关于python爬虫应用urllib库作用分析
目录
- 一、urllib库是什么?
- 二、urllib库的使用
- urllib.request模块
- urllib.parse模块
- 利用try-except,进行超时处理
- status状态码 && getheaders()
- 突破反爬
一、urllib库是什么?
urllib库用于操作网页 URL,并对网页的内容进行抓取处理
urllib包 包含以下几个模块:
urllib.request - 打开和读取 URL。
urllib.error - 包含 urllib.request 抛出的异常。
urllib.parse - 解析 URL。
urllib.robotparser - 解析 robots.txt 文件
python爬虫主要用到的urllib库中的request和parse模块
二、urllib库的使用
下面我们来详细说明一下这两个常用模块的基本运用
urllib.request模块
urllib.request 定义了一些打开 URL 的函数和类,包含授权验证、重定向、浏览器 cookies等。
语法如下:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None,
capath=None, cadefault=False, context=None)
url:url 地址。
data:发送到服务器的其他数据对象,默认为 None。
timeout:设置访问超时时间。
cafile 和 capath:cafile 为 CA 证书, capath 为 CA 证书的路径,使用 HTTPS 需要用到。
cadefault:已经被弃用。
context:ssl.SSLContext类型,用来指定 SSL 设置。
# -*- codeing = utf-8 -*-
# @Author: Y-peak
# @Time : 2021/9/2 19:24
# @FileName : testUrllib.py
# Software : PyCharm
import urllib.request
#get请求
response = urllib.request.urlopen("http://www.baidu.com") #返回的是存储网页数据的对象
#print(response) 可以尝试打印一下看一下
