pandas Dataframe实现批量修改值的方法
目录
- 1.使用iloc对数据进行批量修改
- 2.对数据进行判定后,相互+/-/某个数*
- 第一种方法:使用内置函数where函数
- 第二种方法:使用mask函数
- 第三种方法:replace函数
1.使用iloc对数据进行批量修改
使用iloc最简单的就是将数据批量修改为某个特定的值
以下是我随便写入的数据:

现在将[‘d’,‘e’]列,[2,3,4]行的数据全部修改为0
import pandas as pd
data = pd.read_excel('some_chaneg.xlsx')
data1 = data
data1.iloc[2:5,3:] = 0
data1

.iloc用法[],先行后列,并且都是不包含最后一个元素,例如取[2,3,4]就是[2:5],列同样遵循此规则
2.对数据进行判定后,相互+/-/某个数*
第一种方法:使用内置函数where函数
Series.where(cond, other=nan, inplace=False, axis=None, level=None, errors='rais',...)
解释下来就是如果cond为真,则保持原来的值,否则替换为other,这里的cond和other参数由我们自己写入控制
# data2为data数据的一部分 data2 = data.iloc[0:,1:] print(data2) data2.where(data2>25, data2+5,inplace=True)
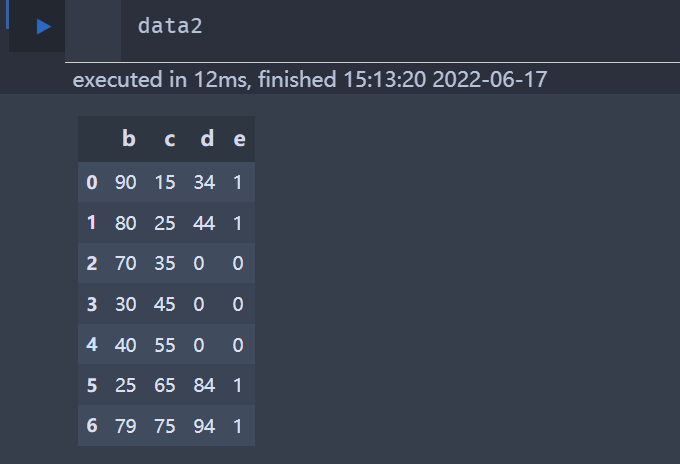

选取data2中<25的数据,全部加上5
第二种方法:使用mask函数
mask和where刚好相反
mask(cond, other=nan)
- where:替换条件(condition)为False处的值
- mask:替换条件(condition)为True处的值
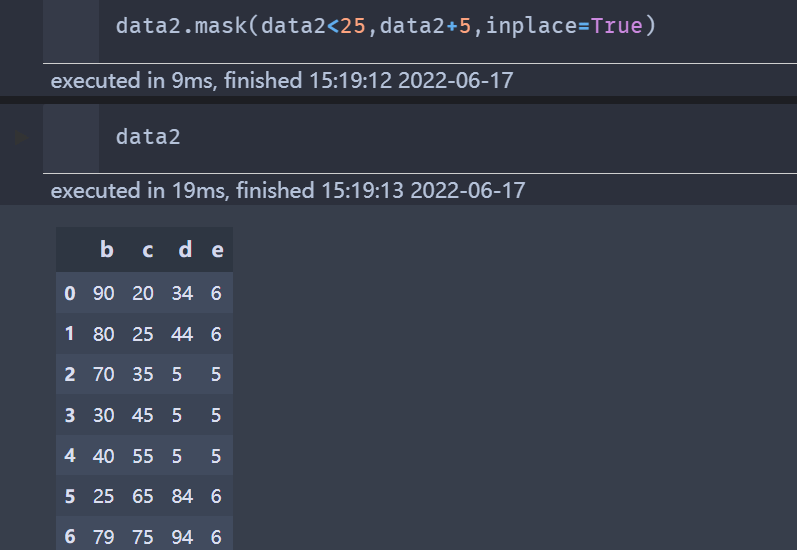
还是以data2举例
data2.mask(data2<25, data2+5, inplace=True)
第三种方法:replace函数
replace可以替换文本值,也可以使用字典替换多个值,也可以使用正则表达式嵌套方法,替换很多不同的值
替换文本值:
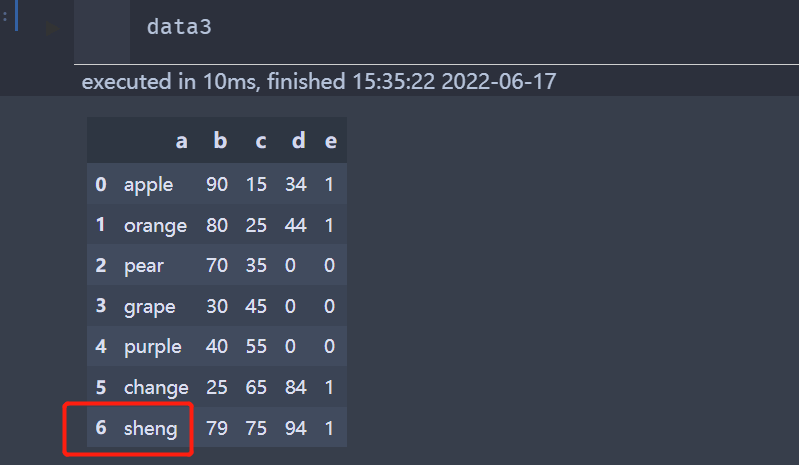
# 替换文本值
data3 = data
data3.replace('wange', 'sheng', inplace=True)
data3

