Python爬虫之教你利用Scrapy爬取图片
Scrapy下载图片项目介绍
Scrapy是一个适用爬取网站数据、提取结构性数据的应用程序框架,它可以通过定制化的修改来满足不同的爬虫需求。
使用Scrapy下载图片
项目创建
首先在终端创建项目
# win4000为项目名 $ scrapy startproject win4000
该命令将创建下述项目目录。
项目预览
查看项目目录
- win4000
- win4000
- spiders
- __init__.py
- __init__.py
- items.py
- middlewares.py
- pipelines.py
- settings.py
- scrapy.cfg
创建爬虫文件
进入spiders文件夹,根据模板文件创建爬虫文件
$ cd win4000/win4000/spiders # pictures 为 爬虫名 $ scrapy genspider pictures "win4000.com"
项目组件介绍
1.引擎(Scrapy):核心组件,处理系统的数据流处理,触发事务。
2.调度器(Scheduler):用来接受引擎发出的请求, 压入队列中, 并在引擎再次请求的时候返回。由URL组成的优先队列, 由它来决定下一个要抓取的网址是什么,同时去除重复的网址。
3.下载器(Downloader):用于下载网页内容, 并将网页内容返回给Spiders。
4.爬虫(Spiders):用于从特定的网页中提取自己需要的信息, 并用于构建实体(Item),也可以从中提取出链接,让Scrapy继续抓取下一个页面
5.管道(Pipeline):负责处理Spiders从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被Spiders解析后,将被发送到项目管道。
6.下载器中间件(Downloader Middlewares):位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
7.爬虫中间件(Spider Middlewares):介于Scrapy引擎和爬虫之间的框架,主要工作是处理Spiders的响应输入和请求输出。
8.调度中间件(Scheduler Middewares):介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy爬虫流程介绍
Scrapy基本爬取流程可以描述为UR2IM(URL-Request-Response-Item-More URL):
1.引擎从调度器中取出一个链接(URL)用于接下来的抓取;
2.引擎把URL封装成一个请求(Request)传给下载器;
3.下载器把资源下载下来,并封装成应答包(Response);
4.爬虫解析Response;
5.解析出实体(Item),则交给实体管道进行进一步的处理;
6.解析出的是链接(URL),则把URL交给调度器等待抓取。
页面结构分析
首先查看目标页面,可以看到包含多个主题,选取感兴趣主题,本项目以“风景”为例(作为练习,也可以通过简单修改,来爬取所有模块内图片)。
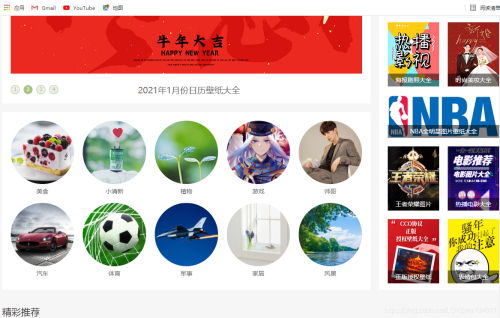
在“风景”分类页面,可以看到每页包含多个专题,利用开发者工具,可以查看每个专题的URL,拷贝相应XPath,利用Xpath的规律性,构建循环,用于爬取每个专题内容。
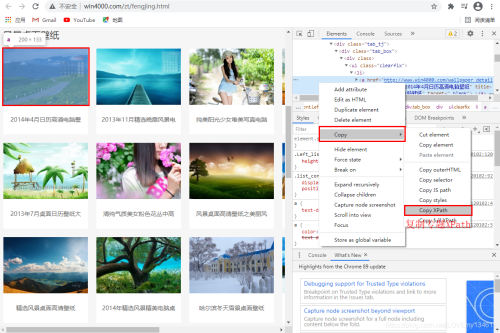
# 查看不同专题的XPath # /html/body/div[3]/div/div[3]/div[1]/div[1]/div[2]/div/div/ul/li[1]/a # /html/body/div[3]/div/div[3]/div[1]/div[1]/div[2]/div/div/ul/li[2]/a
利用上述结果,可以看到li[index]中index为专题序列。因此可以构建Xpath列表如下:
item_selector = response.xpath('/html/body/div[3]/div/div[3]/div[1]/div[1]/div[2]/div/div/ul/li/a/@href')
利用开发者工具,可以查看下一页的URL,拷贝相应XPath用于爬取下一页内容。
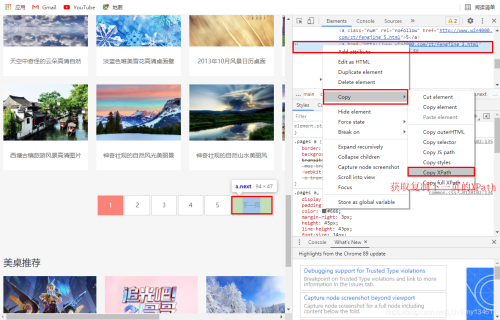
# 查看“下一页”的XPath # /html/body/div[3]/div/div[3]/div[1]/div[2]/div/a[5]
因此可以构建如下XPath:
next_selector = response.xpath('//a[@class="next"]')
点击进入专题,可以看到具体图片,通过查看图片XPath,用于获取图片地址。
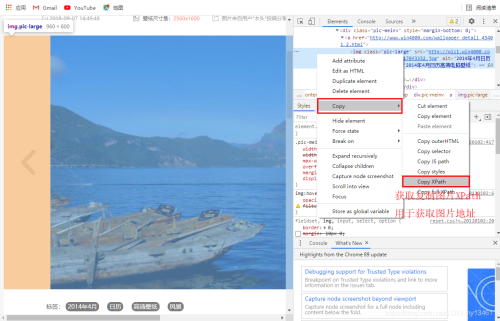
# 构建图片XPath
response.xpath('/html/body/div[3]/div/div[2]/div/div[2]/div[1]/div/a/img/@src').extract_first()
可以通过标题和图片序列构建图片名。
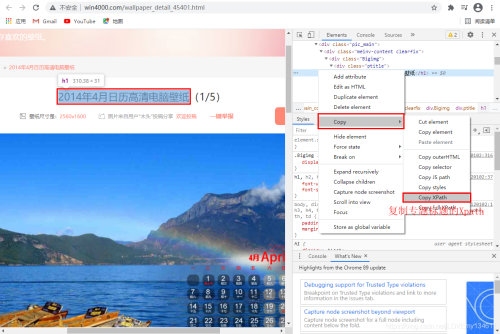

# 利用序号XPath构建图片在列表中的序号
index = response.xpath('/html/body/div[3]/div/div[2]/div/div[1]/div[1]/span/text()').extract_first()
