如何基于Python爬虫爬取美团酒店信息
一、分析网页
网站的页面是 JavaScript 渲染而成的,我们所看到的内容都是网页加载后又执行了JavaScript代码之后才呈现出来的,因此这些数据并不存在于原始 HTML 代码中,而 requests 仅仅抓取的是原始 HTML 代码。抓取这种类型网站的页面数据,解决方案如下:
分析 Ajax,很多数据可能是经过 Ajax 请求时候获取的,所以可以分析其接口。

在XHR里可以找到,Request URL有几个关键参数,uuid和cityId是城市标识,offset偏移量可以控制翻页,分析网页发现,第x页的offset为:(x-1)*20,limit表示每页有20条信息,startDay和endDay为当前的日期。
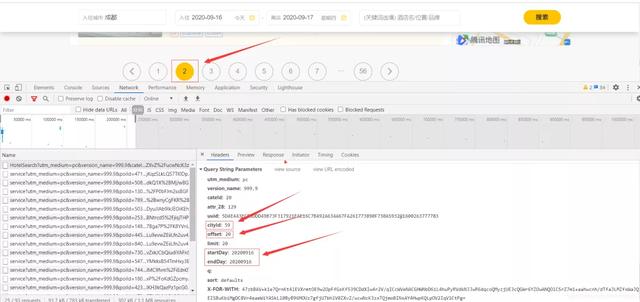
在Preview里可以找到每页的20条信息

模拟JavaScript渲染过程,直接抓取渲染后的结果。
selenium和pyppeteer爬虫就是用的这种方法
二、爬取酒店信息
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
url = "https://ihotel.meituan.com/hbsearch/HotelSearch"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.162 Safari/537.36",
"Referer": "https://hotel.meituan.com/chengdu"
}
wb = openpyxl.Workbook()
sheet = wb.active
sheet.append(['酒店名称', '酒店地址', '酒店类型', '最低价', '评价', '评论数', '经度', '纬度'])
def hotel_data(x):
data = {
'utm_medium': 'pc',
'version_name': 999.9,
'cateId': 20,
'attr_28': 129,
'uuid': '5D4E443EC83DDD49B73F317921EAE16C7B492A634A67FA261773890F730A5932@1600263777783',
'cityId': 59,
'offset': x * 20,
'limit': 20,
'startDay': 20200916,
'endDay': 20200916,
'q': '', 'sort': 'defaults',
'X-FOR-WITH': '47zbBAV+k1e7QrnKt4lEVXrmtOE9w2OpFfGsKf539CDdXIw4r2V/qICcWVeNACGHWNbD6iL4huPyRVdkNJJwR6dqcoQMyzjUE3cQGWr6YZOwANQOlCSrZ7m1+aahwcnh/dTfaJLMZfxWaJQEISBuKbiMgDC8Vr4eaeWiYASkLl0ByB96MOUz7gfjUTbhlV0ZXvZ/ucwNcK3zxTQjmoBINsAY4HwpKQLpOV2IqV1CtPg=',
}
res = requests.get(url, headers=headers, params=data)
time.sleep(random.randint(1, 3))
results = json.loads(res.text)['data']['searchresult']
for con in results:
name = con['name'] # 酒店名称
addr = con['addr'] # 酒店地址
star = con['hotelStar'] # 酒店类型
price = con['lowestPrice'] # 最低价
scoreIntro = con['scoreIntro'] # 评价
comments = con['commentsCountDesc'] # 评论数
lng, lat = con['lng'], con['lat'] # 经纬度
data = [name, addr, star, price, scoreIntro, comments, lng, lat]
sheet.append(data)
logging.info(data)
程序运行成功,酒店信息保存到了Excel。

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python基于requests库爬取网站信息
requests库是一个简介且简单的处理HTTP请求的第三方库 get()是获取网页最常用的方式,其基本使用方式如下 使用requests库获取HTML页面并将其转换成字符串后,需要进一步解析HTML页面格式,这里我们常用的就是beautifulsoup4库,用于解析和处理HTML和XML 下面这段代码便是爬取百度的信息并简单输出百度的界面信息 import requests from bs4 import BeautifulSoup r=requests.get('http://www.bai
-
Python基于BeautifulSoup爬取京东商品信息
