caffe的python接口绘制loss和accuracy曲线
目录
- 引言
- anaconda库
- python接口实现
引言
使用python接口来运行caffe程序,主要的原因是python非常容易可视化。所以不推荐大家在命令行下面运行python程序。如果非要在命令行下面运行,还不如直接用 c++算了。
推荐使用jupyter notebook,spyder等工具来运行python代码,这样才和它的可视化完美结合起来。
anaconda库
因为我是用anaconda来安装一系列python第三方库的,所以我使用的是spyder,与matlab界面类似的一款编辑器,在运行过程中,可以查看各变量的值,便于理解,如下图:
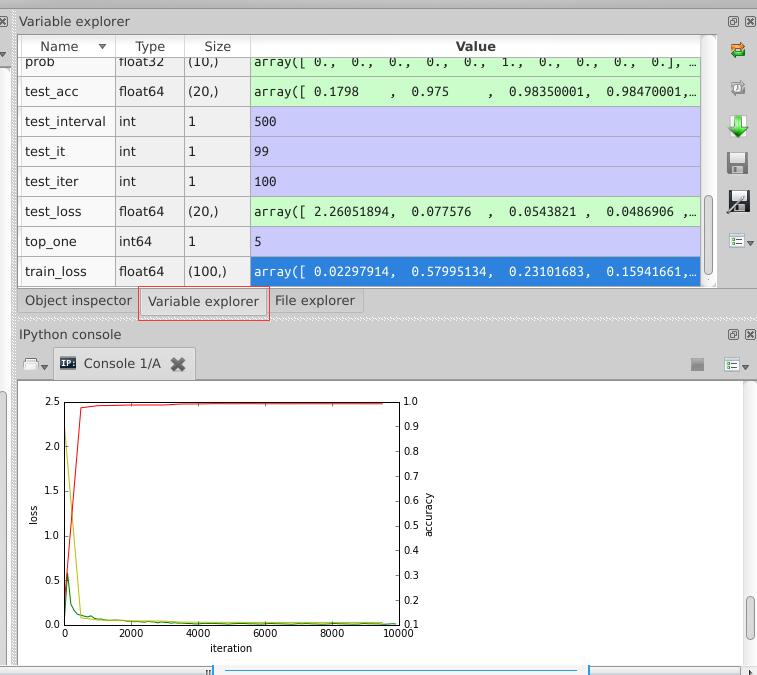
只要安装了anaconda,运行方式也非常方便,直接在终端输入spyder命令就可以了。
python接口实现
在caffe的训练过程中,我们如果想知道某个阶段的loss值和accuracy值,并用图表画出来,用python接口就对了。
# -*- coding: utf-8 -*-
"""
Created on Tue Jul 19 16:22:22 2016
@author: root
"""
import matplotlib.pyplot as plt
import caffe
caffe.set_device(0)
caffe.set_mode_gpu()
# 使用SGDSolver,即随机梯度下降算法
solver = caffe.SGDSolver('/home/xxx/mnist/solver.prototxt')
# 等价于solver文件中的max_iter,即最大解算次数
niter = 9380
# 每隔100次收集一次数据
display= 100
# 每次测试进行100次解算,10000/100
test_iter = 100
# 每500次训练进行一次测试(100次解算),60000/64
test_interval =938
#初始化
train_loss = zeros(ceil(niter * 1.0 / display))
test_loss = zeros(ceil(niter * 1.0 / test_interval))
test_acc = zeros(ceil(niter * 1.0 / test_interval))
# iteration 0,不计入
solver.step(1)
# 辅助变量
_train_loss = 0; _test_loss = 0; _accuracy = 0
# 进行解算
for it in range(niter):
# 进行一次解算
solver.step(1)
# 每迭代一次,训练batch_size张图片
_train_loss += solver.net.blobs['SoftmaxWithLoss1'].data
if it % display == 0:
# 计算平均train loss
train_loss[it // display] = _train_loss / display
_train_loss = 0
if it % test_interval == 0:
for test_it in range(test_iter):
# 进行一次测试
solver.test_nets[0].forward()
# 计算test loss
_test_loss += solver.test_nets[0].blobs['SoftmaxWithLoss1'].data
# 计算test accuracy
_accuracy += solver.test_nets[0].blobs['Accuracy1'].data
# 计算平均test loss
test_loss[it / test_interval] = _test_loss / test_iter
# 计算平均test accuracy
test_acc[it / test_interval] = _accuracy / test_iter
_test_loss = 0
_accuracy = 0
# 绘制train loss、test loss和accuracy曲线
print '\nplot the train loss and test accuracy\n'
_, ax1 = plt.subplots()
ax2 = ax1.twinx()
# train loss -> 绿色
ax1.plot(display * arange(len(train_loss)), train_loss, 'g')
# test loss -> 黄色
ax1.plot(test_interval * arange(len(test_loss)), test_loss, 'y')
# test accuracy -> 红色
ax2.plot(test_interval * arange(len(test_acc)), test_acc, 'r')
ax1.set_xlabel('iteration')
ax1.set_ylabel('loss')
ax2.set_ylabel('accuracy')
plt.show()
最后生成的图表在上图中已经显示出来了。
以上就是caffe的python接口绘制loss和accuracy曲线的详细内容,更多关于caffe python绘制loss accuracy的资料请关注我们其它相关文章!
