python数据分析之单因素分析线性拟合及地理编码
目录
- 一、单因素分析线性拟合
- 二、实现地理编码
一、单因素分析线性拟合
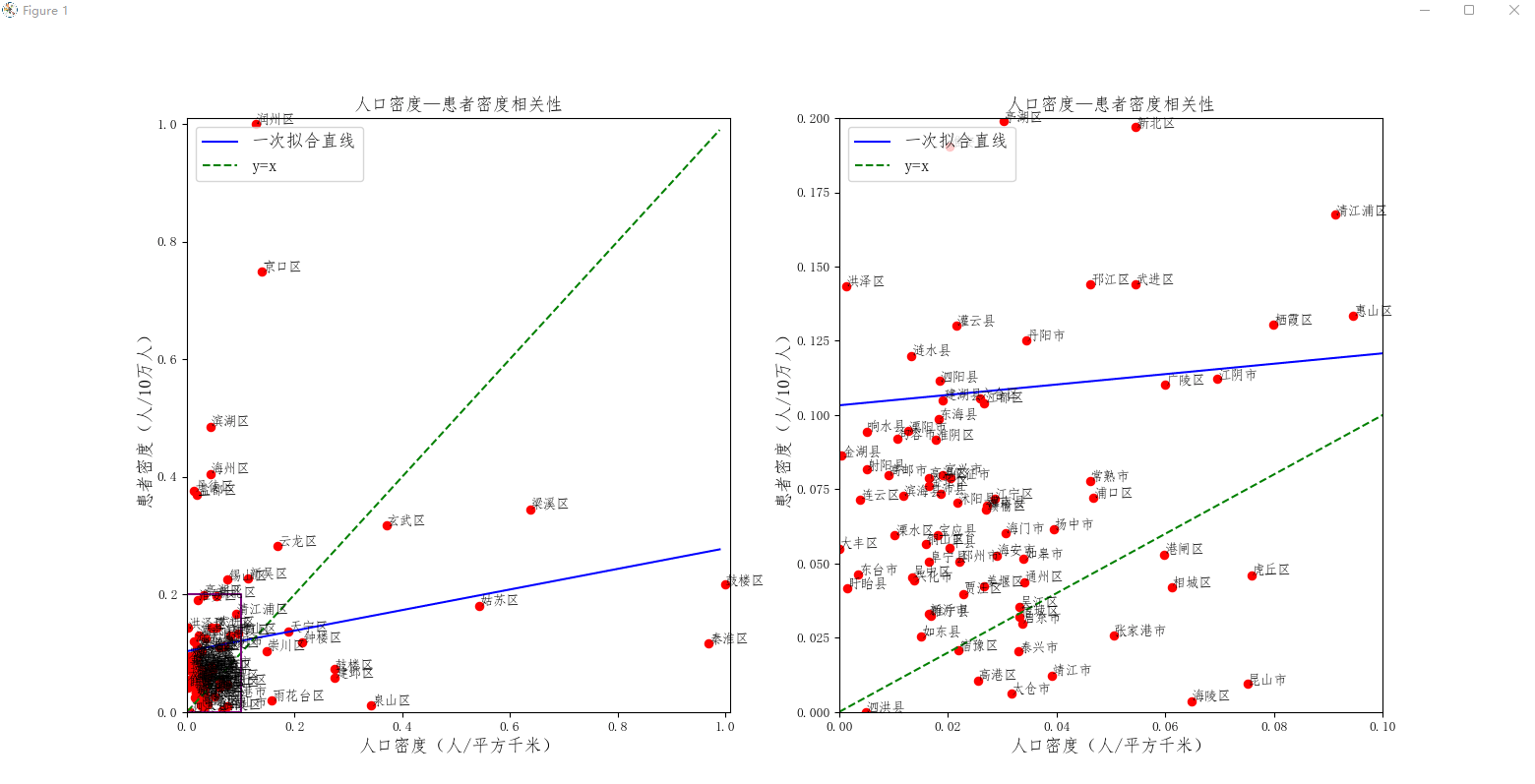
- 功能:线性拟合,单因素分析,对散点图进行线性拟合,并放大散点图的局部位置
- 输入:某个xlsx文件,包含'患者密度(人/10万人)'和'人口密度(人/平方千米)'两列
- 输出:对这两列数据进行线性拟合,绘制散点
实现代码:
import pandas as pd
from pylab import mpl
from scipy import optimize
import numpy as np
import matplotlib.pyplot as plt
def f_1(x, A, B):
return A*x + B
def draw_cure(file):
data1=pd.read_excel(file)
data1=pd.DataFrame(data1)
hz=list(data1['患者密度(人/10万人)'])
rk=list(data1['人口密度(人/平方千米)'])
hz_gy=[]
rk_gy=[]
for i in hz:
hz_gy.append((i-min(hz))/(max(hz)-min(hz)))
for i in rk:
rk_gy.append((i-min(rk))/(max(rk)-min(rk)))
n=['玄武区','秦淮区','建邺区','鼓楼区','浦口区','栖霞区','雨花台区','江宁区','六合区','溧水区','高淳区',
'锡山区','惠山区','滨湖区','梁溪区','新吴区','江阴市','宜兴市',
'鼓楼区','云龙区','贾汪区','泉山区','铜山区','丰县','沛县','睢宁县','新沂市','邳州市',
'天宁区','钟楼区','新北区','武进区','金坛区','溧阳市',
'虎丘区','吴中区','相城区','姑苏区','吴江区','常熟市','张家港市','昆山市','太仓市',
'崇川区','港闸区','通州区','如东县','启东市','如皋市','海门市','海安市',
'连云区','海州区','赣榆区','东海县','灌云县','灌南县',
'淮安区','淮阴区','清江浦区','洪泽区','涟水县','盱眙县','金湖县',
'亭湖区','盐都区','大丰区','响水县','滨海县','阜宁县','射阳县','建湖县','东台市',
'广陵区','邗江区','江都区','宝应县','仪征市','高邮市',
'京口区','润州区','丹徒区','丹阳市','扬中市','句容市',
'海陵区','高港区','姜堰区','兴化市','靖江市','泰兴市',
'宿城区','宿豫区','沭阳县','泗阳县','泗洪县']
mpl.rcParams['font.sans-serif'] = ['FangSong']
plt.figure(figsize=(16,8),dpi=98)
p1 = plt.subplot(121)
p2 = plt.subplot(122)
p1.scatter(rk_gy,hz_gy,c='r')
p2.scatter(rk_gy,hz_gy,c='r')
p1.axis([0.0,1.01,0.0,1.01])
p1.set_ylabel("患者密度(人/10万人)",fontsize=13)
p1.set_xlabel("人口密度(人/平方千米)",fontsize=13)
p1.set_title("人口密度—患者密度相关性",fontsize=13)
for i,txt in enumerate(n):
