利用Python通过商品条形码查询商品信息的实现示例
目录
- 一 商品条形码
- 二 查询商品条形码的目的
- 三 Python实现
- 3.1 爬取网站介绍
- 3.2 python代码实现
提前说明,由于博文重在讲解,代码一体性有一定程度的破坏。如想要省事需要完整代码请至一下链接下载:完整代码下载
一 商品条形码
平日大家会购买许许多多的商品,无论是饮料、食品、药品、日用品等在商品的包装上都会有条形码。
商品条形码包括零售商品、非零售商品、物流单元、位置的代码和条码标识。我国采用国际通用的商品代码及条码标识体系,推广应用商品条形码,建立我国的商品标识系统。
零售商品是指在零售端通过POS扫描结算的商品。其条码标识由全球贸易项目代码(GTIN)及其对应的条码符号组成。零售商品的条码标识主要采用EAN/UPC条码。一听啤酒、一瓶洗发水和一瓶护发素的组合包装都可以作为一项零售商品卖给最终消费者。
总的来讲就是每一种在市面流通的商品都会有属于自己商品条形码。

二 查询商品条形码的目的
从技术方面来讲,本次利用Python通过商品条形码查询商品信息是为了练习爬虫技术。
从生活方面来讲,本次项目可以查询购买商品的信息,确保商品来源与成分可靠。
三 Python实现
3.1 爬取网站介绍
网站链接如下:条形码查询网站
网站截图如下:

可以看到在该网站中输入某一商品的条形码,后输入验证码。点击查询即可查询到商品信息。以“6901028001915”为例,进行一次查询,截图如下:
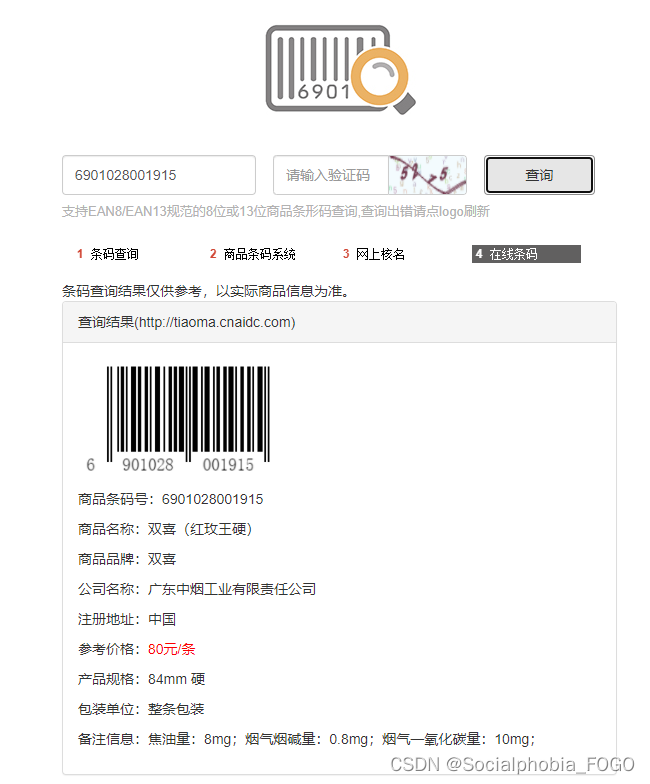
3.2 python代码实现
3.2.1 日志模块
为保存操作记录在项目中添加日志模块,代码如下:
import logging
import logging.handlers
'''
日志模块
'''
LOG_FILENAME = 'msg_seckill.log'
logger = logging.getLogger()
def set_logger():
logger.setLevel(logging.INFO)
formatter = logging.Formatter('%(asctime)s - %(process)d-%(threadName)s - '
'%(pathname)s[line:%(lineno)d] - %(levelname)s: %(message)s')
console_handler = logging.StreamHandler()
console_handler.setFormatter(formatter)
logger.addHandler(console_handler)
file_handler = logging.handlers.RotatingFileHandler(
LOG_FILENAME, maxBytes=10485760, backupCount=5, encoding="utf-8")
file_handler.setFormatter(formatter)
logger.addHandler(file_handler)
set_logger()
3.2.2 查询模块
有上面的截图可以看到,网站查询需要数字验证码验证,因此这里使用ddddocr包来识别验证码。导入相应的包:
from logging import fatal import ddddocr import requests import json import os import time import sys from msg_logger import logger
接下来是项目的主体代码,整个操作逻辑代码注释中有详细讲解:
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'}
path = os.path.abspath(os.path.dirname(sys.argv[0]))
# json化
def parse_json(s):
begin = s.find('{')
end = s.rfind('}') + 1
return json.loads(s[begin:end])
# 创建目录
def mkdir(path):
# 去除首位空格
path = path.strip()
