运用Python3实现Two-Pass算法检测区域连通性
目录
- 技术背景
- Two-Pass算法
- 测试数据的生成
- Two-Pass算法的实现
- 算法的执行流程
- 标签的重映射
- 其他的测试用例
- 总结概要
- 参考链接
技术背景
连通性检测是图论中常常遇到的一个问题,我们可以用五子棋的思路来理解这个问题五子棋中,横、竖、斜相邻的两个棋子,被认为是相连接的,而一样的道理,在一个二维的图中,只要在横、竖、斜三个方向中的一个存在相邻的情况,就可以认为图上相连通的。比如以下案例中的python数组,3号元素和5号元素就是相连接的,5号元素和6号元素也是相连接的,因此这三个元素实际上是属于同一个区域的:
array([[0, 3, 0],
[0, 5, 0],
[6, 0, 0]])
而再如下面这个例子,其中的1、2、3三个元素是相连的,4、5、6三个元素也是相连的,但是这两个区域不存在连接性,因此这个网格被分成了两个区域:
array([[1, 0, 4],
[2, 0, 5],
[3, 0, 6]])
那么如何高效的检测一张图片或者一个矩阵中的所有连通区域并打上标签,就是我们所关注的一个问题。
Two-Pass算法
一个典型的连通性检测的方案是Two-Pass算法,该算法可以用如下的一张动态图来演示:

该算法的核心在于用两次的遍历,为所有的节点打上分区的标签,如果是不同的分区,就会打上不同的标签。其基本的算法步骤可以用如下语言进行概述:
- 遍历网格节点,如果网格的上、左、左上三个格点不存在元素,则为当前网格打上新的标签,同时标签编号加一;
- 当上、左、左上的网格中存在一个元素时,将该元素值赋值给当前的网格作为标签;
- 当上、左、左上的网格中有多个元素时,取最低值作为当前网格的标签;
- 在标签赋值时,留意标签上边和左边已经被遍历过的4个元素,将4个元素中的最低值与这四个元素分别添加到Union的数据结构中(参考链接1);
- 再次遍历网格节点,根据Union数据结构中的值刷新网格中的标签值,最终得到划分好区域和标签的元素矩阵。
测试数据的生成
这里我们以Python3为例,可以用Numpy来产生一系列随机的0-1矩阵,这里我们产生一个20*20大小的矩阵:
# two_pass.py
import numpy as np
import matplotlib.pyplot as plt
if __name__ == "__main__":
np.random.seed(1)
graph = np.random.choice([0,1],size=(20,20))
print (graph)
plt.figure()
plt.imshow(graph)
plt.savefig('random_bin_graph.png')
执行的输出结果如下:
$ python3 two_pass.py [[1 1 0 0 1 1 1 1 1 0 0 1 0 1 1 0 0 1 0 0] [0 1 0 0 1 0 0 0 1 0 0 0 1 1 1 1 1 0 0 0] [1 1 1 1 1 1 0 1 1 0 0 1 0 0 1 1 1 0 1 0] [0 1 1 0 1 1 1 1 0 0 1 1 0 0 0 0 1 1 1 0] [1 0 0 1 1 0 1 1 0 1 0 0 1 1 1 0 1 1 0 1] [1 1 1 0 0 0 0 0 1 1 1 1 1 1 1 0 0 0 0 0] [0 1 1 1 1 1 1 0 0 1 1 0 0 1 0 0 0 1 1 1] [1 1 0 1 0 1 0 0 0 1 1 1 0 1 0 0 0 0 1 0] [1 0 1 1 1 0 0 0 0 0 0 1 0 0 1 0 0 1 1 0] [0 0 1 0 0 0 0 1 0 0 0 0 1 1 0 0 1 1 1 0] [0 0 0 0 1 1 1 0 1 1 0 0 0 1 1 0 1 1 1 0] [1 1 1 1 0 1 0 0 1 0 1 0 1 1 0 1 1 0 1 1] [1 0 1 0 1 0 1 1 1 1 1 1 0 0 1 1 0 0 0 1] [1 0 0 0 0 0 1 1 1 1 1 1 1 0 0 1 0 0 0 1] [0 1 0 1 0 0 0 0 1 1 0 0 0 1 0 1 1 0 0 1] [0 1 0 0 0 1 0 1 0 1 1 1 0 1 0 1 1 1 1 0] [0 1 0 0 0 0 1 1 0 1 1 0 0 1 1 1 1 1 1 1] [0 0 0 0 0 0 0 1 0 0 0 0 0 1 1 1 1 0 0 0] [1 0 1 0 1 0 0 0 0 0 0 1 0 0 0 1 0 1 1 0] [0 1 1 0 1 0 1 0 1 1 0 0 1 0 0 0 0 0 1 1]]