p1.annotate(txt,(rk_gy[i],hz_gy[i]))
A1, B1 = optimize.curve_fit(f_1, rk_gy, hz_gy)[0]
x1 = np.arange(0, 1, 0.01)
y1 = A1*x1 + B1
p1.plot(x1, y1, "blue",label='一次拟合直线')
x2 = np.arange(0, 1, 0.01)
y2 = x2
p1.plot(x2, y2,'g--',label='y=x')
p1.legend(loc='upper left',fontsize=13)
# # plot the box
tx0 = 0;tx1 = 0.1;ty0 = 0;ty1 = 0.2
sx = [tx0,tx1,tx1,tx0,tx0]
sy = [ty0,ty0,ty1,ty1,ty0]
p1.plot(sx,sy,"purple")
p2.axis([0,0.1,0,0.2])
p2.set_ylabel("患者密度(人/10万人)",fontsize=13)
p2.set_xlabel("人口密度(人/平方千米)",fontsize=13)
p2.set_title("人口密度—患者密度相关性",fontsize=13)
for i,txt in enumerate(n):
p2.annotate(txt,(rk_gy[i],hz_gy[i]))
p2.plot(x1, y1, "blue",label='一次拟合直线')
p2.plot(x2, y2,'g--',label='y=x')
p2.legend(loc='upper left',fontsize=13)
plt.show()
if __name__ == '__main__':
draw_cure("F:\医学大数据课题\论文终稿修改\scientific report\返修\市区县相关分析 _2231.xls")
实现效果:
二、实现地理编码
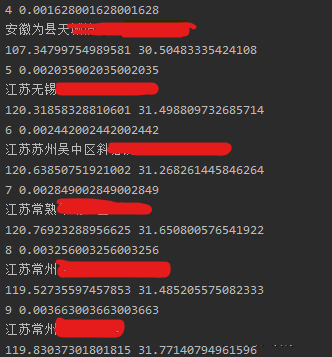
- 输入:中文地址信息,例如安徽为县天城镇都督村冲里18号
- 输出:经纬度坐标,例如107.34799754989581 30.50483335424108
- 功能:根据中文地址信息获取经纬度坐标
实现代码:
import json
from urllib.request import urlopen,quote
import xlrd
def readXLS(XLS_FILE,sheet0):
rb= xlrd.open_workbook(XLS_FILE)
rs= rb.sheets()[sheet0]
return rs
def getlnglat(adress):
url = 'http://api.map.baidu.com/geocoding/v3/?address='
output = 'json'
ak = 'fdi11GHN3GYVQdzVnUPuLSScYBVxYDFK'
add = quote(adress)#使用quote进行编码 为了防止中文乱码
# add=adress
url2 = url + add + '&output=' + output + '&ak=' + ak
req = urlopen(url2)
res = req.read().decode()
temp = json.loads(res)
return temp
def getlatlon(sd_rs):
nrows_sd_rs=sd_rs.nrows
for i in range(4,nrows_sd_rs):
# for i in range(4, 7):
row=sd_rs.row_values(i)
print(i,i/nrows_sd_rs)
