基于golang的轻量级工作流框架Fastflow
目录
- 为什么要开发 Fastflow
- Concept
- 工作流模型
- 工作流的要素
- Dag
- Task
- Action
- DagInstance
- 实例类型与Module
- GetStart
- 准备一个Mongo实例
- 运行 fastflow
- Basic
- Task与Task之间的通信
- 任务日志
- 使用Dag变量
- 分布式锁
Fastflow 是什么?用一句话来定义它:一个 基于golang协程、支持水平扩容的分布式高性能工作流框架。
它具有以下特点:
- 易用性:工作流模型基于 DAG 来定义,同时还提供开箱即用的 API,你可以随时通过 API 创建、运行、暂停工作流等,在开发新的原子能力时还提供了开箱即用的分布式锁功能
- 高性能:得益于 golang 的协程 与 channel 技术,fastflow 可以在单实例上并行执行数百、数千乃至数万个任务
- 可观测性:fastflow 基于 Prometheus 的 metrics 暴露了当前实例上的任务执行信息,比如并发任务数、任务分发时间等。
- 可伸缩性:支持水平伸缩,以克服海量任务带来的单点瓶颈,同时通过选举 Leader 节点来保障各个节点的负载均衡
- 可扩展性:fastflow 准备了部分开箱即用的任务操作,比如 http请求、执行脚本等,同时你也可以自行定义新的节点动作,同时你可以根据上下文来决定是否跳过节点(skip)
- 轻量:它仅仅是一个基础框架,而不是一个完整的产品,这意味着你可以将其很低成本融入到遗留项目而无需部署、依赖另一个项目,这既是它的优点也是缺点——当你真的需要一个开箱即用的产品时(比如 airflow),你仍然需要少量的代码开发才能使用
为什么要开发 Fastflow
组内有很多项目都涉及复杂的任务流场景,比如离线任务,集群上下架,容器迁移等,这些场景都有几个共同的特点:
流程耗时且步骤复杂,比如创建一个 k8s 集群,需要几十步操作,其中包含脚本执行、接口调用等,且相互存在依赖关系。
任务量巨大,比如容器平台每天都会有几十万的离线任务需要调度执行、再比如我们管理数百个K8S集群,几乎每天会有集群需要上下节点、迁移容器等。
我们尝试过各种解法:
- 硬编码实现:虽然工作量较小,但是只能满足某个场景下的特定工作流,没有可复用性。
- airflow:我们最开始的离线任务引擎就是基于这个来实现的,不得不承认它的功能很全,也很方便,但是存在几个问题
- 由 python 编写的,我们希望团队维护的项目能够统一语言,更有助于提升工作效率,虽然对一个有经验的程序员来说多语言并不是问题,但是频繁地在多个语言间来回切换其实是不利于高效工作的
- airflow 的任务执行是以 进程 来运行的,虽然有更好的隔离性,但是显然因此而牺牲了性能和并发度。
- 公司内的工作流平台:你可能想象不到一个世界前十的互联网公司,他们内部一个经历了数年线上考证的运维用工作流平台,会脆弱到承受不了上百工作流的并发,第一次压测就直接让他们的服务瘫痪,进而影响到其他业务的运维任务。据团队反馈称是因为我们的工作流组成太复杂,一个流包含数十个任务节点才导致了这次意外的服务过载,随后半年这个团队重写了一个新的v2版本。
当然 Github 上也还有其他的任务流引擎,我们也都评估过,无法满足需求。比如 kubeflow 是基于 Pod 执行任务的,比起 进程 更为重量,还有一些项目,要么就是没有经过海量数据的考验,要么就是没有考虑可伸缩性,面对大量任务的执行无法水平扩容。
Concept
工作流模型
fastflow 的工作流模型基于DAG(Directed acyclic graph),下图是一个简单的 DAG 示意图:
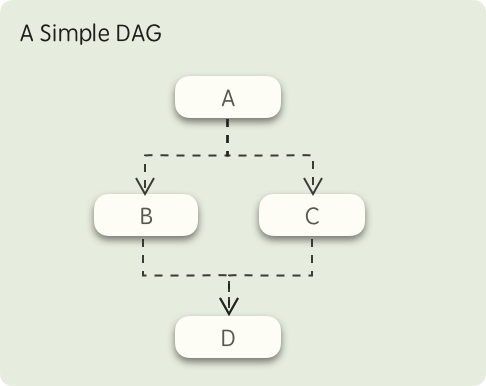
在这个图中,首先 A 节点所定义的任务会被执行,当 A 执行完毕后,B、C两个节点所定义的任务将同时被触发,而只有 B、C 两个节点都执行成功后,最后的 D 节点才会被触发,这就是 fastflow 的工作流模型。
工作流的要素
fastflow 执行任务的过程会涉及到几个概念:Dag, Task, Action, DagInstance
Dag
描述了一个完整流程,它的每个节点被称为 Task,它定义了各个 Task 的执行顺序和依赖关系,你可以通过编程 or yaml 来定义它
一个编程式定义的DAG
dag := &entity.Dag{
BaseInfo: entity.BaseInfo{
ID: "test-dag",
},
Name: "test",
Tasks: []entity.Task{
{ID: "task1", ActionName: "PrintAction"},
{ID: "task2", ActionName: "PrintAction", DependOn: []string{"task1"}},
{ID: "task3", ActionName: "PrintAction", DependOn: []string{"task2"}},
