Python代码实现粒子群算法图文详解
目录
- 1.引言
- 2.算法的具体描述:
- 2.1原理
- 2.2标准粒子群算法流程
- 3.代码案例
- 3.1问题
- 3.2绘图
- 3.3计算适应度
- 3.4更新速度
- 3.5更新粒子位置
- 3.6主要算法过程
- 结果
- 总结
1.引言
粒子群优化算法起源于对鸟群觅食活动的分析。鸟群在觅食的时候通常会毫无征兆的聚拢,分散,以及改变飞行的轨迹,但是在不同个体之间会十分默契的保持距离。所以粒子群优化算法模拟鸟类觅食的过程,将待求解问题的搜索空间看作是鸟类飞行的空间,将每只鸟抽象成一个没有质量和大小的粒子,用这个粒子来表示待求解问题的一个可行解。所以,寻找最优解的过程就相当于鸟类觅食的过程。
粒子群算法也是基于种群以及进化的概念,通过个体间的竞争与协作,实现复杂空间最优解的求解。但是与遗传算法不同的是,他不会对每个个体进行“交叉”,“变异”等操作,而实以一定的规则,更新每个粒子的速度以及位置,使得每一个粒子向自身历史最佳位置以及全局历史最佳位置进行移动,从而实现整个种群向着最优的方向进化。
2.算法的具体描述:
2.1原理
在粒子群优化算法中,粒子之间通过信息共享机制,获得其它粒子的发现与飞行经历。粒子群算法中的信息共享机制实际上是一种合作共生的行为,在搜索最优解的过程中,每个粒子能够对自己经过的最佳的历史位置进行记忆,同时,每个粒子的行为有会受到群体中其他例子的影响,所以在搜索最优解的过程中,粒子的行为既受其他粒子的影响,有受到自身经验的指导。
粒子群优化算法对于鸟群的模拟是按照如下的模式进行的:假设一群鸟在空中搜索食物,所有鸟知道自己当前距离食物有多远(这里的远近会用一个值来衡量,适应度值),那么每只鸟最简单的搜索策略就是寻找距离目前距离食物最近的鸟的周围空间。因此,在粒子群算法中,每个粒子都相当于一只鸟,每个粒子有一个适应度值,还有一个速度决定他们的飞行的距离与方向。所有的粒子追随当前最优的粒子在解空间中搜索。每搜索一次,最优的粒子会发生变化,其他的粒子又会追随新的最优粒子进行搜索,如此反复迭代。
在迭代开始的时候,每个粒子通过随机的方式初始化在空间中的速度和位置,然后在迭代过程中,粒子通过跟踪两个极值来自己在解空间中的位置和速度,一个极值是单个粒子自身在迭代的过程中的最优位置(就是最优适应度值所对应的空间解),这个称之为粒子的个体极值。另一个极值是种群中所有的粒子在迭代过程中所找到的最优位置,这个成为全局极值。如果粒子只是跟踪一个极值的话,则算法称为局部粒子群算法或者全局粒子群算法。
PSO从这种模型中得到启示并用于解决优化问题。PSO 中,每个优化问题的潜在解都是搜索空间中的一只鸟,称之为粒子。所有的粒子都有一个由被优化的函数决定的适值( fitness value) ,每个粒子还有一个速度决定它们飞翔的方向和距离。然后粒子们就追随当前的最优粒子在解空间中搜索。
PSO初始化为一群随机粒子(随机解),然后通过迭代找到最优解。在每一次迭代中,粒子通过跟踪两个极值来更新自己;第一个就是粒子本身所找到的最优解,这个解称为个体极值;另一个极值是整个种群目前找到的最优解,这个极值是全局极值。另外也可以不用整个种群而只是用其中一部分作为粒子的邻居,那么在所有邻居中的极值就是局部极值。

图解:

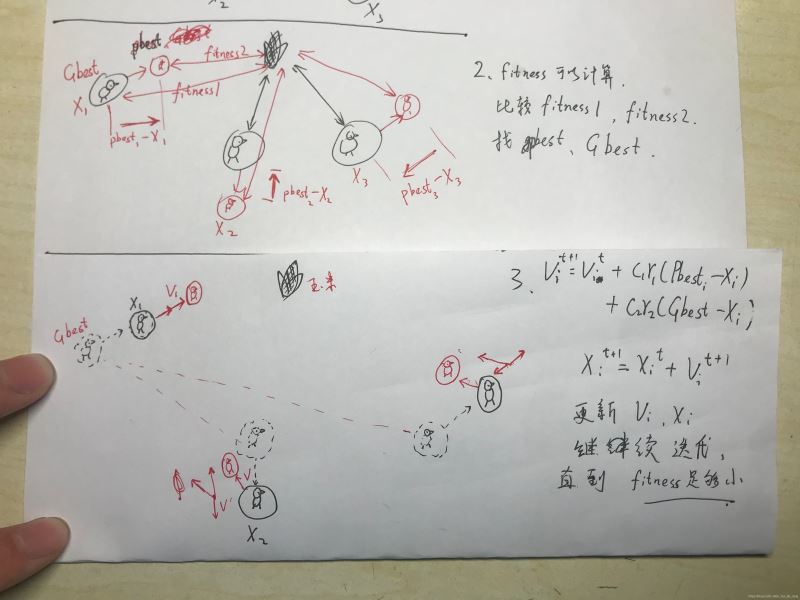
2.2标准粒子群算法流程
算法的流程如下:
Step1:种群初始化:可以进行随机初始化或根据被优化的问题设计特定的初始化方法,包括群体规模,每个粒子的位置 X i X_{i} Xi 和速度 V i V_i Vi ,然后计算每个粒子的适应度值,从而选择出个体的局部最优位置向量和种群的全局最优位置向量。
