Golang爬虫框架 colly的使用
目录
- 项目特性
- 安装colly
- 实例
- colly 的配置
- colly页面爬取和解析
- colly框架重构爬虫
Golang爬虫框架 colly 简介
colly是一个采用Go语言编写的Web爬虫框架,旨在提供一个能够些任何爬虫/采集器/蜘蛛的简介模板,通过Colly。你可以轻松的从网站提取结构化数据,然后进行数据挖掘,处理或归档
项目特性
- 清晰明了的API
- 速度快(每个内核上的请求数大于1K)
- 管理每个域的请求延迟和最大并发数
- 自动cookie和会话处理
- 同步/异步/ 并行抓取
- 高速缓存
- 自动处理非Unicode编码
- 支持Robots.txt
- 支持Google App Engine
- 通过环境变量进行配置
- 可拓展
安装colly
go get -u github.com/gocolly/colly
第一个colly 应用
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector()
// goquery selector class
c.OnHTML(".sidebar_link", func(e *colly.HTMLElement) {
e.Request.Visit(e.Attr("href"))
/* link := e.Attr("href")
// Print link
fmt.Printf("Link found: %q -> %s\n", e.Text, link)
// Visit link found on page
// Only those links are visited which are in AllowedDomains
c.Visit(e.Request.AbsoluteURL(link))*/
})
c.OnRequest(func(r *colly.Request) {
fmt.Println("url:",r.URL)
})
c.Visit("https://gorm.io/zh_CN/docs/")
}
回调函数的调用顺序
- OnRequest 在请求之前调用
- OnError 如果请求期间发生错误,则调用
- OnResponseHeaders 在收到响应标头后调用
- OnResponse 收到回复后调用
- OnHTML OnResponse如果接收到的内容是HTML ,则在此之后立即调用
- OnXML OnHTML如果接收到的内容是HTML或XML ,则在之后调用
- OnScraped 在OnXML回调之后调用
实例
func collback() { // 添加回调 收集器
c:= colly.NewCollector()
c.OnRequest(func(r *colly.Request) {
fmt.Println("请求前调用:OnRequest")
// fmt.Println("Visiting", r.URL)
})
c.OnError(func(_ *colly.Response, err error) {
fmt.Println("发生错误调用:OnReOnError")
//log.Println("Something went wrong:", err)
})
/* c.OnResponseHeaders(func(r *colly.Response) { //高版本已经不用了
fmt.Println("Visited", r.Request.URL)
})
*/
c.OnResponse(func(r *colly.Response) {
fmt.Println("获得响应后调用:OnResponse")
//fmt.Println("Visited", r.Request.URL)
})
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
fmt.Println("OnResponse收到html内容后调用:OnHTML")
//e.Request.Visit(e.Attr("href"))
})
/* c.OnHTML("tr td:nth-of-type(1)", func(e *colly.HTMLElement) {
fmt.Println("First column of a table row:", e.Text)
})*/
c.OnXML("//h1", func(e *colly.XMLElement) {
fmt.Println("OnResponse收到xml内容后调用:OnXML")
//fmt.Println(e.Text)
})
c.OnScraped(func(r *colly.Response) {
fmt.Println("结束", r.Request.URL)
})
c.Visit("https://gorm.io/zh_CN/docs/")
}
得到的:
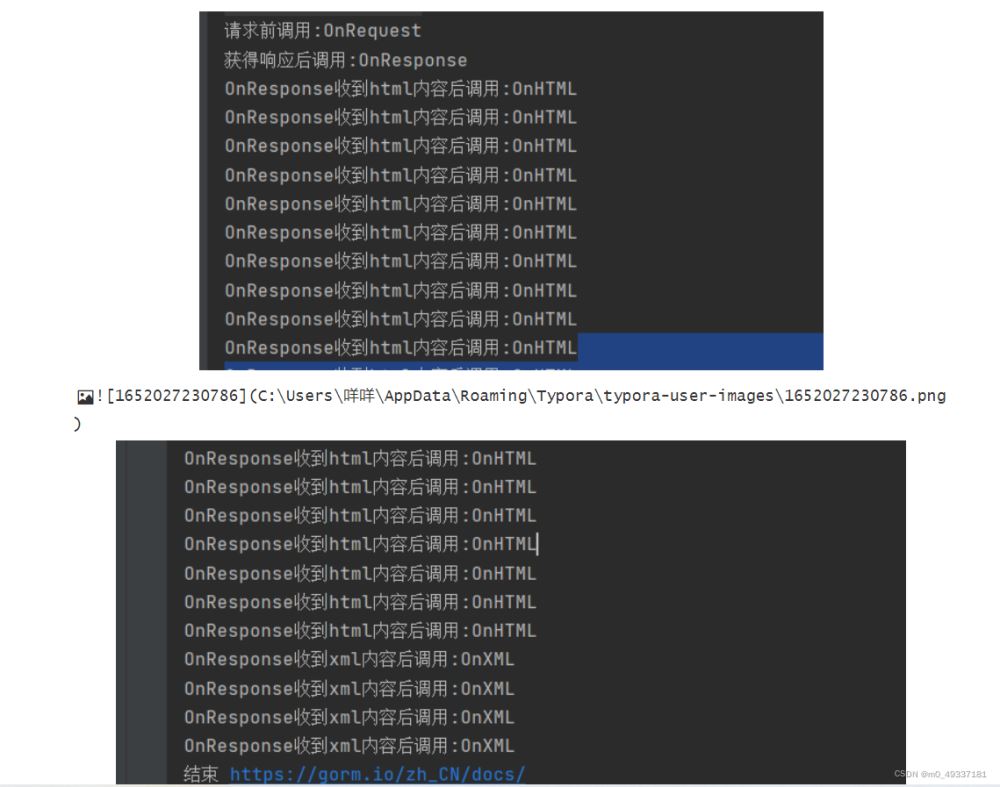
colly 的配置
设置UserAgent
//设置UserAgent的两种方式:
/* //方式一 :
c2 := colly.NewCollector()
c2.UserAgent = "xy"
c2.AllowURLRevisit = true*/
/* //方式二 :
c2 := colly.NewCollector(
colly.UserAgent("xy"),