同时会生成一张网格的图片:

其实从这个图片中我们可以看出,图片的上面部分几乎都是连接在一起的,只有最下面存在几个独立的区域。
Two-Pass算法的实现
这里需要说明的是,因为我们并没有使用Union的数据结构,而是只使用了Python的字典数据结构,因此代码写起来会比较冗余而且不是那么美观,但是这里我们主要的目的是先用代解决这一实际问题,因此代码乱就乱一点吧。
# two_pass.py
import numpy as np
import matplotlib.pyplot as plt
from copy import deepcopy
def first_pass(g) -> list:
graph = deepcopy(g)
height = len(graph)
width = len(graph[0])
label = 1
index_dict = {}
for h in range(height):
for w in range(width):
if graph[h][w] == 0:
continue
if h == 0 and w == 0:
graph[h][w] = label
label += 1
continue
if h == 0 and graph[h][w-1] > 0:
graph[h][w] = graph[h][w-1]
continue
if w == 0 and graph[h-1][w] > 0:
if graph[h-1][w] <= graph[h-1][min(w+1, width-1)]:
graph[h][w] = graph[h-1][w]
index_dict[graph[h-1][min(w+1, width-1)]] = graph[h-1][w]
elif graph[h-1][min(w+1, width-1)] > 0:
graph[h][w] = graph[h-1][min(w+1, width-1)]
index_dict[graph[h-1][w]] = graph[h-1][min(w+1, width-1)]
continue
if h == 0 or w == 0:
graph[h][w] = label
label += 1
continue
neighbors = [graph[h-1][w], graph[h][w-1], graph[h-1][w-1], graph[h-1][min(w+1, width-1)]]
neighbors = list(filter(lambda x:x>0, neighbors))
if len(neighbors) > 0:
graph[h][w] = min(neighbors)
for n in neighbors:
if n in index_dict:
index_dict[n] = min(index_dict[n], min(neighbors))
else:
index_dict[n] = min(neighbors)
continue
graph[h][w] = label
label += 1
return graph, index_dict
def remap(idx_dict) -> dict:
index_dict = deepcopy(idx_dict)
for id in idx_dict:
idv = idx_dict[id]
while idv in idx_dict:
if idv == idx_dict[idv]:
break
idv = idx_dict[idv]
index_dict[id] = idv
return index_dict
def second_pass(g, index_dict) -> list:
graph = deepcopy(g)
height = len(graph)
width = len(graph[0])
for h in range(height):
for w in range(width):
if graph[h][w] == 0:
continue
if graph[h][w] in index_dict:
graph[h][w] = index_dict[graph[h][w]]
return graph
def flatten(g) -> list:
graph = deepcopy(g)
fgraph = sorted(set(list(graph.flatten())))
flatten_dict = {}
for i in range(len(fgraph)):
flatten_dict[fgraph[i]] = i