# 利用标题XPath构建图片标题
title = response.xpath('/html/body/div[3]/div/div[2]/div/div[1]/div[1]/h1/text()').extract_first()
# 利用图片标题title和序号index构建图片名
name = title + '_' + index + '.jpg'
同时可以看到,在专题页面下,包含了多张图片,可以通过点击“下一张”按钮来获取下一页面URL,此处为了简化爬取过程,可以通过观察URL规律来构建每一图片详情页的URL,来下载图片。
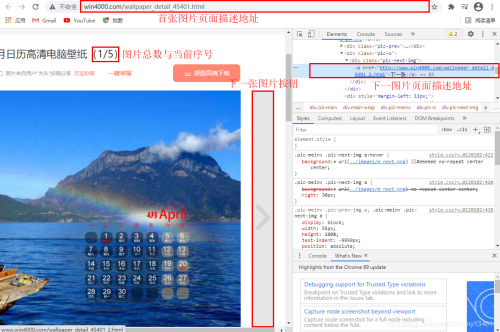
# 第一张图片详情页地址 # http://www.win4000.com/wallpaper_detail_45401.html # 第二张图片详情页地址 # http://www.win4000.com/wallpaper_detail_45401_2.html
因此可以通过首页地址和图片序号来构建每一张图片详情页地址。
# 第一张图片详情页地址
first_url = response.url
# 图片总数
num = response.xpath('/html/body/div[3]/div/div[2]/div/div[1]/div[1]/em/text()').extract_first()
num = int(num)
for i in range(2,num+1):
next_url = '.'.join(first_url.split('.')[:-1]) + '_' + str(i) + '.html'
定义Item字段(Items.py)
本项目用于下载图片,因此可以仅构建图片名和图片地址字段。
# win4000/win4000/items.py
import scrapy
class Win4000Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
url = scrapy.Field()
name = scrapy.Field()
编写爬虫文件(pictures.py)
代码详解见代码注释。
# win4000/win4000/spiders/pictures.py
import scrapy
from win4000.items import Win4000Item
from urllib import parse
import time
class PicturesSpider(scrapy.Spider):
name = 'pictures'
allowed_domains = ['win4000.com']
start_urls = ['http://www.win4000.com/zt/fengjing.html']
start_urls = ['http://www.win4000.com/zt/fengjing.html']
# cookie用于模仿浏览器行为
cookie={
"t":"29b7c2a8d2bbf060dc7b9ec00e75a0c5",
"r":"7957",
"UM_distinctid":"178c933b40e9-08430036bca215-7e22675c-1fa400-178c933b40fa00",
"CNZZDATA1279564249":"1468742421-1618282415-%7C1618282415",
"XSRF-TOKEN":"eyJpdiI6Ik8rbStsK1Fwem5zR2YzS29ESlI2dmc9PSIsInZhbHVlIjoiaDl5bXp5b1VvWmdSYklWWkEwMWJBK0FaZG9OaDA1VGQ2akZ0RDNISWNDM0hnOW11Q0JTVDZFNlY4cVwvSTBjQlltUG9tMnFUcWd5MzluUVZ0NDBLZlJuRWFuaVF0U3k0XC9CU1dIUzJybkorUEJ3Y2hRZTNcL0JqdjZnWjE5SXFiNm8iLCJtYWMiOiI2OTBjOTkzMTczYWQwNzRiZWY5MWMyY2JkNTQxYjlmZDE2OWUyYmNjNDNhNGYwNDAyYzRmYTk5M2JhNjg5ZmMwIn0%3D",
"win4000_session":"eyJpdiI6Inc2dFprdkdMTHZMSldlMXZ2a1cwWGc9PSIsInZhbHVlIjoiQkZHVlNYWWlET0NyWWlEb2tNS0hDSXAwZGVZV05vTmY0N0ZiaFdTa1VRZUVqWkRmNWJuNGJjNkFNa3pwMWtBcFRleCt4SUFhdDdoYnlPMGRTS0dOR0tkdmVtVDhzUWdTTTc3YXpDb0ZPMjVBVGJzM2NoZzlGa045Qnl0MzRTVUciLCJtYWMiOiI2M2VmMTEyMDkxNTIwNmJjZjViYTg4MjIwZGIxNTlmZWUyMTJlYWZhNjk5ZmM0NzgyMTA3MWE4MjljOWY3NTBiIn0%3D"
}
def start_requests(self):
"""
重构start_requests函数,用于发送带有cookie的请求,模仿浏览器行为
"""
