Python统计文本词汇出现次数的实例代码
问题描述
有时在遇到一个文本需要统计文本内词汇的次数 的时候 ,可以用一个简单的python程序来实现。
解决方案
首先需要的是一个文本文件(.txt)格式(文本内词汇以空格分隔),因为需要的是一个程序,所以要考虑如何将文件打开而不是采用复制粘贴的方式。这时就要用到open()的方式来打开文档,然后通过read()读取其中内容,再将词汇作为key,出现次数作为values存入字典。

图 1 txt文件内容
再通过open和read函数来读取文件:
open_file=open("text.txt")
file_txt=open_file.read()
然后再创建一个空字典,将所有出现的每个词汇作为key保存到字典中,对文本从开始到结束,循环处理每个词汇,并将词汇设置为一个字典的key,将其value设置为1,如果已经存在该词汇的key,说明该词汇已经使用过,就将value累积加1。
代码示例:
def wordcount(readtxt):
readlist = readtxt.split()
dict1={}
for every_world in readlist:
if every_world in dict1:
dict1[every_world] += 1
else:
dict1[every_world] = 1
return dict1
print(wordcount(file_txt))
这里加了def函数把该程序封装成一个函数。
最后输出得到词汇出现的字典:
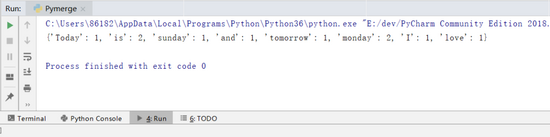
图 2 形成字典
ps:下面看下python统计文本中每个单词出现的次数
1.python统计文本中每个单词出现的次数:
#coding=utf-8
__author__ = 'zcg'
import collections
import os
with open('abc.txt') as file1:#打开文本文件
str1=file1.read().split(' ')#将文章按照空格划分开
print "原文本:\n %s"% str1
print "\n各单词出现的次数:\n %s" % collections.Counter(str1)
print collections.Counter(str1)['a']#以字典的形式存储,每个字符对应的键值就是在文本中出现的次数
2.python编写生成序列化:
__author__ = 'zcg' #endcoding utf-8 import string,random field=string.letters+string.digits def getRandom(): return "".join(random.sample(field,4)) def concatenate(group): return "-".join([getRandom() for i in range(group)]) def generate(n): return [concatenate(4) for i in range(n)] if __name__ =='__main__': print generate(10)
3.遍历excel表格中的所有数据:
__author__ = 'Administrator'
import xlrd
workbook = xlrd.open_workbook('config.xlsx')
print "There are {} sheets in the workbook".format(workbook.nsheets)
for booksheet in workbook.sheets():
for col in xrange(booksheet.ncols):
for row in xrange(booksheet.nrows):
value=booksheet.cell(row,col).value
print value
其中xlrd需要百度下载导入这个模块到python中
4.将表格中的数据整理成lua类型的一个格式
#coding=utf-8
__author__ = 'zcg'
#2017 9/26
import xlrd
fileOutput = open('Configs.lua','w')
writeData="--@author:zcg\n\n\n"
workbook = xlrd.open_workbook('config.xlsx')
print "There are {} sheets in the workbook".format(workbook.nsheets)
for booksheet in workbook.sheets():
writeData = writeData+'AT' +booksheet.name+' ={\n'
for col in xrange(booksheet.ncols):
for row in xrange(booksheet.nrows):
value = booksheet.cell(row,col).value
if row ==0:
writeData = writeData+'\t'+'["'+value+'"]'+'='+'{'
else:
writeData=writeData+'"'+str(booksheet.cell(row,col).value)+'", '
else:
writeData=writeData+'},\n'
else:
writeData=writeData+'}\n\n'
else :
fileOutput.write(writeData)
fileOutput.close()
总结
到此这篇关于Python统计文本词汇出现次数的实例代码的文章就介绍到这了,更多相关Python统计文本词汇出现次数内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python统计字符串中指定字符出现次数的方法
本文实例讲述了python统计字符串中指定字符出现次数的方法.分享给大家供大家参考.具体如下: python统计字符串中指定字符出现的次数,例如想统计字符串中空格的数量 s = "Count, the number of spaces." print s.count(" ") x = "I like to program in Python" print x.count("i") PS:本站还提供了一个关于字符统计的工具,感兴
-
Python统计列表中的重复项出现的次数的方法
本文实例展示了Python统计列表中的重复项出现的次数的方法,是一个很实用的功能,适合Python初学者学习借鉴.具体方法如下: 对一个列表,比如[1,2,2,2,2,3,3,3,4,4,4,4],现在我们需要统计这个列表里的重复项,并且重复了几次也要统计出来. 方法1: mylist = [1,2,2,2,2,3,3,3,4,4,4,4] myset = set(mylist) #myset是另外一个列表,里面的内容是mylist里面的无重复 项 for item in myset: prin
-
Python统计单词出现的次数