替换多个值
将所有的0和1互换:
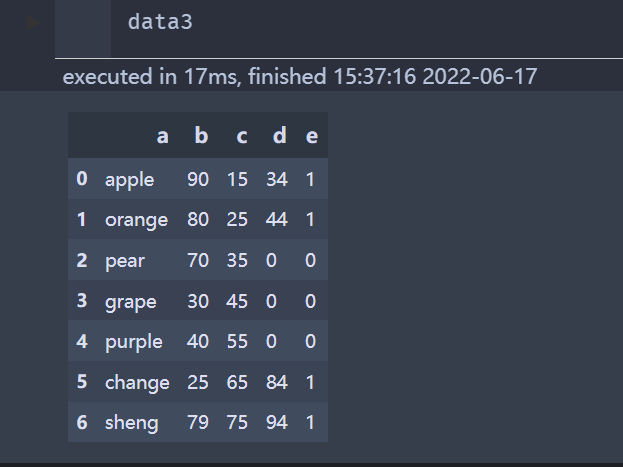
# 替换多个值
# 将所有的0和1互换
data3.replace({1:0,0:1},inplace=True)

运用正则表达式:
将所有含英文字母的全部变成Anonymous
# 切记使用正则表达式的时候,一定要添加上regex=True
data3.replace('[a-zA-Z]+','Anonymous',regex=True,inplace=True)

到此这篇关于pandas Dataframe实现批量修改值的方法的文章就介绍到这了,更多相关pandas 修改值内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Pandas实现DataFrame的简单运算、统计与排序
目录 一.运算 二.统计 三.排序 在前面的章节中,我们讨论了Series的计算方法与Pandas的自动对齐功能.不光是Series,DataFrame也是支持运算的,而且还是经常被使用的功能之一. 由于DataFrame的数据结构中包含了多行.多列,所以DataFrame的计算与统计可以是用行数据或者用列数据.为了更方便我们的使用,Pandas为我们提供了常用的计算与统计方法: 操作 方法 操作 方法 求和 sum 最大值 max 求均值 mean 最小值 min 求方差 var 标准差 st
-
pandas选择或添加列生成新的DataFrame操作示例
目录 如何向 pandas.DataFrame 添加新的列或行 选择某些列 选择某些列和行 添加新的列 更改某一列的值 补全缺失值 如何向 pandas.DataFrame 添加新的列或行 通过指定新的列名/行名来添加,或者用pandas.DataFrame的assign().insert().append()方法添加等方法. 这里,将描述以下内容. 将列添加到 pandas.DataFrame 通过指定新列名添加 用assign()方法添加/分配 用insert()方法添加到任意位置 使用 c
-
pandas中提取DataFrame某些列的一些方法
目录 前言 方法一:df[columns] 方法二:df.loc[]:用 label (行名或列名)做索引. 方法三:df.iloc[]: i 表示 integer,用 integer location(行或列的整数位置,从0开始)做索引. 补充:提取所有列名中包含“线索”.“浏览”字段的列 参考: 总结 前言 在处理表格型数据时,一行数据是一个 sample,列就是待提取的特征.怎么选取其中的一些列呢?本文分享一些方法. 使用如下的数据作为例子: import pandas as pd dat
-

