Python 图片文字识别的实现之PaddleOCR
目录
- 项目使用
- 项目结构
- 环境部署
- 1、安装Anaconda,构造虚拟环境
- 2、依赖包下载
- 测试代码
- 参数补充
- 总结
前言
什么是OCR?
光学字符识别(Optical Character Recognition, OCR),是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。简而言之,检测图像中的文本资料,并且识别出文本的内容。
那么有哪些应用场景呢?
其实我们日常生活中处处都有ocr的影子,比如在疫情期间身份证识别录入信息、车辆车牌号识别、自动驾驶等。我们的生活中,机器学习已经越来越多的扮演着重要角色,也不再是神秘的东西。
OCR的技术路线是什么呢?
ocr的运行方式如下图,输入->图像预处理->文字检测->文本识别->输出。

本文主要是介绍一个博主使用的比较好的OCR开源项目,在这里分享给大家——PaddleOCR。
项目Github地址: PaddleOCR地址
我会按照刚接触的状态,梳理一下验证使用该项目的过程。
项目使用
先把项目从github上clone下来,慢慢分析。
项目结构
首先我们看一下项目的构造。
发现项目有中文的介绍说明,这就很方便了,点开按照官方的说明开始操作。
环境部署
点开README.md,,可以从文档教程中看到第一步就是教你如何安装环境。
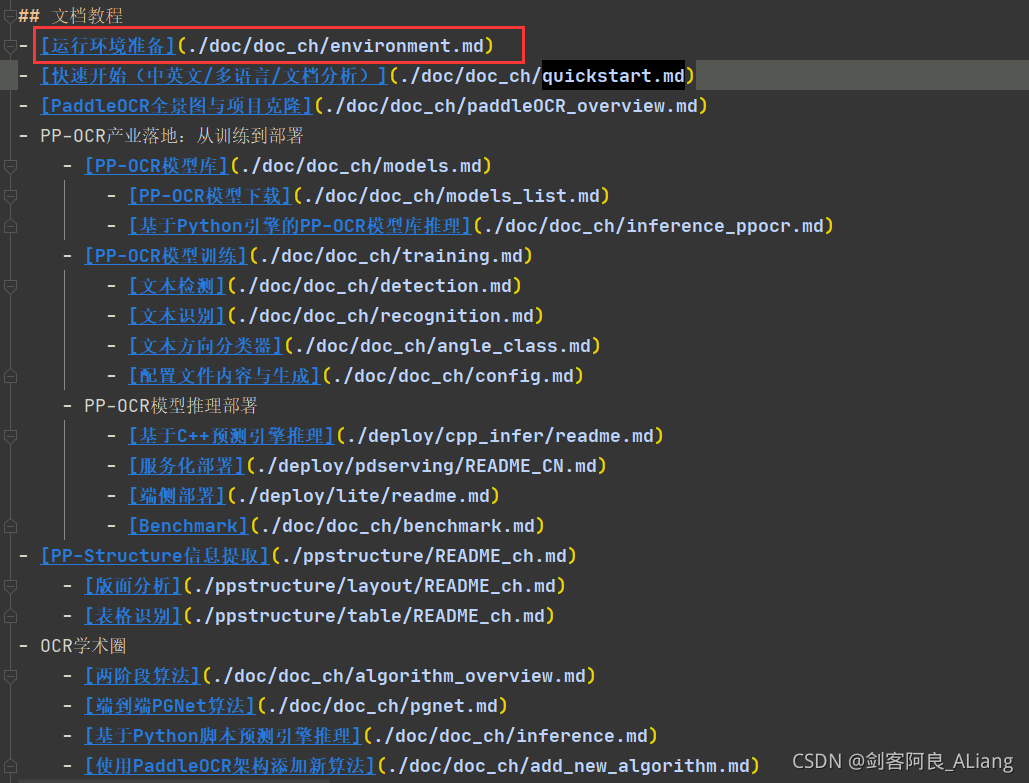
由于内容过多,我就做个概括,方便大家直接上手。
1、安装Anaconda,构造虚拟环境
这里可以参考我的另一篇文章,里面很详细:Python 机器学习第一章环境配置图解流程
官方给的是python3.8的虚拟环境,我们也构造一个,打开Anaconda Prompt。
输入命令:
conda create -n paddle_env python=3.8
激活环境:
conda activate paddle_env
2、依赖包下载
paddlepaddle安装
pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
layoutparser安装
pip3 install -U https://paddleocr.bj.bcebos.com/whl/layoutparser-0.0.0-py3-none-any.whl
Shapely安装,这个需要下载,下载地址:Shapely下载地址
我选的是这个
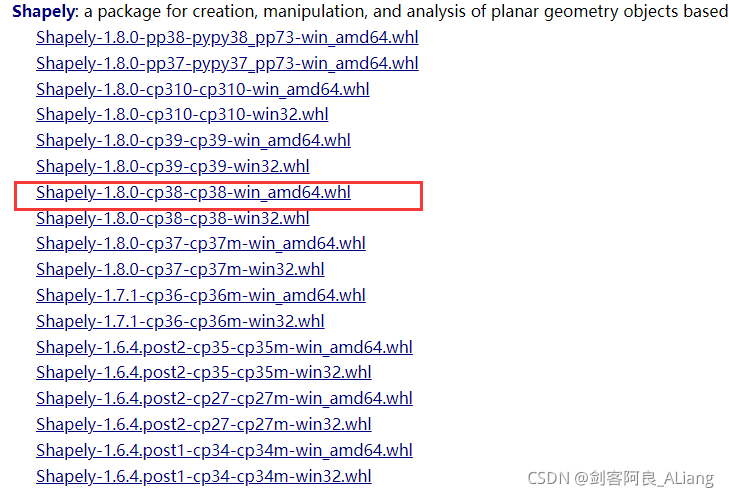
安装命令:
pip install Shapely-1.8.0-cp38-cp38-win_amd64.whl
paddleocr安装
pip install paddleocr -i https://mirror.baidu.com/pypi/simple
好的,环境有点多,都安装好了就开始上手使用吧。
测试代码
官方给出了两种模式,一是命令行执行,一是代码执行。为了直观的看到配置,我这里使用的是代码模式。
准备一张带文字的图片

测试代码如下
#!/user/bin/env python
# coding=utf-8
"""
@project : ocr_paddle
@author : huyi
@file : test.py
@ide : PyCharm
@time : 2021-11-15 14:56:20
"""
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True, use_gpu=False,
lang="ch") # need to run only once to download and load model into memory
img_path = './data/2.jpg'
result = ocr.ocr(img_path, cls=True)
for line in result:
# print(line[-1][0], line[-1][1])
print(line)
# 显示结果
from PIL import Image
