TensorFlow人工智能学习按索引取数据及维度变换详解
目录
- 一、按索引取数据
- ①tf.gather()
- ②tf.gather_nd
- ③tf.boolean_mask
- 二、维度变换
- ①tf.reshape()
- ②tf.transpose()
- ③tf.expand_dims()
- ④tf.squeeze()
一、按索引取数据
①tf.gather()
输入参数:数据、维度、索引
例:设数据是[4,35,8],4个班级,每个班级35个学生,每个学生8门课成绩。
则下面In [49]的意思是,全部四个班级,每个班级取编号为2,3,7,9,16的学生,每个学生取所有8门课的成绩。


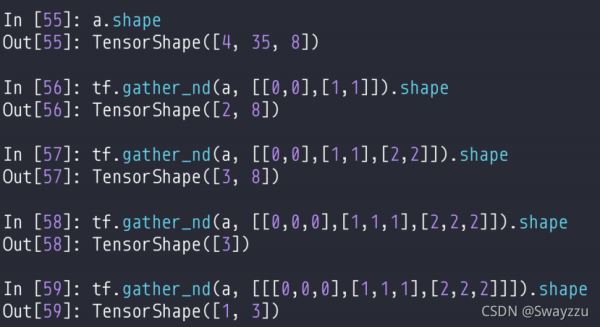
②tf.gather_nd
前面输入数据,后面填取的联合维度。只把最内层的括号当做联合索引的坐标。

下面的例子,也是一样,最内层的中括号,是一个联合索引。比如in56,第0个班级,第0号学生成绩,以及第1号班级,第1号学生的成绩。也就是每一个最内层中括号,都是一个样本,而里面的每一个数据,都相当于一个特征。
③tf.boolean_mask
按布尔值索引,不指定维度相当于是第一个维度,指定axis就会根据axis去索引。给索引矩阵也可以。

二、维度变换
①tf.reshape()
输入参数:数据,希望变成的维度

②tf.transpose()
转置,perm数字指的是数字所在位置上放哪一个原来的维度。

pytorch中图像存储维度是[b,c,h,w],tf中是[b,h,w,c]
③tf.expand_dims()
增加维度,第一个填的是数据,第二个填的是维度,是指你希望把添加的维度作为第几维。

④tf.squeeze()
可以去掉为1的维度。不指定维度的话就去掉所有的为1的维度。

以上就是TensorFlow人工智能学习按索引取数据及维度变换详解的详细内容,更多关于TensorFlow索引维度变换的资料请关注我们其它相关文章!
相关推荐
-