yield scrapy.Request('http://www.win4000.com/zt/fengjing.html', callback=self.parse, cookies=self.cookie)
def parse(self,response):
# 获取下一页的选择器
next_selector = response.xpath('//a[@class="next"]')
for url in next_selector.xpath('@href').extract():
url = parse.urljoin(response.url,url)
# 暂停执行,防止网页的反爬虫程序
time.sleep(3)
# 用于爬取下一页
yield scrapy.Request(url, cookies=self.cookie)
# 用于获取每一专题的选择器
item_selector = response.xpath('/html/body/div[3]/div/div[3]/div[1]/div[1]/div[2]/div/div/ul/li/a/@href')
for item_url in item_selector.extract():
item_url = parse.urljoin(response.url,item_url)
#print(item_url)
time.sleep(3)
# 请求专题页面,并利用回调函数callback解析专题页面
yield scrapy.Request(item_url,callback=self.parse_item, cookies=self.cookie)
def parse_item(self,response):
"""
用于解析专题页面
"""
# 由于Scrapy默认并不会爬取重复页面,
# 因此需要首先构建首张图片实体,然后爬取剩余图片,
# 也可以通过使用参数来取消过滤重复页面的请求
# 首张图片实体
item = Win4000Item()
item['url'] = response.xpath('/html/body/div[3]/div/div[2]/div/div[2]/div[1]/div/a/img/@src').extract_first()
index = response.xpath('/html/body/div[3]/div/div[2]/div/div[1]/div[1]/span/text()').extract_first()
item['name'] = response.xpath('/html/body/div[3]/div/div[2]/div/div[1]/div[1]/h1/text()').extract_first() + '_' + index + '.jpg'
yield item
first_url = response.url
num = response.xpath('/html/body/div[3]/div/div[2]/div/div[1]/div[1]/em/text()').extract_first()
num = int(num)
for i in range(2,num+1):
next_url = '.'.join(first_url.split('.')[:-1]) + '_' + str(i) + '.html'
# 请求其余图片,并用回调函数self.parse_detail解析页面
yield scrapy.Request(next_url,callback=self.parse_detail,cookies=self.cookie)
def parse_detail(self,response):
"""
解析图片详情页面,构建实体
"""
item = Win4000Item()
item['url'] = response.xpath('/html/body/div[3]/div/div[2]/div/div[2]/div[1]/div/a/img/@src').extract_first()
index = response.xpath('/html/body/div[3]/div/div[2]/div/div[1]/div[1]/span/text()').extract_first()
item['name'] = response.xpath('/html/body/div[3]/div/div[2]/div/div[1]/div[1]/h1/text()').extract_first() + '_' + index + '.jpg'
yield item
修改配置文件settings.py
修改win4000/win4000/settings.py中的以下项。
BOT_NAME = 'win4000'
SPIDER_MODULES = ['win4000.spiders']
NEWSPIDER_MODULE = 'win4000.spiders'
# 图片保存文件夹
IMAGES_STORE = './result'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# 用于模仿浏览器行为
USER_AGENT = 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:87.0) Gecko/20100101 Firefox/87.0'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
# 下载时延
DOWNLOAD_DELAY = 3