题目: 统计一个文件中每个单词出现的次数,列出出现频率最多的5个单词. 前言: 这道题在实际应用场景中使用比较广泛,比如统计历年来四六级考试中出现的高频词汇,记得李笑来就利用他的编程技能出版过一本背单词的畅销书,就是根据词频来记单词,深受学生喜欢.这就是一个把编程技能用来解决实际问题的典型场景.另外,在数据分析时,那些词云效果本质上都是基于词频统计来调整字体的大小,如果你能熟练运用Python中的知识来解决问题的话,说明你真的入门Python了. 分析 本题主要考察以下几个方面的知识点: 1.如
-
Python统计日志中每个IP出现次数的方法
本文实例讲述了Python统计日志中每个IP出现次数的方法.分享给大家供大家参考.具体如下: 这脚本可用于多种日志类型,本人测试MDaemon的all日志文件大小1.23G左右,分析用时2~3分钟 代码很简单,很适合运维人员,有不足的地方请大家指出哦 #-*- coding:utf-8 -*- import re,time def mail_log(file_path): global count log=open(file_path,'r') C=r'\.'.join([r'\d{1,3}']
-
python脚本实现统计日志文件中的ip访问次数代码分享
适用的日志格式: 106.45.185.214 - - [06/Aug/2014:07:38:59 +0800] "GET / HTTP/1.0" 200 10 "-" "-" 171.104.119.22 - - [06/Aug/2014:08:55:01 +0800] "GET / HTTP/1.0" 200 10 "-" "-" 27.31.238.242 - - [06/Aug/
-
Python统计文本词汇出现次数的实例代码
问题描述 有时在遇到一个文本需要统计文本内词汇的次数 的时候 ,可以用一个简单的python程序来实现. 解决方案 首先需要的是一个文本文件(.txt)格式(文本内词汇以空格分隔),因为需要的是一个程序,所以要考虑如何将文件打开而不是采用复制粘贴的方式.这时就要用到open()的方式来打开文档,然后通过read()读取其中内容,再将词汇作为key,出现次数作为values存入字典. 图 1 txt文件内容 再通过open和read函数来读取文件: open_file=open("text.txt
-
python统计文本字符串里单词出现频率的方法
本文实例讲述了python统计文本字符串里单词出现频率的方法.分享给大家供大家参考.具体实现方法如下: # word frequency in a text # tested with Python24 vegaseat 25aug2005 # Chinese wisdom ... str1 = """Man who run in front of car, get tired. Man who run behind car, get exhausted."&quo
-
python在文本开头插入一行的实例
问题 对于一个文本文件,需要在起开头插入一行,其他内容不变 解决方法 with open('article.txt', 'r+') as f: content = f.read() f.seek(0, 0) f.write('writer:Fatsheep\n'+content) 其中字符串'writer:Fatsheep\n'中为要插入的内容. 效果 运行代码后: 注意 f.seek(0, 0)不可或缺,file.seek(off, whence=0)在文件中移动文件指针, 从 whence
-
Python统计列表元素出现次数的方法示例
1. 引言 在使用Python的时候,通常会出现如下场景: array = [1, 2, 3, 3, 2, 1, 0, 2] 获取array中元素的出现次数 比如,上述列表中:0出现了1次,1出现了2次,2出现了3次,3出现了2次. 本文阐述了Python获取元素出现次数的几种方法.点击获取完整代码. 2. 方法 获取元素出现次数的方法较多,这里我提出如下5个方法,谨供参考.下面的代码,传入的参数均为 array = [1, 2, 3, 3, 2, 1, 0, 2] 2.1 Counter方法
-

Python+tkinter模拟“记住我”自动登录实例代码
本文分享的代码主要是通过Python+tkinter模拟"记住我"自动登录的功能,具体介绍如下. 基本思路:如果某次登录成功,则创建临时文件记录有关信息,每次启动程序时尝试自动获取上次登录成功的信息并自动编写.本文主要演示思路,可根据实际系统中的需要进行改写,例如读取数据库并验证用户名和密码是否正确.对用户名和密码进行本地加密存储等等. import tkinter import tkinter.messagebox import os import os.path # 获取Windo
-
实时监控文本框输入字数的实例代码
需求:实时监控文本输入框的字数,并加以限制 1.实时监控当前输入字数,直接使用onkeyup事件方法,给输入框加maxlength属性限制长度.如: <div> <textarea id="txt" maxlength="10"></textarea> <p><span id="txtNum">0</span>/10</p> </div> var tx
-
python批量替换页眉页脚实例代码
简介 本文分享的实例代码主要通过python语言实现批量替换页眉页脚的操作功能,具体如下. 代码 #!/usr/bin/env python # -*- coding: utf-8 -*- import win32com,os,sys,re from win32com.client import Dispatch, constants # 打开新的文件 suoyou = os.listdir('d:\\daizhuan') #print suoyou for i in suoyou: wenji
-
Python找出最小的K个数实例代码
题目描述 输入n个整数,找出其中最小的K个数.例如输入4,5,1,6,2,7,3,8这8个数字,则最小的4个数字是1,2,3,4,. 这个题目完成的思路有很多,很多排序算法都可以完成既定操作,关键是复杂度性的考虑.以下几种思路当是笔者抛砖引玉,如果读者有兴趣可以自己再使用其他方法一一尝试. 思路1:利用冒泡法 临近的数字两两进行比较,按照从小到大的顺序进行交换,如果前面的值比后面的大,则交换顺序.这样一趟过去后,最小的数字被交换到了第一位:然后是次小的交换到了第二位,...,依次直到第k个数,停
-
Python使用requests及BeautifulSoup构建爬虫实例代码
本文研究的主要是Python使用requests及BeautifulSoup构建一个网络爬虫,具体步骤如下. 功能说明 在Python下面可使用requests模块请求某个url获取响应的html文件,接着使用BeautifulSoup解析某个html. 案例 假设我要http://maoyan.com/board/4猫眼电影的top100电影的相关信息,如下截图: 获取电影的标题及url. 安装requests和BeautifulSoup 使用pip工具安装这两个工具. pip install