Python pandas替换指定数据的方法实例
目录
- 一、构造dataframe
- 二、替换指定数据(fillna、isin、replace)
- 1、用"sz"列的同行数据将"bj"列的空值替换掉
- 2、在1的基础上,将"sz"列为2或者6的数据替换成-4
- 三、替换函数replace()详解
- 1、全局替换元素
- 2、通过指定条件替换元素
- 3、通过模糊条件替换指定元素
- 总结
一、构造dataframe
import pandas as pd import numpy as np df=pd.DataFrame(np.arange(16).reshape(4,4),columns=["sh","bj","sz","gz"],index=["one","two","three","four"]) df.iloc[0,1]=np.nan
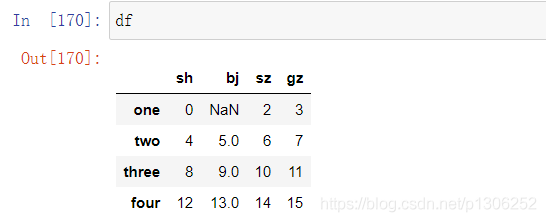
二、替换指定数据(fillna、isin、replace)
1、用"sz"列的同行数据将"bj"列的空值替换掉
df["bj"].fillna(df["sz"],inplace=True)

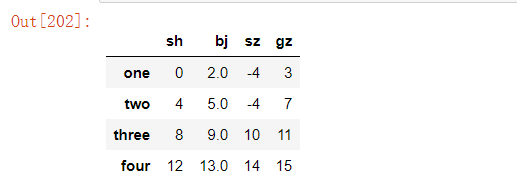
2、在1的基础上,将"sz"列为2或者6的数据替换成-4
法一:直接替换
df.loc[df["sz"].isin([2,6]),"sz"]=-4
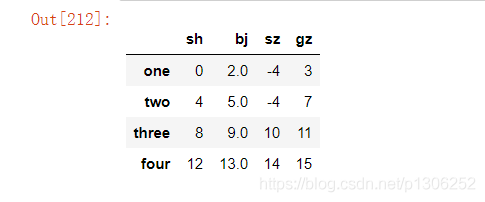
法二:函数replace()替换
df.replace({"sz":{2:-4,6:-4}},inplace=True)
三、替换函数replace()详解
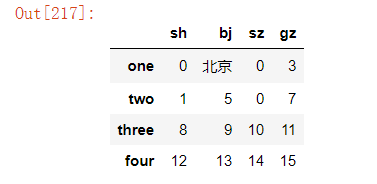
原dataframe如下:

1、全局替换元素
1)替换单个元素
df.replace(-4,0)#将所有的-4元素替换为0,返回dataframe
2)替换多个元素
法一:在字典中指定
df.replace({-4:0,4:1})#将-4替换为0,4替换为1
法二:在列表中指定
df.replace([-4,4],[0,1])#将-4替换为0,4替换为1
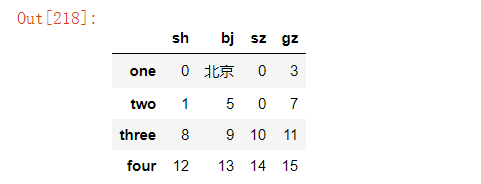
其中法二在列表中指定的方式,如果多个元素替换为相同的值,会更方便。
df.replace([-4,4],1)#将-4和4替换为1

2、通过指定条件替换元素
df.replace({"bj":{5:10,9:50},"gz":{7:10}})#将"bj"列的5替换为10,9替换为50,将gz列的7替换为10
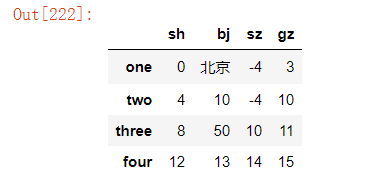
也可通过直接索引列的方式来替换指定列的元素
df["bj"].replace({5:10,9:50})#将"bj"列的5替换为10,9替换为50
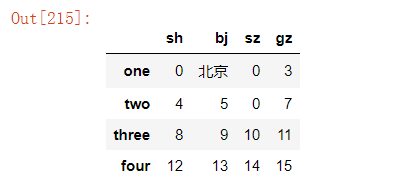
3、通过模糊条件替换指定元素
法一:通过字符串方法替换 str.replace()
df["bj"]=df["bj"].str.replace("北","南").fillna(df["bj"])#将"bj"列中的"北"字替换成"南"字,若无"北"值,则不替换
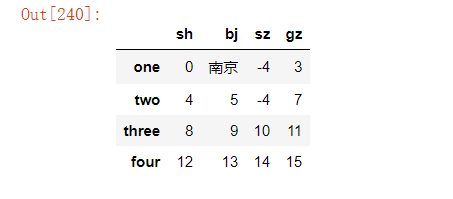
法二:通过正则匹配替换
df.replace("(.*)北(.*)","南京",regex=True)#将"bj"列中的含有"北"字的元素替换成"南京"
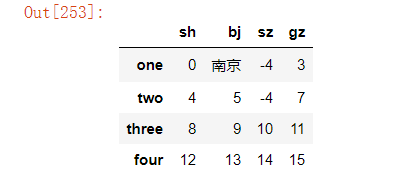
最后,如果需要在原始数据上完成替换,可以通过设置参数inplace=True。
参考链接:
https://blog.csdn.net/qq_18351157/article/details/107141339
总结
到此这篇关于Python pandas替换指定数据的文章就介绍到这了,更多相关Python pandas替换指定数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python Pandas中缺失值NaN的判断,删除及替换