print(response.read().decode('utf-8')) #通过read将数据读取出来, 使用utf-8解码防止有的地方出现乱码
将其打印的内容写到一个html文件中,打开和百度一毛一样
# -*- codeing = utf-8 -*-
# @Author: Y-peak
# @Time : 2021/9/2 19:24
# @FileName : testUrllib.py
# Software : PyCharm
import urllib.request
response = urllib.request.urlopen("http://www.baidu.com") #返回的是存储网页数据的对象
data = response.read().decode('utf-8') #通过read将数据读取出来, 使用utf-8解码防止有的地方出现乱码
#print(data)
with open("index.html",'w',encoding='utf-8') as wfile: #或者你们也可以常规打开,不过需要最后关闭记得close()
wfile.write(data)
print("读取结束")
urllib.parse模块
有时我们爬虫需要模拟浏览器进行用户登录等操作,这个时候我们就需要进行post请求
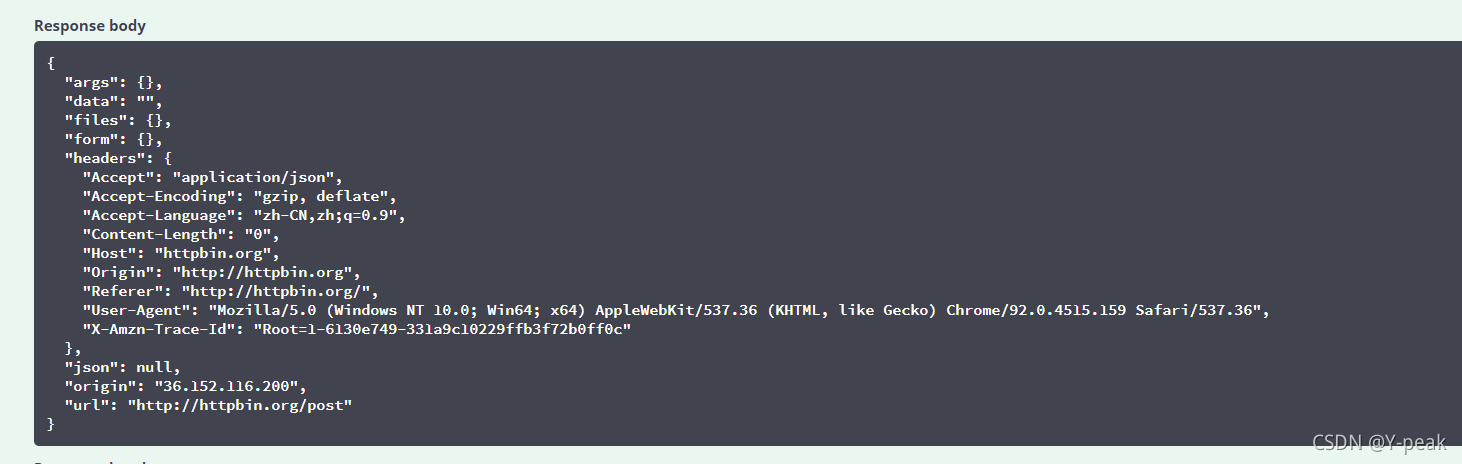
但是post必须有一个获取请求之后的响应,也就是我们需要有一个服务器。给大家介绍一个免费的服务器网址,就是用来测试用的http://httpbin.org/。主要用来测试http和https的

我们可以尝试执行一下,去获取对应的响应。


可以用Linux命令去发起请求,URL地址为http://httpbin.org/post。得到下方的响应。

我们也可以通过爬虫来实现
# -*- codeing = utf-8 -*-
# @Author: Y-peak
# @Time : 2021/9/2 19:24
# @FileName : testUrllib.py
# Software : PyCharm
import urllib.request
import urllib.parse #解析器
data = bytes(urllib.parse.urlencode({"hello":"world"}),encoding='utf-8') #转换为二进制数据包,里面是键值对(有时输入的用户名:密码就是这样的),还有一些编码解码的数值等.这里就是按照utf-8的格式进行解析封装生成二进制数据包
