详解MySQL自增主键的实现
目录
- 一、自增值保存在哪儿?
- 二、自增值修改机制
- 三、自增值的修改时机
- 四、自增锁的优化
- 五、自增主键用完了
一、自增值保存在哪儿?
不同的引擎对于自增值的保存策略不同
1.MyISAM引擎的自增值保存在数据文件中
2.InnoDB引擎的自增值,在MySQL5.7及之前的版本,自增值保存在内存里,并没有持久化。每次重启后,第一次打开表的时候,都会去找自增值的最大值max(id),然后将max(id)+步长作为这个表当前的自增值
select max(ai_col) from table_name for update;
在MySQL8.0版本,将自增值的变更记录在了redo log中,重启的时候依靠redo log恢复重启之前的值
二、自增值修改机制
如果字段id被定义为AUTO_INCREMENT,在插入一行数据的时候,自增值的行为如下:
1.如果插入数据时id字段指定为0、null或未指定值,那么就把这个表当前的AUTO_INCREMENT值填到自增字段
2.如果插入数据时id字段指定了具体的值,就直接使用语句里指定的值
假设,某次要插入的值是X,当前的自增值是Y
1.如果X<Y,那么这个表的自增值不变
2.如果X>=Y,就需要把当前自增值修改为新的自增值
新的自增值生成算法是:从auto_increment_offset(初始值)开始,以auto_increment_increment(步长)为步长,持续叠加,直到找到第一个大于X的值,作为新的自增值
三、自增值的修改时机
创建一个表t,其中id是自增主键字段、c是唯一索引,建表语句如下:
CREATE TABLE `t` ( `id` int(11) NOT NULL AUTO_INCREMENT, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `c` (`c`) ) ENGINE=InnoDB;
假设,表t里面已经有了(1,1,1)这条记录,这时再执行一条插入数据命令:
insert into t values(null, 1, 1);
执行流程如下:
1.执行器调用InnoDB引擎接口写入一行,传入的这一行的值是(0,1,1)
2.InnoDB发现用于没有指定自增id的值,获取表t当前的自增值2
3.将传入的行的值改成(2,1,1)
4.将表的自增值改成3
5.继续执行插入数据操作,由于已经存在c=1的记录,所以报Duplicate key error(唯一键冲突),语句返回
对应的执行流程图如下:
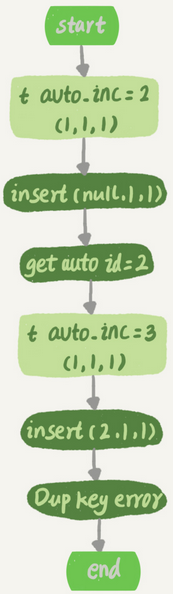
在这之后,再插入新的数据行时,拿到的自增id就是3。出现了自增主键不连续的情况
唯一键冲突和事务回滚都会导致自增主键id不连续的情况
四、自增锁的优化
自增id锁并不是一个事务锁,而是每次申请完就马上释放,以便允许别的事务再申请
但在MySQL5.0版本的时候,自增锁的范围是语句级别。也就是说,如果一个语句申请了一个表自增锁,这个锁会等语句执行结束以后才释放
MySQL5.1.22版本引入了一个新策略,新增参数innodb_autoinc_lock_mode,默认值是1
1.这个参数设置为0,表示采用之前MySQL5.0版本的策略,即语句执行结束后才释放锁
2.这个参数设置为1
- 普通insert语句,自增锁在申请之后就马上释放
- 类似insert … select这样的批量插入数据的语句,自增锁还是要等语句结束后才被释放
3.这个参数设置为2,所有的申请自增主键的动作都是申请后就释放锁
为了数据的一致性,默认设置为1

如果sessionB申请了自增值以后马上就释放自增锁,那么就可能出现这样的情况:
- sessionB先插入了两行数据(1,1,1)、(2,2,2)
- sessionA来申请自增id得到id=3,插入了(3,5,5)
- 之后,sessionB继续执行,插入两条记录(4,3,3)、(5,4,4)
当binlog_format=statement的时候,两个session是同时执行插入数据命令的,所以binlog里面对表t2的更新日志只有两种情况:要么先记sessionA的,要么先记录sessionB的。无论是哪一种,这个binlog拿到从库执行,或者用来恢复临时实例,备库和临时实例里面,sessionB这个语句执行出来,生成的结果里面,id都是连续的。这时,这个库就发生了数据不一致
解决这个问题的思路:
1)让原库的批量插入数据语句,固定生成连续的id值。所以,自增锁直到语句执行结束才释放,就是为了达到这个目的
