Python深度学习albumentations数据增强库
数据增强的必要性
深度学习在最近十年得以风靡得益于计算机算力的提高以及数据资源获取的难度下降。一个好的深度模型往往需要大量具有label的数据,使得模型能够很好的学习这种数据的分布。而给数据打标签往往是一件耗时耗力的工作。
拿cv里的经典任务为例,classification需要人准确识别物品类别或者生物种类,object detection需要人工画出bounding box, 确定其坐标,semantic segmentation甚至需要在像素级别进行标签标注。对于一些专业领域的图像标注,依赖于专业人士的知识素养(例如医疗,遥感等),这无疑对有标签数据的收集带来了麻烦。
那么有没有什么方法能够在数据集规模很小的情况,尽可能提高模型的表现力呢?
1.transfer learning或者说是domain adaptation,这种方法期望降低源域与目标域之间的数据分布差异,使得具有大量标注数据的源域帮助提升模型的训练效果。
2.对现有数据进行数据增强深度学习能够学习到的空间不变性,像素级别的不变性特征都有限。所以对图片进行平移,缩放,旋转,改变色调值等方法,可以使得模型见过各种类型的数据,提高模型在测试数据上的判别力。
albumentations
上面我只是笼统的谈了下数据增强的必要性,对于其更加深刻的理解往往需要在实验中不断体会或者总结。
albumentations的安装
这步没什么好说,利用包管理工具直接安装。
pip install albumentations
albumentations的流水线工作方式
导入所需要的库
import albumentations as A from PIL import Image import numpy as np
读入数据这步需要其它库进行配合,可以利用CV2,PIL等,这里出于习惯我选择使用PIL
image_path = './your/image/path' image = np.array(Image.open(image_path)) # 获得了一个[H, W, C]的三维数组
创建流水线
transform = A.Compose([ A.Resize(width=256, height=256), A.HorizontalFlip(p=0.5), A.RandomBrightnessContrast(p=0.2) ])
A.Compose中需要传入一个list, list包含了一系列数据增强操作的对象。这里可以理解为A.Compose返回一条工业流水线, 第一步进行A.Resize操作,将图片缩放成256 * 256;第二步在上一步的基础上以0.5的概率对图片进行镜像翻转(p这个参数代表进行这个操作的概率);第三步同理,对第一步第二步处理完的图像以0.2的概率进行亮度和对比度的改变。
transform就是我们将要对图片进行的操作流程,下一步就需要将图片数据传入进去。
获得数据增强完的图片数据
transformed = transform(image=image) tranformed_image = transformed['image']
将图片数据传递给transform(很明显这是个可调用的对象)的image参数,它会返回一个处理完的对象,对象的key值image对应的value就是处理完的图像数据。
图像处理结果展示

object detection的数据增强
上述对albumentations流水线工作过程的简要说明其实就是classification任务的大致流程。
当然,albumentations如果仅仅只能做到上述的功能,那么torchvision中transform API可以把它完全替代,并且它也满足不了大多数cv任务的数据增强需求。
拿object detection为例,一张图片数据往往对应了若干个bounding box,如果你对图片数据进行的操作具有空间变换性,那么原有的bounding box数据画出的目标框必然已经对应不了图片中的对象了。
所以对图片数据进行变换的同时也必须对bounding box数据进行变换,保持二者的一致性。
绘制目标框
在介绍object detection的数据增强之前,先介绍一个绘制目标框的函数。在albumentation中展示的代码是用cv2实现,个人觉得画出的bounding box不太美观,下面使用的是matplotlib实现的代码。
import matplotlib.pyplot as plt
import matplotlib.patches as patches
def visualize_bbox(img, bbox, class_name, color, ax):
"""
img:图片数据 (H, W, C)数据格式
bbox:array或者tensor, 假定数据格式是 [x_mid, y_mid, width, height]
classname:str 目标框对应的种类
color:str
thickness:目标框的宽度
"""
x_mid, y_mid, width, height = bbox