今天小编利用美丽的汤来为大家演示一下如何实现京东商品信息的精准匹配~~ HTML文件其实就是由一组尖括号构成的标签组织起来的,每一对尖括号形式一个标签,标签之间存在上下关系,形成标签树:因此可以说Beautiful Soup库是解析.遍历.维护"标签树"的功能库. 如何利用BeautifulSoup抓取京东网商品信息 首先进入京东网,输入自己想要查询的商品,向服务器发送网页请求.在这里小编仍以关键词"狗粮"作为搜索对象,之后得到后面这一串网址: https://se
-
Python爬虫实例——爬取美团美食数据
1.分析美团美食网页的url参数构成 1)搜索要点 美团美食,地址:北京,搜索关键词:火锅 2)爬取的url https://bj.meituan.com/s/%E7%81%AB%E9%94%85/ 3)说明 url会有自动编码中文功能.所以火锅二字指的就是这一串我们不认识的代码%E7%81%AB%E9%94%85. 通过关键词城市的url构造,解析当前url中的bj=北京,/s/后面跟搜索关键词. 这样我们就可以了解到当前url的构造. 2.分析页面数据来源(F12开发者工具) 开启F12开发
-
Python爬取12306车次信息代码详解
详情查看下面的代码: 如果被识别就要添加一个cookie如果没有被识别的话就要一个user-agent就好了.如果出现乱码就设置编码格式为utf-8 #静态的数据一般在elements中(复制文字到sources按ctrl+f搜索.找到的为静态),而动态去network中去寻找相关的信息 import requests import re def send_request(): headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win6
-
Python爬取股票信息,并可视化数据的示例
前言 截止2019年年底我国股票投资者数量为15975.24万户, 如此多的股民热衷于炒股,首先抛开炒股技术不说, 那么多股票数据是不是非常难找, 找到之后是不是看着密密麻麻的数据是不是头都大了? 今天带大家爬取雪球平台的股票数据, 并且实现数据可视化 先看下效果图 基本环境配置 python 3.6 pycharm requests csv time 目标地址 https://xueqiu.com/hq 爬虫代码 请求网页 import requests url = 'https://xueq
-
基于Python爬虫采集天气网实时信息
相信小伙伴们都知道今冬以来范围最广.持续时间最长.影响最重的一场低温雨雪冰冻天气过程正在进行中.预计,今天安徽.江苏.浙江.湖北.湖南等地有暴雪,局地大暴雪,新增积雪深度4-8厘米,局地可达10-20厘米.此外,贵州中东部.湖南中北部.湖北东南部.江西西北部有冻雨.言归正传,天气无时无刻都在陪伴着我们,今天小编带大家利用Python网络爬虫来实现天气情况的实时采集. 此次的目标网站是绿色呼吸网.绿色呼吸网站免费提供中国环境监测总站发布的PM2.5实时数据查询,更收集分析关于PM2.5有关的一切报
-
Python通过正则库爬取淘宝商品信息代码实例
使用正则库爬取淘宝商品的商品信息,首先我们需要确定想要爬取的对象 我们在淘宝里搜索"python",出来的结果 从url连接中可以得到搜索商品的关键字是"q=",所以我们要用的起始url为:https://s.taobao.com/search?q=python 然后翻页,经过对比发现,翻页后,变化的关键字是s,每次翻页,s便以44的倍数增长(可以数一下每页显示的商品数量,刚好是44) 所以可以根据关键字"s=",来设置爬取的深度(爬取多少页)
-
Python爬虫实例——scrapy框架爬取拉勾网招聘信息
本文实例为爬取拉勾网上的python相关的职位信息, 这些信息在职位详情页上, 如职位名, 薪资, 公司名等等. 分析思路 分析查询结果页 在拉勾网搜索框中搜索'python'关键字, 在浏览器地址栏可以看到搜索结果页的url为: 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=', 尝试将?后的参数删除, 发现访问结果相同. 打开Chrome网页调试工具(F12), 分析每条搜索结果
-
如何基于Python爬虫爬取美团酒店信息
一.分析网页 网站的页面是 JavaScript 渲染而成的,我们所看到的内容都是网页加载后又执行了JavaScript代码之后才呈现出来的,因此这些数据并不存在于原始 HTML 代码中,而 requests 仅仅抓取的是原始 HTML 代码.抓取这种类型网站的页面数据,解决方案如下: 分析 Ajax,很多数据可能是经过 Ajax 请求时候获取的,所以可以分析其接口. 在XHR里可以找到,Request URL有几个关键参数,uuid和cityId是城市标识,offset偏移量可以控制翻页,分析
-
记一次python 爬虫爬取深圳租房信息的过程及遇到的问题