colly.AllowURLRevisit(),
)*/
设置Cookie
//设置cookie的两种方式
//方式一:通过手动网页添加cookies
c.OnRequest(func(r *colly.Request) {
r.Headers.Add("cookie","_ga=GA1.2.1611472128.1650815524; _gid=GA1.2.2080811677.1652022429; __atuvc=2|17,0|18,5|19")
})
// 方式二 :通过url 添加cookies
siteCookie := c.Cookies("url")
c.SetCookies("",siteCookie)
HTTP配置
Colly使用Golang的默认http客户端作为网络层。可以通过更改默认的HTTP roundtripper来调整HTTP选项。
c := colly.NewCollector()
c.WithTransport(&http.Transport{
Proxy: http.ProxyFromEnvironment,
DialContext: (&net.Dialer{
Timeout: 30 * time.Second,
KeepAlive: 30 * time.Second,
DualStack: true,
}).DialContext,
MaxIdleConns: 100,
IdleConnTimeout: 90 * time.Second,
TLSHandshakeTimeout: 10 * time.Second,
ExpectContinueTimeout: 1 * time.Second,
}
colly页面爬取和解析
页面爬取和解析重点方法是 onHTML 回调方法
c.OnHTML("a[href]", func(e *colly.HTMLElement) {
fmt.Printf("e.Name:%v\n",e.Name)
e.Request.Visit(e.Attr("href"))
})
func html() {
c:= colly.NewCollector()
c.OnHTML("#sidebar", func(e *colly.HTMLElement) {
//fmt.Printf("e.Name:%v\n",e.Name) //名字
//fmt.Printf("e.Text:%v\n",e.Text) //文本
ret, _ := e.DOM.Html() // selector 选择器
fmt.Printf("ret:%v\n",ret)
})
c.OnRequest(func(r *colly.Request) {
fmt.Println("url:",r.URL)
})
c.Visit("https://gorm.io/zh_CN/docs/")
}
第一个参数是:goquery选择器,可以元素名称,ID或者Class选择器,第二个参数是根据第一个选择器获得的HTML元素结构如下:
colly框架重构爬虫
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func main() {
c:= colly.NewCollector()
c.OnHTML(".sidebar_link", func(e *colly.HTMLElement) { // 左侧链接
href := e.Attr("href")
if href != "index.html"{
c.Visit(e.Request.AbsoluteURL(href))
}
})
c.OnHTML(".article-title", func(h *colly.HTMLElement) { // 选择链接之后的标题
title := h.Text
fmt.Printf("title: %v\n",title)
})
c.OnHTML(".article", func(h *colly.HTMLElement) { //内容
content, _ := h.DOM.Html()
fmt.Printf("content: %v\n",content)
})
c.OnRequest(func(r *colly.Request) {
fmt.Println("url:",r.URL.String())
})
c.Visit("https://gorm.io/zh_CN/docs/")
}
到此这篇关于Golang爬虫框架 colly的使用的文章就介绍到这了,更多相关Golang colly内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫 scrapy框架爬取某招聘网存入mongodb解析
创建项目 scrapy startproject zhaoping 创建爬虫 cd zhaoping scrapy genspider hr zhaopingwang.com 目录结构 items.py title = scrapy.Field() position = scrapy.Field() publish_date = scrapy.Field() pipelines.py from pymongo import MongoClient mongoclient = MongoClien
-
Golang爬虫框架 colly的使用