Step2:迭代设置:设置迭代次数 g m a x g_{max} gmax ,令当前迭代次数g=1。
Step3:根据公式更新每个粒子的速度向量V。
Step4:根据公式更新每个粒子的位置向量X。
Step5:局部位置向量和全局位置向量更新:更新每个粒子的Pbest,和种群的Gbest。
Step6:终止条件判断:判断迭代次数时都达到 g m a x g_{max} gmax 或误差是否足够小,如果满足则输出Gbest.否则继续进行迭代,跳转至步骤(3)。
对于粒子群优化算法的实际应用,因为主要是对速度和位置向量迭代算子的设计计,选代算子是否合理将决定整个PSO算法性能的优劣.,所以如何设计 t pso的迭代算子是算法应用的研究重点和难点。

3.代码案例
3.1问题
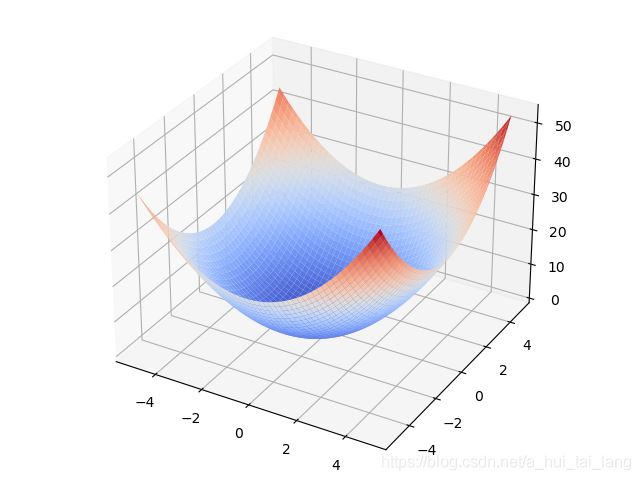
求解f(x,y)的最小值点

3.2绘图
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot3d import Axes3D # 生成X和Y的数据 X=np.arange(-5,5,0.1) Y=np.arange(-5,5,0.1) X,Y=np.meshgrid(X,Y) # 目标函数 Z=X**2+Y**2+X # 绘图 fig=plt.figure() ax=Axes3D(fig) surf=ax.plot_surface(X,Y,Z,cmap=cm.coolwarm) plt.show()
3.3计算适应度
# 速度
# Vi+1 = w*Vi + c1 * r1 * (pbest_i - Xi) + c2 * r2 * (gbest_i - Xi)
# 位置
# Xi+1 = Xi + Vi+1
# vi, xi 分别表示粒子第i维的速度和位置
# pbest_i, gbest_i 分别表示某个粒子最好位置第i维的值、整个种群最好位置第i维的值
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
def fitness_func(X):
"""计算粒子的的适应度值,也就是目标函数值,X 的维度是 size * 2 """
A = 10
pi = np.pi
x = X[:, 0]
y = X[:, 1]
return x**2+y**2+x
3.4更新速度
def velocity_update(V, X, pbest, gbest, c1, c2, w, max_val):
"""
根据速度更新公式更新每个粒子的速度
:param V: 粒子当前的速度矩阵,20*2 的矩阵
:param X: 粒子当前的位置矩阵,20*2 的矩阵
:param pbest: 每个粒子历史最优位置,20*2 的矩阵
:param gbest: 种群历史最优位置,1*2 的矩阵
"""
size = X.shape[0]
r1 = np.random.random((size, 1))
r2 = np.random.random((size, 1))
V = w*V+c1*r1*(pbest-X)+c2*r2*(gbest-X)
# 防止越界处理
V[V < -max_val] = -max_val
V[V > -max_val] = max_val
return V
3.5更新粒子位置
def position_update(X, V):
"""
根据公式更新粒子的位置
:param X: 粒子当前的位置矩阵,维度是 20*2
:param V: 粒子当前的速度举着,维度是 20*2
"""
return X+V
3.6主要算法过程
