mysql主从只同步部分库或表的思路与方法
同步部分数据有两个思路,1.master只发送需要的;2.slave只接收想要的。
master端:
binlog-do-db 二进制日志记录的数据库(多数据库用逗号,隔开)
binlog-ignore-db 二进制日志中忽略数据库 (多数据库用逗号,隔开)
举例说明:
1)binlog-do-db=YYY 需要同步的数据库,不在内的不同步。(不添加这行表示同步所有)
这里主库只同步test1,test2库。
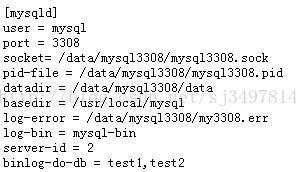
2)binlog-ignore-db = mysql 这是不记录binlog,来达到从库不同步mysql库,以确保各自权限
binlog-ignore-db = performance_schema
binlog-ignore-db = information_schema
这里向从库同步时忽略test1,test2库
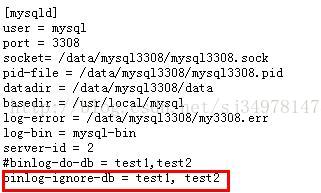
slave端
replicate-do-db 设定需要复制的数据库(多数据库使用逗号,隔开)
replicate-ignore-db 设定需要忽略的复制数据库 (多数据库使用逗号,隔开)
replicate-do-table 设定需要复制的表
replicate-ignore-table 设定需要忽略的复制表
replicate-wild-do-table 同replication-do-table功能一样,但是可以通配符
replicate-wild-ignore-table 同replication-ignore-table功能一样,但是可以加通配符
与上述对比,这里的replicate就很好理解了,下面简单说几点。
例如:
从库忽略复制数据库test3,但是需要说明的是,其实从库的relaylog中是从在关于test3的相关日志,只是从库没有使用罢了。


增加通配符的两个配置
replicate-wild-do-table=db_name.% 只复制哪个库的哪个表
replicate-wild-ignore-table=mysql.% 忽略哪个库的哪个表
总结
到此这篇关于mysql主从只同步部分库或表的文章就介绍到这了,更多相关mysql主从只同步部分内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Mysql主从同步的实现原理
1.什么是mysql主从同步? 当master(主)库的数据发生变化的时候,变化会实时的同步到slave(从)库. 2.主从同步有什么好处? 水平扩展数据库的负载能力. 容错,高可用.Failover(失败切换)/High Availability 数据备份. 3.主从同步的原理是什么? 首先我们来了解master-slave的体系结构. 如下图: 不管是delete.update.insert,还是创建函数.存储过程,所有的操作都在master上.当master有操作的时候,slave会快速的
-
MySQL主从同步延迟的原因及解决办法
由于历史原因,MySQL复制基于逻辑的二进制日志,而非重做日志.多次被问到何时MySQL能支持基于物理的复制,其实这就看MySQL各位大佬的想法.上次和赖老师脑暴,倏地说道:MySQL会不会来个基于Paxos的redo复制? 物理复制的真正好处不在于正确性,因为基于ROW格式的日志复制也已能完全保证复制的正确性.由于物理日志的写入是在事务执行过程中就不断写入,而二进制日志的写入仅仅在事务提交时.因此物理日志的优势如下所示: 复制架构下,大事务日志提交速度快: 复制架构下,主从数据延迟小: 假设执
-
mysql主从库不同步问题解决方法
遇到这样的错误如:"Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find first log file name in binary log index file'"等或由于清数据导致主从库不同步了,解决办法如下: 先进入slave中执行:"slave stop;"来停止从库同步: 再去master中执行:"flu
-
MySQL主从同步、读写分离配置步骤
现在使用的两台服务器已经安装了MySQL,全是rpm包装的,能正常使用. 为了避免不必要的麻烦,主从服务器MySQL版本尽量保持一致; 环境:192.168.0.1 (Master) 192.168.0.2 (Slave) MySQL Version:Ver 14.14 Distrib 5.1.48, for pc-linux-gnu (i686) using readline 5.1 1.登录Master服务器,修改my.cnf,添加如下内容: server-id = 1 //数据库ID号,
-
Mysql主从同步备份策略分享
环境:主从服务器上的MySQL数据库版本同为5.1.34主机IP:192.168.0.1从机IP:192.168.0.2一. MySQL主服务器配置1.编辑配置文件/etc/my.cnf# 确保有如下行server-id = 1log-bin=mysql-binbinlog-do-db=mysql #需要备份的数据库名,如果备份多个数据库,重复设置这个选项即可binlog-ignore-db=mysql #不需要备份的数据库名,如果备份多个数据库,重复设置这个选项即可log-slave-up
-
Mysql 主从数据库同步(centos篇)
环境: 主服务器:centos 5.2 mysql 5.1.35 源码 IP:192.168.1.22 从服务器:centos 5.2 mysql 5.1.35 源码 IP:192.168.1.33 配置: 一.主服务器 1.1.创建一个复制用户,具有replication slave 权限. mysql>grant replication slave on *.* to 'repl'@'192.168.1.22' identified by 'repl'; 1.2.编辑my.cnf文件 vi
-
mysql主从数据库不同步的2种解决方法
今天发现Mysql的主从数据库没有同步 先上Master库: mysql>show processlist; 查看下进程是否Sleep太多.发现很正常. show master status; 也正常. mysql> show master status; +-------------------+----------+--------------+-------------------------------+ | File | Position | Binlog_Do_DB | Binlo
