pytorch教程resnet.py的实现文件源码分析
目录
- 调用pytorch内置的模型的方法
- 解读模型源码Resnet.py
- 包含的库文件
- 该库定义了6种Resnet的网络结构
- 每种网络都有训练好的可以直接用的.pth参数文件
- Resnet中大多使用3*3的卷积定义如下
- 如何定义不同大小的Resnet网络
- 定义Resnet18
- 定义Resnet34
- Resnet类
- 网络的forward过程
- 残差Block连接是如何实现的
调用pytorch内置的模型的方法
import torchvision model = torchvision.models.resnet50(pretrained=True)
这样就导入了resnet50的预训练模型了。如果只需要网络结构,不需要用预训练模型的参数来初始化
那么就是:
model = torchvision.models.resnet50(pretrained=False)
如果要导入densenet模型也是同样的道理
比如导入densenet169,且不需要是预训练的模型:
model = torchvision.models.densenet169(pretrained=False)
由于pretrained参数默认是False,所以等价于:
model = torchvision.models.densenet169()
不过为了代码清晰,最好还是加上参数赋值。
解读模型源码Resnet.py
包含的库文件
import torch.nn as nn import math import torch.utils.model_zoo as model_zoo
该库定义了6种Resnet的网络结构
包括
__all__ = ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101', 'resnet152']
每种网络都有训练好的可以直接用的.pth参数文件
__all__ = ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101', 'resnet152']
Resnet中大多使用3*3的卷积定义如下
def conv3x3(in_planes, out_planes, stride=1): """3x3 convolution with padding""" return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride, padding=1, bias=False)
该函数继承自nn网络中的2维卷积,这样做主要是为了方便,少写参数参数由原来的6个变成了3个
输出图与输入图长宽保持一致
如何定义不同大小的Resnet网络
Resnet类是一个基类,
所谓的"Resnet18", ‘resnet34', ‘resnet50', ‘resnet101', 'resnet152'只是Resnet类初始化的时候使用了不同的参数,理论上我们可以根据Resnet类定义任意大小的Resnet网络
下面先看看这些不同大小的Resnet网络是如何定义的
定义Resnet18
def resnet18(pretrained=False, **kwargs):
"""
Constructs a ResNet-18 model.
Args:
pretrained (bool):If True, returns a model pre-trained on ImageNet
"""
model = ResNet(BasicBlock, [2, 2, 2, 2], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet18']))
return model
定义Resnet34
def resnet34(pretrained=False, **kwargs):
"""Constructs a ResNet-34 model.
Args: pretrained (bool): If True, returns a model pre-trained on ImageNet """
model = ResNet(BasicBlock, [3, 4, 6, 3], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet34']))
return model
我们发现Resnet18和Resnet34的定义几乎是一样的,下面我们把Resnet18,Resnet34,Resnet50,Resnet101,Resnet152,不一样的部分写在一块进行对比
model = ResNet(BasicBlock, [2, 2, 2, 2], **kwargs) #Resnet18 model = ResNet(BasicBlock, [3, 4, 6, 3], **kwargs) #Resnet34 model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs) #Eesnt50 model = ResNet(Bottleneck, [3, 4, 23, 3], **kwargs) #Resnet101 model = ResNet(Bottleneck, [3, 8, 36, 3], **kwargs) #Resnet152
代码看起来非常的简洁工整,
其他resnet18、resnet101等函数和resnet18基本类似,差别主要是在:
1、构建网络结构的时候block的参数不一样,比如resnet18中是[2, 2, 2, 2],resnet101中是[3, 4, 23, 3]。