b = (row[11]+row[12]+row[9]).replace('#','号') # 第三列的地址
print(b)
try:
lng = getlnglat(b)['result']['location']['lng'] # 获取经度并写入
lat = getlnglat(b)['result']['location']['lat'] #获取纬度并写入
except KeyError as e:
lng=''
lat=''
f_err=open('f_err.txt','a')
f_err.write(str(i)+'\t')
f_err.close()
print(e)
print(lng,lat)
f_latlon = open('f_latlon.txt', 'a')
f_latlon.write(row[0]+'\t'+b+'\t'+str(lng)+'\t'+str(lat)+'\n')
f_latlon.close()
if __name__=='__main__':
# sle_xls_file = 'F:\医学大数据课题\江苏省SLE数据库(两次随访合并).xlsx'
sle_xls_file = "F:\医学大数据课题\数据副本\江苏省SLE数据库(两次随访合并) - 副本.xlsx"
sle_data_rs = readXLS(sle_xls_file, 1)
getlatlon(sle_data_rs)
结果展示:
到此这篇关于python数据分析之单因素分析线性拟合及地理编码的文章就介绍到这了,更多相关python数据分析内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
彻彻底底地理解Python中的编码问题
Python处理文本的功能非常强大,但是如果是初学者,没有搞清楚python中的编码机制,也经常会遇到乱码或者decode error.本文的目的是简明扼要地说明python的编码机制,并给出一些建议. 问题1:问题在哪里? 问题是我们的靶子,心中没有问题去学习就会抓不住重点. 本文使用的编程环境是centos6.7,python2.7.我们在shell中键入python以打开python命令行,并键入如下两句话: s = "中国zg" e = s.encode("utf-8
-

Python实战实现爬取天气数据并完成可视化分析详解
1.实现需求: 从网上(随便一个网址,我爬的网址会在评论区告诉大家,dddd)获取某一年的历史天气信息,包括每天最高气温.最低气温.天气状况.风向等,完成以下功能: (1)将获取的数据信息存储到csv格式的文件中,文件命名为”城市名称.csv”,其中每行数据格式为“日期,最高温,最低温,天气,风向”: (2)在数据中增加“平均温度”一列,其中:平均温度=(最高温+最低温)/2,在同一张图中绘制两个城市一年平均气温走势折线图: (3)统计两个城市各类天气的天数,并绘制条形图进行对比,假设适合旅游的
-
python 线性回归分析模型检验标准--拟合优度详解
建立完回归模型后,还需要验证咱们建立的模型是否合适,换句话说,就是咱们建立的模型是否真的能代表现有的因变量与自变量关系,这个验证标准一般就选用拟合优度. 拟合优度是指回归方程对观测值的拟合程度.度量拟合优度的统计量是判定系数R^2.R^2的取值范围是[0,1].R^2的值越接近1,说明回归方程对观测值的拟合程度越好:反之,R^2的值越接近0,说明回归方程对观测值的拟合程度越差. 拟合优度问题目前还没有找到统一的标准说大于多少就代表模型准确,一般默认大于0.8即可 拟合优度的公式:R^2 = 1
-
python如何实现数据的线性拟合