response = urllib.request.urlopen("http://httpbin.org/post",data=data) #返回的请求
print(response.read().decode('utf-8')) #通过read将数据读取出来, 使用utf-8解码防止有的地方出现乱码
两个响应结果对比是不是一样几乎
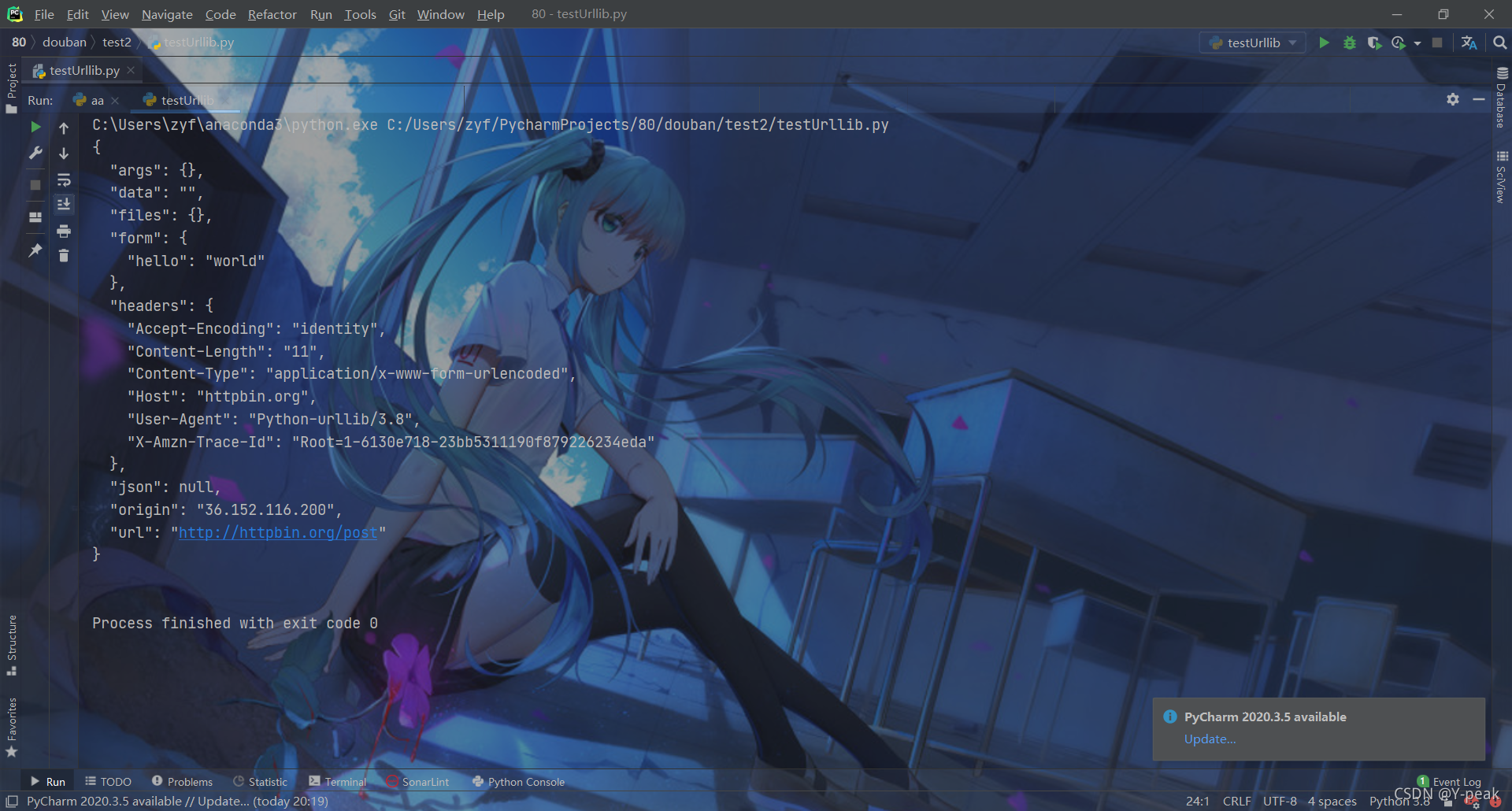

相当于进行了一次模拟的post请求。这样有些需要登录的网站也是可以爬取的。
利用try-except,进行超时处理
一般进行爬虫时,不可能一直等待响应。有时网络不好或者网页有反爬或者一些其他东西时。无法快速爬出。我们就可以进入下一个网页继续去爬。利用timeout属性就好
# -*- codeing = utf-8 -*-
# @Author: Y-peak
# @Time : 2021/9/2 19:24
# @FileName : testUrllib.py
# Software : PyCharm
import urllib.request
try:
response = urllib.request.urlopen("http://httpbin.org/get",timeout=0.01) #返回的是存储网页数据的对象, 直接用这个网址的get请求了.timeout表示超时,超过0.01秒不响应就报错,避免持续等待
print(response.read().decode('utf-8')) #通过read将数据读取出来, 使用utf-8解码防止有的地方出现乱码
except urllib.error.URLError as e:
print("超时了\t\t错误为:",e)
status状态码 && getheaders()
status:
- 返回200,正确响应可以爬取
- 报错404,没有找到网页
- 报错418,老子知道你就是爬虫
- getheaders():获取Response Headers
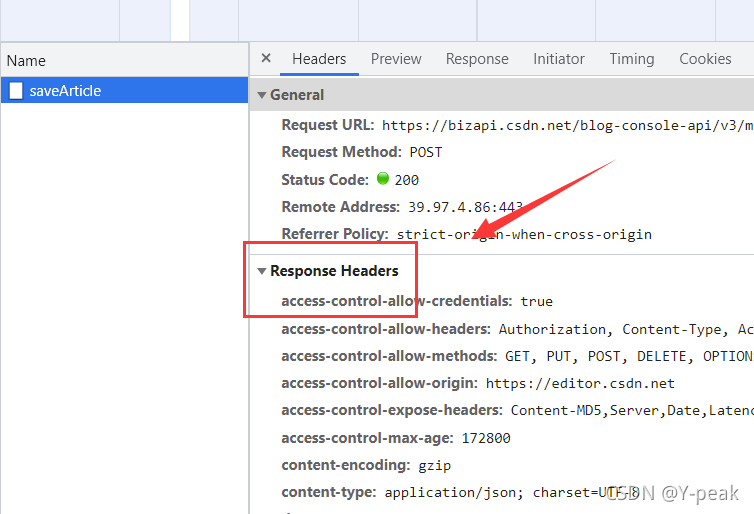
- 也可以通过gethead(“xx”) 获取xx对应的值,比如:上图 gethead(content-encoding) 为 gzip
突破反爬