},
}
对应的yaml如下:
id: "test-dag" name: "test" tasks: - id: "task1" actionName: "PrintAction" - id: ["task2"] actionName: "PrintAction" dependOn: ["task1"] - id: "task3" actionName: "PrintAction" dependOn: ["task2"]
同时 Dag 可以定义这个工作流所需要的参数,以便于在各个 Task 去消费它:
id: "test-dag"
name: "test"
vars:
fileName:
desc: "the file name"
defaultValue: "file.txt"
filePath:
desc: "the file path"
defaultValue: "/tmp/"
tasks:
- id: "task1"
actionName: "PrintAction"
params:
writeName: "{{fileName}}"
writePath: "{{filePath}}"
Task
它定义了这个节点的具体工作,比如是要发起一个 http 请求,或是执行一段脚本等,这些不同动作都通过选择不同的 Action 来实现,同时它也可以定义在何种条件下需要跳过 or 阻塞该节点。
下面这段yaml演示了 Task 如何根据某些条件来跳过运行该节点。
id: "test-dag" name: "test" vars: fileName: desc: "the file name" defaultValue: "file.txt" tasks: - id: "task1" actionName: "PrintAction" preCheck: - act: skip #you can set "skip" or "block" conditions: - source: vars # source could be "vars" or "share-data" key: "fileName" op: "in" values: ["warn.txt", "error.txt"]
Task 的状态有以下几个:
- init: Task已经初始化完毕,等待执行
- running: 正在运行中
- ending: 当执行 Action 的 Run 所定义的内容后,会进入到该状态
- retrying: 任务重试中
- failed: 执行失败
- success: 执行成功
- blocked: 任务已阻塞,需要人工启动
- skipped: 任务已跳过
Action
Action 是工作流的核心,定义了该节点将执行什么操作,fastflow携带了一些开箱即用的Action,但是一般你都需要根据具体的业务场景自行编写,它有几个关键属性:
- Name: Required Action的名称,不可重复,它是与 Task 关联的核心
- Run: Required 需要执行的动作,fastflow 将确保该动作仅会被执行 一次(ExactlyOnce)
- RunBefore: Optional 在执行 Run 之前运行,如果有一些前置动作,可以在这里执行,RunBefore 有可能会被执行多次。
- RunAfter: Optional 在执行 Run 之后运行,一些长时间执行的任务内容建议放在这里,只要 Task 尚未结束,节点发生故障重启时仍然会继续执行这部分内容,
- RetryBefore:Optional 在重试失败的任务节点,可以提前执行一些清理的动作
自行开发的 Action 在使用前都必须先注册到 fastflow,如下所示:
type PrintParams struct {
Key string
Value string
}
type PrintAction struct {
}
// Name define the unique action identity, it will be used by Task
func (a *PrintAction) Name() string {
return "PrintAction"
}
func (a *PrintAction) Run(ctx run.ExecuteContext, params interface{}) error {
cinput := params.(*ActionParam)
fmt.Println("action start: ", time.Now())
fmt.Println(fmt.Sprintf("params: key[%s] value[%s]", cinput.Key, cinput.Value))
return nil
}
func (a *PrintAction) ParameterNew() interface{} {
return &PrintParams{}
}
func main() {
...