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='./fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
代码说明
1、因为我的电脑没有显卡,所以设置了use_gpu=False。
2、显示结果部分会将识别的文字用框标出来,并且展示识别的结果。
验证一下
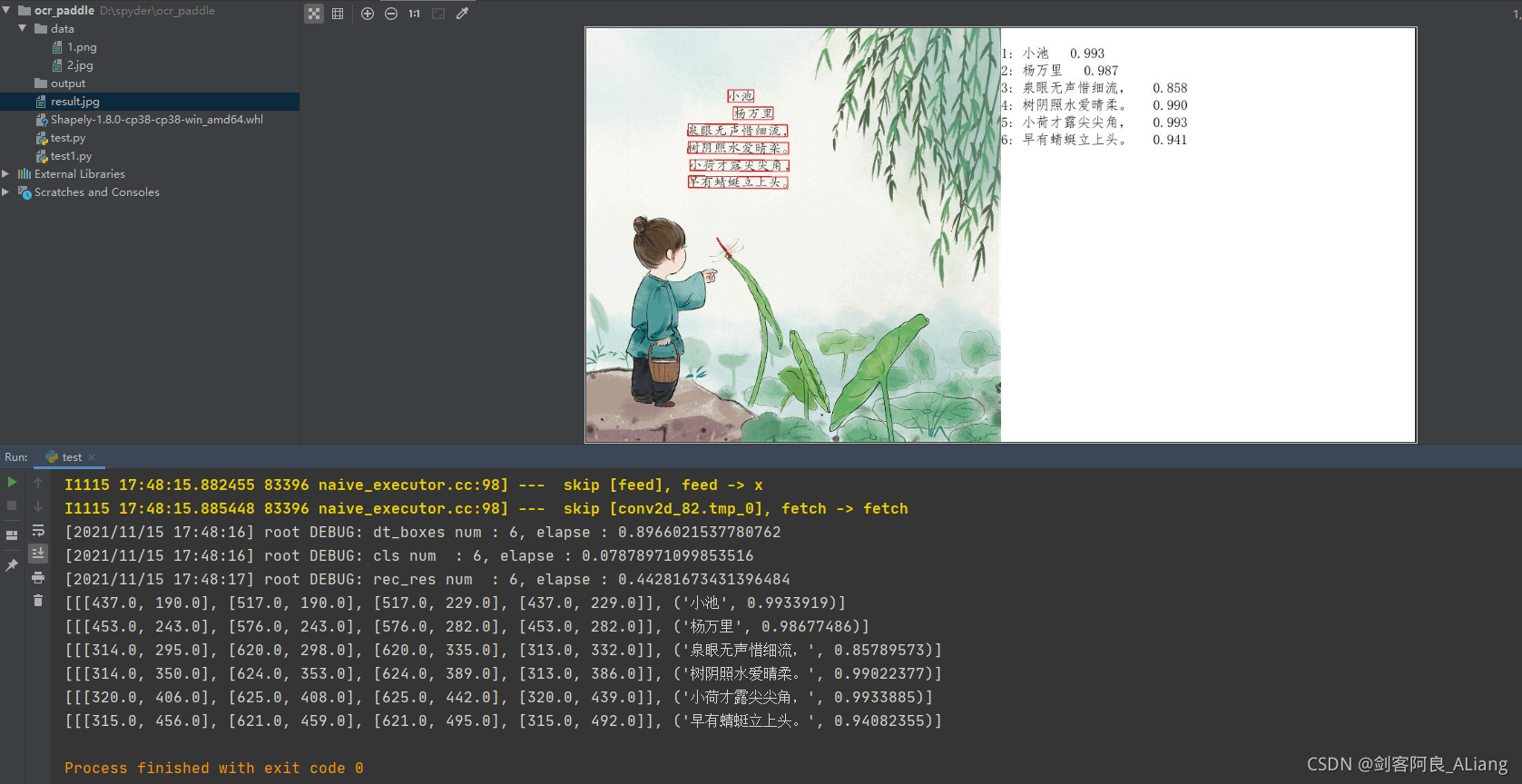
我们看到,打印的内容有识别出来的每句话所在的图片位置,以及识别结果和可信度。而上面的结果图中,将每句话对应的文字都框了出来。效果很不错!
参数补充
官方还给出了一些参数,可以调整输出的内容。可以参看quickstart.md文件。参数补充:
- 单独使用检测:设置`--rec`为`false`
- 单独使用识别:设置`--det`为`false`
官方还提供一个标准的json结构输出数据
PP-Structure的返回结果为一个dict组成的list,示例如下
```shell
[{ 'type': 'Text',
'bbox': [34, 432, 345, 462],
'res': ([[36.0, 437.0, 341.0, 437.0, 341.0, 446.0, 36.0, 447.0], [41.0, 454.0, 125.0, 453.0, 125.0, 459.0, 41.0, 460.0]],
[('Tigure-6. The performance of CNN and IPT models using difforen', 0.90060663), ('Tent ', 0.465441)])
}
]
```
总结
总的来说,这个项目还是很有意思的,训练的部分我就不多赘述了,毕竟准备数据挺麻烦的。回头我再想想这个项目可不可以魔改成好用的工具。
分享:
我们根本不需要最后的落脚点,只要不断前进就好了,只要不停下,道路就会不断延伸。——《进击的巨人》
如果本文对你有帮助的话,请不要吝啬你的赞,谢谢!