graph = second_pass(graph, flatten_dict)
return graph
if __name__ == "__main__":
np.random.seed(1)
graph = np.random.choice([0,1],size=(20,20))
graph_1, idx_dict = first_pass(graph)
idx_dict = remap(idx_dict)
graph_2 = second_pass(graph_1, idx_dict)
graph_3 = flatten(graph_2)
print (graph_3)
plt.subplot(131)
plt.imshow(graph)
plt.subplot(132)
plt.imshow(graph_3)
plt.subplot(133)
plt.imshow(graph_3>0)
plt.savefig('random_bin_graph.png')
完整代码的输出如下所示:
$ python3 two_pass.py [[1 1 0 0 1 1 1 1 1 0 0 1 0 1 1 0 0 1 0 0] [0 1 0 0 1 0 0 0 1 0 0 0 1 1 1 1 1 0 0 0] [1 1 1 1 1 1 0 1 1 0 0 1 0 0 1 1 1 0 1 0] [0 1 1 0 1 1 1 1 0 0 1 1 0 0 0 0 1 1 1 0] [1 0 0 1 1 0 1 1 0 1 0 0 1 1 1 0 1 1 0 1] [1 1 1 0 0 0 0 0 1 1 1 1 1 1 1 0 0 0 0 0] [0 1 1 1 1 1 1 0 0 1 1 0 0 1 0 0 0 1 1 1] [1 1 0 1 0 1 0 0 0 1 1 1 0 1 0 0 0 0 1 0] [1 0 1 1 1 0 0 0 0 0 0 1 0 0 1 0 0 1 1 0] [0 0 1 0 0 0 0 1 0 0 0 0 1 1 0 0 1 1 1 0] [0 0 0 0 1 1 1 0 1 1 0 0 0 1 1 0 1 1 1 0] [1 1 1 1 0 1 0 0 1 0 1 0 1 1 0 1 1 0 1 1] [1 0 1 0 1 0 1 1 1 1 1 1 0 0 1 1 0 0 0 1] [1 0 0 0 0 0 1 1 1 1 1 1 1 0 0 1 0 0 0 1] [0 1 0 2 0 0 0 0 1 1 0 0 0 1 0 1 1 0 0 1] [0 1 0 0 0 1 0 1 0 1 1 1 0 1 0 1 1 1 1 0] [0 1 0 0 0 0 1 1 0 1 1 0 0 1 1 1 1 1 1 1] [0 0 0 0 0 0 0 1 0 0 0 0 0 1 1 1 1 0 0 0] [3 0 3 0 4 0 0 0 0 0 0 5 0 0 0 1 0 1 1 0] [0 3 3 0 4 0 6 0 7 7 0 0 5 0 0 0 0 0 1 1]]
同样的我们可以看看此时得到的新的图像:
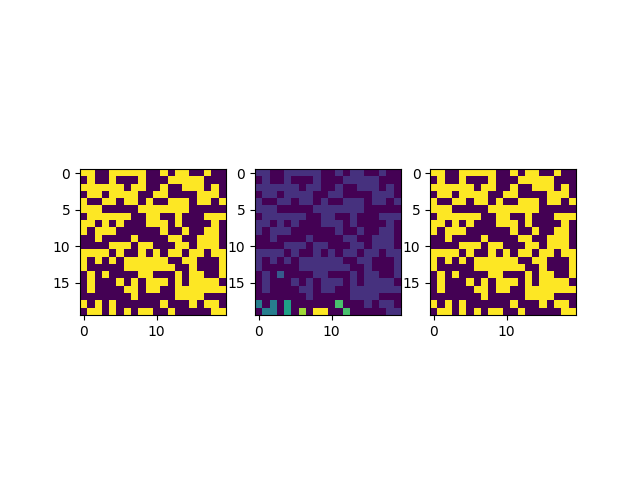
这里我们并列的画了三张图,第一张图是原图,第二张图是划分好区域和标签的图,第三张是对第二张图进行二元化的结果,以确保在运算过程中没有丢失原本的信息。经过确认这个标签的结果划分是正确的,但是因为涉及到一些算法实现的细节,这里我们还是需要展开来介绍一下。
算法的执行流程
if __name__ == "__main__":
np.random.seed(1)
graph = np.random.choice([0,1],size=(20,20))
graph_1, idx_dict = first_pass(graph)
idx_dict = remap(idx_dict)
graph_2 = second_pass(graph_1, idx_dict)
graph_3 = flatten(graph_2)
这个部分是算法的核心框架,在本文中的算法实现流程为:先用first_pass遍历一遍网格节点,按照上一个章节中介绍的Two-Pass算法打上标签,并获得一个映射关系;然后用remap将上面得到的映射关系做一个重映射,确保每一个级别的映射都对应到了最根部(可以联系参考链接1的内容进行理解,虽然这里没有使用Union的数据结构,但是本质上还是一个树形的结构,需要做一个重映射);然后用second_pass执行Two-Pass算法的第二次遍历,得到一组打上了新的独立标签的网格节点;最后需要用flatten将标签进行压平,因为前面映射的关系,有可能导致标签不连续,所以我们这里又做了一次映射,确保标签是连续变化的,实际应用中可以不使用这一步。