# 去除尾部 \ 符号
path = path.rstrip("\\")
# 判断路径是否存在
isExists=os.path.exists(path)
# 判断结果
if not isExists:
os.makedirs(path)
logger.info(path + ' 创建成功')
return True
else:
# 如果目录存在则不创建,并提示目录已存在
logger.info(path + ' 目录已存在')
return False
# 爬取 "tiaoma.cnaidc.com" 来查找商品信息
def requestT1(shop_id):
url = 'http://tiaoma.cnaidc.com'
s = requests.session()
# 获取验证码
img_data = s.get(url + '/index/verify.html?time=', headers=headers).content
with open('verification_code.png','wb') as v:
v.write(img_data)
# 解验证码
ocr = ddddocr.DdddOcr()
with open('verification_code.png', 'rb') as f:
img_bytes = f.read()
code = ocr.classification(img_bytes)
logger.info('当前验证码为 ' + code)
# 请求接口参数
data = {"code": shop_id, "verify": code}
resp = s.post(url + '/index/search.html',headers=headers,data=data)
resp_json = parse_json(resp.text)
logger.info(resp_json)
# 判断是否查询成功
if resp_json['msg'] == '查询成功' and resp_json['json'].get('code_img'):
# 保存商品图片
img_url = ''
if resp_json['json']['code_img'].find('http') == -1:
img_url = url + resp_json['json']['code_img']
else:
img_url = resp_json['json']['code_img']
try:
shop_img_data = s.get(img_url, headers=headers, timeout=10,).content
# 新建目录
mkdir(path + '\\' + shop_id)
localtime = time.strftime("%Y%m%d%H%M%S", time.localtime())
# 保存图片
with open(path + '\\' + shop_id + '\\' + str(localtime) +'.png','wb') as v:
v.write(shop_img_data)
logger.info(path + '\\' + shop_id + '\\' + str(localtime) +'.png')
except requests.exceptions.ConnectionError:
logger.info('访问图片URL出现错误!')
if resp_json['msg'] == '验证码错误':
requestT1(shop_id)
return resp_json
3.2.3 运行结果
if __name__ == "__main__":
try:
dict_info = requestT1('6901028001915')['json']
print(dict_info['code_sn'])
print(dict_info['code_name'])
print(dict_info['code_company'])
print(dict_info['code_address'])
print(dict_info['code_price'])
except:
print('商品无法查询!')