2)在binlog里面把插入数据的操作都如实记录进来,到备库执行的时候,不再依赖于自增主键去生成。也就是把innodb_autoinc_lock_mode设置为2,同时binlog_format设置为row
如果有批量插入数据(insert … select、replace … select和load data)的场景时,从并发插入数据性能的角度考虑,建议把innodb_autoinc_lock_mode设置为2,同时binlog_format设置为row,这样做既能并发性,又不会出现数据一致性的问题
对于批量插入数据的语句,MySQL有一个批量申请自增id的策略:
1.语句执行过程中,第一次申请自增id,会分配1个
2.1个用完以后,这个语句第二次申请自增id,会分配2个
3.2个用完以后,还是这个语句,第三次申请自增id,会分配4个
4.依次类推,同一个语句去申请自增id,每次申请到的自增id个数都是上一次的两倍
insert into t values(null, 1,1); insert into t values(null, 2,2); insert into t values(null, 3,3); insert into t values(null, 4,4); create table t2 like t; insert into t2(c,d) select c,d from t; insert into t2 values(null, 5,5);
insert … select,实际上往表t2中插入了4行数据。但是,这四行数据是分三次申请的自增id,第一次申请到了id=1,第二次被分配了id=2和id=3,第三次被分配到id=4到id=7
由于这条语句实际上只用上了4个id,所以id=5到id=7就被浪费掉了。之后,再执行insert into t2 values(null, 5,5),实际上插入了的数据就是(8,5,5)
这是主键id出现自增id不连续的第三种原因
五、自增主键用完了
自增主键字段在达到定义类型上限后,再插入一行记录,则会报主键冲突的错误
以无符号整型(4个字节,上限就是 2 32 − 1 2^{32}-1 232−1)为例,通过下面这个语句序列验证一下:
CREATE TABLE t ( id INT UNSIGNED auto_increment PRIMARY KEY ) auto_increment = 4294967295; INSERT INTO t VALUES(NULL); INSERT INTO t VALUES(NULL);
第一个insert语句插入数据成功后,这个表的AUTO_INCREMENT没有改变(还是4294967295),就导致了第二个insert语句又拿到相同的自增id值,再试图执行插入语句,报主键冲突错误
推荐资料:
https://time.geekbang.org/column/article/80531
到此这篇关于详解MySQL自增主键的实现的文章就介绍到这了,更多相关MySQL自增主键内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

mysql非主键自增长用法实例分析
本文实例讲述了mysql非主键自增长用法.分享给大家供大家参考,具体如下: mysql并非只有主键才能自增长,而是设为键的列就可以设置自增长. 如下: CREATE TABLE t1 ( id INT, col1 INT auto_increment NOT NULL ); 结果如下: 如果把col1列设为键,就可以创建自增. CREATE TABLE t1 ( id INT, col1 INT auto_increment NOT NULL, key(col1) ); 结果如下: 如果我们
-
深入探寻mysql自增列导致主键重复问题的原因
废话少说,进入正题. 拿到问题后,首先查看现场,发现问题表的中记录的最大值比自增列的值要大,那么很明显,当有记录进行插入时,自增列产生的值就有可能与已有的记录主键冲突,导致出错.首先想办法解决问题,通过人工调大自增列的值,保证大于表内已有的主键即可,调整后,导数据正常.问题是解决了,接下来要搞清楚问题原因,什么操作导致了这种现象的发生呢? 这里有一种可能,即业务逻辑包含更新自增主键的代码,由于mysql的update动作不会同时更新自增列值,若更新主键值比自增列大,也会导致上述现象:记录最大值比
-
MySQL的自增ID(主键) 用完了的解决方法