首先打开任何一个网页按F12找到Response Headers,拉到最下面找到 User-Agent。将其复制保存下来,为反爬做准备。


下面我们进行尝试,直接爬取豆瓣,直接来个418,知道你是爬虫,我们来伪装一下
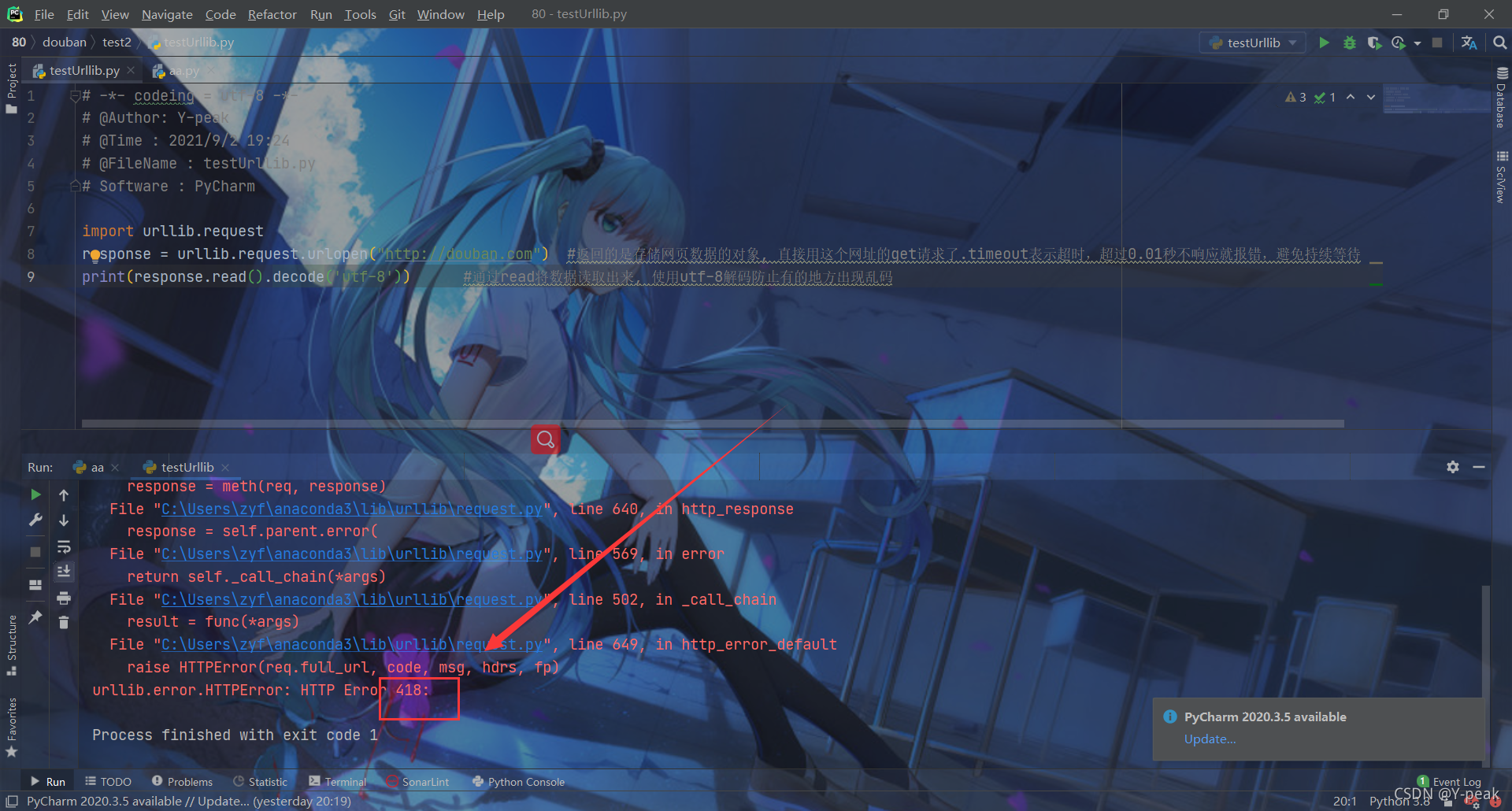
为什么418呢,因为如果是直接进行请求访问的话,发过去的User-Agent 是下面的,直接告诉浏览器我们是爬虫。我们需要伪装
# -*- codeing = utf-8 -*-
# @Author: Y-peak
# @Time : 2021/9/2 19:24
# @FileName : testUrllib.py
# Software : PyCharm
import urllib.request
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36"
}
request = urllib.request.Request("http://douban.com", headers=headers) #返回的是请求,将我们伪装成浏览器发送的请求
response = urllib.request.urlopen(request) #返回的是存储网页数据的对象
data = response.read().decode('utf-8') #通过read将数据读取出来, 使用utf-8解码防止有的地方出现乱码
with open("index.html",'w',encoding='utf-8') as wfile: #或者你们也可以常规打开,不过需要最后关闭记得close()
wfile.write(data)
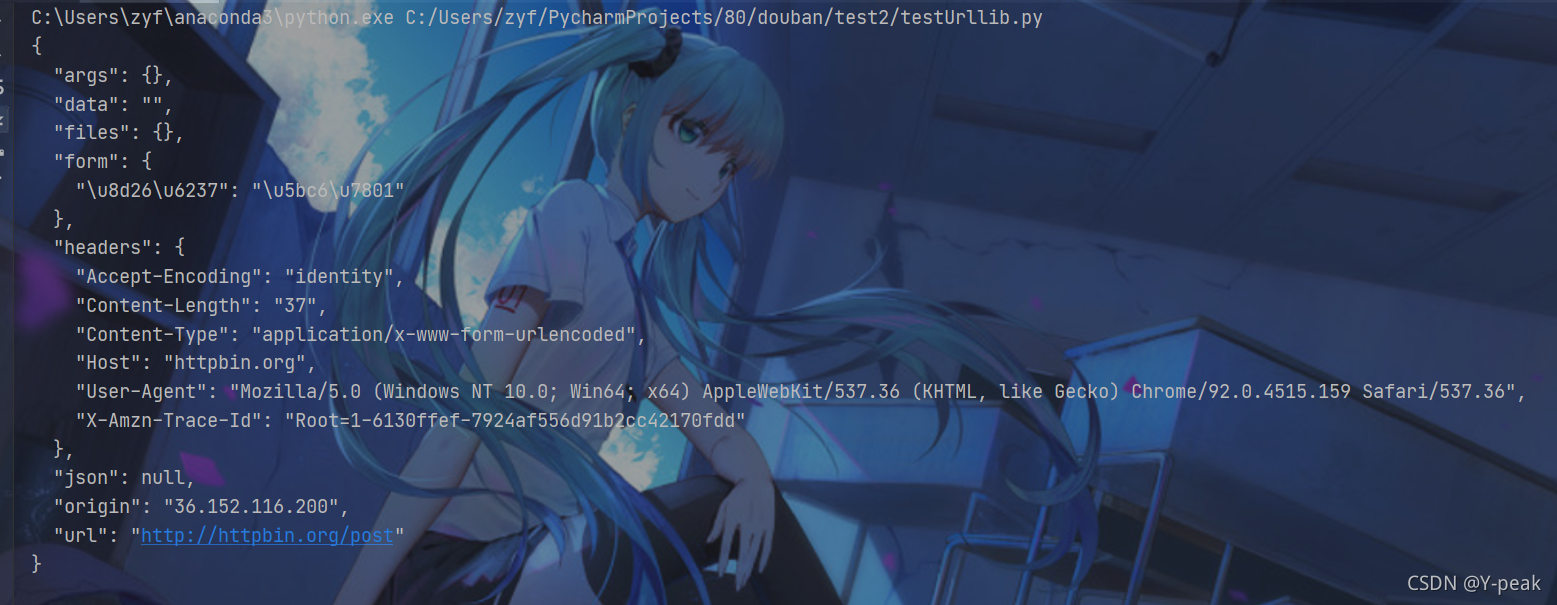
当然反爬不可能如此简单,上面将讲的那个 post请求,也是十分常见的突破反爬的方式,不行就将整个Response Headers全部模仿。下面还有个例子作为参考。和上面的post访问的网址一样
浏览器访问结果
爬虫访问结果
# -*- codeing = utf-8 -*-
# @Author: Y-peak
# @Time : 2021/9/3 0:47
# @FileName : testUrllib.py
# Software : PyCharm
import urllib.request
import urllib.parse