为了分析深圳市所有长租.短租公寓的信息,爬取了某租房公寓网站上深圳区域所有在租公寓信息,以下记录了爬取过程以及爬取过程中遇到的问题: 爬取代码: import requests from requests.exceptions import RequestException from pyquery import PyQuery as pq from bs4 import BeautifulSoup import pymongo from config import * from multipr
-

Python爬虫爬取新浪微博内容示例【基于代理IP】
本文实例讲述了Python爬虫爬取新浪微博内容.分享给大家供大家参考,具体如下: 用Python编写爬虫,爬取微博大V的微博内容,本文以女神的微博为例(爬新浪m站:https://m.weibo.cn/u/1259110474) 一般做爬虫爬取网站,首选的都是m站,其次是wap站,最后考虑PC站.当然,这不是绝对的,有的时候PC站的信息最全,而你又恰好需要全部的信息,那么PC站是你的首选.一般m站都以m开头后接域名, 所以本文开搞的网址就是 m.weibo.cn. 前期准备 1.代理IP 网上有
-
Python爬虫爬取全球疫情数据并存储到mysql数据库的步骤
思路:使用Python爬虫对腾讯疫情网站世界疫情数据进行爬取,封装成一个函数返回一个 字典数据格式的对象,写另一个方法调用该函数接收返回值,和数据库取得连接后把 数据存储到mysql数据库. 一.mysql数据库建表 CREATE TABLE world( id INT(11) NOT NULL AUTO_INCREMENT, dt DATETIME NOT NULL COMMENT '日期', c_name VARCHAR(35) DEFAULT NULL COMMENT '国家'
-
Python爬虫爬取一个网页上的图片地址实例代码
本文实例主要是实现爬取一个网页上的图片地址,具体如下. 读取一个网页的源代码: import urllib.request def getHtml(url): html=urllib.request.urlopen(url).read() return html print(getHtml(http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%E5%A3%81%E7%BA%B8&ct=201326592&am
-
python爬虫爬取某站上海租房图片
对于一个net开发这爬虫真真的以前没有写过.这段时间开始学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup.python 版本:python3.6 ,IDE :pycharm.其实就几行代码,但希望没有开发基础的人也能一下子看明白,所以大神请绕行. 第三方库首先安装 我是用的pycharm所以另为的脚本安装我这就不介绍了. 如上图打开默认设置选择Project Interprecter,双击pip或者点击加
-
python爬虫爬取淘宝商品信息
本文实例为大家分享了python爬取淘宝商品的具体代码,供大家参考,具体内容如下 import requests as req import re def getHTMLText(url): try: r = req.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def parasePage(ilt, html): tr
-
python爬虫爬取淘宝商品信息(selenum+phontomjs)
本文实例为大家分享了python爬虫爬取淘宝商品的具体代码,供大家参考,具体内容如下 1.需求目标 : 进去淘宝页面,搜索耐克关键词,抓取 商品的标题,链接,价格,城市,旺旺号,付款人数,进去第二层,抓取商品的销售量,款号等. 2.结果展示 3.源代码 # encoding: utf-8 import sys reload(sys) sys.setdefaultencoding('utf-8') import time import pandas as pd time1=time.time()
-
python爬虫爬取快手视频多线程下载功能
环境: python 2.7 + win10 工具:fiddler postman 安卓模拟器 首先,打开fiddler,fiddler作为http/https 抓包神器,这里就不多介绍. 配置允许https 配置允许远程连接 也就是打开http代理 电脑ip: 192.168.1.110 然后 确保手机和电脑是在一个局域网下,可以通信.由于我这边没有安卓手机,就用了安卓模拟器代替,效果一样的. 打开手机浏览器,输入192.168.1.110:8888 也就是设置的代理地址,安装证书之后才能
-
python爬虫爬取网页表格数据
用python爬取网页表格数据,供大家参考,具体内容如下 from bs4 import BeautifulSoup import requests import csv import bs4 #检查url地址 def check_link(url): try: r = requests.get(url) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print('无法链接服务器!!!')