在 MySQL 中用很多类型的自增 ID,每个自增 ID 都设置了初始值.一般情况下初始值都是从 0 开始,然后按照一定的步长增加(一般是自增 1).一般情况下,我们都是用int(11)来作为数据表的自增 ID,在 MySQL 中只要定义了这个数的字节长度,那么就会有上限. MySQL的自增ID(主键) 用完了,怎么办? 如果用 int unsigned (int,4个字节 ), 我们可以算下最大当前声明的自增ID最大是多少,由于这里定义的是 int unsigned,所以最大可以达到2的32幂
-
MySQL中的主键以及设置其自增的用法教程
1.声明主键的方法: 您可以在创建表的时候就为表加上主键,如: CREATE TABLE tbl_name ([字段描述省略...], PRIMARY KEY(index_col_name)); 也可以更新表结构时为表加上主键,如: ALTER TABLE tbl_name ADD PRIMARY KEY (index_col_name,-); /* 创建一个qq表,将qq_id设为主键,且没有对其进行NOT NULl约束 */ create table qq( qq_id int(10), n
-
Mysql主键UUID和自增主键的区别及优劣分析
引言 之前有段时间用postgresql 数据库,在上云之后,从自增主键变为uuid,感觉uuid全球唯一,很方便. 最近用mysql,发现mysql主键都是选择自增主键,仔细比较一下,为什么mysql选择自增主键,有什么不同. 在mysql5.0之前,如果是多个master复制的环境,无法用自增主键,因为可能重复.在5.0以及之后的版本通过配置自增偏移量解决了整个问题. 什么情况下我们希望用uuid 1. 避免重复,便于scale,这就是我们做cloud service的时候选择uuid的主要
-
浅谈MySQL中的自增主键用完了怎么办
在面试中,大家应该经历过如下场景 面试官:"用过mysql吧,你们是用自增主键还是UUID?" 你:"用的是自增主键" 面试官:"为什么是自增主键?" 你:"因为采用自增主键,数据在物理结构上是顺序存储,性能最好,blabla-" 面试官:"那自增主键达到最大值了,用完了怎么办?" 你:"what,没复习啊!!" (然后,你就可以回去等通知了!) 这个问题是一个粉丝给我提的,我觉得
-
深入谈谈MySQL中的自增主键
MySQL的主键可以是自增的,那么如果在断电重启后新增的值还会延续断电前的自增值吗?自增值默认为1,那么可不可以改变呢?下面就说一下 MySQL的自增值. 特点 保存策略 1.如果存储引擎是 MyISAM,那么这个自增值是存储在数据文件中的: 2.如果是 InnoDB引擎,1)在 5.6之前是存储在内存中,没有持久化,在重启后会去找最大的键值,举个例子,如果一个表当前数据行里最大 id是10,AUTO_INCREMENT=11.这时候,我们删除 id=10 的行,AUTO_INCREMENT 还
-
详解MySQL自增主键的实现
目录 一.自增值保存在哪儿? 二.自增值修改机制 三.自增值的修改时机 四.自增锁的优化 五.自增主键用完了 一.自增值保存在哪儿? 不同的引擎对于自增值的保存策略不同 1.MyISAM引擎的自增值保存在数据文件中 2.InnoDB引擎的自增值,在MySQL5.7及之前的版本,自增值保存在内存里,并没有持久化.每次重启后,第一次打开表的时候,都会去找自增值的最大值max(id),然后将max(id)+步长作为这个表当前的自增值 select max(ai_col) from table_name
-
详解MySQL 表中非主键列溢出情况监控
今天,又掉坑了. 之前踩到过MySQL主键溢出的情况,通过prometheus监控起来了,具体见这篇MySQL主键溢出复盘 这次遇到的坑,更加的隐蔽. 是一个log表里面的一个int signed类型的列写满了.快速的解决方法当然还是只能切新表来救急了,然后搬迁老表的部分历史数据到热表. 亡羊补牢,处理完故障后,赶紧写脚本把生产的其他表都捋一遍. 下面是我暂时用的一个检测脚本,还不太完善,凑合用 分2个文件(1个sql文件,1个shell脚本) check.sql 内容如下: SELECT ca
-
图文详解MySQL中的主键与事务
一.MySQL 主键和表字段的注释 1.主键及自增 每一张表通常会有一个且只有一个主键,来表示每条数据的唯一性. 特性:值不能重复,不能为空 null 格式:create table test (ID int primary key) 1 主键 + 自增的写法: 格式:create table test (ID int primary key auto_increment) 1 注意:自增只能配合主键来使用(如果单独定义则会报错) 2.表字段的注释 mysql> alter table test