def pos():
w = 1
c1 = 2
c2 = 2
r1 = None
r2 = None
dim = 2
size = 20
iter_num = 1000
max_val = 0.5
best_fitness = float(9e10)
fitness_val_list = []
# 初始化种群各个粒子的位置
X = np.random.uniform(-5, 5, size=(size, dim))
# 初始化各个粒子的速度
V = np.random.uniform(-0.5, 0.5, size=(size, dim))
# print(X)
p_fitness = fitness_func(X)
g_fitness = p_fitness.min()
fitness_val_list.append(g_fitness)
# 初始化的个体最优位置和种群最优位置
pbest = X
gbest = X[p_fitness.argmin()]
# 迭代计算
for i in range(1, iter_num):
V = velocity_update(V, X, pbest, gbest, c1, c2, w, max_val)
X = position_update(X, V)
p_fitness2 = fitness_func(X)
g_fitness2 = p_fitness2.min()
# 更新每个粒子的历史最优位置
for j in range(size):
if p_fitness[j] > p_fitness2[j]:
pbest[j] = X[j]
p_fitness[j] = p_fitness2[j]
# 更新群体的最优位置
if g_fitness > g_fitness2:
gbest = X[p_fitness2.argmin()]
g_fitness = g_fitness2
# 记录最优迭代记录
fitness_val_list.append(g_fitness)
i += 1
# 输出迭代结果
print("最优值是:%.5f" % fitness_val_list[-1])
print("最优解是:x=%.5f,y=%.5f" % (gbest[0], gbest[1]))
# 绘图
plt.plot(fitness_val_list, color='r')
plt.title('迭代过程')
plt.show()
pos()
结果
最优值是:-0.23696
最优解是:x=-0.54359,y=-0.10555

参考:
苏振裕.《Python最优化实战》[M].北京大学出版社
总结
本篇文章就到这里了,希望能给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-

Python编程实现粒子群算法(PSO)详解
1 原理 粒子群算法是群智能一种,是基于对鸟群觅食行为的研究和模拟而来的.假设在鸟群觅食范围,只在一个地方有食物,所有鸟儿看不到食物(不知道食物的具体位置),但是能闻到食物的味道(能知道食物距离自己位置).最好的策略就是结合自己的经验在距离鸟群中距离食物最近的区域搜索. 利用粒子群算法解决实际问题本质上就是利用粒子群算法求解函数的最值.因此需要事先把实际问题抽象为一个数学函数,称之为适应度函数.在粒子群算法中,每只鸟都可以看成是问题的一个解,这里我们通常把鸟称之为粒子,每个粒子都拥有: 位置,可
-
python实现粒子群算法