实验室老师让给数据画一张线性拟合图.不会matlab,就琢磨着用python.参照了网上的一些文章,查看了帮助文档,成功的写了出来 这里用到了三个库 import numpy as np import matplotlib.pyplot as plt from scipy import optimize def f_1(x, A, B): return A * x + B plt.figure() # 拟合点 x0 = [75, 70, 65, 60, 55,50,45,40,35,30] y0
-
Python数据分析之 Pandas Dataframe条件筛选遍历详情
目录 一.条件筛选 二.Dataframe数据遍历 for...in...语句 iteritems()方法 iterrows()方法 itertuples()方法 一.条件筛选 查询Pandas Dataframe数据时,经常会筛选出符合条件的数据,接下来介绍一下具体的使用方式. 示例Dataframe如下: 单条件筛选,例如查询gender为woman的数据: df[df["gender"]=="woman"] # 或 df.loc[df["gender
-
python实现最小二乘法线性拟合
本文python代码实现的是最小二乘法线性拟合,并且包含自己造的轮子与别人造的轮子的结果比较. 问题:对直线附近的带有噪声的数据进行线性拟合,最终求出w,b的估计值. 最小二乘法基本思想是使得样本方差最小. 代码中self_func()函数为自定义拟合函数,skl_func()为调用scikit-learn中线性模块的函数. import numpy as np import matplotlib.pyplot as plt from sklearn.linear_model import Li
-
详解用Python调用百度地图正/逆地理编码API
一.背景 (正)地理编码指的是:将地理位置名称转换成经纬度: 逆地理编码指的是:将经纬度转换成地理位置信息,如地名.所在的省份或城市等 百度地图提供了相应的API,可以方便调用.相应的说明文档如下: 正地理编码 逆地理编码 具体API的参数可以查看相应的"服务文档": 不过首次使用时需要申请,具体在控制台.申请AK的方式可参见其他文章. 二.源码 废话不多说,直接放源码.这里提供了Python调用这两个API的方法. #!/usr/bin/env python # -*- coding
-
python数据分析之单因素分析线性拟合及地理编码
目录 一.单因素分析线性拟合 二.实现地理编码 一.单因素分析线性拟合 功能:线性拟合,单因素分析,对散点图进行线性拟合,并放大散点图的局部位置 输入:某个xlsx文件,包含'患者密度(人/10万人)'和'人口密度(人/平方千米)'两列 输出:对这两列数据进行线性拟合,绘制散点 实现代码: import pandas as pd from pylab import mpl from scipy import optimize import numpy as np import matplotli
-
Python线性拟合实现函数与用法示例
本文实例讲述了Python线性拟合实现函数与用法.分享给大家供大家参考,具体如下: 1. 参考别人写的: #-*- coding:utf-8 -*- import math import matplotlib.pyplot as plt def linefit(x , y): N = float(len(x)) sx,sy,sxx,syy,sxy=0,0,0,0,0 for i in range(0,int(N)): sx += x[i] sy += y[i] sxx += x[i]*x[i]
-
Python数据分析之双色球基于线性回归算法预测下期中奖结果示例