// Register action
fastflow.RegisterAction([]run.Action{
&PrintAction{},
})
...
}
DagInstance
当你开始运行一个 Dag 后,则会为本次执行生成一个执行记录,它被称为 DagInstance,当它生成以后,会由 Leader 实例将其分发到一个健康的 Worker,再由其解析、执行。
实例类型与Module
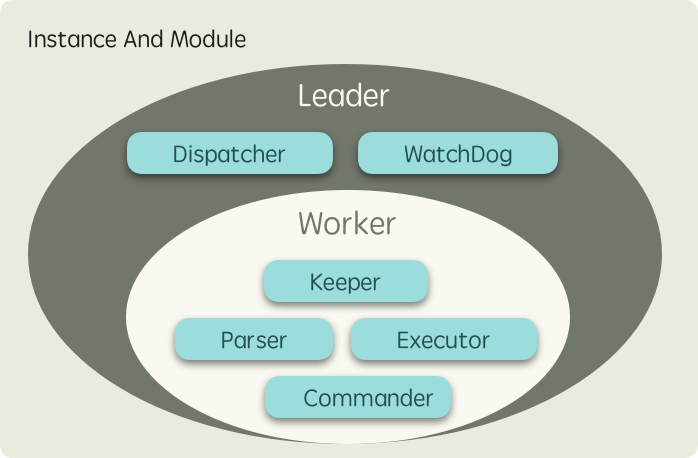
首先 fastflow 是一个分布式的框架,意味着你可以部署多个实例来分担负载,而实例被分为两类角色:
- Leader:此类实例在运行过程中只会存在一个,从 Worker 中进行选举而得出,它负责给 Worker 实例分发任务,也会监听长时间得不到执行的任务将其调度到其他节点等
- Worker:此类实例会存在复数个,它们负责解析 DAG 工作流并以
协程执行其中的任务
而不同节点能够承担不同的功能,其背后是不同的 模块 在各司其职,不同节点所运行的模块如下图所示:
NOTE
- Leader 实例本质上是一个承担了
仲裁者角色的 Worker,因此它也会分担工作负载。 - 为了实现更均衡的负载,以及获得更好的可扩展性,fastflow 没有选择加锁竞争的方式来实现工作分发
从上面的图看,Leader 实例会比 Worker 实例多运行一些模块用于执行中仲裁者相关的任务,模块之间的协作关系如下图所示:
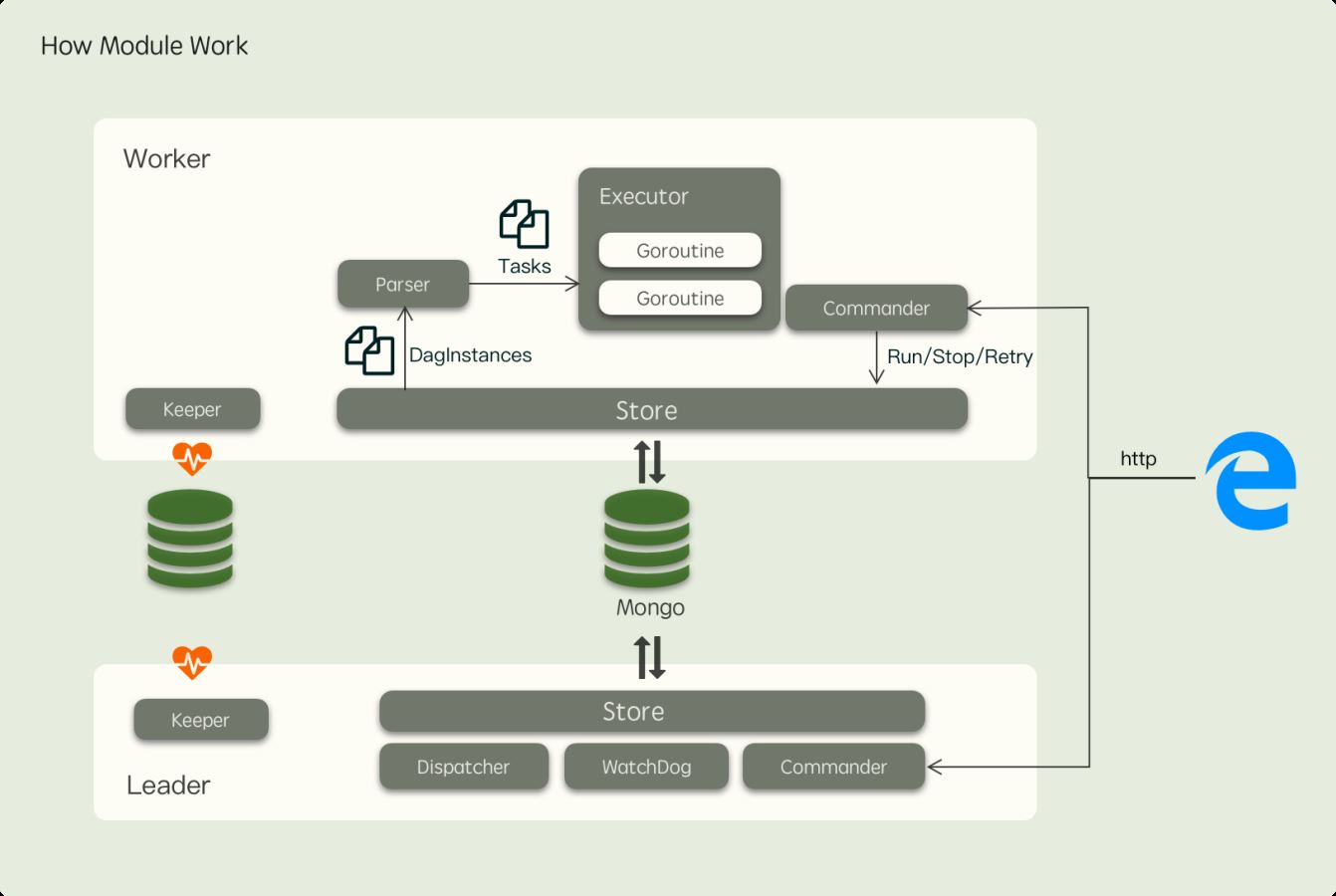
其中各个模块的职责如下:
- Keeper: 每个节点都会运行 负责注册节点到存储中,保持心跳,同时也会周期性尝试竞选 Leader,防止上任 Leader 故障后阻塞系统,这个模块同时也提供了 分布式锁 功能,我们也可以实现不同存储的 Keeper 来满足特定的需求,比如 Etcd or Zookeepper,目前支持的 Keeper 实现只有 Mongo
- Store: 每个节点都会运行 负责解耦 Worker 对底层存储的依赖,通过这个组件,我们可以实现利用 Mongo, Mysql 等来作为 fastflow 的后端存储,目前仅实现了 Mongo
- Parser:Worker 节点运行 负责监听分发到自己节点的任务,然后将其 DAG 结构重组为一颗 Task 树,并渲染好各个任务节点的输入,接下来通知 Executor 模块开始执行 Task
- Commander:每个节点都会运行 负责封装一些常见的指令,如停止、重试、继续等,下发到节点去运行
- Executor: Worker 节点运行 按照 Parser 解析好的 Task 树以 goroutine 运行单个的 Task
- Dispatcher:Leader节点才会运行 负责监听等待执行的 DAG,并根据 Worker 的健康状况均匀地分发任务
- WatchDog:Leader节点才会运行 负责监听执行超时的 Task 将其更新为失败,同时也会重新调度那些一直得不到执行的 DagInstance 到其他 Worker
Tips
以上模块的分布机制仅仅只是 fastflow 的默认实现,你也可以自行决定实例运行的模块,比如在 Leader 上不再运行 Worker 的实例,让其专注于任务调度。
GetStart
更多例子请参考项目下面的
examples目录
准备一个Mongo实例
如果已经你已经有了可测试的实例,可以直接替换为你的实例,如果没有的话,可以使用Docker容器在本地跑一个,指令如下:
docker run -d --name fastflow-mongo --network host mongo
运行 fastflow
运行以下示例
package main
import (
"fmt"
"log"
"time"
"github.com/shiningrush/fastflow"
mongoKeeper "github.com/shiningrush/fastflow/keeper/mongo"
"github.com/shiningrush/fastflow/pkg/entity/run"
"github.com/shiningrush/fastflow/pkg/mod"