粒子群算法 粒子群算法源于复杂适应系统(Complex Adaptive System,CAS).CAS理论于1994年正式提出,CAS中的成员称为主体.比如研究鸟群系统,每个鸟在这个系统中就称为主体.主体有适应性,它能够与环境及其他的主体进行交流,并且根据交流的过程"学习"或"积累经验"改变自身结构与行为.整个系统的演变或进化包括:新层次的产生(小鸟的出生):分化和多样性的出现(鸟群中的鸟分成许多小的群):新的主题的出现(鸟寻找食物过程中,不断发现新的食物). P
-
python3实现单目标粒子群算法
本文实例为大家分享了python3单目标粒子群算法的具体代码,供大家参考,具体内容如下 关于PSO的基本知识......就说一下算法流程 1) 初始化粒子群: 随机设置各粒子的位置和速度,默认粒子的初始位置为粒子最优位置,并根据所有粒子最优位置,选取群体最优位置. 2) 判断是否达到迭代次数: 若没有达到,则跳转到步骤3).否则,直接输出结果. 3) 更新所有粒子的位置和速度: 4) 计算各粒子的适应度值. 将粒子当前位置的适应度值与粒子最优位置的适应度值进行比较,决定是否更新粒子最优位置:将所
-
Python实现粒子群算法的示例
粒子群算法是一种基于鸟类觅食开发出来的优化算法,它是从随机解出发,通过迭代寻找最优解,通过适应度来评价解的品质. PSO算法的搜索性能取决于其全局探索和局部细化的平衡,这在很大程度上依赖于算法的控制参数,包括粒子群初始化.惯性因子w.最大飞翔速度和加速常数与等. PSO算法具有以下优点: 不依赖于问题信息,采用实数求解,算法通用性强. 需要调整的参数少,原理简单,容易实现,这是PSO算法的最大优点. 协同搜索,同时利用个体局部信息和群体全局信息指导搜索. 收敛速度快, 算法对计算机内存和CPU要
-
Python代码实现粒子群算法图文详解
目录 1.引言 2.算法的具体描述: 2.1原理 2.2标准粒子群算法流程 3.代码案例 3.1问题 3.2绘图 3.3计算适应度 3.4更新速度 3.5更新粒子位置 3.6主要算法过程 结果 总结 1.引言 粒子群优化算法起源于对鸟群觅食活动的分析.鸟群在觅食的时候通常会毫无征兆的聚拢,分散,以及改变飞行的轨迹,但是在不同个体之间会十分默契的保持距离.所以粒子群优化算法模拟鸟类觅食的过程,将待求解问题的搜索空间看作是鸟类飞行的空间,将每只鸟抽象成一个没有质量和大小的粒子,用这个粒子来表示待求解
-
Python 十大经典排序算法实现详解
目录 关于时间复杂度 关于稳定性 名词解释 1.冒泡排序 (1)算法步骤 (2)动图演示 (3)Python代码 2.选择排序 (1)算法步骤 (2)动图演示 (3)Python代码 3.插入排序 (1)算法步骤 (2)动图演示 (3)Python代码 4.希尔排序 (1)算法步骤 (2)Python代码 5.归并排序 (1)算法步骤 (2)动图演示 (3)Python代码 6.快速排序 (1)算法步骤 (2)动图演示 (3)Python代码 7.堆排序 (1)算法步骤 (2)动图演示 (3)P
-
Python 开发工具PyCharm安装教程图文详解(新手必看)
PyCharm是由JetBrains打造的一款Python IDE,VS2010的重构插件Resharper就是出自JetBrains之手. 同时支持Google App Engine,PyCharm支持IronPython.这些功能在先进代码分析程序的支持下,使 PyCharm 成为 Python 专业开发人员和刚起步人员使用的有力工具. PyCharm是一种Python IDE,带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试.语法高亮.Project管理.代码跳
-
通俗易懂的C++前缀和与差分算法图文详解