x_min = int(x_mid - width / 2)
y_min = int(y_mid - height / 2)
# 画目标检测框
rect = patches.Rectangle((x_min, y_min),
width,
height,
linewidth=3,
edgecolor=color,
facecolor="none"
)
ax.imshow(img)
ax.add_patch(rect)
ax.text(x_min + 1, y_min - 3, class_name, fontSize=10, bbox={'facecolor':color, 'pad': 3, 'edgecolor':color})
def visualize(img, bboxes, category_ids, category_id_to_name, category_id_to_color):
fig, ax = plt.subplots(1, figsize=(8, 8))
ax.axis('off')
for box, category in zip(bboxes, category_ids):
class_name = category_id_to_name[category]
color = category_id_to_color[category]
visualize_bbox(img, box, class_name, color, ax)
plt.show()

对bounding box进行空间变换
导入所需要的库
import albumentations as A from PIL import Image import numpy as np image_path = './your/image/path' image = np.array(Image.open(image_path))
构造流水线
transform = A.Compose([ A.Resize(width=256, height=256), A.HorizontalFlip(p=0.5), A.RandomBrightnessContrast(p=0.2) ], bbox_params = A.BboxParams(format='yolo'))
相较于最简单的流水线(for classification),oject detection需要传入一个叫做bbox_params的参数,它接收的是用于配置bounding box参数的对象。
format表示的是bounding box数据的格式,albumentations提供了4种格式。
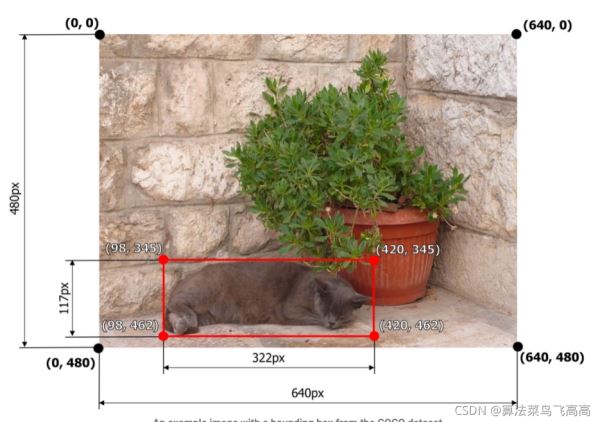
1.pascal_voc [x_min, y_min, x_max, y_max] 数值并没有归一化
直接使用像素值[98, 345, 420, 462]
2.albumentations [x_min, y_min, x_max, y_max] 与上一种格式不一样的是
这里值都是normalized 做了归一化处理[0.153125, 0.71875, 0.65625, 0.9625]
3.coco [x_min, y_min, width, height] 没有归一化
4.yolo [x_center, y_center, width, height] 归一化了
传入image数据和bounding box数据进行变换
label = np.array([
[0.339, 0.6693333333333333, 0.402, 0.42133333333333334],
[0.379, 0.5666666666666667, 0.158, 0.3813333333333333],
[0.612, 0.7093333333333333, 0.084, 0.3466666666666667],
[0.555, 0.7026666666666667, 0.078, 0.34933333333333333]
]) # normalized (x_center, y_center, width, height) 对应format yolo
category_ids = [12, 14, 14, 14]
category_id_to_name = {
12: 'horse',
14: 'people'
}
category_id_to_color = {
12: 'yellow',
14: 'red'
}
transformed = transform(image=image,bboxes=label)
transformed_image = transformed['image']
transformed_bboxes = transformed['bboxes']
height, width, _ = transformed_image.shape
transformed_bboxes[:, [0, 2]] = transformed_bboxes[:, [0, 2]] * width