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36"
}
url = "http://httpbin.org/post"
data = (bytes)(urllib.parse.urlencode({"账户":"密码"}),encoding = 'utf-8')
request = urllib.request.Request(url, data = data,headers=headers, method='POST') #返回的是请求
response = urllib.request.urlopen(request) #返回的是存储网页数据的对象
data = response.read().decode('utf-8') #通过read将数据读取出来, 使用utf-8解码防止有的地方出现乱码
print(data)
以上就是关于python爬虫应用urllib库作用分析的详细内容,更多关于python爬虫urllib库分析的资料请关注我们其它相关文章!
相关推荐
-
python爬虫开发之urllib模块详细使用方法与实例全解
爬虫所需要的功能,基本上在urllib中都能找到,学习这个标准库,可以更加深入的理解后面更加便利的requests库. 首先 在Pytho2.x中使用import urllib2---对应的,在Python3.x中会使用import urllib.request,urllib.error 在Pytho2.x中使用import urllib---对应的,在Python3.x中会使用import urllib.request,urllib.error,urllib.parse 在Pytho2.x中使
-
Python爬虫中urllib库的进阶学习
urllib的基本用法 urllib库的基本组成 利用最简单的urlopen方法爬取网页html 利用Request方法构建headers模拟浏览器操作 error的异常操作 urllib库除了以上基础的用法外,还有很多高级的功能,可以更加灵活的适用在爬虫应用中,比如: 使用HTTP的POST请求方法向服务器提交数据实现用户登录 使用代理IP解决防止反爬 设置超时提高爬虫效率 解析URL的方法 本次将会对这些内容进行详细的分析和讲解. POST请求 POST是HTTP协议的请求方法之一,也是比较
-
python爬虫之urllib库常用方法用法总结大全