标签的重映射
关于节点的遍历,大家可以直接看算法代码,这里需要额外讲解的是标签的重映射模块的代码:
def remap(idx_dict) -> dict:
index_dict = deepcopy(idx_dict)
for id in idx_dict:
idv = idx_dict[id]
while idv in idx_dict:
if idv == idx_dict[idv]:
break
idv = idx_dict[idv]
index_dict[id] = idv
return index_dict
这里的算法是先对得到的标签进行遍历,在字典中获取当前标索引所对应的值,作为新的索引,直到键跟值一致为止,相当于在一个树形的数据结构中重复寻找父节点直到找到根节点。
其他的测试用例
这里我们可以再额外测试一些案例,比如增加几个0元素使得网格节点更加稀疏:
graph = np.random.choice([0,0,0,1],size=(20,20))
得到的结果图片如下所示:

还可以再稀疏一些:
graph = np.random.choice([0,0,0,0,0,1],size=(20,20))
得到的结果如下图所示:

越是稀疏的图,得到的分组结果就越分散。
总结概要
在本文中我们主要介绍了利用Two-Pass的算法来检测区域连通性,并给出了Python3的代码实现,当然在实现的过程中因为没有使用到Union这样的数据结构,仅仅用了字典来存储标签之间的关系,因此效率和代码可读性都会低一些,单纯作为用例的演示和小规模区域划分的计算是足够用了。在该代码实现方案中,还有一点与原始算法不一致的是,本实现方案中打新的标签是读取上、上左和左三个方向的格点,但是存储标签的映射关系时,是读取了上、上左、上右和左这四个方向的格点。
参考链接
- https://blog.csdn.net/lichengyu/article/details/13986521
- https://www.cnblogs.com/riddick/p/8280883.html
到此这篇关于运用Python3实现Two-Pass算法检测区域连通性的文章就介绍到这了,更多相关Python3实现Two-Pass算法检测区域流通内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python3基础语法知识点总结
本章节将一些Python3基础语法整理成手册,方便各位在日常使用和学习是查阅,包含了编码.标识符.保留字.注释.缩进.字符串等常用内容. 编码 默认情况下,Python 3 源码文件以 UTF-8 编码,所有字符串都是 unicode 字符串. 当然你也可以为源码文件指定不同的编码: #*- coding: cp-1252*- 标识符 第一个字符必须是字母表中字母或下划线'_'. 标识符的其他的部分有字母.数字和下划线组成. 标识符对大小写敏感. 在 Python 3中,非ASCII 编码的标识
-

运用Python3实现Two-Pass算法检测区域连通性
目录 技术背景 Two-Pass算法 测试数据的生成 Two-Pass算法的实现 算法的执行流程 标签的重映射 其他的测试用例 总结概要 参考链接 技术背景 连通性检测是图论中常常遇到的一个问题,我们可以用五子棋的思路来理解这个问题五子棋中,横.竖.斜相邻的两个棋子,被认为是相连接的,而一样的道理,在一个二维的图中,只要在横.竖.斜三个方向中的一个存在相邻的情况,就可以认为图上相连通的.比如以下案例中的python数组,3号元素和5号元素就是相连接的,5号元素和6号元素也是相连接的,因此这三个元
-
Python利用Canny算法检测硬币边缘
目录 一.问题背景 二.Canny 算法 (一).高斯平滑 (二)Sobel算子计算梯度 (三)非极大化抑制 (四)滞后边缘跟踪 一.问题背景 纸面上有一枚一元钱的银币,你能在 Canny 和 Hough 的帮助下找到它的坐标方程吗? 确定一个圆的坐标方程,首先我们要检测到其边缘,然后求出其在纸面上的相对位置以及半径大小. 在这篇文章中我们使用 Canny 算法来检测出纸面上银币的边缘. 二.Canny 算法 Canny 可以用于拿到图像中物体的边缘,其步骤如下 进行高斯平滑 计算图像梯度(记录
-
Unity实现攻击范围检测并绘制检测区域
本文实例为大家分享了Unity实现攻击范围检测并绘制检测区域的具体代码,供大家参考,具体内容如下 一.圆形检测 using System.Collections; using System.Collections.Generic; using UnityEngine; /// <summary> /// 圆形检测,并绘制出运行的攻击范围 /// </summary> public class CircleDetect : MonoBehaviour { GameObject go;