本文实例讲述了Python数据分析之双色球基于线性回归算法预测下期中奖结果.分享给大家供大家参考,具体如下: 前面讲述了关于双色球的各种算法,这里将进行下期双色球号码的预测,想想有些小激动啊. 代码中使用了线性回归算法,这个场景使用这个算法,预测效果一般,各位可以考虑使用其他算法尝试结果. 发现之前有很多代码都是重复的工作,为了让代码看的更优雅,定义了函数,去调用,顿时高大上了 #!/usr/bin/python # -*- coding:UTF-8 -*- #导入需要的包 import pan
-
python数据分析之时间序列分析详情
目录 前言 时间序列的相关检验 白噪声检验 平稳性检验 自相关和偏相关分析 移动平均算法 简单移动平均法 简单指数平滑法 霍尔特(Holt)线性趋势法 Holt-Winters季节性预测模型 ARIMA模型 ARMA模型 针对ARMA模型自动选择合适的参数 时序数据的异常值检测 前言 时间序列分析是基于随机过程理论和数理统计学方法: 每日的平均气温 每天的销售额 每月的降水量 时间序列分析主要通过statsmodel库的tsa模块完成: 根据时间序列的散点图,自相关函数和偏自相关函数图识别序列是
-
分享一下Python数据分析常用的8款工具
Python是数据处理常用工具,可以处理数量级从几K至几T不等的数据,具有较高的开发效率和可维护性,还具有较强的通用性和跨平台性.Python可用于数据分析,但其单纯依赖Python本身自带的库进行数据分析还是具有一定的局限性的,需要安装第三方扩展库来增强分析和挖掘能力. Python数据分析需要安装的第三方扩展库有:Numpy.Pandas.SciPy.Matplotlib.Scikit-Learn.Keras.Gensim.Scrapy等,以下是千锋武汉Python培训老师对该第三方扩展库的
-
Python 普通最小二乘法(OLS)进行多项式拟合的方法
多元函数拟合.如 电视机和收音机价格多销售额的影响,此时自变量有两个. python 解法: import numpy as np import pandas as pd #import statsmodels.api as sm #方法一 import statsmodels.formula.api as smf #方法二 import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D df = pd.read_c
-
python数据分析之用sklearn预测糖尿病
一.数据集描述 本数据集内含十个属性列 Pergnancies: 怀孕次数 Glucose:血糖浓度 BloodPressure:舒张压(毫米汞柱) SkinThickness:肱三头肌皮肤褶皱厚度(毫米) Insulin:两个小时血清胰岛素(μU/毫升) BMI:身体质量指数,体重除以身高的平方 Diabets Pedigree Function: 疾病血统指数 是否和遗传相关,Height:身高(厘米) Age:年龄 Outcome:0表示不患病,1表示患病. 任务:建立机器学习模型以准确预
-
Python数据分析之彩票的历史数据
一.需求介绍 该需求主要是分析彩票的历史数据 客户的需求是根据彩票的前两期的情况,如果存在某个斜着的两个数字相等,那么就买第三期的同一个位置处的彩票 对于1.,如果相等的数字是:1-5,那就买6-10,如果相等的数字是:6-10,那就买1-5: 对于2.,如果相等的数字是:1-5,那就买1-5,如果相等的数字是:6-10,,那就买6-10. 然后,根据这个方案,有可能会买中,但是也有可能买不中,于是,客户希望我可以统计出来在100天中,按照这种方法,连续6次以及6次以上的购买彩票才能够命中一次奖