transformed_bboxes[:, [1, 3]] = transformed_bboxes[:, [1, 3]] * height
visualize(transformed_image, transformed_bboxes, category_ids, category_id_to_name, category_id_to_color)

BboxParams中不止format这一个参数。当我们做随机裁剪操作的时候,bounding box完全可能只保留了一部分,当保留比例小于某一个阈值的时候,我们可以将其drop掉,具体的操作细节可以查看albumentations的相关教程。
semantic segmentation的数据增强
object detection和semantic segmentation在像素级别的data agumentation和classification没什么区别,而在空间变换上segmentation没有bounding box变换,与之对应的是mask变换。
mask是像素级别的label,与原图中的像素一一对应。
albumentations上的教程使用的是kaggle上的数据集,这里为了方便展示我们使用同样的数据集。
下载完数据并解压缩完成后可以得到如上的目录结构,通过train.csv文件可以得到所用的image和mask名称。
image = np.array(Image.open(image_path)) # 这里使用的是/train/images/0fea4b5049.png mask = np.array(Image.open(mask_path)) # /train/masks/0fea4b5049.png
下面介绍一下展示结果的函数
from matplotlib import pyplot as plt
def visualize(image, mask, original_image=None, original_mask=None):
fontsize=8
if original_image == None and original_mask == None:
fg, ax = plt.subplots(2, 1, figsize=(8, 8))
ax[0].axis('off')
ax[0].imshow(image)
ax[0].set_title('image', fontsize=fontsize)
ax[1].axis('off')
ax[1].imshow(mask)
ax[1].set_title('mask', fontsize=fontsize)
else:
fg, ax = plt.subplots(2, 2, figsize=(8, 8))
ax[0, 0].axis('off')
ax[0, 0].imshow(original_image)
ax[0, 0].set_title('Original Image', fontsize=fontsize)
ax[0, 1].axis('off')
ax[0, 1].imshow(original_mask)
ax[0, 1].set_title('Original Mask', fontsize=fontsize)
ax[1, 0].axis('off')
ax[1, 0].imshow(image)
ax[1, 0].set_title('Transformed Image', fontsize=fontsize)
ax[1, 1].axis('off')
ax[1, 1].imshow(mask)
ax[1, 1].set_title('Transformed Mask', fontsize=fontsize)
data agumentation的流水线操作
aug = A.PadIfNeeded(min_height=128, min_width=128, p=1) augmented = aug(image=image, mask=mask) augmented_img = augmented['image'] augmented_mask = augmented['mask'] visualize(augmented_img, augmented_mask, original_image=image, original_mask=mask)
这里相较于classification就是多了个mask函数,将mask数据直接传进入即可。
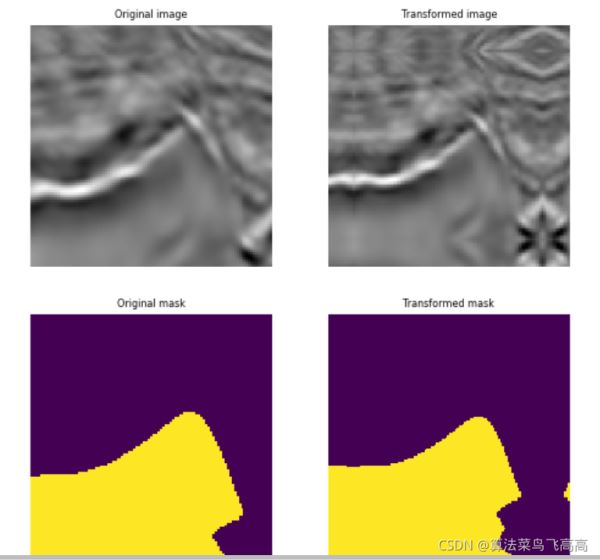
padding的填充方式默认是reflection, 可以看到变换以后的mask右侧多了些黄色区域。
对于一些分割任务而言,我们不想增加或者删除额外的信息,所以往往采用 Non destructive transformations(非破坏性变换)如HorizontalFlip(水平翻转), VerticalFlip(垂直翻转), RandomRotate90(Randomly rotates by 0, 90, 180, 270 degrees)