Python数据分析之 Pandas Dataframe修改和删除及查询操作
目录 一.查询操作 元素的查询 二.修改操作 行列索引的修改 元素值的修改 三.行和列的删除操作 一.查询操作 可以使用Dataframe的index属性和columns属性获取行.列索引. import pandas as pd data = {"name": ["Alice", "Bob", "Cindy", "David"], "age": [25, 23, 28, 24], &q
-
Pandas 如何处理DataFrame中的inf值
目录 如何处理DataFrame的inf值 DataFrame有关inf的处理技巧 什么是inf? 为什么会产生? 产生inf有什么好处? 产生inf有什么坏处? 怎么处理? 怎么获取到inf的所在位置并进行填补? 如何处理DataFrame的inf值 在用DataFrame计算变化率时,例如(今天-昨天) / 昨天恰好为(2-0) / 0时,这些结果数据会变为inf. 为了方便后续处理,可以利用numpy,将这些inf值进行替换. 1. 将某1列(series格式)中的 inf 替换为数值.
-
Pandas DataFrame数据修改值的方法
dfmi.iloc[:,1] pandas要修改值先需要了解DataFrame的一些知识 此处参照的是pandas的官方文档 When setting values in a pandas object, care must be taken to avoid what is calledchained indexing. Here is an example. 要修改pandas--DataFrame中的值要注意避免在链式索引上得到的DataFrame的值 这里创建了一个DataFrame d
-
Python数据分析Pandas Dataframe排序操作
目录 1.索引的排序 2.值的排序 前言: 数据的排序是比较常用的操作,DataFrame 的排序分为两种,一种是对索引进行排序,另一种是对值进行排序,接下来就分别介绍一下. 1.索引的排序 DataFrame 提供了sort_index()方法来进行索引的排序,通过axis参数指定对行索引排序还是对列索引排序,默认为0,表示对行索引排序,设置为1表示对列索引进行排序:ascending参数指定升序还是降序,默认为True表示升序,设置为False表示降序, 具体使用方法如下: 对行索引进行降序
-
Python数据分析之 Pandas Dataframe合并和去重操作
目录 一.之 Pandas Dataframe合并 二.去重操作 一.之 Pandas Dataframe合并 在数据分析中,避免不了要从多个数据集中取数据,那就避免不了要进行数据的合并,这篇文章就来介绍一下 Dataframe 对象的合并操作. Pandas 提供了merge()方法来进行合并操作,使用语法如下: pd.merge(left, right, how="inner", on=None, left_on=None, right_on=None, left_index=Fa
-
Pandas-DataFrame知识点汇总
目录 1.DataFrame的创建 根据字典创建 读取文件 2.DataFrame轴的概念 3.DataFrame一些性质 索引.切片 修改数据 重新索引 丢弃指定轴上的值 算术运算 函数应用和映射 排序和排名 汇总和计算描述统计 处理缺失数据 1.DataFrame的创建 DataFrame是一种表格型数据结构,它含有一组有序的列,每列可以是不同的值.DataFrame既有行索引,也有列索引,它可以看作是由Series组成的字典,不过这些Series公用一个索引.DataFrame的创建有多种
-
Python数据分析之 Pandas Dataframe条件筛选遍历详情
目录 一.条件筛选 二.Dataframe数据遍历 for...in...语句 iteritems()方法 iterrows()方法 itertuples()方法 一.条件筛选 查询Pandas Dataframe数据时,经常会筛选出符合条件的数据,接下来介绍一下具体的使用方式. 示例Dataframe如下: 单条件筛选,例如查询gender为woman的数据: df[df["gender"]=="woman"] # 或 df.loc[df["gender