# Disable cookies (enabled by default)
# 是否启用Cookie
COOKIES_ENABLED = True
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'win4000.pipelines.Win4000Pipeline': 300,
}
修改管道文件pipelines.py用于下载图片
修改win4000/win4000/pipelines.py文件。
from itemadapter import ItemAdapter
from scrapy.pipelines.images import ImagesPipeline
import scrapy
import os
from scrapy.exceptions import DropItem
class Win4000Pipeline(ImagesPipeline):
def get_media_requests(self, item, info):
# 下载图片,如果传过来的是集合需要循环下载
# meta里面的数据是从spider获取,然后通过meta传递给下面方法:file_path
yield scrapy.Request(url=item['url'],meta={'name':item['name']})
def item_completed(self, results, item, info):
# 是一个元组,第一个元素是布尔值表示是否成功
if not results[0][0]:
with open('img_error_name.txt','a') as f_name:
error_name = str(item['name'])
f_name.write(error_name)
f_name.write('\n')
with open('img_error_url.txt','a') as f_url:
error_url = str(item['url'])
f_url.write(error_url)
f_url.write('\n')
raise DropItem('下载失败')
return item
# 重命名,若不重写这函数,图片名为哈希,就是一串乱七八糟的名字
def file_path(self, request, response=None, info=None):
# 接收上面meta传递过来的图片名称
filename = request.meta['name']
return filename
编写爬虫启动文件begin.py
在win4000目录下创建begin.py
# win4000/begin.py
from scrapy import cmdline
cmdline.execute('scrapy crawl pictures'.split())
最终目录树
- win4000
- begin.py
- win4000
- spiders
- __init__.py
- pictures.py
- __init__.py
- items.py
- middlewares.py
- pipelines.py
- settings.py
- scrapy.cfg
项目运行
进入begin.py所在目录,运行程序,启动scrapy进行爬虫。
$ python3 begin.py
爬取结果
后记
本项目仅用于测试用途。
Enjoy coding.
到此这篇关于Python爬虫之教你利用Scrapy爬取图片的文章就介绍到这了,更多相关python中用Scrapy爬取图片内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬取科目四考试题库的方法实现
1.环境 PyCharm Python 3.6 pip安装的依赖包包括:requests 2.25.0.urllib3 1.26.2.docx 0.2.4.python-docx 0.8.10.lxml 4.6.2 谷歌浏览器 2.目标网站及请求分析 驾驶员考试网站 从上图中,可以看到科目四共有1487道题目,为了将所有的题目汇总到一个Word文档中,需要获取到每道题的文本和图片. 首先,打开谷歌浏览器访问上述网站,键盘按F12,点击Network,点击左侧题目中的向右箭头,一直
-
用python爬虫爬取CSDN博主信息
一.项目介绍 爬取网址:CSDN首页的Python.Java.前端.架构以及数据库栏目.简单分析其各自的URL不难发现,都是https://www.csdn.net/nav/+栏目名样式,这样我们就可以爬取不同栏目了. 以Python目录页为例,如下图所示: 爬取内容:每篇文章的博主信息,如博主姓名.码龄.原创数.访问量.粉丝数.获赞数.评论数.收藏数 (考虑到周排名.总排名.积分都是根据上述信息综合得到的,对后续分析没实质性的作用,这里暂不爬取.) 不想看代码的朋友可直接跳到第三部分~ 二.S
-
python基于scrapy爬取京东笔记本电脑数据并进行简单处理和分析
一.环境准备 python3.8.3 pycharm 项目所需第三方包 pip install scrapy fake-useragent requests selenium virtualenv -i https://pypi.douban.com/simple 1.1 创建虚拟环境 切换到指定目录创建 virtualenv .venv 创建完记得激活虚拟环境 1.2 创建项目 scrapy startproject 项目名称 1.3 使用pycharm打开项目,将创建的虚拟环境配置到项目中来