mongoStore "github.com/shiningrush/fastflow/store/mongo"
)
type PrintAction struct {
}
// Name define the unique action identity, it will be used by Task
func (a *PrintAction) Name() string {
return "PrintAction"
}
func (a *PrintAction) Run(ctx run.ExecuteContext, params interface{}) error {
fmt.Println("action start: ", time.Now())
return nil
}
func main() {
// Register action
fastflow.RegisterAction([]run.Action{
&PrintAction{},
})
// init keeper, it used to e
keeper := mongoKeeper.NewKeeper(&mongoKeeper.KeeperOption{
Key: "worker-1",
// if your mongo does not set user/pwd, youshould remove it
ConnStr: "mongodb://root:pwd@127.0.0.1:27017/fastflow?authSource=admin",
Database: "mongo-demo",
Prefix: "test",
})
if err := keeper.Init(); err != nil {
log.Fatal(fmt.Errorf("init keeper failed: %w", err))
}
// init store
st := mongoStore.NewStore(&mongoStore.StoreOption{
// if your mongo does not set user/pwd, youshould remove it
ConnStr: "mongodb://root:pwd@127.0.0.1:27017/fastflow?authSource=admin",
Database: "mongo-demo",
Prefix: "test",
})
if err := st.Init(); err != nil {
log.Fatal(fmt.Errorf("init store failed: %w", err))
}
go createDagAndInstance()
// start fastflow
if err := fastflow.Start(&fastflow.InitialOption{
Keeper: keeper,
Store: st,
// use yaml to define dag
ReadDagFromDir: "./",
}); err != nil {
panic(fmt.Sprintf("init fastflow failed: %s", err))
}
}
func createDagAndInstance() {
// wait fast start completed
time.Sleep(time.Second)
// run some dag instance
for i := 0; i < 10; i++ {
_, err := mod.GetCommander().RunDag("test-dag", nil)
if err != nil {
log.Fatal(err)
}
time.Sleep(time.Second * 10)
}
}
程序运行目录下的test-dag.yaml
id: "test-dag" name: "test" tasks: - id: "task1" actionName: "PrintAction" - id: "task2" actionName: "PrintAction" dependOn: ["task1"] - id: "task3" actionName: "PrintAction" dependOn: ["task2"]