目录 前言 1. 检查缺失值NaN 2. Pandas中NaN的类型 3. NaN的删除 dropna() 3.1 删除所有值均缺失的行/列 3.2 删除至少包含一个缺失值的行/列 3.3 根据不缺少值的元素数量删除行/列 3.4 删除特定行/列中缺少值的列/行 4. 缺失值NaN的替换(填充) fillna() 4.1 用通用值统一替换 4.2 为每列替换不同的值 4.3 用每列的平均值,中位数,众数等替换 4.4 替换为上一个或下一个值 总结 前言 当使用pandas读取csv文件时,如果元
-
python pandas 如何替换某列的一个值
摘要:本文主要是讲解怎么样替换某一列的一个值. 应用场景: 假如我们有以下的数据集: 我们想把里面不是pre的字符串全部换成Nonpre,我们要怎么做呢? 做法很简单. df['col2']=df['col1'] df.loc[df['col1'] !=' pre','col2']=Nonpre 以上这篇python pandas 如何替换某列的一个值就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
Python Pandas删除替换并提取其中的缺失值NaN(dropna,fillna,isnull)
目录 前言 Pandas中缺少值NaN的介绍 将缺失值作为Pandas中的缺少值NaN 缺少值NaN的删除方法 删除所有值均缺失的行/列 删除至少包含一个缺失值的行/列 根据不缺少值的元素数量删除行/列 删除特定行/列中缺少值的列/行 pandas.Series 替换(填充)缺失值 用通用值统一替换 为每列替换不同的值 用每列的平均值,中位数,众数等替换 替换为上一个或下一个值 指定连续更换的最大数量 pandas.Series 提取缺失值 提取特定行/列中缺少值的列/行 提取至少包含一个缺失值
-
python pandas消除空值和空格以及 Nan数据替换方法
在人工采集数据时,经常有可能把空值和空格混在一起,一般也注意不到在本来为空的单元格里加入了空格.这就给做数据处理的人带来了麻烦,因为空值和空格都是代表的无数据,而pandas中Series的方法notnull()会把有空格的数据也纳入进来,这样就不能完整地得到我们想要的数据了,这里给出一个简单的方法处理该问题. 方法1: 既然我们认为空值和空格都代表无数据,那么可以先得到这两种情况下的布尔数组. 这里,我们的DataFrame类型的数据集为df,其中有一个变量VIN,那么取得空值和空格的布尔数组
-

Python pandas替换指定数据的方法实例
目录 一.构造dataframe 二.替换指定数据(fillna.isin.replace) 1.用"sz"列的同行数据将"bj"列的空值替换掉 2.在1的基础上,将"sz"列为2或者6的数据替换成-4 三.替换函数replace()详解 1.全局替换元素 2.通过指定条件替换元素 3.通过模糊条件替换指定元素 总结 一.构造dataframe import pandas as pd import numpy as np df=pd.DataFr
-
Python "手绘风格"数据可视化方法实例汇总
目录 前言 Python-matplotlib 手绘风格图表绘制 Python-cutecharts 手绘风格图表绘制 Python-py-roughviz 手绘风格图表绘制 总结 前言 大家好,今天给大家带来绘制“手绘风格”可视化作品的小技巧,主要涉及Python编码绘制.主要内容如下: Python-matplotlib 手绘风格图表绘制 Python-cutecharts 手绘风格图表绘制 Python-py-roughviz 手绘风格图表绘制 Python-matplotlib 手绘风格
-
python脚本替换指定行实现步骤
python脚本替换指定行实现步骤 本文主要介绍了Python的脚本替换,由于工作的需要,必须对日志系统进行更新,这里在网上搜索到一篇文章比较不错,这里记录下,大家可以参考下, 工作中需要迁移代码,并把原来的日志系统更新到现在的格式,原来获取log的格式是 AuctionPoolLoggerUtil.getLogger() 现在获取log的格式是: LoggerFactory.getLogger(XXXXX.class) 这里的XXXXX需要替换为当前的类名.如果这样的java文
-
Python pandas删除指定行/列数据的方法实例
