一篇文章教你掌握python数据类型的底层实现
目录
- 1. 列表
- 1.1 复制
- 1.2 列表的底层实现 - 浅拷贝
- 1.3 浅拷贝 - 示例
- 1. 新增元素
- 2. 修改元素
- 3. 列表型元素
- 4. 元组型元素
- 5. 字典型元素
- 6. 小结
- 1.4 列表的底层实现 - 深拷贝
- 2. 字典
- 2.1 快速查找
- 2.2 字典的底层实现
- 1. 字典的创建过程
- 2. 字典的访问过程
- 2.3 小结
- 3. 字符串
- 4. 是否可变
- 不可变类型:数字,字符串,元组
- 可变类型:列表,字典,集合
- 总结

1. 列表
1.1 复制
浅拷贝
list_1 = [1, [22, 33, 44], (5, 6, 7), {"name":"Alina"}]
list_3 = list_1 ## 错误!!只是换了别名
list_2 = list_1.copy() ## 浅拷贝
##或者 也可这样实现
## list_1[:]
## list(list_1)
对拷贝前后两个列表分别进行操作
list_2[1].append(55)
print("list_1: ", list_1)
print("list_2: ", list_2)
发现虽然浅拷贝了,但修改 list_2 的某些元素时,相应的 list_1 也有同样的变化

1.2 列表的底层实现 - 浅拷贝
通过 引用数组 实现列表元素的存储
列表中存储的并不是我们看到的元素的值,而是这些元素的地址
列表所谓的连续,是在内存中连续存储元素的地址,而元素的值是在内存中分散存储的
当访问到列表的某个元素时,是按照列表中存储的元素地址去找到元素的值
直接赋值,是完完全全的没改变原列表的任何内容,就是原来的列表多了一个别名。
浅拷贝,确实是把列表拷贝了一份,也就是把列表中存储的地址全部拷贝了一份给新列表,新列表拥有一份独立的地址信息。但这些地址指向的元素和原列表是同一份元素。总结,浅拷贝只是把地址重新拷贝了一份,他们指向的内容还是同一份内容。

1.3 浅拷贝 - 示例


1. 新增元素

新增元素时,list_1 列表中新存储了一个指向元素100的地址,list_2 列表中新增了一个指向元素 ‘n' 的地址,因此互不影响。

2. 修改元素
当我们对 list_1[0]重新赋值的时候,实际是把这里原来存储的指向元素1的地址,替换成了另一个地址——指向元素10的地址,下次我们去list_1[0] 找元素的时候,会直接找到元素10,而不会再和原来的元素1有任何联系。同样的,list_2[0] 存放的地址换成了元素20的地址。


3. 列表型元素

list_1[1] 和 list_2[1] 存放了同一个地址列表,这个地址列表指向的也是同一批列表元素,所以修改 list_1[1]和list_2[1]的时候,都是对这批列表元素进行修改,是同时更新的。

4. 元组型元素
元组是不可变的!!! 一旦改变了,就不再是这个元组了,而是一个新的元组。
所以要对元组执行操作,都是先产生一个新元组,再在新元组上执行相应操作。在这里就是先产生了一个新的地址元组(元组内存储了元素地址),再对新元组进行修改。

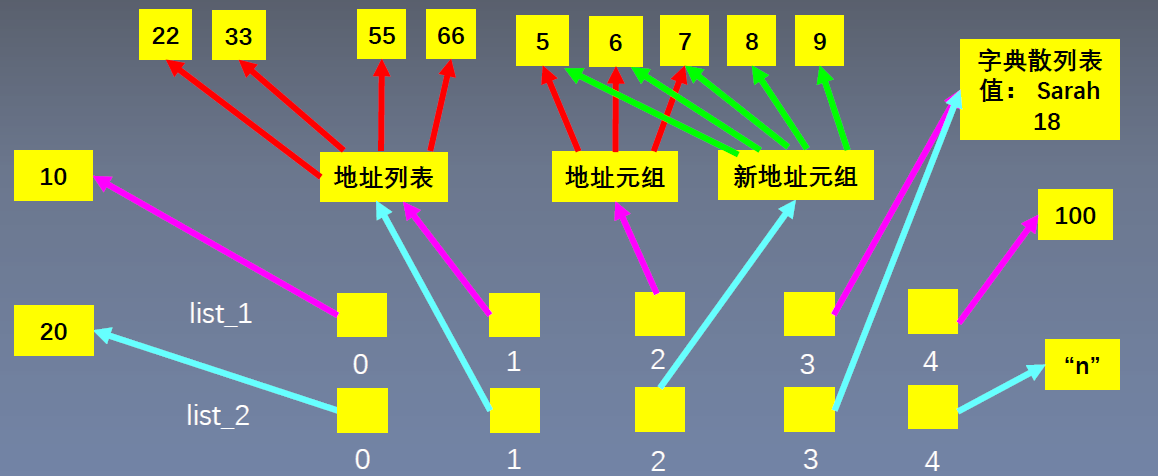
5. 字典型元素
对 list_1里的字典元素,增加一个键值对,发现 list_2 里的字典元素也增加了键值对。
和列表型元素类似,在对列表型元素操作时,地址列表本身是不变的,我们对于地址列表的内容进行操作。
在对字典型元素操作时,字典散列表本身也是不变的,我们对于字典散列表的内容进行操作,按照新增的键找到对应位置,把新增的值存进去,这个新增值的存放位置,是由字典的键决定的。