Basic
Task与Task之间的通信
由于任务都是基于 goroutine 来执行,因此任务之间的 context 是共享的,意味着你完全可以使用以下的代码:
func (a *UpAction) Run(ctx run.ExecuteContext, params interface{}) error {
ctx.WithValue("key", "value")
return nil
}
func (a *DownAction) Run(ctx run.ExecuteContext, params interface{}) error {
val := ctx.Context().Value("key")
return nil
}
但是注意这样做有个弊端:当节点重启时,如果任务尚未执行完毕,那么这部分内容会丢失。
如果不想因为故障or升级而丢失你的更改,可以使用 ShareData 来传递进行通信,ShareData 是整个 在整个 DagInstance 的生命周期都会共享的一块数据空间,每次对它的写入都会通过 Store 组件持久化,以确保数据不会丢失,用法如下:
func (a *UpAction) Run(ctx run.ExecuteContext, params interface{}) error {
ctx.ShareData().Set("key", "value")
return nil
}
func (a *DownAction) Run(ctx run.ExecuteContext, params interface{}) error {
val := ctx.ShareData().Get("key")
return nil
}
任务日志
fastflow 还提供了 Task 粒度的日志记录,这些日志都会通过 Store 组件持久化,用法如下:
func (a *Action) Run(ctx run.ExecuteContext, params interface{}) error {
ctx.Trace("some message")
return nil
}
使用Dag变量
上面的文章中提到,我们可以在 Dag 中定义一些变量,在创建工作流时可以对这些变量进行赋值,比如以下的Dag,定义了一个名为 `fileName 的变量
id: "test-dag" name: "test" vars: fileName: desc: "the file name" defaultValue: "file.txt"
随后我们可以使用 Commander 组件来启动一个具体的工作流:
mod.GetCommander().RunDag("test-id", map[string]string{
"fileName": "demo.txt",
})
这样本次启动的工作流的变量则被赋值为 demo.txt,接下来我们有两种方式去消费它
1.带参数的Action
id: "test-dag"
name: "test"
vars:
fileName:
desc: "the file name"
defaultValue: "file.txt"
tasks:
- id: "task1"
action: "PrintAction"
params:
# using {{var}} to consume dag's variable
fileName: "{{fileName}}"
PrintAction.go:
type PrintParams struct {
FileName string `json:"fileName"`
}
type PrintAction struct {
}
// Name define the unique action identity, it will be used by Task
func (a *PrintAction) Name() string {
return "PrintAction"
}
func (a *PrintAction) Run(ctx run.ExecuteContext, params interface{}) error {