-
详解Mysql主从同步配置实战
1.Introduction 之前写过一篇文章:Mysql主从同步的原理. 相信看过这篇文章的童鞋,都摩拳擦掌,跃跃一试了吧? 今天我们就来一次mysql主从同步实战! 2.环境说明 os:ubuntu16.04 mysql:5.7.17 下面的实战演练,都是基于上面的环境.当然,其他环境也大同小异. 3.进入实战 工具 2台机器: master IP:192.168.33.22 slave IP:192.168.33.33 master机器上的操作 1.更改配置文件 我们找到文件 /etc/
-
详解MySQL数据库设置主从同步的方法
简介 MySQL主从同步是目前使用比较广泛的数据库架构,技术比较成熟,配置也不复杂,特别是对于负载比较大的网站,主从同步能够有效缓解数据库读写的压力. MySQL主从同步的机制: MySQL同步的流程大致如下: 1.主服务器(master)将变更事件(更新.删除.表结构改变等等)写入二进制日志(master log). 2.从服务器(slave)的IO线程从主服务器(binlog dump线程)获取二进制日志,并在本地保存一份自己的二进制日志(relay log) 3.从服务器的SQL线程读取本
-
mysql主从只同步部分库或表的思路与方法
同步部分数据有两个思路,1.master只发送需要的:2.slave只接收想要的. master端: binlog-do-db 二进制日志记录的数据库(多数据库用逗号,隔开) binlog-ignore-db 二进制日志中忽略数据库 (多数据库用逗号,隔开) 举例说明: 1)binlog-do-db=YYY 需要同步的数据库,不在内的不同步.(不添加这行表示同步所有) 这里主库只同步test1,test2库. 2)binlog-ignore-db = mysql 这是不记录binlo
-
减少mysql主从数据同步延迟问题的详解
基于局域网的master/slave机制在通常情况下已经可以满足'实时'备份的要求了.如果延迟比较大,就先确认以下几个因素: 1. 网络延迟2. master负载3. slave负载一般的做法是,使用多台slave来分摊读请求,再从这些slave中取一台专用的服务器,只作为备份用,不进行其他任何操作,就能相对最大限度地达到'实时'的要求了 另外,再介绍2个可以减少延迟的参数 –slave-net-timeout=seconds 参数含义:当slave从主数据库读取log数据失败后,等待多久重新
-
MYSQL数据库数据拆分之分库分表总结
数据存储演进思路一:单库单表 单库单表是最常见的数据库设计,例如,有一张用户(user)表放在数据库db中,所有的用户都可以在db库中的user表中查到. 数据存储演进思路二:单库多表 随着用户数量的增加,user表的数据量会越来越大,当数据量达到一定程度的时候对user表的查询会渐渐的变慢,从而影响整个DB的性能.如果使用mysql, 还有一个更严重的问题是,当需要添加一列的时候,mysql会锁表,期间所有的读写操作只能等待. 可以通过某种方式将user进行水平的切分,产生两个表结构完全一样的
-
MYSQL主从不同步延迟原理分析及解决方案
1. MySQL数据库主从同步延迟原理.要说延时原理,得从mysql的数据库主从复制原理说起,mysql的主从复制都是单线程的操作,主库对所有DDL和DML产生binlog,binlog是顺序写,所以效率很高,slave的Slave_IO_Running线程到主库取日志,效率很比较高,下一步,问题来了,slave的Slave_SQL_Running线程将主库的DDL和DML操作在slave实施.DML和DDL的IO操作是随即的,不是顺序的,成本高很多,还可能可slave上的其他查询产生lock争
-
mysql主从服务器同步心得体会第1/2页
原来看过MYSQL同步数据的实现,可是自己还没有动过手,今天没什么事就玩一玩,正好在旁边有另一台空电脑,都在同一个路由器下.哈哈,正好. 不过首先在找配置文件上就把我卡了好久,由于我用的是xampp安装包,在xampp/mysql/bin目录下看始终没有找到my.cnf,在c:windows目录下也没有发现, 如上图,看到的只有一个"my"的快速拨号的东西,又不是文件,怎么都打不开.后来找了好久才在网上看到说遇到这种情况需要先打开editplus,然后再从editplus里面打开这个文
-
MYSQL主从数据库同步备份配置的方法
下文分步骤给大家介绍的非常详细,具体详情请看下文吧. 一.准备 用两台服务器做测试: Master Server: 192.0.0.1/Linux/MYSQL 4.1.12 Slave Server: 192.0.0.2/Linux/MYSQL 4.1.18 做主从服务器的原则是,MYSQL版本要相同,如果不能满足,最起码从服务器的MYSQL的版本必须高于主服务器的MYSQL版本 二.配置master服务器 1. 登录Master服务器,编辑my.cnf #vim /etc/my.cnf 在[m
-
CentOS服务器环境下MySQL主从同步配置方法
本文实例讲述了CentOS服务器环境下MySQL主从同步配置方法.分享给大家供大家参考,具体如下: 一.环境 主机: master操作系统:centos 5.3 IP:192.168.1.222 MySQL版本:5.0.77 从机: slave操作系统:centos 5.3 IP:192.168.1.220 MySQL版本:5.0.77 二.创建数据库 分别登录master机和slave机的 mysql:mysql –u root –p 创建数据库: create database repl;
-
详解MySQL主从不一致情形与解决方法
一.MySQL主从不同步情况 1.1 网络的延迟 由于mysql主从复制是基于binlog的一种异步复制 通过网络传送binlog文件,理所当然网络延迟是主从不同步的绝大多数的原因,特别是跨机房的数据同步出现这种几率非常的大,所以做读写分离,注意从业务层进行前期设计. 1.2 主从两台机器的负载不一致 由于mysql主从复制是主数据库上面启动1个io线程,而从上面启动1个sql线程和1个io线程,当中任何一台机器的负载很高,忙不过来,导致其中的任何一个线程出现资源不足,都将出现主从不一致的情况.