Urllib 官方文档地址:https://docs.python.org/3/library/urllib.html urllib提供了一系列用于操作URL的功能. 本文主要介绍的是关于python urllib库常用方法用法的相关内容,下面话不多说了,来一起看看详细的介绍吧 1.读取cookies import http.cookiejar as cj,urllib.request as request cookie = cj.CookieJar() handler = request.HT
-
python urllib爬虫模块使用解析
前言 网络爬虫也称为网络蜘蛛.网络机器人,抓取网络的数据.其实就是用Python程序模仿人点击浏览器并访问网站,而且模仿的越逼真越好.一般爬取数据的目的主要是用来做数据分析,或者公司项目做数据测试,公司业务所需数据. 而数据来源可以来自于公司内部数据,第三方平台购买的数据,还可以通过网络爬虫爬取数据.python在网络爬虫方向上有着成熟的请求.解析模块,以及强大的Scrapy网络爬虫框架. 爬虫分类 1.通用网络爬虫:搜索引擎使用,遵守robots协议(君子协议) robots协议 :网站通过r
-

关于python爬虫应用urllib库作用分析
目录 一.urllib库是什么? 二.urllib库的使用 urllib.request模块 urllib.parse模块 利用try-except,进行超时处理 status状态码 && getheaders() 突破反爬 一.urllib库是什么? urllib库用于操作网页 URL,并对网页的内容进行抓取处理 urllib包 包含以下几个模块: urllib.request - 打开和读取 URL. urllib.error - 包含 urllib.request 抛出的异常. ur
-
Python爬虫之urllib库详解
目录 一.说明: 二.urllib四个模块组成: 三.urllib.request 1.urlopen函数 2.response 响应类型 3.Request对象 4.高级请求方式 四.urllib.error 五.URL解析urllib.parse 六.urllib.robotparser 总结 一.说明: urllib库是python内置的一个http请求库,requests库就是基于该库开发出来的,虽然requests库使用更方便,但作为最最基本的请求库,了解一下原理和用法还是很有必要的.