cinput := params.(*ActionParam)
fmt.Println(fmt.Sprintf("params: file[%s]", cinput.FileName, cinput.Value))
return nil
}
func (a *PrintAction) ParameterNew() interface{} {
return &PrintParams{}
}
2.编程式读取
fastflow 也提供了相关函数来获取 Dag 变量
func (a *Action) Run(ctx run.ExecuteContext, params interface{}) error {
// get variable by name
ctx.GetVar("fileName")
// iterate variables
ctx.IterateVars(func(key, val string) (stop bool) {
...
})
return nil
}
分布式锁
如前所述,你可以在直接使用 Keeper 模块提供的分布式锁,如下所示:
...
mod.GetKeeper().NewMutex("mutex key").Lock(ctx.Context(),
mod.LockTTL(time.Second),
mod.Reentrant("worker-key1"))
...
其中:
LockTTL表示你持有该锁的TTL,到期之后会自动释放,默认30sReentrant用于需要实现可重入的分布式锁的场景,作为持有场景的标识,默认为空,表示该锁不可重入 欢迎转载,注明出处即可。如果你觉得这篇博文帮助到你了,请点下右下角的推荐让更多人看到它。
到此这篇关于基于golang的轻量级工作流框架Fastflow的文章就介绍到这了,更多相关go Fastflow内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

基于golang的轻量级工作流框架Fastflow
目录 为什么要开发 Fastflow Concept 工作流模型 工作流的要素 Dag Task Action DagInstance 实例类型与Module GetStart 准备一个Mongo实例 运行 fastflow Basic Task与Task之间的通信 任务日志 使用Dag变量 分布式锁 Fastflow 是什么?用一句话来定义它:一个 基于golang协程.支持水平扩容的分布式高性能工作流框架.它具有以下特点: 易用性:工作流模型基于 DAG 来定义,同时还提供开箱即用的 API
-
.NET Core基于EMIT编写的轻量级AOP框架CZGL.AOP
目录 1,快速入门 1.1继承ActionAttribute特性 1.2标记代理类型 2,如何创建代理类型 通过API直接创建 2,创建代理类型 通过API 通过Microsoft.Extensions.DependencyInjection 通过Autofac 3,深入使用 代理类型 方法.属性代理 上下文 拦截方法或属性的参数 非侵入式代理 Nuget 库地址:https://www.nuget.org/packages/CZGL.AOP/ Github 库地址:https://github
-
Spring Batch轻量级批处理框架实战
目录 1 实战前的理论基础 1.1 Spring Batch是什么 1.2 Spring Batch能做什么 1.3 基础架构 1.4 核心概念和抽象 2 各个组件介绍 2.1 Job 2.2 Step 2.3 ExecutionContext 2.4 JobRepository 2.5 JobLauncher 2.6 Item Reader 2.7 Item Writer 2.8 Item Processor 3 Spring Batch实战 3.1 依赖和项目结构以及配置文件 3.2 代码和
-
轻量级javascript 框架Backbone使用指南