aug = A.RandomRotate(p=1) augmented = aug(image=image, mask=mask) augmented_image = augmented['image'] augmented_mask = augmented['mask'] visualize(augmented_image, augmented_mask, original_image=image, original_mask=mask)
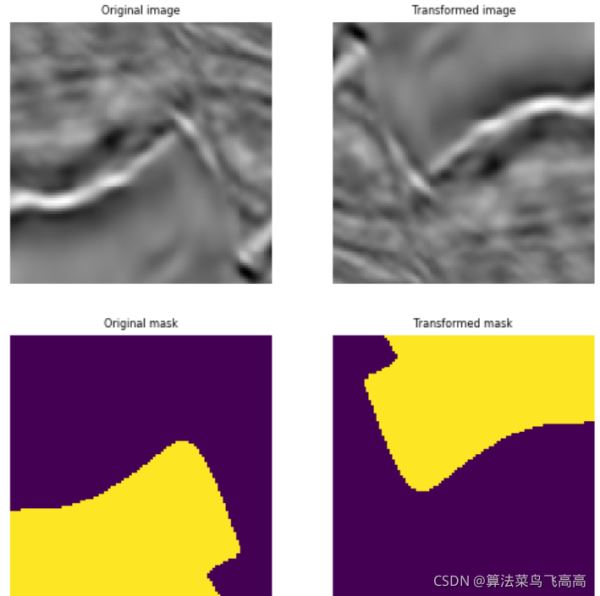
下面介绍下多个transform综合起来的流水线操作
original_height, original_width = image.shape[:2]
aug = A.Compose([
A.OneOf([
A.RandomSizedCrop(min_max_height=(50, 101), height=original_height, width=original_width, p=0.5),
A.PadIfNeeded(min_height=original_height, min_width=original_width, p=0.5)
]),
A.VerticalFlip(p=0.5),
A.RandomRotate90(p=0.5),
A.OneOf([
A.ElasticTransform(p=0.5, alpha=120, sigma=120 * 0.05, alpha_affine=120 * 0.03),
A.GridDistortion(p=0.5),
A.OpticalDistortion(distort_limit=1, shift_limit=0.5, p=1)
], p=0.8)
])
augmented = aug(image=image, mask=mask)
image_medium = augmented['image']
mask_medium = augmented['mask']
visualize(image_medium, mask_medium, original_image=image, original_mask=mask)
这里一个较新的知识点是A.OneOf,它接收的transform对象的list, 从中按照权重随机选择一个进行变换,它本身也有概率。
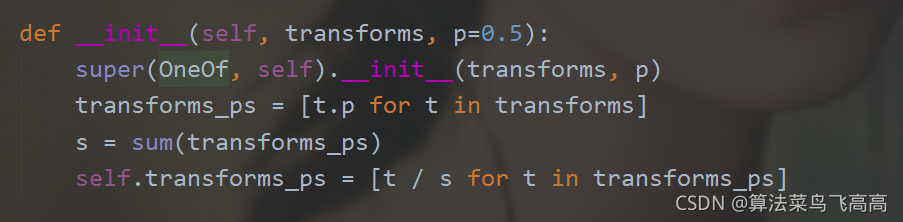
可以看到OneOf将list中的transform的概率进行归一化再重新分配。所以这里transform的p不再理解为概率,而是权重,取到1,甚至比1大都没有关系。
以上就是Python深度学习albumentations数据增强库的详细内容,更多关于Python数据增强库albumentations的资料请关注我们其它相关文章!
相关推荐
-

python使用matplotlib显示图像失真的解决方案
在python显示图象时,我们用matplotlib模块时会遇到图像色彩失真问题,究竟是什么原因呢,下面就来看看究竟. 待显示图像为: import cv2 from matplotlib import pyplot as plt img = cv2.imread('demo_2.jpg',0) plt.imshow(img, cmap = 'gray', interpolation = 'bicubic') plt.xticks([]), plt.yticks([]) # to hide ti
-
Python深度学习之使用Albumentations对图像做增强
目录 一.导入所需的库 二.定义可视化函数显示图像上的边界框和类标签 三.获取图像和标注 四.使用RandomSizedBBoxSafeCrop保留原始图像中的所有边界框 五.定义增强管道 六.输入用于增强的图像和边框 七.其他不同随机种子的示例 一.导入所需的库 import random import cv2 from matplotlib import pyplot as plt import albumentations as A 二.定义可视化函数显示图像上的边界框和类标签 可视化函数
-
Python深度学习之图像标签标注软件labelme详解
前言 labelme是一个非常好用的免费的标注软件,博主看了很多其他的博客,有的直接是翻译稿,有的不全面.对于新手入门还是有点困难.因此,本文的主要是详细介绍labelme该如何使用. 一.labelme是什么? labelme是图形图像注释工具,它是用Python编写的,并将Qt用于其图形界面.说直白点,它是有界面的, 像软件一样,可以交互,但是它又是由命令行启动的,比软件的使用稍微麻烦点.其界面如下图: 它的功能很多,包括: 对图像进行多边形,矩形,圆形,多段线,线段,点形式的标注(可用于目
-
Python深度学习albumentations数据增强库