到此这篇关于Python 图片文字识别的实现之PaddleOCR的文章就介绍到这了,更多相关Python 文字识别内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python3使用腾讯云文字识别(腾讯OCR)提取图片中的文字内容实例详解
百度OCR体验地址: https://ai.baidu.com/tech/imagerecognition/general 腾讯OCR体验地址: https://cloud.tencent.com/act/event/ocrdemo 测试结果是:腾讯的效果要比百度的好 腾讯云目前额度是: 每个接口 1,000次/月免费,有6个文字识别的接口,一共是6,000次/月 百度接口调用之前写过文章 python实现百度OCR图片识别过程解析 使用步骤 1.注册账号: https://cloud.tenc
-

Python 实现任意区域文字识别(OCR)操作
本文的OCR当然不是自己从头开发的,是基于百度智能云提供的API(我感觉是百度在中国的人工智能领域值得称赞的一大贡献),其提供的API完全可以满足个人使用,相对来说简洁准确率高. 安装OCR Python SDK OCR Python SDK目录结构 ├── README.md ├── aip //SDK目录 │ ├── __init__.py //导出类 │ ├── base.py //aip基类 │ ├── http.py //http请求 │ └── ocr.py //OCR └── se
-
python 百度aip实现文字识别的实现示例
目录 介绍 模块使用 介绍 百度aip模块是用于实现百度云与用户接口,简单来说就是使用百度云所拥有的人工智能模块. 模块使用 pip install baidu-aip#下载百度云模块 登录百度云账号 填写信息 使用官方的文档 https://cloud.baidu.com/doc/OCR/s/wkibizyjk #百度aip模块,实现文字识别 from aip import AipOcr """ 你的 APPID AK SK """ APP_I
-
python PaddleOCR库用法及知识点详解
说明 1.PaddleOCR是基于深度学习的ocr识别库,中文识别精度相当还不错,能够应对大多数文字提取需求. 2.需要依次安装三个依赖库,shapely库可能会受到系统的影响,出现安装错误. 安装命令 pip install paddlepaddle pip install shapely pip install paddleocr 代码实现 ocr = PaddleOCR(use_angle_cls=True,) # 输入待识别图片路径 img_path = r"d:\Desktop\4A3
-
python调用文字识别OCR轻松搞定验证码
今天带你们去研究一个有趣的东西,文字识别OCR.不知道你们有没有想要识别图片,然后读出文字的功能.例如验证码,如果需要自动填写的话就需要这功能.还有很多种情况需要这功能的. 我们可以登录百度云,然后看看里面的接口文档.接口功能还是有比较丰富的应用场景的. # encoding:utf-8 import requests import base64 ''' 通用文字识别 ''' request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/gene
-
Python调用百度AI实现图片上文字识别功能实例
目录 简介 步骤 安装百度AI库 注册百度AI开放平台 调用glob库 调用AipOcr库识别文字 可能会遇到的问题 批量操作 总结 简介 Python免费调用百度AI实现图片上面的文字识别 步骤 安装百度AI库 !pip install baidu-aip 注册百度AI开放平台 先注册百度AI,获得ID和密钥.注册方法可参考:注册方法 只需走到 "1.6 获取密钥" 即可.然后记录下自己的APP_ID.API_KEY.SECRET_KEY,就可以开始了. 调用glob库 glob库用
-
python3.7中安装paddleocr及paddlepaddle包的多种方法
升级pip pip版本必须升级到20.0.4版本才能应用: 方法一.在pycharm中对pip进行升级: 方法二.通过命令进行升级 python3.7 -m pip install --upgrade pip 下载paddleOCR 下载链接:https://github.com/PaddlePaddle/PaddleOCR 打开paddleOCR文件夹中requirements.txt文件,更改文件中opencv-python为opencv-python == 4.2.0.32,因为支持pad
-
Python图像处理之图片文字识别功能(OCR)
OCR与Tesseract介绍 将图片翻译成文字一般被称为光学文字识别(Optical Character Recognition,OCR).可以实现OCR 的底层库并不多,目前很多库都是使用共同的几个底层OCR 库,或者是在上面进行定制. Tesseract 是一个OCR 库,目前由Google 赞助(Google 也是一家以OCR 和机器学习技术闻名于世的公司).Tesseract 是目前公认最优秀.最精确的开源OCR 系统. 除 了极高的精确度,Tesseract 也具有很高的灵活性.它可