2、调用的block类不一样,比如在resnet50、resnet101、resnet152中调用的是Bottleneck类,而在resnet18和resnet34中调用的是BasicBlock类,这两个类的区别主要是在residual结果中卷积层的数量不同,这个是和网络结构相关的,后面会详细介绍。
3、如果下载预训练模型的话,model_urls字典的键不一样,对应不同的预训练模型。因此接下来分别看看如何构建网络结构和如何导入预训练模型。
Resnet类
构建ResNet网络是通过ResNet这个类进行的。ResNet类是继承PyTorch中网络的基类:torch.nn.Module。
构建Resnet类主要在于重写 init() 和 forward() 方法。
我们构建的所有网络比如:VGG,Alexnet等都需要重写这两个方法,这两个方法很重要
看起来Resne类是整个文档的核心
下面我们就要研究一下Resnet基类是如何实现的
Resnet类采用了pytorch定义网络模型的标准结构,包含
iinit()方法: 定义了网络的各个层
forward()方法: 定义了前向传播过程
这两个方法的用法,这个可以查看pytorch的官方文档就可以明白
在Resnet类中,还包含一个自定义的方法make_layer()方法
是用来构建ResNet网络中的4个blocks。
_make_layer方法的第一个输入block是Bottleneck或BasicBlock类
第二个输入是该blocks的输出channel
第三个输入是每个blocks中包含多少个residual子结构,因此layers这个列表就是前面resnet50的[3, 4, 6, 3]。
_make_layer方法中比较重要的两行代码是:
layers.append(block(self.inplanes, planes, stride, downsample))
该部分是将每个blocks的第一个residual结构保存在layers列表中。
for i in range(1, blocks): layers.append(block(self.inplanes, planes))
该部分是将每个blocks的剩下residual 结构保存在layers列表中,这样就完成了一个blocks的构造。这两行代码中都是通过Bottleneck这个类来完成每个residual的构建
接下来介绍Bottleneck类
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7, stride=1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
下面我们分别看看这两个过程:
网络的forward过程
def forward(self, x): #x代表输入
x = self.conv1(x) #进过卷积层1
x = self.bn1(x) #bn1层
x = self.relu(x) #relu激活
x = self.maxpool(x) #最大池化
x = self.layer1(x) #卷积块1
x = self.layer2(x) #卷积块2
x = self.layer3(x) #卷积块3
x = self.layer4(x) #卷积块4
x = self.avgpool(x) #平均池化
x = x.view(x.size(0), -1) #二维变成变成一维向量
x = self.fc(x) #全连接层
return x
里面的大部分我们都可以理解,只有layer1-layer4是Resnet网络自己定义的,
它也是Resnet残差连接的精髓所在,我们来分析一下layer层是怎么实现的
残差Block连接是如何实现的
从前面的ResNet类可以看出,在构造ResNet网络的时候,最重要的是 BasicBlock这个类,因为ResNet是由residual结构组成的,而 BasicBlock类就是完成residual结构的构建。同样 BasicBlock还是继承了torch.nn.Module类,且重写了__init__()和forward()方法。从forward方法可以看出,bottleneck就是我们熟悉的3个主要的卷积层、BN层和激活层,最后的out += residual就是element-wise add的操作。
这部分在 BasicBlock类中实现,我们看看这层是如何前向传播的
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
我画个流程图来表示一下
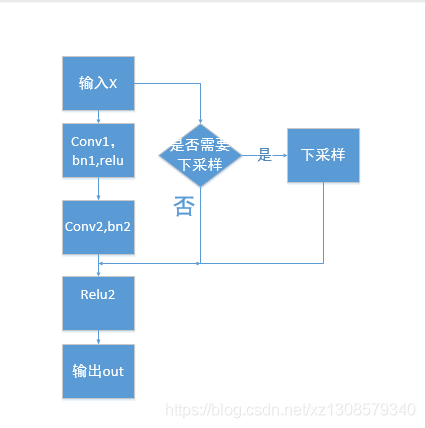
画的比较丑,不过基本意思在里面了,
根据论文的描述,x是否需要下采样由x与out是否大小一样决定,
假如进过conv2和bn2后的结果我们称之为 P
假设x的大小为wHchannel1
如果P的大小也是wHchannel1
则无需下采样
out = relu(P + X)
out的大小为W * H *(channel1+channel2),
如果P的大小是W/2 * H/2 * channel
则X需要下采样后才能与P相加,
out = relu(P+ X下采样)
out的大小为W/2 * H/2 * (channel1+channel2)
BasicBlock类和Bottleneck类类似,前者主要是用来构建ResNet18和ResNet34网络,因为这两个网络的residual结构只包含两个卷积层,没有Bottleneck类中的bottleneck概念。因此在该类中,第一个卷积层采用的是kernel_size=3的卷积,就是我们之前提到的conv3x3函数。
下面是BasicBlock类的完整代码
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
以上就是pytorch教程resnet.py的实现文件源码解读的详细内容,更多关于pytorch源码解读的资料请关注我们其它相关文章!