TensorFlow人工智能学习张量及高阶操作示例详解
目录 一.张量裁剪 1.tf.maximum/minimum/clip_by_value() 2.tf.clip_by_norm() 二.张量排序 1.tf.sort/argsort() 2.tf.math.topk() 三.TensorFlow高阶操作 1.tf.where() 2.tf.scatter_nd() 3.tf.meshgrid() 一.张量裁剪 1.tf.maximum/minimum/clip_by_value() 该方法按数值裁剪,传入tensor和阈值,maximum是把数
-
详解tensorflow训练自己的数据集实现CNN图像分类
利用卷积神经网络训练图像数据分为以下几个步骤 1.读取图片文件 2.产生用于训练的批次 3.定义训练的模型(包括初始化参数,卷积.池化层等参数.网络) 4.训练 1 读取图片文件 def get_files(filename): class_train = [] label_train = [] for train_class in os.listdir(filename): for pic in os.listdir(filename+train_class): class_train.app
-
Tensorflow之构建自己的图片数据集TFrecords的方法
学习谷歌的深度学习终于有点眉目了,给大家分享我的Tensorflow学习历程. tensorflow的官方中文文档比较生涩,数据集一直采用的MNIST二进制数据集.并没有过多讲述怎么构建自己的图片数据集tfrecords. 流程是:制作数据集-读取数据集--加入队列 先贴完整的代码: #encoding=utf-8 import os import tensorflow as tf from PIL import Image cwd = os.getcwd() classes = {'test'
-
TensorFlow人工智能学习数据合并分割统计示例详解
目录 一.数据合并与分割 1.tf.concat() 2.tf.split() 3.tf.stack() 二.数据统计 1.tf.norm() 2.reduce_min/max/mean() 3.tf.argmax/argmin() 4.tf.equal() 5.tf.unique() 一.数据合并与分割 1.tf.concat() 填入两个tensor, 指定某维度,在指定的维度合并.除了合并的维度之外,其他的维度必须相等. 2.tf.split() 填入tensor,指定维度,指定分割的数量
-
TensorFlow人工智能学习数据填充复制实现示例
目录 1.tf.pad() 2.tf.tile() 1.tf.pad() 该方法能够给数据周围填0,填的参数是:需要填充的数据+填0的位置 填0的位置是一个数组形式,对应如下:[[上行,下行],[左列,右列]],具体例子如下: 较为常用的是上下左右各一行. 给图片进行padding的时候,通常数据的维度是[b,h,w,c],那么增加两行,两列的话,是在中间的h和w增加: 2.tf.tile() 该方法可以复制数据,需要填的参数:数据,维度+对应的复制次数. broadcast_to = expa
-
TensorFlow人工智能学习创建数据实现示例详解
目录 一.数据创建 1.tf.constant() 2.tf.convert_to_tensor() 3.tf.zeros() 4.tf.fill() 二.数据随机初始化 ①tf.random.normal() ②tf.random.truncated_normal() ③tf.random.uniform() ④tf.random.shuffle() 一.数据创建 1.tf.constant() 创建自定义类型,自定义形状的数据,但不能创建类似于下面In [59]这样的,无法解释的数据. 2.
-
TensorFlow人工智能学习按索引取数据及维度变换详解
目录 一.按索引取数据 ①tf.gather() ②tf.gather_nd ③tf.boolean_mask 二.维度变换 ①tf.reshape() ②tf.transpose() ③tf.expand_dims() ④tf.squeeze() 一.按索引取数据 ①tf.gather() 输入参数:数据.维度.索引 例:设数据是[4,35,8],4个班级,每个班级35个学生,每个学生8门课成绩. 则下面In [49]的意思是,全部四个班级,每个班级取编号为2,3,7,9,16的学生,每个学生
-
TensorFlow人工智能学习数据类型信息及转换
目录 一.数据类型 二.数据类型信息 ①.device ②.numpy() ③.shape / .ndim 三.数据类型转换 ①tf.convert_to_tensor ②tf.cast() 一.数据类型 在tf中,数据类型有整型(默认是int32),浮点型(默认是float32),以及布尔型,字符串. 二.数据类型信息 ①.device 查看tensor在哪(CPU上面或者GPU上面),可以通过.cpu(),.gpu()进行转换,如果数据所在的处理器位置不一样,则不能进行计算. ②.numpy
-
Python Pandas学习之数据离散化与合并详解
目录 1数据离散化 1.1为什么要离散化 1.2什么是数据的离散化 1.3举例股票的涨跌幅离散化 2数据合并 2.1pd.concat实现数据合并 2.2pd.merge 1 数据离散化 1.1 为什么要离散化 连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数.离散化方法经常作为数据挖掘的工具. 1.2 什么是数据的离散化 连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数 值代表落在每个子区间中的属性值. 离散化有
-
对pandas的层次索引与取值的新方法详解
1.层次索引 1.1 定义 在某一个方向拥有多个(两个及两个以上)索引级别,就叫做层次索引. 通过层次化索引,pandas能够以较低维度形式处理高纬度的数据 通过层次化索引,可以按照层次统计数据 层次索引包括Series层次索引和DataFrame层次索引 1.2 Series的层次索引 import numpy as np import pandas as pd s1 = pd.Series(data=[99, 80, 76, 80, 99], index=[['2017', '2017',
-
tensorflow入门:TFRecordDataset变长数据的batch读取详解
在上一篇文章tensorflow入门:tfrecord 和tf.data.TFRecordDataset的使用里,讲到了使用如何使用tf.data.TFRecordDatase来对tfrecord文件进行batch读取,即使用dataset的batch方法进行:但如果每条数据的长度不一样(常见于语音.视频.NLP等领域),则不能直接用batch方法获取数据,这时则有两个解决办法: 1.在把数据写入tfrecord时,先把数据pad到统一的长度再写入tfrecord:这个方法的问题在于:若是有大量
-
tensorflow的ckpt及pb模型持久化方式及转化详解
使用tensorflow训练模型的时候,模型持久化对我们来说非常重要. 如果我们的模型比较复杂,需要的数据比较多,那么在模型的训练时间会耗时很长.如果在训练过程中出现了模型不可预期的错误,导致训练意外终止,那么我们将会前功尽弃.为了解决这一问题,我们可以使用模型持久化(保存为ckpt文件格式)来保存我们在训练过程中的临时数据.. 如果我们训练出的模型需要提供给用户做离线预测,那么我们只需要完成前向传播过程.这个时候我们就可以使用模型持久化(保存为pb文件格式)来只保存前向传播过程中的变量并将变量