R语言中cut()函数的用法说明
R语言cut()函数使用
cut()切割将x的范围划分为时间间隔,并根据其所处的时间间隔对x中的值进行编码。
参数:breaks:两个或更多个唯一切割点或单个数字(大于或等于2)的数字向量,给出x被切割的间隔的个数。
breaks采用fivenum():返回五个数据:最小值、下四分位数、中位数、上四分位数、最大值。
labels为区间数,打标签
ordered_result 逻辑结果应该是一个有序的因素吗?
先用fivenum求出5个数,再用labels为每两个数之间,贴标签,采用(]的区间, 再将各个数,对应区间,求出即可
>j1<-c(23,62,72,80,59,82,90,43,94)
break1<-fivenum(j1)
> break1
[1] 23 59 72 82 94
> labels = c("差", "中", "良", "优")
> j2<-cut(j1,break1,labels,ordered_result = T)
> j2
[1] <NA> 中 中 良 差 良 优 差 优
Levels: 差 < 中 < 良 < 优
补充:R语言中使用CUT函数将数据进行分段重编码
在很多SCI论文中,都会把连续变量进行分段比较,如年龄分为青年、中年、老年,或者把某一指标连续高,中,低分为几等分再进行性分析,如下图所示,把连续的孕周通过认为的分为早孕、中孕和晚孕

在R语言中,实现这种方法,我们需要把连续变量进行分段(也叫分箱)然后进行重编码对数据进行分析,这一步很重要,这是为后面的分析做准备。今天我们通过使用R语言自带的CUT函数来演示对数据的分段重编码及数据整理。
我们今天使用SPSS软件自带的Breast cancer surviva的数据资料为演示,先打开Rstudiu把数据导入,并且删除缺失值
library(foreign)#导入foreign包 bc <- read.spss(“E:/r/Breast cancer survival agec.sav”, use.value.labels=F, to.data.frame=T) bc <- na.omit(bc)
查看一下该数据
head(bc)

第二个指标是年龄,我们打算把年龄平局分为高中低三个区间
age1<-cut(bc$age,breaks = 3,labels = c(1,2,3))#平均分为3个区间,命名为1,2,3
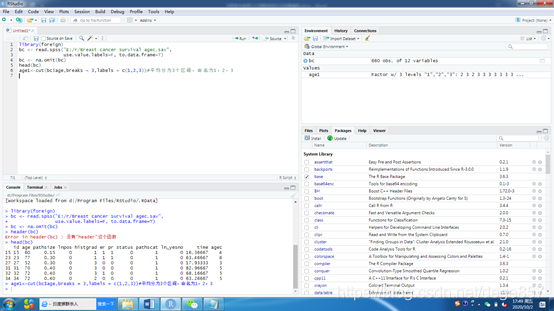
dc<-cbind(bc,age1)#把变量加入表格

这样就把年龄进行了分组重编码。我们还可以对具体年龄段进行分组
age2<-cut(bc$age,breaks=c(0,20,60,100),include.lowest=T, labels = c(1,2,3))#把age划分为0-20,20-60,60到100这样3个区间 dd<-cbind(bc,age2)#把变量加入表格

也可以按百分位比把年龄进行分段
age3<-quantile(bc$age,c(0,.25,.50,.75,1)) dc<-cbind(bc,age3)#把变量加入表格

以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
R语言:数据筛选match的使用详解
数据筛选是在分析中最常用的步骤,如微生物组分析中,你的OTU表.实验设计.物种注释之间都要不断筛选,来进行数据对齐,或局部分析. 今天来详解一下此函数的用法. match match:匹配两个向量,返回x中存在的返回索引或TRUE.FALSE match函数使用格式有如下两种: 第一种方便设置参数,返回x中元素在table中的位置 match(x, table, nomatch = NA_integer_, incomparables = NULL) 第二种简洁,返回x中每个元素在table中是
-
R语言中c()函数与paste()函数的区别说明
c()函数:将括号中的元素连接起来,并不创建向量 paste()函数:连接括号中的元素 例如 c(1, 2:4),结果为1 2 3 4 paste(1, 2:4),结果为"1 2" "1 3" "1 4" c(2, "and"),结果为"2" "and" paste(2, "and"),结果为"2 and" 补充:R语言中paste函数的参数sep
-