-
Python爬虫之爬取2020女团选秀数据
一.先看结果 1.1创造营2020撑腰榜前三甲 创造营2020撑腰榜前三名分别是 希林娜依·高.陈卓璇 .郑乃馨 >>>df1[df1['排名']<=3 ][['排名','姓名','身高','体重','生日','出生地']] 排名 姓名 身高 体重 生日 出生地 0 1.0 希林娜依·高 NaN NaN 1998年07月31日 新疆 1 2.0 陈卓璇 168.0 42.0 1997年08月13日 贵州 2 3.0 郑乃馨 NaN NaN 1997年06月25日 泰国 1.2青春有
-
利用Python网络爬虫爬取各大音乐评论的代码
python爬虫--爬取网易云音乐评论 方1:使用selenium模块,简单粗暴.但是虽然方便但是缺点也是很明显,运行慢等等等. 方2:常规思路:直接去请求服务器 1.简易看出评论是动态加载的,一定是ajax方式. 2.通过网络抓包,可以找出评论请求的的URL 得到请求的URL 3.去查看post请求所上传的数据 显然是经过加密的,现在就需要按着网易的思路去解读加密过程,然后进行模拟加密. 4.首先去查看请求是经过那些js到达服务器的 5.设置断点:依次对所发送的内容进行观察,找到评论对应的UR
-
Python爬虫爬取全球疫情数据并存储到mysql数据库的步骤
思路:使用Python爬虫对腾讯疫情网站世界疫情数据进行爬取,封装成一个函数返回一个 字典数据格式的对象,写另一个方法调用该函数接收返回值,和数据库取得连接后把 数据存储到mysql数据库. 一.mysql数据库建表 CREATE TABLE world( id INT(11) NOT NULL AUTO_INCREMENT, dt DATETIME NOT NULL COMMENT '日期', c_name VARCHAR(35) DEFAULT NULL COMMENT '国家'
-
python 爬取壁纸网站的示例
本次爬虫用到的网址是: http://www.netbian.com/index.htm: 彼岸桌面.里面有很多的好看壁纸,而且都是可以下载高清无损的,还比较不错,所以我就拿这个网站练练手. 作为一个初学者,刚开始的时候,无论的代码的质量如何,总之代码只要能够被正确完整的运行那就很能够让自己开心的,如同我们的游戏一样,能在短时间内得到正向的反馈,我们就会更有兴趣去玩. 学习也是如此,只要我们能够在短期内得到学习带来的反馈,那么我们的对于学习的欲望也是强烈的. 作为一个菜鸡,能够完整的完整此次爬虫
-
Python爬虫之爬取某文库文档数据
一.基本开发环境 Python 3.6 Pycharm 二.相关模块的使用 import os import requests import time import re import json from docx import Document from docx.shared import Cm 安装Python并添加到环境变量,pip安装需要的相关模块即可. 三.目标网页分析 网站的文档内容,都是以图片形式存在的.它有自己的数据接口 接口链接: https://openapi.book11
-
详解用python实现爬取CSDN热门评论URL并存入redis
一.配置webdriver 下载谷歌浏览器驱动,并配置好 import time import random from PIL import Image from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import exp
-
python爬虫之教你如何爬取地理数据
一.shapely模块 1.shapely shapely是python中开源的针对空间几何进行处理的模块,支持点.线.面等基本几何对象类型以及相关空间操作. 2.point→Point类 curve→LineString和LinearRing类: surface→Polygon类 集合方法分别对应MultiPoint.MultiLineString.MultiPolygon 3.导入所需模块 # 导入所需模块 from shapely import geometry as geo from s
-
python爬取晋江文学城小说评论(情绪分析)
1. 收集数据 1.1 爬取晋江文学城收藏排行榜前50页的小说信息 获取收藏榜前50页的小说列表,第一页网址为 'http://www.jjwxc.net/bookbase.php?fw0=0&fbsj=0&ycx0=0&xx2=2&mainview0=0&sd0=0&lx0=0&fg0=0&sortType=0&isfinish=0&collectiontypes=ors&searchkeywords=&pa
-
python爬取各省降水量及可视化详解
在具体数据的选取上,我爬取的是各省份降水量实时数据 话不多说,开始实操 正文 1.爬取数据 使用python爬虫,爬取中国天气网各省份24时整点气象数据 由于降水量为动态数据,以js形式进行存储,故采用selenium方法经xpath爬取数据-ps:在进行数据爬取时,最初使用的方法是漂亮汤法(beautifulsoup)法,但当输出爬取的内容(<class = split>时,却空空如也.在源代码界面Ctrl+Shift+F搜索后也无法找到降水量,后查询得知此为动态数据,无法用该方法进行爬取