目录 项目特性 安装colly 实例 colly 的配置 colly页面爬取和解析 colly框架重构爬虫 Golang爬虫框架 colly 简介 colly是一个采用Go语言编写的Web爬虫框架,旨在提供一个能够些任何爬虫/采集器/蜘蛛的简介模板,通过Colly.你可以轻松的从网站提取结构化数据,然后进行数据挖掘,处理或归档 项目特性 清晰明了的API 速度快(每个内核上的请求数大于1K) 管理每个域的请求延迟和最大并发数 自动cookie和会话处理 同步/异步/ 并行抓取 高速缓存 自动处理
-
golang爬虫colly 发送post请求
继续还是工作中使用colly,不管是官网,还是网上的一些文章(其实90%就是把官网的案例抄过去),都是一样的格式,没有讲到post,测试了几次,记录一下post的使用 c := colly.NewCollector() type data struct { Phone string `json:"phone" binding:"required"` } d:=&data{ Phone:"
-
Python爬虫框架Scrapy安装使用步骤
一.爬虫框架Scarpy简介Scrapy 是一个快速的高层次的屏幕抓取和网页爬虫框架,爬取网站,从网站页面得到结构化的数据,它有着广泛的用途,从数据挖掘到监测和自动测试,Scrapy完全用Python实现,完全开源,代码托管在Github上,可运行在Linux,Windows,Mac和BSD平台上,基于Twisted的异步网络库来处理网络通讯,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片. 二.Scrapy安装指南 我们的安装步骤假设你已经安装一下内容:<1>
-
零基础写python爬虫之爬虫框架Scrapy安装配置
前面十章爬虫笔记陆陆续续记录了一些简单的Python爬虫知识, 用来解决简单的贴吧下载,绩点运算自然不在话下. 不过要想批量下载大量的内容,比如知乎的所有的问答,那便显得游刃不有余了点. 于是乎,爬虫框架Scrapy就这样出场了! Scrapy = Scrach+Python,Scrach这个单词是抓取的意思, Scrapy的官网地址:点我点我. 那么下面来简单的演示一下Scrapy的安装流程. 具体流程参照:http://www.jb51.net/article/48607.htm 友情提醒:
-
简单好用的nodejs 爬虫框架分享
这个就是一篇介绍爬虫框架的文章,开头就不说什么剧情了.什么最近一个项目了,什么分享新知了,剧情是挺好,但介绍的很初级,根本就没有办法应用,不支持队列的爬虫,都是耍流氓. 所以我就先来举一个例子,看一下这个爬虫框架是多么简单并可用. 第一步:安装 Crawl-pet nodejs 就不用多介绍吧,用 npm 安装 crawl-pet $ npm install crawl-pet -g --production 运行,程序会引导你完成配置,首次运行,会在项目目录下生成 info.json 文件 $
-
Python爬虫框架Scrapy实战之批量抓取招聘信息
网络爬虫抓取特定网站网页的html数据,但是一个网站有上千上万条数据,我们不可能知道网站网页的url地址,所以,要有个技巧去抓取网站的所有html页面.Scrapy是纯Python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便- Scrapy 使用wisted这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求.整体架构如下图所示: 绿线是数据流向,首先从初始URL 开始,Scheduler 会将其
-
python爬虫框架scrapy实战之爬取京东商城进阶篇
前言 之前的一篇文章已经讲过怎样获取链接,怎样获得参数了,详情请看python爬取京东商城普通篇,本文将详细介绍利用python爬虫框架scrapy如何爬取京东商城,下面话不多说了,来看看详细的介绍吧. 代码详解 1.首先应该构造请求,这里使用scrapy.Request,这个方法默认调用的是start_urls构造请求,如果要改变默认的请求,那么必须重载该方法,这个方法的返回值必须是一个可迭代的对象,一般是用yield返回. 代码如下: def start_requests(self): fo
-
分享一个简单的java爬虫框架
反复给网站编写不同的爬虫逻辑太麻烦了,自己实现了一个小框架 可以自定义的部分有: 请求方式(默认为Getuser-agent为谷歌浏览器的设置),可以通过实现RequestSet接口来自定义请求方式 储存方式(默认储存在f盘的html文件夹下),可以通过SaveUtil接口来自定义保存方式 需要保存的资源(默认为整个html页面) 筛选方式(默认所有url都符合要求),通过实现ResourseChooser接口来自定义需要保存的url和资源页面 实现的部分有: html页面的下载方式,通过Htt
-
Python之Scrapy爬虫框架安装及使用详解
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫. 本文档将
-
Python之Scrapy爬虫框架安装及简单使用详解
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了页面抓取(更确切来说,网络抓取)所设计的, 也可以应用在获取API所返回的数据(例如Amazon Associates Web Services) 或者通用的网络爬虫. 本文档将通过介绍Sc