相关推荐
-
关于PyTorch源码解读之torchvision.models
PyTorch框架中有一个非常重要且好用的包:torchvision,该包主要由3个子包组成,分别是:torchvision.datasets.torchvision.models.torchvision.transforms. 这3个子包的具体介绍可以参考官网: http://pytorch.org/docs/master/torchvision/index.html. 具体代码可以参考github: https://github.com/pytorch/vision/tree/master/
-

pytorch实现ResNet结构的实例代码
1.ResNet的创新 现在重新稍微系统的介绍一下ResNet网络结构. ResNet结构首先通过一个卷积层然后有一个池化层,然后通过一系列的残差结构,最后再通过一个平均池化下采样操作,以及一个全连接层的得到了一个输出.ResNet网络可以达到很深的层数的原因就是不断的堆叠残差结构而来的. 1)亮点 网络中的亮点 : 超深的网络结构( 突破1000 层) 提出residual 模块 使用Batch Normalization 加速训练( 丢弃dropout) 但是,一般来说,并不是一直的加深神经
-
PyTorch数据读取的实现示例
前言 PyTorch作为一款深度学习框架,已经帮助我们实现了很多很多的功能了,包括数据的读取和转换了,那么这一章节就介绍一下PyTorch内置的数据读取模块吧 模块介绍 pandas 用于方便操作含有字符串的表文件,如csv zipfile python内置的文件解压包 cv2 用于图片处理的模块,读入的图片模块为BGR,N H W C torchvision.transforms 用于图片的操作库,比如随机裁剪.缩放.模糊等等,可用于数据的增广,但也不仅限于内置的图片操作,也可以自行进行图片数
-
关于ResNeXt网络的pytorch实现
此处需要pip install pretrainedmodels """ Finetuning Torchvision Models """ from __future__ import print_function from __future__ import division import torch import torch.nn as nn import torch.optim as optim import numpy as np im
-
PyTorch实现ResNet50、ResNet101和ResNet152示例
PyTorch: https://github.com/shanglianlm0525/PyTorch-Networks import torch import torch.nn as nn import torchvision import numpy as np print("PyTorch Version: ",torch.__version__) print("Torchvision Version: ",torchvision.__version__) _
-
pytorch教程resnet.py的实现文件源码分析
目录 调用pytorch内置的模型的方法 解读模型源码Resnet.py 包含的库文件 该库定义了6种Resnet的网络结构 每种网络都有训练好的可以直接用的.pth参数文件 Resnet中大多使用3*3的卷积定义如下 如何定义不同大小的Resnet网络 定义Resnet18 定义Resnet34 Resnet类 网络的forward过程 残差Block连接是如何实现的 调用pytorch内置的模型的方法 import torchvision model = torchvision.models
-
ZooKeeper框架教程Curator分布式锁实现及源码分析
目录 如何使用InterProcessMutex 实现思路 代码实现概述 InterProcessMutex源码分析 实现接口 属性 构造方法 方法 获得锁 释放锁 LockInternals源码分析 获取锁 释放锁 总结 ZooKeeper入门教程一简介与核心概念 ZooKeeper入门教程二在单机和集群环境下的安装搭建及使用 ZooKeeper入门教程三分布式锁实现及完整运行源码 上一篇文章中,我们使用zookeeper的java api实现了分布式排他锁. Curator中有着更为标准.规
-
Pytorch搭建YoloV4目标检测平台实现源码