数据增强的必要性 深度学习在最近十年得以风靡得益于计算机算力的提高以及数据资源获取的难度下降.一个好的深度模型往往需要大量具有label的数据,使得模型能够很好的学习这种数据的分布.而给数据打标签往往是一件耗时耗力的工作. 拿cv里的经典任务为例,classification需要人准确识别物品类别或者生物种类,object detection需要人工画出bounding box, 确定其坐标,semantic segmentation甚至需要在像素级别进行标签标注.对于一些专业领域的图像标注,依
-
13个最常用的Python深度学习库介绍
如果你对深度学习和卷积神经网络感兴趣,但是并不知道从哪里开始,也不知道使用哪种库,那么这里就为你提供了许多帮助. 在这篇文章里,我详细解读了9个我最喜欢的Python深度学习库. 这个名单并不详尽,它只是我在计算机视觉的职业生涯中使用并在某个时间段发现特别有用的一个库的列表. 这其中的一些库我比别人用的多很多,尤其是Keras.mxnet和sklearn-theano. 其他的一些我是间接的使用,比如Theano和TensorFlow(库包括Keras.deepy和Blocks等). 另外的我只
-
python深度学习标准库使用argparse调参
目录 前言 使用步骤: 常见规则 使用config文件传入超参数 argparse中action的可选参数store_true 前言 argparse是深度学习项目调参时常用的python标准库,使用argparse后,我们在命令行输入的参数就可以以这种形式python filename.py --lr 1e-4 --batch_size 32来完成对常见超参数的设置.,一般使用时可以归纳为以下三个步骤 使用步骤: 创建ArgumentParser()对象 调用add_argument()方法添
-
python深度学习tensorflow实例数据下载与读取
目录 一.mnist数据 二.CSV数据 三.cifar10数据 一.mnist数据 深度学习的入门实例,一般就是mnist手写数字分类识别,因此我们应该先下载这个数据集. tensorflow提供一个input_data.py文件,专门用于下载mnist数据,我们直接调用就可以了,代码如下: import tensorflow.examples.tutorials.mnist.input_data mnist = input_data.read_data_sets("MNIST_data/&q
-
Python深度学习之简单实现猫狗图像分类
一.前言 本文使用的是 kaggle 猫狗大战的数据集 训练集中有 25000 张图像,测试集中有 12500 张图像.作为简单示例,我们用不了那么多图像,随便抽取一小部分猫狗图像到一个文件夹里即可. 通过使用更大.更复杂的模型,可以获得更高的准确率,预训练模型是一个很好的选择,我们可以直接使用预训练模型来完成分类任务,因为预训练模型通常已经在大型的数据集上进行过训练,通常用于完成大型的图像分类任务. tf.keras.applications中有一些预定义好的经典卷积神经网络结构(Applic
-
Python深度学习之实现卷积神经网络
一.卷积神经网络 Yann LeCun 和Yoshua Bengio在1995年引入了卷积神经网络,也称为卷积网络或CNN.CNN是一种特殊的多层神经网络,用于处理具有明显网格状拓扑的数据.其网络的基础基于称为卷积的数学运算. 卷积神经网络(CNN)的类型 以下是一些不同类型的CNN: 1D CNN:1D CNN 的输入和输出数据是二维的.一维CNN大多用于时间序列. 2D CNNN:2D CNN的输入和输出数据是三维的.我们通常将其用于图像数据问题. 3D CNNN:3D CNN的输入和输出数
-
Python深度学习之Unet 语义分割模型(Keras)
目录 前言 一.什么是语义分割 二.Unet 1.基本原理 2.mini_unet 3. Mobilenet_unet 4.数据加载部分 参考 前言 最近由于在寻找方向上迷失自我,准备了解更多的计算机视觉任务重的模型.看到语义分割任务重Unet一个有意思的模型,我准备来复现一下它. 一.什么是语义分割 语义分割任务,如下图所示: 简而言之,语义分割任务就是将图片中的不同类别,用不同的颜色标记出来,每一个类别使用一种颜色.常用于医学图像,卫星图像任务. 那如何做到将像素点上色呢? 其实语义分割的输
-
Python深度学习之Keras模型转换成ONNX模型流程详解
目录 从Keras转换成PB模型 从PB模型转换成ONNX模型 改变现有的ONNX模型精度 部署ONNX 模型 总结 从Keras转换成PB模型 请注意,如果直接使用Keras2ONNX进行模型转换大概率会出现报错,这里笔者曾经进行过不同的尝试,最后都失败了. 所以笔者的推荐的情况是:首先将Keras模型转换为TensorFlow PB模型. 那么通过tf.keras.models.load_model()这个函数将模型进行加载,前提是你有一个基于h5格式或者hdf5格式的模型文件,最后再通过改