6. 小结
列表,字典类型的元素,都是可变的,可以在地址不变的情况下改变内容。
而元组,数字,字符串类型的元素,一旦内容发生变化,那么地址也必须变化。
浅拷贝之后,针对不可变元素(元组,数字,字符串)的操作都生效了
针对可变元素(列表,字典)的操作,则发生了一些混淆。
当列表中出现了可变类型的元素,我们想对列表进行一个安全的复制,使得能够独立操作而不影响原列表,那么就不能浅拷贝,而是需要深拷贝。
1.4 列表的底层实现 - 深拷贝
copy.deepcopy()
深拷贝将所有层级的相关元素全部完全的复制,避免了上述的混淆问题。


2. 字典
2.1 快速查找
慢 - 列表的查找
import time
ls_1 = list(range(1000000))
ls_2 = list(range(500)) + [-10]*500
start = time.time()
count = 0
for n in ls_2:
if n in ls_1:
count += 1
end = time.time()
print("查找{}个元素,在ls_1中有{}个,共用时{}秒".format(len(ls_2), count, round(end-start))))
# 查找1000个元素,在ls_1中有500个,共用时6.19秒
快 - 字典的查找
import time
d = {i:i for i in range(1000000)}
ls_2 = list(range(500)) + [-10]*500
start = time.time()
count = 0
for n in ls_2:
try:
d[n]
except:
pass
else:
count += 1
end = time.time()
print("查找{}个元素,在ls_1中有{}个,共用时{}秒".format(len(ls_2), count, round(end-start)))
# 查找1000个元素,在ls_1中有500个,共用时0秒
2.2 字典的底层实现
通过稀疏数组 实现值的存储与访问
1. 字典的创建过程
1.创建一个散列表(稀疏数组,N >>n,可以动态扩充)
2.通过hash()计算键的散列值
3.根据计算的散列值确定其在散列表中的位置(个别时候有哈希冲突,解决办法是开放寻址法 或 链接法 )
4.在该位置上存入值
d = {}
# d = dict()
print(hash("python"))
print(hash(1024))
print(hash(1.2))
# -477104656440599764...
# 1024
# 3713081631934410656...
d["age"] = 18 #增加键值对之前,首先计算键的散列值hash("age")
print(hash("age"))
#

2. 字典的访问过程
1.计算要访问的键的散列值
2.根据计算的散列值,按照一定的规则,确定其在散列表中的位置
3.读取该位置上存储的值(存在则返回该值,不存在则报错 KeyError)
d["age"] #访问键值对之前,首先计算键的散列值hash("age")
2.3 小结
字典数据类型,以空间换时间,内存占用大,空间利用率低,但查找速度快(稀疏数组 N >> n,否则会产生很多冲突,另外动态扩充也是)因为键在字典中显示的顺序,与实际计算出来的它在散列表中的存放位置,是两码事,因此字典表现为无序的
之前专门写过 —— Python字典及底层哈希
3. 字符串
通过紧凑数组 实现字符串的存储
字符串数据在内存中是连续存放的,空间利用率高
原因是:每个字符的大小是固定的,因此一个字符串的大小也是固定的,可以分配一个固定大小的空间给字符串。
同为序列类型,为什么列表采用引用数组,而字符串采用紧凑数据
虽然同为序列类型,但列表可以存储的元素类型是多种多样的,并且列表是可变的,无法预估内存空间,所以列表不能通过紧凑数组。