尝试运行代码,以“6901028001915”为例,查看运行结果:

可见商品的信息成功查询出来。
到此这篇关于利用Python通过商品条形码查询商品信息的文章就介绍到这了,更多相关利用Python通过商品条形码查询商品信息内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python之ReportLab绘制条形码和二维码的实例
条形码和二维码 #引入所需要的基本包 from reportlab.pdfgen import canvas from reportlab.graphics.barcode import code39, code128, code93 from reportlab.graphics.barcode import eanbc, qr, usps from reportlab.graphics.shapes import Drawing from reportlab.lib.units import
-
python中扫描条形码和二维码的实现代码
简单说明,代码太难懂,先做此记录留待来日在看 步骤: 1,pip install pyzbar安装好该模块.pyzbar模块是Python一个开源库用于扫描和识别二维码信息. 2,随便在网上找好两张截图 3, from pyzbar import pyzbar import matplotlib.pyplot as plt import cv2 #条形码定位及识别 def decode(image,barcodes): #循环监测条形码 for barcode in barcodes: #提取条
-
python利用elaphe制作二维条形码实现代码
手机上的二维码识别程序已经做的很好了,"我查查"用起来很不错的 我搜集了几个二维条码生成网站: http://www.morovia.com/free-online-barcode-generator/qrcode-maker.php http://qrencode.sinaapp.com/ http://www.mayacode.com/ 作为一个程序猿,我们也要懂得如何制作二维条形码 python的elaphe模块帮我们解决了问题 复制代码 代码如下: from elaphe im
-
python3转换code128条形码的方法
这年头如果用 python3 做条形码的,肯定(推荐)用 pystrich . 这货官方文档貌似都没写到支持 Code128 ,但是居然有这个类( Code128Encoder ).... 一些喷墨打印机,如果质量差一点的话,喷出来的条码,会沾到一起,不好识别. 而用 pystrich 的话,会发觉宽度无法调节. 于是想到了用 条形码字体 来自己控制大小,找是找到字库了,但是你会发觉,你生成的东西,无法被扫描识别, 那是因为,这东西得转换后,才能打印啊... 经过千辛万苦,终于找到一篇文章说到转
-
Python识别快递条形码及Tesseract-OCR使用详解
识别快递单号 这次跟老师做项目,这项目大概是流水线上识别快递上的快递单号.首先我尝试了解条形码的基本知识 百度百科:条形码 条形码(barcode)是将宽度不等的多个黑条和空白,按照一定的编码规则排列,用以表达一组信息的图形标识符.常见的条形码是由反射率相差很大的黑条(简称条)和白条(简称空)排成的平行线图案.条形码可以标出物品的生产国.制造厂家.商品名称.生产日期.图书分类号.邮件起止地点.类别.日期等许多信息,因而在商品流通.图书管理.邮政管理.银行系统等许多领域都得到广泛的应用. 条形码有
-
python批量生成条形码的示例
在工作中,有时会遇见需要将数字转换为条码的问题,每次都需要打开条码转换的网站,一次次的转换后截图,一两个还行,但是当需要转换的数量较多时,就会显得特别麻烦,弄不好还会遗漏或者重复,为了解决这个问题,使用python写了以下脚本,用来解决此问题 1.安装python-barcode库和pillow库 需要导入的python库 import barcode from barcode.writer import ImageWriter 2.将需要转换的条形码数据保存到同级目录下的 EAN.txt 内
-
Python识别处理照片中的条形码
最近一直在玩数独,突发奇想实现图像识别求解数独,输入到输出平均需要0.5s. 整体思路大概就是识别出图中数字生成list,然后求解. 输入输出demo 数独采用的是微软自带的Microsoft sudoku软件随便截取的图像,如下图所示: 经过程序求解后,得到的结果如下图所示: def getFollow(varset, terminalset, first_dic, production_list): follow_dic = {} done = {} for var
-
利用Python通过商品条形码查询商品信息的实现示例
目录 一 商品条形码 二 查询商品条形码的目的 三 Python实现 3.1 爬取网站介绍 3.2 python代码实现 提前说明,由于博文重在讲解,代码一体性有一定程度的破坏.如想要省事需要完整代码请至一下链接下载:完整代码下载 一 商品条形码 平日大家会购买许许多多的商品,无论是饮料.食品.药品.日用品等在商品的包装上都会有条形码. 商品条形码包括零售商品.非零售商品.物流单元.位置的代码和条码标识.我国采用国际通用的商品代码及条码标识体系,推广应用商品条形码,建立我国的商品标识系统. 零售
-
Python爬取京东商品信息评论存并进MySQL