目录 1.前缀和 2.前缀和算法有什么好处? 3.二维前缀和 4.差分 5.一维差分 6.二维差分 1.前缀和 前缀和是指某序列的前n项和,可以把它理解为数学上的数列的前n项和,而差分可以看成前缀和的逆运算.合理的使用前缀和与差分,可以将某些复杂的问题简单化. 2.前缀和算法有什么好处? 先来了解这样一个问题: 输入一个长度为n的整数序列.接下来再输入m个询问,每个询问输入一对l, r.对于每个询问,输出原序列中从第l个数到第r个数的和. 我们很容易想出暴力解法,遍历区间求和. 代码如下: in
-
Python Django的安装配置教程图文详解
Django 教程 Python下有许多款不同的 Web 框架.Django是重量级选手中最有代表性的一位.许多成功的网站和APP都基于Django. Django是一个开放源代码的Web应用框架,由Python写成. Django遵守BSD版权,初次发布于2005年7月, 并于2008年9月发布了第一个正式版本1.0 . Django采用了MVC的软件设计模式,即模型M,视图V和控制器C. 学习Django前,我们要确定电脑上是否已经安装了Python,目前Python有两个版本,不过这两个版
-
Python代码块及缓存机制原理详解
这篇文章主要介绍了Python代码块及缓存机制原理详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1.相同的字符串在Python中地址相同 s1 = 'panda' s2 = 'panda' print(s1 == s2) #True print(id(s1) == id (s2)) #True 2.代码块: 所有的代码都需要依赖代码块执行. 一个模块,一个函数,一个类,一个文件等都是一个代码块 交互式命令中, 一行就是一个代码块
-
python机器学习Sklearn实战adaboost算法示例详解
目录 pandas批量处理体测成绩 adaboost adaboost原理案例举例 弱分类器合并成强分类器 pandas批量处理体测成绩 import numpy as np import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as plt data = pd.read_excel("/Users/zhucan/Desktop/18级高一体测成绩汇总.xls") cond =
-
vue2从数据变化到视图变化之diff算法图文详解
目录 引言 1.isUndef(oldStartVnode) 2.isUndef(oldEndVnode) 3.sameVnode(oldStartVnode, newStartVnode) 4.sameVnode(oldEndVnode, newEndVnode) 5.sameVnode(oldStartVnode, newEndVnode) 6.sameVnode(oldEndVnode, newStartVnode) 7.如果以上都不满足 小结 引言 vue数据的渲染会引入视图的重新渲染.
-
IDEA安装阿里代码规范插件的步骤图文详解
要养成一个好的编码习惯从自己编码开始,对自己代码的合理化命名,编码不仅对自己有好处,而且别人也容易读懂你的代码. 所以下载阿里的代码规范插件来约束自己凌乱的代码. 阿里规范插件GitHub地址:https://github.com/alibaba/p3c IDEA安装该插件步骤: 1.打开IDEA,File-> Setteings->Plugins->Browse Repositories,在Browse Repositories搜索栏搜索Alibaba,然后安装 2.安装完后点击