv:1905.12767},
year={2019}
}
IEEE格式:
Ie, Eugene and Jain, Vihan and Wang, Jing and Narvekar, Sanmit and Agarwal, Ritesh and Wu, Rui and Cheng, Heng-Tze and Lustman, Morgane and Gatto, Vince and Covington, Paul and others, “Reinforcement learning for slate-based recommender systems: A tractable decomposition and practical methodology,” arXiv preprint arXiv:1905.12767, 2019.
到此这篇关于用Python代码自动生成文献的IEEE引用格式的实现的文章就介绍到这了,更多相关Python自动生成IEEE格式内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python自动生成证件号的方法示例
前言 在跟进需求的时候,往往涉及到测试,特别是需要用到身份信息的时候,总绕不开身份证号码这个话题.之前在跟一个互联网产品的时候,需要很多身份证做测试,又不想装太多软件自动生成(有需要的小伙伴可自行搜索身份证号码自动生成软件),按照身份证规则现编也比较浪费时间,在处理身份数据时,Python就非常有用了. 方法示例如下 # Author:BeeLe # -*-coding:utf-8-*- # 生成身份证号码主程序 import urllib.request import requests fro
-
利用python自动生成docker nginx反向代理配置
利用python自动生成docker nginx反向代理配置 由于在测试环境上用docker部署了多个应用,而且他们的端口有的相同,有的又不相同,数量也比较多,在使用jenkins发版本的时候,不好配置,于是想要写一个脚本,能在docker 容器创建.停止的时候,自动生成nginx反向代理,然后reload nginx 我的原则是尽量简单,轻量,内存占用少 目标很明确,只要能监听到docker的容器启动/停止事件,即可 网上查了一下可以用docker events来监听docker事件,试了一下
-

基于Python的身份证号码自动生成程序
需求细化: 1.身份证必须能够通过身份证校验程序. 2.通过查询,发现身份证号码是有国家标准的,标准号为 GB 11643-1999 可以从百度下载到这个文档 下载:GB11643-1999sfz(jb51.net).rar 现行身份证号为18位,分别为6位地址码,8位生日,3位顺序码,一位校验码.具体例子可见下图. 前六位也是国家标准,GB2260-2007.吐槽一下,国标竟然没有一个网站供全面检索和免费下载...还好国家统计局有这些公开数据.可以从统计数据->统计标准->行政区划代码页面内
-
Python利用sqlacodegen自动生成ORM实体类示例
本文实例讲述了Python利用sqlacodegen自动生成ORM实体类.分享给大家供大家参考,具体如下: 在前面一篇<Python流行ORM框架sqlalchemy安装与使用>我们是手动创建了一个名叫Infos.py的文件,然后定义了一个News类,把这个类作为和我们news数据表的映射. from sqlalchemy.ext.declarative import declarative_base Base = declarative_base() from sqlalchemy impo
-
使用Python自动生成HTML的方法示例
python 自动化批量生成前端的HTML可以大大减轻工作量 下面演示两种生成 HTML 的方法 方法一:使用 webbrowser #coding:utf-8 import webbrowser #命名生成的html GEN_HTML = "test.html" #打开文件,准备写入 f = open(GEN_HTML,'w') #准备相关变量 str1 = 'my name is :' str2 = '--MichaelAn--' # 写入HTML界面中 message = &qu
-
Python使用win32com模块实现数据库表结构自动生成word表格的方法
本文实例讲述了Python使用win32com模块实现数据库表结构自动生成word表格的方法.分享给大家供大家参考,具体如下: 下载win32模块 下载链接:https://sourceforge.net/projects/pywin32/files/pywin32/ 连接mysql import MySQLdb db_host = "" db_port = 3306 db_name = "" db_user = "" db_pwd = &quo
-
Python自动生成代码 使用tkinter图形化操作并生成代码框架
背景 在写代码过程中,如果有频繁重复性的编码操作,或者可以Reuse的各类代码,可以通过Python写一个脚本,自动生成这类代码,就不用每次手写.或者copy了. 比如新建固定的代码框架.添加一些既定的软件逻辑,通讯协议.消息模板等等,再编写一套代码时,或者一个Function时,每次使通过脚本一键生成代码,就不需要每次都写一遍了,同时可以把相关软件逻辑放进去,也能避免出错. 脚本代码 Demo_CodeGenerator.py 具体详细代码去掉了,大家想生成什么样的代码就在mycode中app
-
Python3自动生成MySQL数据字典的markdown文本的实现
为啥要写这个脚本 五一前的准备下班的时候,看到同事为了做数据库的某个表的数据字典,在做一个复杂的人工操作,就是一个字段一个字段的纯手撸,那速度可想而知是多么的折磨和锻炼人的意志和耐心,反正就是很耗时又费力的活,关键是工作效率太低了,于是就网上查了一下,能否有在线工具可用,但是并没有找到理想和如意的,于是吧,就干脆自己撸一个,一劳永逸,说干就干的那种-- 先屡一下脚本思路 第一步:输入或修改数据库连接配置信息,以及输入数据表名 第二步:利用pymysql模块连接数据库,并判断数据表是否存在 第三步
-
python自动生成model文件过程详解
生成方式 Python中想要自动生成 model文件可以通过 sqlacodegen这个命令来生成对应的model文件 sqlacodegen 你可以通过pip去安装: pip install sqlacodegen 格式: sqlacodegen mysql+pymysql://username:password@host/database_name > model.py 说明: mysql+pymysql : 表示连接数据库的连接方式 username : 连接MySQL数据库的用户名 pa
-
简单使用Python自动生成文章
为了应付某些情况,需要做17份记录.虽然不很重要,但是17份完全雷同也不很好.大体看了一下,此记录大致分为四段.于是决定每段提供四种选项,每段四选一,拼凑成四段文字,存成一个文件.文件名就叫"XX记录+日期".应急的随手创作,使用了"文件操作"和"生成随机数"的功能.比较简陋.后期扩展可以考虑搭配个数据库. 复制代码 代码如下: # -*- coding: cp936 -*- import random title='XXX周例会\n会议时间:
-
使用python脚本自动生成K8S-YAML的方法示例
1.生成 servie.yaml 1.1.yaml转json service模板yaml apiVersion: v1 kind: Service metadata: name: ${jarName} labels: name: ${jarName} version: v1 spec: ports: - port: ${port} targetPort: ${port} selector: name: ${jarName} 转成json的结构 { "apiVersion": "
-
详解python脚本自动生成需要文件实例代码
python脚本自动生成需要文件 在工作中我们经常需要通过一个文件写出另外一个文件,然而既然是对应关系肯定可以总结规律让计算机帮我们完成,今天我们就通过一个通用文件生成的python脚本来实现这个功能,将大家从每日重复的劳动中解放! 定义一个函数 def produceBnf(infilename,outfilename): List=[] with open(infilename,'r') as inf: for line in inf.readlines(): List.append(re.