4. 是否可变
不可变类型:数字,字符串,元组
(元组并不总是不可变的,元组内存储的元素也必须同时是不可变类型,否则该元组属于可变)
在生命周期内保持内容不变,一旦内容变了,就不再是它了( id / 地址也变了)
不可变对象的 += 扩充操作,实际上是创建了一个新的对象。
x = 1
print("x id:", id(x))
# x id: 1407184...
x += 2
print("x id:", id(x))
# x id: 204099...
可变类型:列表,字典,集合
id (地址)不变的情况下,里面的内容可以改变
可变对象的 += 操作,实际是在原对象的基础上直接修改
ls = [1,2,3]
print("ls id:", id(ls))
# ls id: 2040991750856
ls += [4,5]
print("ls id:", id(ls))
# ls id: 2040991750856
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-
Python如何实现强制数据类型转换
这篇文章主要介绍了Python如何实现强制数据类型转换,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 常用转换函数 函数 作用 int(x) 将x转换成整数类型 float(x) 将 x 转换成浮点数类型 complex(real, [,imag]) 创建一个复数 str(x) 将 x 转换为字符串 repr(x) 将 x 转换为表达式字符串 eval(str) 计算在字符串中的有效 Python 表达式,并返回一个对象 chr(x) 将整数
-
Python xml、字典、json、类四种数据类型如何实现互相转换
之前都是直接拿sax,或dom等库去解析xml文件为Python的数据类型再去操作,比较繁琐,如今在写Django网站ajax操作时json的解析,发现这篇帖子对这几种数据类型的转换操作提供了另一种更简洁的方法,xmltodict和 dicttoxml等库功不可没,几种转换方式也都比较全面,转存一下以备不时之需,感谢原创整理! 注:xml.字典.json.类四种数据的转换,从左到右依次转换,即xml要转换为类时,先将xml转换为字典,再将字典转换为json, 最后将json转换为类. 1.解析x
-
Python基本数据类型之字符串str
字符串的表示方式 单引号 ' ' 双引号 " " 多引号 """ """" . ''' ''' print("hello world") print('hello world') print("""hello world""") # 输出结果 hello world hello world hello world 为什么需要单引号,又需
-