-
Python 图片文字识别的实现之PaddleOCR
目录 项目使用 项目结构 环境部署 1.安装Anaconda,构造虚拟环境 2.依赖包下载 测试代码 参数补充 总结 前言 什么是OCR? 光学字符识别(Optical Character Recognition, OCR),是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程.简而言之,检测图像中的文本资料,并且识别出文本的内容. 那么有哪些应用场景呢? 其实我们日常生活中处处都有ocr的影子,比如在疫情期间身份证识别录入信息.车辆车牌号识别.自动驾驶等.我们的生活中,机器学习已
-
Python调用百度OCR实现图片文字识别的示例代码
百度AI提供了一天50000次的免费文字识别额度,可以愉快的免费使用!下面直接上方法: 首先在百度AI创建一个应用,按照下图创建即可,创建后会获得如下: 创建后会获得如下信息: APP_ID = '******' API_KEY = '************' SECRET_KEY = '**************' 下面就是百度API包的安装,在终端cmd输入如下语句直接pip方式安装,注意是 baidu-api 哦! pip install --user baidu-aip 接下来上py
-
Python3一行代码实现图片文字识别的示例
自学Python3第5天,今天突发奇想,想用Python识别图片里的文字.没想到Python实现图片文字识别这么简单,只需要一行代码就能搞定 from PIL import Image import pytesseract #上面都是导包,只需要下面这一行就能实现图片文字识别 text=pytesseract.image_to_string(Image.open('denggao.jpeg'),lang='chi_sim') print(text) 我们以识别诗词为例 下面是我们要识别的图片 先
-
python图片验证码识别最新模块muggle_ocr的示例代码
一.官方文档 https://pypi.org/project/muggle-ocr/ 二模块安装 pip install muggle-ocr # 因模块过新,阿里/清华等第三方源可能尚未更新镜像,因此手动指定使用境外源,为了提高依赖的安装速度,可预先自行安装依赖:tensorflow/numpy/opencv-python/pillow/pyyaml 三.使用代码 # 导入包 import muggle_ocr # 初始化:model_type 包含了 ModelType.OCR/Model
-
Android实现图片文字识别
导言 OCR,tess-two ,openCV等晕人的东西先分清,OCR,tess-two是图片文字识别,而openCV是图像识别比对,对于更复杂的图片文字识别需求可以采用百度云人工智能通用文字识别开发的SDK,准确性更高 可运行的步骤 1.添加依赖 implementation 'com.rmtheis:tess-two:8.0.0' 2.下载字体识别库(chi_sim.traineddata 中文简体,chi_tra.traineddata 中文繁体,eng.traineddata 英文库)
-
Java使用Tessdata做OCR图片文字识别的详细思路
说到文字识别,目前除了用一些现成的api,大概就是 tessdata.canvas或者 ocrad等. 1.百度接口用过(可以自己去百度开发者申请,免费的),识别率吧,还可以,但也不是百分百的,但是次数使用有限制,虽然也是够用,但是被限制总是害怕超过不让用. 2.canvas的话是需要对图片做具体的处理,涉及到图片的翻转.置灰.文字间隔的设定等等,成功率很高,但是公司产品验证码是各式各样的,没办法用这种方法处理,所以暂时放弃了. 3.ocrad这个目前用过其.js版本,识别率还是比较低的,具体使
-
SpringBoot+OCR 实现图片文字识别
本篇介绍的是基于百度人工智能接口的文字识别实现. 1. 注册百度云,获得AppID 此处百度云非百度云盘,而是百度智能云. 大家可进入https://cloud.baidu.com/自行注册,这里就不多说了. 接下来,我们进行应用的创建 所需接口根据实际勾选,我们暂时只需前四个即可. 2. 日常demo操作 pom.xml: <dependencies> <!-- 百度人工智能依赖 --> <!-- https://mvnrepository.com/artifact/com
-
java实现图片文字识别ocr
最近在开发的时候需要识别图片中的一些文字,网上找了相关资料之后,发现google有一个离线的工具,以下为java使用的demo 在此之前,使用这个工具需要在本地安装OCR工具: 下面一个是一定要安装的离线包,建议默认安装 上面一个是中文的语言包,如果网络可以FQ的童鞋可以在安装的时候就选择语言包在线安装,有多种语言可供选择,默认只有英文的 exe安装好之后,把上面一个文件拷到安装目录下tessdata文件夹下 如C:\Program Files (x86)\Tesseract-OCR\tessd