-
使用prometheus统计MySQL自增主键的剩余可用百分比
最近生产环境一套数据库因为疯狂写日志数据,造成主键值溢出的情况出现,因此有必要将这个指标监控起来. mysqld_exporter自带的这个功能,下面是我使用的启动参数: nohup ./mysqld_exporter --config.my-cnf="./my.cnf" --web.listen-address=":9104" --collect.heartbeat --collect.auto_increment.columns --collect.binlog
-
Mysql自增主键id不是以此逐级递增的处理
Mysql自增主键id不是以此逐级递增 一.介绍 在mysql数据库添加数据时使用ON DUPLICATE KEY UPDATE进行数据更新时可能会出现id不是逐级以此递增的,而是间断递增. 如id从10下次添加可能就是15或者其他的数字,两个数字之间间隔是ON DUPLICATE KEY UPDATE执行的次数,也就是说ON DUPLICATE KEY UPDATE在执行更新的时候把该表主键进行自增加一. 如图所示 二.问题介绍 在对于同一个表进行新增和修改时我用了两个mapper接口方法,也
-
为什么mysql自增主键不是连续的
目录 一 前言 二 自增值存储说明 三 自增值修改机制 四 自增值修改时机 五 导致自增值不连续的原因 5.1 唯一键冲突 5.2 事务回滚 5.3 批量写库操作 六 参考文档 一 前言 提出这个问题,是因为在工作中发现 mysql 中的 user 表的 id 默认是自增的,但是数据库存储的结果却不是连续的. user 表结构: CREATE TABLE `user` ( `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT '递增id
-
面试官问订单ID是如何生成的?难道不是MySQL自增主键
一个美女面试官坐到我的对面,发光logo的MacBook也挡不住她那圆润可爱的脸庞. 程序媛本就稀有,美女面试官更是难寻. 这么温柔可爱的面试官,应该不会为难我吧.嗯,应该是的,毕竟我这么帅气,面试可能就是走个过场.美女面试官是不是单身?毕竟程序员都不善交流,因为我也是单身,难道我的姻缘就在此注定.孩子的名字我都想好了.一冰!好名字. 面试官: 小伙子,你低着头笑什么呐.开始面试了,你知道订单ID是怎么生成的吗? 啥?订单ID怎么生成?美女怎么不按套路出牌!HashMap实现原理,我已经倒背如流
-
详解mysql数据库增删改操作
插入数据 insert into 表名(列名1,列名2,列名3) values(值1,值2,值3); insert into user(user_id,name,age) values(1,'nice',24); 简单写法可以省去字段名,但是要插入全部字段. 批量插入 单条插入和批量插入的效率问题 mysql多条数据插入效率大于单条数据插入 删除记录 delete from 表名 [where 条件] 如果没有指定条件,会将表中数据一条一条全部删除掉. delete删除数据和truncate删除
-
详解MySQL中的外键约束问题
使用MySQL开发过数据库驱动的小型web应用程序的人都知道,对关系数据库的表进行创建.检索.更新和删除等操作都是些比较简单的过程.理论上,只要掌握了最常见的SQL语句的用法,并熟悉您选择使用的服务器端脚本语言,就足以应付对MySQL表所需的各种操作了,尤其是当您使用了快速MyISAM数据库引擎的时候.但是,即使在最简单的情况下,事情也要比我们想象的要复杂得多.下面我们用一个典型的例子进行说明.假设您正在运行一个博客网站,您几乎天天更新,并且该站点允许访问者评论您的帖子. MySQL外键约束条件
-
MySQL8自增主键变化图文详解
目录 一.简述 二.MySQL自增主键 为什么MySQL8新特性会修改自增主键属性? 如何解决自增主键冲突问题? 三.自增主键测试 1.MySQL5.7自增主键 2.MySQL8自增主键 总结 一.简述 MySQL版本从5直接大跃进到8,相信MySQL8一定会有很多令人意想不到的改进,如果不想只会CRUD可以看看. 比如系统表引擎的变化-全部换成事务型的InnoDB. MySQL5.7系统部引擎 MySQL8系统引擎 上图可以看到,MySQL5.7的系统表引擎有MEMORY.InnnoDB和My