-
python爬虫用request库处理cookie的实例讲解
python爬虫中使用urli库可以使用opener"发送多个请求,这些请求是能共享处理cookie的,小编之前也提过python爬虫中使用request库会比urllib库更加⽅便,使用使用requests也能达到共享cookie的目的,即使用request库get方法和使用requests库提供的session对象都可以处理. 方法一:使用request库get方法 resp = requests.get('http://www.baidu.com/') print(resp.cookies
-
Python爬虫之requests库基本介绍
目录 一.说明 二.基本用法: 总结 一.说明 requests是一个很实用的Python HTTP客户端库,爬虫和测试服务器响应数据时经常会用到,requests是Python语言的第三方的库,专门用于发送HTTP请求,使用起来比urllib简洁很多. Requests 有这些功能: 1.Keep-Alive & 连接池2.国际化域名和 URL3.带持久 Cookie 的会话4.浏览器式的 SSL 认证5.自动内容解码6.基本/摘要式的身份认证7.优雅的 key/value Cookie8.自
-
python爬虫之urllib,伪装,超时设置,异常处理的方法
Urllib 1. Urllib.request.urlopen().read().decode() 返回一个二进制的对象,对这个对象进行read()操作,可以得到一个包含网页的二进制字符串,然后用decode()解码成html源码 2. urlretrieve() 将一个网页爬取到本地 3. urlclearup() 清除 urlretrieve()所产生的缓存 4. info() 返回一个httpMessage对象,表示远程服务器的头信息 5. getcode() 获取当前网页的状态码 20
-
对python中的xlsxwriter库简单分析
一.xlsxwriter 基本用法,创建 xlsx 文件并添加数据 官方文档:http://xlsxwriter.readthedocs.org/ xlsxwriter 可以操作 xls 格式文件 注意:xlsxwriter 只能创建新文件,不可以修改原有文件.如果创建新文件时与原有文件同名,则会覆盖原有文件 Linux 下安装: sudo pip install XlsxWriter Windows 下安装: pip install XlsxWriter # coding=utf-8 from
-
Python爬虫之Selenium库的使用方法
Selenium 是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等.这个工具的主要功能包括:测试与浏览器的兼容性--测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上.测试系统功能--创建回归测试检验软件功能和用户需求.支持自动录制动作和自动生成 .Net.Java.Perl等不同语言的测试
-
python爬虫之selenium库的安装及使用教程
第一步:python中安装selenium库 和其他所有Python库一样,selenium库需要安装 pip install selenium # Windows电脑安装selenium pip3 install selenium # Mac电脑安装selenium 第二步:下载谷歌浏览器驱动并合理放置 selenium的脚本可以控制所有常见浏览器,在使用之前需要安装浏览器端的驱动 注意:驱动和浏览器要版本对应 推荐使用Chrome浏览器:谷歌浏览器驱动 打开chrome浏览器,在网址栏中输入