Backbone 是一款基于模型-视图-控制器 MVC 模式的轻量级javascript 框架 ,可以用来帮助开发人员创建单页Web应用. 借助Backbone 我们可以使用REST的方式来最小化客户端和服务器间的数据传输,从而实现了更快加速的Web页面更新. 能心静下来学习了,以前以为Backbone 是一座高山用起来很难,结果只是学了2天就有一些新的,实在让人开心. 我整理了一下整个BackBone的学习记录在我的GIT里面,大部分事件都有例子并且有详细的注解和解释,结合require.js
-
Python轻量级ORM框架Peewee访问sqlite数据库的方法详解
本文实例讲述了Python轻量级ORM框架Peewee访问sqlite数据库的方法.分享给大家供大家参考,具体如下: ORM框架就是 object relation model,对象关系模型,用来实现把数据库中的表 映射到 面向对象编程语言中的类,不需要写sql,通过操作对象就能实现 增删改查. ORM的基本技术有3种: (1)映射技术 数据类型映射:就是把数据库中的数据类型,映射到编程语言中的数据类型.比如,把数据库的int类型映射到Python中的integer 类型. 类映射:把数据库中的
-
基于.NET平台常用的框架和开源程序整理
自从学习.NET以来,优雅的编程风格,极度简单的可扩展性,足够强大开发工具,极小的学习曲线,让我对这个平台产生了浓厚的兴趣,在工作和学习中也积累了一些开源的组件,就目前想到的先整理于此,如果再想到,就继续补充这篇日志,日积月累,就能形成一个自己的组件经验库. 分布式缓存框架: Microsoft Velocity:微软自家分布式缓存服务框架. Memcahed:一套分布式的高速缓存系统,目前被许多网站使用以提升网站的访问速度. Redis:是一个高性能的KV数据库. 它的出现很大程度补偿了Mem
-
c#基于Redis实现轻量级消息组件的步骤
最近在开发一个轻量级ASP.NET MVC开发框架,需要加入日志记录,邮件发送,短信发送等功能,为了保持模块的独立性,所以需要通过消息通信的方式进行处理,为了保持框架在部署,使用,二次开发过程中的简易便捷性,所以没有选择传统的MQ,而是基于Redis的订阅发布实现一个系统内部消息组件,话不多说,上码! 数据结构定义 消息实体包含几个部分,订阅通道名称,信息头,信息体,信息差异化额外信息字典,信息头主要包含消息标识,消息日期,信息体包含信息内容,信息实体类型等 public class Messa
-
基于springboot的flowable工作流实战流程分析
目录 背景 一.flowable-ui部署运行 二.绘制流程图 三.后台项目搭建 四.数据库 五.流程引擎API与服务 五.参考资料 背景 使用flowable自带的flowable-ui制作流程图 使用springboot开发流程使用的接口完成流程的业务功能 一.flowable-ui部署运行 flowable-6.6.0 运行 官方demo 参考文档:https://flowable.com/open-source/docs/bpmn/ch14-Applications/ 1.从官网下载fl
-
SpringBoot整合Activiti工作流框架的使用
目录 Activiti介绍 SpringBoot整合 使用starter 不使用starter 使用Activiti Activiti 介绍 Activiti是一个开源的工作流引擎,它实现了BPMN 2.0规范,可以发布设计好的流程定义,并通过api进行流程调度.Activiti 作为一个遵从 Apache 许可的工作流和业务流程管理开源平台,其核心是基于 Java 的超快速.超稳定的 BPMN2.0 流程引擎,强调流程服务的可嵌入性和可扩展性,同时更加强调面向业务人员. 简单来说activit
-
基于MyBatis的数据持久化框架的使用详解
目录 一.MyBatis是什么 1.1.概述 1.2.什么是持久化 1.3.什么是ORM 1.4.MyBatis主要内容 1.5.优点 1.6.缺点 二.MyBatis架构 2.1.mybatis所依赖的jar包 2.2.MyBatis准备工作 三.MyBatis 核心对象 一.MyBatis是什么 1.1.概述 Mybatis是一个优秀的开源.轻量级持久层框架,它对JDBC操作数据库的过程进行封装,简化了加载驱动.创建连接.创建 statement 等繁杂的过程,使开发者只需要关注sql本身.