-
Python OpenCV基于霍夫圈变换算法检测图像中的圆形
目录 第一章:霍夫变换检测圆 ① 实例演示1 ② 实例演示2 ③ 霍夫变换函数解析 第二章:Python + opencv 完整检测代码 ① 源代码 ② 运行效果图 第一章:霍夫变换检测圆 ① 实例演示1 这个是设定半径范围 0-50 后的效果. ② 实例演示2 这个是设定半径范围 50-70 后的效果,因为原图稍微大一点,半径也大了一些. ③ 霍夫变换函数解析 cv.HoughCircles() 方法 参数分别为:image.method.dp.minDist.param1.param2.mi
-
用Python实现通过哈希算法检测图片重复的教程
Iconfinder 是一个图标搜索引擎,为设计师.开发者和其他创意工作者提供精美图标,目前托管超过 34 万枚图标,是全球最大的付费图标库.用户也可以在 Iconfinder 的交易板块上传出售原创作品.每个月都有成千上万的图标上传到Iconfinder,同时也伴随而来大量的盗版图.Iconfinder 工程师 Silviu Tantos 在本文中提出一个新颖巧妙的图像查重技术,以杜绝盗版. 我们将在未来几周之内推出一个检测上传图标是否重复的功能.例如,如果用户下载了一个图标然后又试图通过上传
-
人脸检测中AdaBoost算法详解
人脸检测中的AdaBoost算法,供大家参考,具体内容如下 第一章:引言 2017.7.31.英国测试人脸识别技术,不需要排队购票就能刷脸进站.据BBC新闻报道,这项英国政府铁路安全标准委员会资助的新技术,由布里斯托机器人实验室(Bristol Robotics Laboratory) 负责开发.这个报道可能意味着我们将来的生活方式.虽然人脸识别技术已经研究了很多年了,比较成熟了,但是还远远不够,我们以后的目标是通过识别面部表情来获得人类心理想法. 长期以来,计算机就好像一个盲人,需要
-
python 实现Harris角点检测算法
算法流程: 将图像转换为灰度图像 利用Sobel滤波器求出 海森矩阵 (Hessian matrix) : 将高斯滤波器分别作用于Ix².Iy².IxIy 计算每个像素的 R= det(H) - k(trace(H))².det(H)表示矩阵H的行列式,trace表示矩阵H的迹.通常k的取值范围为[0.04,0.16]. 满足 R>=max(R) * th 的像素点即为角点.th常取0.1. Harris算法实现: import cv2 as cv import numpy as np impo
-
opencv实现机器视觉检测和计数的方法
引言 在机器视觉中,有时需要对产品进行检测和计数.其难点无非是对于产品的图像分割. 由于之前网购的维生素片,有时候忘了今天有没有吃过,就想对瓶子里的药片计数...在学习opencv以后,希望实现对于维生素片分割计数算法.本次实战在基于形态学的基础上又衍生出基于距离变换的分水岭算法,使其实现的效果更具普遍性. 基于形态学的维生素片检测和计数 整体思路: 读取图片 形态学处理(在二值化前进行适度形态学处理,效果俱佳) 二值化 提取轮廓(进行药片分割) 获取轮廓索引,并筛选所需要的轮廓 画出轮廓,显示
-
opencv canny边缘检测算法详解
目录 一.边缘检测原理 二.canny算法原理 三.opencv函数支持Canny() 四.代码示例: 一.边缘检测原理 图像的边缘由图像中两个相邻的区域之间的像素集合组成,是指图像中一个区域的结束和另外一个区域的开始.也可以这么理解,图像边缘就是图像中灰度值发生空间突变的像素的集合.梯度方向和幅度是图像边缘的两个性质,沿着跟边缘垂直的的方向,像素值的变化幅度比较平缓:而沿着与边缘平行的方向,则像素值变化幅度变化比较大.于是,根据该变化特性,通常会采用计算一阶或者二阶导数的方法来描述和检测图像边
-
Python3实现生成随机密码的方法
本文实例讲述了Python3实现生成随机密码的方法,在Python程序设计中有着广泛的实用价值.具体方法如下: 本文实例主要实现创建8位随机密码(大小写字母+数字),采用Python3生成了初级算法的随机密码. 主要功能代码如下: __author__ = 'Goopand' import string import random def genPassword(length=8,chars=string.digits+string.ascii_letters): return ''.join(