相关推荐
-
caffe的python接口caffemodel参数及特征抽取
目录 前言 前言 如果用公式 y=f(wx+b) 来表示整个运算过程的话,那么w和b就是我们需要训练的东西,w称为权值,在cnn中也可以叫做卷积核(filter),b是偏置项.f是激活函数,有sigmoid.relu等.x就是输入的数据. 数据训练完成后,保存的caffemodel里面,实际上就是各层的w和b值. 我们运行代码: deploy=root + 'mnist/deploy.prototxt' #deploy文件 caffe_model=root + 'mnist/lenet_ite
-
python格式的Caffe图片数据均值计算学习
目录 引言 一.二进制格式的均值计算 二.python格式的均值计算 引言 图片减去均值后,再进行训练和测试,会提高速度和精度.因此,一般在各种模型中都会有这个操作. 那么这个均值怎么来的呢,实际上就是计算所有训练样本的平均值,计算出来后,保存为一个均值文件,在以后的测试中,就可以直接使用这个均值来相减,而不需要对测试图片重新计算. 一.二进制格式的均值计算 caffe中使用的均值数据格式是binaryproto, 作者为我们提供了一个计算均值的文件compute_image_mean.cpp,
-
caffe的python接口生成solver文件详解学习
目录 solver.prototxt的文件参数设置 生成solver文件 简便的方法 训练模型(training) solver.prototxt的文件参数设置 caffe在训练的时候,需要一些参数设置,我们一般将这些参数设置在一个叫solver.prototxt的文件里面,如下: base_lr: 0.001display: 782gamma: 0.1lr_policy: “step”max_iter: 78200momentum: 0.9snapshot: 7820snapshot_pref
-
caffe的python接口之手写数字识别mnist实例
目录 引言 一.数据准备 二.导入caffe库,并设定文件路径 二.生成配置文件 三.生成参数文件solver 四.开始训练模型 五.完成的python文件 引言 深度学习的第一个实例一般都是mnist,只要这个例子完全弄懂了,其它的就是举一反三的事了.由于篇幅原因,本文不具体介绍配置文件里面每个参数的具体函义,如果想弄明白的,请参看我以前的博文: 数据层及参数 视觉层及参数 solver配置文件及参数 一.数据准备 官网提供的mnist数据并不是图片,但我们以后做的实际项目可能是图片.因此有些
-

Caffe数据可视化环境python接口配置教程示例
目录 引言 一.安装python和pip 二.安装pyhon接口依赖库 三.利用anaconda来配置python环境 四.编译python接口 五.安装jupyter 引言 caffe程序是由c++语言写的,本身是不带数据可视化功能的.只能借助其它的库或接口,如opencv, python或matlab.大部分人使用python接口来进行可视化,因为python出了个比较强大的东西:ipython notebook, 现在的最新版本改名叫jupyter notebook,它能将python代码
-
caffe的python接口生成deploy文件学习示例
目录 如果要把训练好的模型拿来测试新的图片,那必须得要一个deploy.prototxt文件,这个文件实际上和test.prototxt文件差不多,只是头尾不相同而也.deploy文件没有第一层数据输入层,也没有最后的Accuracy层,但最后多了一个Softmax概率层. 这里我们采用代码的方式来自动生成该文件,以mnist为例. deploy.py # -*- coding: utf-8 -*- from caffe import layers as L,params as P,to_pro
-
caffe的python接口绘制loss和accuracy曲线
目录 引言 anaconda库 python接口实现 引言 使用python接口来运行caffe程序,主要的原因是python非常容易可视化.所以不推荐大家在命令行下面运行python程序.如果非要在命令行下面运行,还不如直接用 c++算了. 推荐使用jupyter notebook,spyder等工具来运行python代码,这样才和它的可视化完美结合起来. anaconda库 因为我是用anaconda来安装一系列python第三方库的,所以我使用的是spyder,与matlab界面类似的一款
-
python接口调用已训练好的caffe模型测试分类方法
训练好了model后,可以通过python调用caffe的模型,然后进行模型测试的输出. 本次测试主要依靠的模型是在caffe模型里面自带训练好的结构参数:~/caffe/models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel,以及结构参数 :~/caffe/models/bvlc_reference_caffenet/deploy.prototxt相结合,用python接口进行调用. 训练的源代码以及相应的注释如下所示
-
Python绘制loss曲线和准确率曲线实例代码
目录 引言 一.数据读取与存储部分 二.绘制 loss 曲线 三.绘制准确率曲线 总结 引言 使用 python 绘制网络训练过程中的的 loss 曲线以及准确率变化曲线,这里的主要思想就时先把想要的损失值以及准确率值保存下来,保存到 .txt 文件中,待网络训练结束,我们再拿这存储的数据绘制各种曲线. 其大致步骤为:数据读取与存储 - > loss曲线绘制 - > 准确率曲线绘制 一.数据读取与存储部分 我们首先要得到训练时的数据,以损失值为例,网络每迭代一次都会产生相应的 loss,那么我
-
TensorFlow绘制loss/accuracy曲线的实例
1. 多曲线 1.1 使用pyplot方式 import numpy as np import matplotlib.pyplot as plt x = np.arange(1, 11, 1) plt.plot(x, x * 2, label="First") plt.plot(x, x * 3, label="Second") plt.plot(x, x * 4, label="Third") plt.legend(loc=0, ncol=1)
-
keras自定义回调函数查看训练的loss和accuracy方式
前言: keras是一个十分便捷的开发框架,为了更好的追踪网络训练过程中的损失函数loss和准确率accuracy,我们有几种处理方式,第一种是直接通过 history=model.fit(),来返回一个history对象,通过这个对象可以访问到训练过程训练集的loss和accuracy以及验证集的loss和accuracy. 第二种方式就是通过自定义一个回调函数Call backs,来实现这一功能,本文主要讲解第二种方式. 一.如何构建回调函数Callbacks 本文所针对的例子是卷积神经网络