目录 什么是YOLOV4 YOLOV4结构解析 1.主干特征提取网络Backbone 2.特征金字塔 3.YoloHead利用获得到的特征进行预测 4.预测结果的解码 5.在原图上进行绘制 YOLOV4的训练 1.YOLOV4的改进训练技巧 a).Mosaic数据增强 b).Label Smoothing平滑 c).CIOU d).学习率余弦退火衰减 2.loss组成 a).计算loss所需参数 b).y_pre是什么 c).y_true是什么. d).loss的计算过程 训练自己的YoloV4
-
Pytorch搭建yolo3目标检测平台实现源码
目录 yolo3实现思路 一.预测部分 1.主题网络darknet53介绍 2.从特征获取预测结果 3.预测结果的解码 4.在原图上进行绘制 二.训练部分 1.计算loss所需参数 2.pred是什么 3.target是什么. 4.loss的计算过程 训练自己的YoloV3模型 一.数据集的准备 二.数据集的处理 三.开始网络训练 四.训练结果预测 yolo3实现思路 一起来看看yolo3的Pytorch实现吧,顺便训练一下自己的数据. 源码下载 一.预测部分 1.主题网络darknet53介绍
-
Hadoop源码分析六启动文件namenode原理详解
1. namenode启动 在本系列文章三中分析了hadoop的启动文件,其中提到了namenode启动的时候调用的类为 org.apache.hadoop.hdfs.server.namenode.NameNode 其main方法的内容如下: public static void main(String argv[]) throws Exception { if (DFSUtil.parseHelpArgument(argv, NameNode.USAGE, System.out, true)
-
SpringBoot源码分析之bootstrap.properties文件加载的原理
目录 1.bootstrap的使用 2.bootstrap加载原理分析 2.1 BootstrapApplicationListener 2.2 启动流程梳理 2.3 bootstrap.properties的加载原理 对于SpringBoot中的属性文件相信大家在工作中用的是比较多的,对于application.properties和application.yml文件应该非常熟悉,但是对于bootstrap.properties文件和bootstrap.yml这个两个文件用的估计就比较少了
-
go 压缩解压zip文件源码示例
目录 压缩zip 解压zip 压缩zip func Zip(dest string, paths ...string) error { zfile, err := os.Create(dest) if err != nil { return err } defer zfile.Close() zipWriter := zip.NewWriter(zfile) defer zipWriter.Close() for _, src := range paths { // remove the tra
-
SpringBoot拦截器与文件上传实现方法与源码分析
目录 一.拦截器 1.创建一个拦截器 2.配置拦截器 二.拦截器原理 三.文件上传 四.文件上传流程 一.拦截器 拦截器我们之前在springmvc已经做过介绍了 大家可以看下[SpringMVC]自定义拦截器和过滤器 为什么在这里还要再讲一遍呢? 因为spring boot里面对它做了简化,大大节省了我们配置那些烦人的xml文件的时间 接下来,我们就通过一个小例子来了解一下拦截器在spring boot中的使用 1.创建一个拦截器 首先我们创建一个拦截器,实现HandlerIntercepto
-
redis源码分析教程之压缩链表ziplist详解
前言 压缩列表(ziplist)是由一系列特殊编码的内存块构成的列表,它对于Redis的数据存储优化有着非常重要的作用.这篇文章总结一下redis中使用非常多的一个数据结构压缩链表ziplist.该数据结构在redis中说是无处不在也毫不过分,除了链表以外,很多其他数据结构也是用它进行过渡的,比如前面文章提到的SortedSet.下面话不多说了,来一起看看详细的介绍吧. 一.压缩链表ziplist数据结构简介 首先从整体上看下ziplist的结构,如下图: 压缩链表ziplist结构图 可以看出
-
Django模型验证器介绍与源码分析
前言 在Django的模型字段参数中,有一个参数叫做validators,这个参数是用来指定当前字段需要使用的验证器,也就是对字段数据的合法性进行验证,比如大小.类型等. Django的验证器可以分为模型相关的验证器和表单相关的验证器,它们基本类似,但在使用上有区别. 本文讨论的是模型相关的验证器. 一.自定义验证器 一个验证器其实就是一个可调用的对象(函数或类),接收一个初始输入值作为参数,对这个值进行一系列逻辑判断,如果不满足某些规则或者条件,则表示验证不通过,抛出一个ValidationE