目录 1.滤除缺失数据dropna() 1)滤除含有NaN值的所有行 2)滤除含有NaN值的所有列 3)滤除元素都是NaN值的行 4)滤除元素都是NaN值的列 5)滤除指定列中含有缺失的行 2.删除重复值 drop_duplicates() 1)keep=“first” 2)keep=“last” 3)keep=False 4)删除指定列中重复项对应的行 3.根据指定条件删除行列drop() 1).删除指定列 2).删除指定行 总结 1.滤除缺失数据dropna() import pandas
-
python:pandas合并csv文件的方法(图书数据集成)
数据集成:将不同表的数据通过主键进行连接起来,方便对数据进行整体的分析. 两张表:ReaderInformation.csv,ReaderRentRecode.csv ReaderInformation.csv: ReaderRentRecode.csv: pandas读取csv文件,并进行csv文件合并处理: # -*- coding:utf-8 -*- import csv as csv import numpy as np # ------------- # csv读取表格数据 # ---
-
Python Pandas list列表数据列拆分成多行的方法实现
1.实现的效果 示例代码: df=pd.DataFrame({'A':[1,2],'B':[[1,2],[1,2]]}) df Out[458]: A B 0 1 [1, 2] 1 2 [1, 2] 拆分成多行的效果: A B 0 1 1 1 1 2 3 2 1 4 2 2 2.拆分成多行的方法 1)通过apply和pd.Series实现 容易理解,但在性能方面不推荐. df.set_index('A').B.apply(pd.Series).stack().reset_ind
-
Python Pandas模块实现数据的统计分析的方法
一.groupby函数 Python中的groupby函数,它主要的作用是进行数据的分组以及分组之后的组内的运算,也可以用来探索各组之间的关系,首先我们导入我们需要用到的模块 import pandas as pd 首先导入我们所需要用到的数据集 customer = pd.read_csv("Churn_Modelling.csv") marketing = pd.read_csv("DirectMarketing.csv") 我们先从一个简单的例子着手来看, c
-
Python pandas自定义函数的使用方法示例
本文实例讲述了Python pandas自定义函数的使用方法.分享给大家供大家参考,具体如下: 自定义函数的使用 import numpy as np import pandas as pd # todo 将自定义的函数作用到dataframe的行和列 或者Serise的行上 ser1 = pd.Series(np.random.randint(-10,10,5),index=list('abcde')) df1 = pd.DataFrame(np.random.randint(-10,10,(
-
Python处理XML格式数据的方法详解
本文实例讲述了Python处理XML格式数据的方法.分享给大家供大家参考,具体如下: 这里的操作是基于Python3平台. 在使用Python处理XML的问题上,首先遇到的是编码问题. Python并不支持gb2312,所以面对encoding="gb2312"的XML文件会出现错误.Python读取的文件本身的编码也可能导致抛出异常,这种情况下打开文件的时候就需要指定编码.此外就是XML中节点所包含的中文. 我这里呢,处理就比较简单了,只需要修改XML的encoding头部. #!/
-
Python Pandas学习之数据离散化与合并详解
目录 1数据离散化 1.1为什么要离散化 1.2什么是数据的离散化 1.3举例股票的涨跌幅离散化 2数据合并 2.1pd.concat实现数据合并 2.2pd.merge 1 数据离散化 1.1 为什么要离散化 连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数.离散化方法经常作为数据挖掘的工具. 1.2 什么是数据的离散化 连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数 值代表落在每个子区间中的属性值. 离散化有