R语言中assign函数和get函数的用法
assign函数在循环时候,给变量赋值,算是比较方便 1.给变量赋值 for (i in 1:(length(rowSeq)-1)){ assign(paste("nginx_server_fields7_", i, sep = ""), nginx_server_fields7[(rowSeq[(i-1)+1]):(rowSeq[i+1]), ]) } 2.通过for循环给变量a1.a2.a3赋值 for (i in 1:3){ assign(paste(&quo
-
R语言中的fivenum与quantile()函数算法详解
fivenum()函数: 返回五个数据:最小值.下四分位数数.中位数.上四分位数.最大值 对于奇数个数字=5,fivenum()先排序,依次返回最小值.下四分位数.中位数.上四分位数.最大值 > fivenum(c(1,12,40,23,13)) [1] 1 12 13 23 40 对于奇数个数字>5,fivenum()先排序,我们可以求取最小值,最大值,中位数.在排序中,最小值与中位数中间,若为奇数,取其中位数为下四分位数,若为偶数,取最中间两个数的平均值为下四分位数:在排序中,中位数与最大
-
R语言中if(){}else{}语句和ifelse()函数的区别详解
首先看看定义: # if statement if(cond) expr if(cond) cons.expr else alt.expr # ifelse function ifelse(test, yes, no) 这两个函数(R语言中都是函数)相同的地方都是根据条件返回对应的值. 区别在于: if语句的条件是个TRUE/FALSE值,如果是个长度>1的逻辑向量,只判断第一个TRUE/FALSE值:而ifelse是长度任意的逻辑向量,返回根据逻辑向量对应对的yes/no值组合的新向量 ife
-
R语言-summary()函数的用法解读
summary():获取描述性统计量,可以提供最小值.最大值.四分位数和数值型变量的均值,以及因子向量和逻辑型向量的频数统计等. 结果解读如下: 1. 调用:Call lm(formula = DstValue ~ Month + RecentVal1 + RecentVal4 + RecentVal6 + RecentVal8 + RecentVal12, data = trainData) 当创建模型时,以上代码表明lm是如何被调用的. 2. 残差统计量:Residuals Min 1Q M
-
R语言-生成频数表和列联表crosstable函数介绍
列联表crosstable 列联表不仅可以用来做简单的描述性统计,还可以在机器学习中用来比较识别正确率,FPR,TPR等等数据,以便我们比较不同的ML模型 or 调参. 2x2列联表一般长下面这样: Total Observations in Table: 143 | test_cancer$diagnosis lda.class | 0 | 1 | Row Total | -------------|-----------|-----------|-----------| 0 | 82 | 1
-
R语言中cut()函数的用法说明
R语言cut()函数使用 cut()切割将x的范围划分为时间间隔,并根据其所处的时间间隔对x中的值进行编码. 参数:breaks:两个或更多个唯一切割点或单个数字(大于或等于2)的数字向量,给出x被切割的间隔的个数. breaks采用fivenum():返回五个数据:最小值.下四分位数.中位数.上四分位数.最大值. labels为区间数,打标签 ordered_result 逻辑结果应该是一个有序的因素吗? 先用fivenum求出5个数,再用labels为每两个数之间,贴标签,采用(]的区间,
-
R语言中qplot()函数的用法说明
ggplot2()函数 ggplot2是一个强大的作图工具,它可以让你不受现有图形类型的限制,创造出任何有助于解决你所遇到问题的图形. qplot() qplot()属于ggplot2(),可以理解成是它的简化版本. qplot 即"快速作图"(quick plot),顾名思义,能快速对数据进行可视化分析.它的用法和R base包的plot函数很相似. qplot() 参数 qplot(x, y = NULL, ..., data, facets = NULL, margins = F
-
R语言中quantile()函数的用法说明
在R语言中取百分位比用quantile()函数,下面举几个简单的示例: 1.求某个百分位比 > data <- c(1,2,3,4,5,6,7,8,9,10) > quantile(data,0.5) 50% 5.5 > quantile(data,c(0.25,0.75)) 25% 75% 3.25 7.75 2.产生一个序列百分位比值 > quantile(data,seq(0.1,1,0.1)) 10% 20% 30% 40% 50% 60% 70% 80% 90% 1
-
C语言中memcpy 函数的用法详解
C语言中memcpy 函数的用法详解 memcpy(内存拷贝函数) c和c++使用的内存拷贝函数,memcpy函数的功能是从源src所指的内存地址的起始位置开始拷贝n个字节到目标dest所指的内存地址的起始位置中. void* memcpy(void* destination, const void* source, size_t num); void* dest 目标内存 const void* src 源内存 size_t num 字节个数 库中实现的memcpy函数 struct { ch
-
C语言中qsort函数的用法实例详解
C语言中qsort函数的用法实例详解 快速排序是一种用的最多的排序算法,在C语言的标准库中也有快速排序的函数,下面说一下详细用法. qsort函数包含在<stdlib.h>中 qsort函数声明如下: void qsort(void * base,size_t nmemb,size_t size ,int(*compar)(const void *,const void *)); 参数说明: base,要排序的数组 nmemb,数组中元素的数目 size,每个数组元素占用的内存空间,可使用si
-
R语言中merge函数详解
1.创建测试数据: name <- c('A','B','A','A','C','D') school <- c('s1','s2','s1','s1','s1','s3') class <- c(10, 5, 4, 11, 1, 8) English <- c(85, 50, 90 ,90, 12, 96) w <- data.frame(name, school, class, English) w name <- c('A','B','C','F') school
-
聊聊R语言中Legend 函数的参数用法
如下所示: legend(x, y = NULL, legend, fill = NULL, col = par("col"), border = "black", lty, lwd, pch, angle = 45, density = NULL, bty = "o", bg = par("bg"), box.lwd = par("lwd"), box.lty = par("lty")
-
R语言中igraph包的用法(邻接矩阵)
先导入igraph包: library(igraph) graph包最简单的用法就是graph方法,两句代码就完成绘制如下所示,1的loop表示为(1,1),1和2之间有3条edge,表示为(1,2,1,2,1,2) g <- graph(c(1,1,1,2,1,2,1,2,1,5,2,3,2,4,2,5,3,3,3,4,3,4,3,4,4,5),directed = FALSE) plot(g) 如果用顶点的邻接矩阵表示,仍以上图为例: 则对1,1有loop,与2有条edge,与5有一条edg