目录 构建mysql数据表 第一版: 第二版 : 第三版: 构建mysql数据表 问题:使用SQL alchemy时,非主键不能设置为自增长,但是我想让这个非主键仅仅是为了作为索引,autoincrement=True无效,该怎么实现让它自增长呢? from sqlalchemy import String,Integer,Text,Column from sqlalchemy import create_engine from sqlalchemy.orm import sessionmake
-
利用Python实现获取照片位置信息
目录 引言 一.exifread函数库 安装exrfread库(PyCharm) 什么是exifread函数库 二.获取女朋友发来的照片(单身勿扰) 三.具体代码实现 四.经纬度转换 引言 通过一张照片居然发现女友在宿舍里没去上课!强大的照片位置信息获取,快来一起学习吧! 一.exifread函数库 要怎样获得拍摄图片的GPS呢?这里我们需要exifread 库,这个就是用来提取 GPS 信息的.直接 pip install exifread 来安装就好了. 安装exrfread库(PyChar
-
利用Python获取赶集网招聘信息前篇
如何获取一个网站的相关信息,获取赶集网的招聘信息,本文为大家介绍利用python获取赶集网招聘信息的关键代码,供大家参考,具体内容如下 import re import urllib import urllib.request #获取赶集网数据 def begin(url): #要伪装成的浏览器(我这个是用的chrome) headers = ('User-Agent','Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML,
-
Python脚本读取Consul配置信息的方法示例
先来说一下背景,为什么要写脚本去读Consul的配置信息呢?Consul是啥呢?consul是google开源的一个使用go语言开发的服务发现.配置管理中心服务.目前公司用的是这个东西去管理项目上的一些配置信息.公司的环境是通过docker镜像的方式去部署的,镜像是通过rancher去进行管理的.这一套东西面临的一个问题是:服务每次更新之后,服务对应的ip地址是动态变化的.每次需要使用swagger去测接口的时候,都要去rancher上去重新找新的ip地址,比较麻烦.正好呢,最近部门在考虑准备做
-
利用Python打造一个多人聊天室的示例详解
一.实验名称 建立聊天工具 二.实验目的 掌握Socket编程中流套接字的技术,实现多台电脑之间的聊天. 三.实验内容和要求 vii.掌握利用Socket进行编程的技术 viii.必须掌握多线程技术,保证双方可以同时发送 ix.建立聊天工具 x.可以和多个人同时进行聊天 xi.必须使用图形界面,显示双方的语录 四.实验环境 PC多台,操作系统Win7,win10(32位.64位) 具备软件python3.6 . 五.操作方法与实验步骤 服务端 1.调入多线程.与scoket包,用于实现多线程连接
-
利用Python pandas对Excel进行合并的方法示例
前言 在网上找了很多Python处理Excel的方法和代码,都不是很尽人意,所以自己综合网上各位大佬的方法,自己进行了优化,具体的代码如下. 博主也是新手一枚,代码肯定有很多需要优化的地方,欢迎各位大佬提出建议~ 代码我自己已经用了一段时间,可以直接拿去用 主要功能 按行合并 ,即保留固定的表头(如前几行),实现多个Excel相同格式相同名字的表单按纵轴合并: 按列合并. 即保留固定的首列,实现多个Excel相同格式相同名字的表单按横轴合并: 表单集成 ,实现不同Excel中相同sheet的集成
-
python正则匹配查询港澳通行证办理进度示例分享
复制代码 代码如下: import socketimport re '''广东省公安厅出入境政务服务网护照,通行证办理进度查询.分析网址格式为 http://www.gdcrj.com/wsyw/tcustomer/tcustomer.do?&method=find&applyid=身份证号码构造socket请求网页html,利用正则匹配出查询结果'''def gethtmlbyidentityid(identityid): s = socket.socket(socket.AF_INET
-
Python实现读取机器硬件信息的方法示例
本文实例讲述了Python实现读取机器硬件信息的方法.分享给大家供大家参考,具体如下: 本人最近新学python ,用到关于机器的相关信息,经过一番研究,从网上查找资料,经过测试,总结了一下相关的方法. # -*- coding: UTF8 -*- import os import win32api import datetime import platform import getpass import socket import uuid import _winreg import re 1
-
Python中捕捉详细异常信息的代码示例
大家在开发的过程中可能时常碰到一个需求,需要把Python的异常信息输出到日志文件中. 网上的办法都不太实用,下面介绍一种实用的,从Python 2.7源码中扣出来的. 废话不说 直接上代码,代码不多,注释比较多而已. import sys, traceback traceback_template = '''Traceback (most recent call last): File "%(filename)s", line %(lineno)s, in %(name)s %(ty