Python基础之数据类型相关知识总结
1.字符串 (1)概念 字符串英文名string,简称str. 字符串就是由一个个字符连接起来的组合, 你平时所见的字母.数字.汉字.符号都是字符. 字符串可以用来表示词.语句.甚至是数学公式.简单概括一下,所有单引号.双引号.三引号中的内容就是字符串,无论引号里面内容是中文.英文.法文.数字.符号.甚至是火星文. 代码演示1: name='小明' 代码演示2: print("hello") 在上面的代码中,小明和hello都属于字符串类型. (2)字符串拼接 字符串拼接的方法简单的很
-
Python3 使用map()批量的转换数据类型,如str转float的实现
我们知道map() 会根据提供的函数对指定序列做映射. 第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表. 先看一下map()在python2和3中的区别 在python2中: in: a = [1,2,3];b = [2,3,4] c = map(lambda x,y:s+y,a,b) c out: [3, 5, 7] 返回的是list 在python3中: in: a = [1,2,3];b = [2,3,
-
Python基础之数据类型详解
一.整数 python2中整形可以分为一般整形和长整形,但是在python3中,两者以及合二为一了,只有整形.python中的整形是具有无限精度的(只有内存能放下),可以表示任意位数的数字.例如: >>> 1111_2222_3333_4444_5555_6666_7777_8888_9999_0000 1111222233334444555566667777888899990000 python人性化的地方在于,上面的代码中,我每四位做了一个分割,让数字看起来很清晰.外国人可能更喜欢每
-
一篇文章教你掌握python数据类型的底层实现
目录 1. 列表 1.1 复制 1.2 列表的底层实现 - 浅拷贝 1.3 浅拷贝 - 示例 1. 新增元素 2. 修改元素 3. 列表型元素 4. 元组型元素 5. 字典型元素 6. 小结 1.4 列表的底层实现 - 深拷贝 2. 字典 2.1 快速查找 2.2 字典的底层实现 1. 字典的创建过程 2. 字典的访问过程 2.3 小结 3. 字符串 4. 是否可变 不可变类型:数字,字符串,元组 可变类型:列表,字典,集合 总结 1. 列表 1.1 复制 浅拷贝 list_1 = [1, [2
-
一篇文章教你用python画动态爱心表白
初级画心 学Python,感觉你们的都好复杂,那我来个简单的,我是直接把心形看作是一个正方形+两个半圆: 于是这就很简单了,十行代码解决: import turtle as t t.pensize(2) # 笔大小2像素 t.pencolor("red") # 颜色为红色 t.left(45) # 45度 t.fd(200) # 向前200直线 t.circle(100, 180) # 画一圆半径100 弧度180 t.right(90) # 向右90度 t.circle(100, 1
-
一篇文章教你用Python实现一键文件重命名
目录 应用背景 准备工作 上脚本 view.py 功能展示 打包方式 windows打包方式:pycharm打包为exe执行文件方法 总结 应用背景 背景:"由于工作需要可能需要对一些文件进行重命名的处理,但是可能操作起来比较烦,点错了就命名失败或者没带鼠标,用控制板操作起来比较麻烦等等场景" ps:以上都是200自我觉得比较烦,所以才出了这个小功能- 好了,此版本是基于上次文章的版本进行更新,(❕这次对上次的代码进行了更新,下文不会进行补充了哦,详细可以查看github上的源代码)详
-
一篇文章教你用Python实现一个学生管理系统
目录 片头 源码: 总结 片头 Python看了差不多三四天吧,基本上给基础看差不多了.写个管理系统吧,后续不出意外SQL.文件存储版本都会更. 学习Python感想: 人生苦短,我用Python 人生苦短,我用Python 人生苦短,我用Python 人生苦短,我用Python Python实在太爽了 源码: 使用Python3 ''' 学生成绩管理系统 时间:2021.9.9 作者:sunbeam ''' import time import os student_list = [] #定义
-
一篇文章教你用Python绘画一个太阳系
目录 日地月三体 日地火 太阳系 你们要的3D太阳系 图片上传之后不知为何帧率降低了许多... 日地月三体 所谓三体,就是三个物体在重力作用下的运动.由于三点共面,所以三个质点仅在重力作用下的运动轨迹也必然无法逃离平面. 三体运动所遵循的规律就是古老而经典的万有引力 则对于 m i 而言, 且 将其写为差分形式 由于我们希望观察三体运动的复杂形式,而不关系其随对应的宇宙星体,所以不必考虑单位制,将其在二维平面坐标系中拆分,则 #后续代码主要更改这里的参数 m = [1.33e20,3.98e14
-
一篇文章教你学会使用Python绘制甘特图
目录 优点 局限 一日一书 用来制作甘特图的专业工具也不少,常见的有:Microsoft Office Project.GanttProject.WARCHART XGantt.jQuery.Gantt.Excel等,网络上也有一些优质工具支持在线绘制甘特图. 可是这种现成的工具,往往也存在一些弊端,让编程人员不知所措.比如说,花里胡哨的UI,让人目不暇接,不知点哪个才好: 比如说,有些基于浏览器的图表需要掌握HTML.JS等编程语言,只会点Python的我直接被劝退: 再比如,进来就是注册.登
-
一篇文章彻底搞懂Python切片操作
目录 引言 一.Python可切片对象的索引方式 二.Python切片操作的一般方式 三.Python切片操作详细例子 1.切取单个值 2.切取完整对象 3.start_index和end_index全为正(+)索引的情况 4.start_index和end_index全为负(-)索引的情况 5.start_index和end_index正(+)负(-)混合索引的情况 6.连续切片操作 7.切片操作的三个参数可以用表达式 8.其他对象的切片操作 四.Python常用切片操作 1.取偶数位置 2.
-
一篇文章教你使用SpringBoot如何实现定时任务
前言 在 Spring + SpringMVC 环境中,一般来说,要实现定时任务,我们有两中方案,一种是使用 Spring 自带的定时任务处理器 @Scheduled 注解,另一种就是使用第三方框架 Quartz ,Spring Boot 源自 Spring+SpringMVC ,因此天然具备这两个 Spring 中的定时任务实现策略,当然也支持 Quartz,本文我们就来看下 Spring Boot 中两种定时任务的实现方式. 一.第一种方式:@Scheduled 使用 @Scheduled
-
一篇文章教你学会js实现弹幕效果
目录 新建一个html文件: 建好html文件,搞出初始模版 HTML添加 CSS填充 js逻辑代码 动画效果 下面是弹幕效果 : 相信小伙伴们都看过了,那么它实现的原理是什么呢,那么我们前端怎么用我们web技术去实现呢?? 新建一个html文件: 哈哈哈,大家别像我一样用中文命名. 中文命名是不合规范的,行走江湖,大佬们看见你的中文命名会笑话你的. 上图中,我们引入了jquery插件,没错我们用jq写,回归原始(找不到cdn链接的小伙伴可以百度bootcdn,在里面搜索jquery).并且取了
-
一篇文章彻底弄懂Python字符编码
目录 1. 字符编码简介 1.1. ASCII 1.2. MBCS 1.3. Unicode 2. Python2.x中的编码问题 2.1. str和unicode 2.2. 字符编码声明 2.3. 读写文件 2.4. 与编码相关的方法 3.建议 3.1.字符编码声明 3.2. 抛弃str,全部使用unicode. 3.3. 使用codecs.open()替代内置的open(). 3.4. 绝对需要避免使用的字符编码:MBCS/DBCS和UTF-16. 1. 字符编码简介 1.1. ASCII