利用Python实现模拟登录知乎
目录
- 环境与开发工具
- 模拟过程概述
- 参数探索
- 模拟源码
- 运行结果
- 结果一:密码错误
- 结果二:验证码错误
- 结果三:成功登录
环境与开发工具
在抓包的时候,开始使用的是Chrome开发工具中的Network,结果没有抓到,后来使用Fiddler成功抓取数据。下面逐步来细化上述过程。
模拟知乎登录前,先看看本次案例使用的环境及其工具:
- Windows 7 + Python 2.75
- Chrome + Fiddler: 用来监控客户端与服务器的通讯情况,以及查找相关参数的位置。
模拟过程概述
- 使用Google浏览器结合Fiddler来监控客户端与服务端的通讯过程;
- 根据监控结果,构造请求服务器过程中传递的参数;
- 使用Python模拟参数传递过程。
客户端与服务端通信过程的几个关键点:
- 登录时的url地址。
- 登录时提交的参数【params】,获取方式主要有两种:第一、分析页面源代码,找到表单标签及属性。适应比较简单的页面。第二、使用抓包工具,查看提交的url和参数,通常使用的是Chrome的开发者工具中的Network, Fiddler等。
- 登录后跳转的url。
参数探索
首先看看这个登录页面,也就是我们登录时的url地址。

看到这个页面,我们也可以大概猜测下请求服务器时传递了几个字段,很明显有:用户名、密码、验证码以及“记住我”这几个值。那么实际上有哪些呢?下面来分分析下。
首先查看一下HTML源码,Google里可以使用CTRL+U查看,然后使用CTRL+F输入input看看有哪些字段值,详情如下:

通过源码,我们可以看到,在请求服务器的过程中还携带了一个隐藏字段”_xsrf”。那么现在的问题是:这些参数在传递时是以什么名字传递的呢?这就需要借用其他工具抓包进行分析了。笔者是Windows系统,这里使用的是Fiddler(当然,你也可以使用其他的)。
抓包过程比较繁琐,因为抓到的东西比较多,很难快速的找到需要的信息。关于fiddler,很容易使用,有过不会,可以去百度搜一下。为了防止其他信息干扰,我们先将fiddler中的记录清除,然后输入用户名(笔者使用的是邮箱登录)、密码等信息登录,相应的在fiddler中会有如下结果:
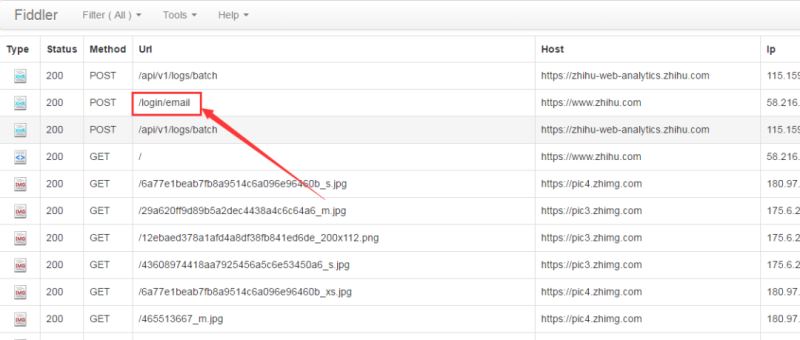
备注:如果是使用手机登录,则对应fiddler中的url是“/login/phone_num”。
为了查看详细的请求参数,我们左键单机“/login/email”,可以看到下列信息:

请求方式为POST,请求的url为https://www.zhihu.com/login/email。而从From Data可以看出,相应的字段名称如下:
- _xsrf
- captcha
- password
- remember
对于这五个字段,代码中email、password以及captcha都是手动输入的,remember初始化为true。剩下的_xsrf则可以根据登录页面的源文件,取input为_xsrf的value值即可。

对于验证码,则需要通过额外的请求,该链接可以通过定点查看源码看出:

链接为https://www.zhihu.com/captcha.gif?type=login,这里省略了ts(经测试,可省略掉)。现在,可以使用代码进行模拟登录。
温馨提示:如果使用的是手机号码进行登录,则请求的url为https://www.zhihu.com/login/phone_num,同时email字段名称将变成“phone_num”。
模拟源码
在编写代码实现知乎登录的过程中,笔者将一些功能封装成了一个简单的类WSpider,以便复用,文件名称为WSpider.py。
# -*- coding: utf-8 -*-
"""
Created on Thu Nov 02 14:01:17 2016
@author: liudiwei
"""
import urllib
import urllib2
import cookielib
import logging
class WSpider(object):
def __init__(self):
#init params
self.url_path = None
self.post_data = None
self.header = None
self.domain = None
self.operate = None
#init cookie
self.cookiejar = cookielib.LWPCookieJar()
self.opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cookiejar))
urllib2.install_opener(self.opener)
def setRequestData(self, url_path=None, post_data=None, header=None):
self.url_path = url_path
self.post_data = post_data
self.header = header
def getHtmlText(self, is_cookie=False):
if self.post_data == None and self.header == None:
request = urllib2.Request(self.url_path)
else:
request = urllib2.Request(self.url_path, urllib.urlencode(self.post_data), self.header)
response = urllib2.urlopen(request)
if is_cookie:
self.operate = self.opener.open(request)
resText = response.read()
return resText
"""
Save captcha to local
"""
def saveCaptcha(self, captcha_url, outpath, save_mode='wb'):
picture = self.opener.open(captcha_url).read() #用openr访问验证码地址,获取cookie
local = open(outpath, save_mode)
local.write(picture)
local.close()
def getHtml(self, url):
page = urllib.urlopen(url)
html = page.read()
return html
"""
功能:将文本内容输出至本地
@params
content:文本内容
out_path: 输出路径
"""
def output(self, content, out_path, save_mode="w"):
fw = open(out_path, save_mode)
fw.write(content)
fw.close()
"""#EXAMPLE
logger = createLogger('mylogger', 'temp/logger.log')
logger.debug('logger debug message')
logger.info('logger info message')
logger.warning('logger warning message')
logger.error('logger error message')
logger.critical('logger critical message')
"""
def createLogger(self, logger_name, log_file):
# 创建一个logger
logger = logging.getLogger(logger_name)
logger.setLevel(logging.INFO)
# 创建一个handler,用于写入日志文件
fh = logging.FileHandler(log_file)
# 再创建一个handler,用于输出到控制台
ch = logging.StreamHandler()
# 定义handler的输出格式formatter
formatter = logging.Formatter('%(asctime)s | %(name)s | %(levelname)s | %(message)s')
fh.setFormatter(formatter)
ch.setFormatter(formatter)
# 给logger添加handler
logger.addHandler(fh)
logger.addHandler(ch)
return logger
关于模拟登录知乎的源码,保存在zhiHuLogin.py文件,内容如下:
# -*- coding: utf-8 -*-
"""
Created on Thu Nov 02 17:07:17 2016
@author: liudiwei
"""
import urllib
from WSpider import WSpider
from bs4 import BeautifulSoup as BS
import getpass
import json
import WLogger as WLog
"""
2016.11.03 由于验证码问题暂时无法正常登陆
2016.11.04 成功登录,期间出现下列问题
验证码错误返回:{ "r": 1, "errcode": 1991829, "data": {"captcha":"验证码错误"}, "msg": "验证码错误" }
验证码过期:{ "r": 1, "errcode": 1991829, "data": {"captcha":"验证码回话无效 :(","name":"ERR_VERIFY_CAPTCHA_SESSION_INVALID"}, "msg": "验证码回话无效 :(" }
登录:{"r":0, "msg": "登录成功"}
"""
def zhiHuLogin():
spy = WSpider()
logger = spy.createLogger('mylogger', 'temp/logger.log')
homepage = r"https://www.zhihu.com/"
html = spy.opener.open(homepage).read()
soup = BS(html, "html.parser")
_xsrf = soup.find("input", {'type':'hidden'}).get("value")
#根据email和手机登陆得到的参数名不一样,email登陆传递的参数是‘email',手机登陆传递的是‘phone_num'
username = raw_input("Please input username: ")
password = getpass.getpass("Please input your password: ")
account_name = None
if "@" in username:
account_name = 'email'
else:
account_name = 'phone_num'
#保存验证码
logger.info("save captcha to local machine.")
captchaURL = r"https://www.zhihu.com/captcha.gif?type=login" #验证码url
spy.saveCaptcha(captcha_url=captchaURL, outpath="temp/captcha.jpg") #temp目录需手动创建
#请求的参数列表
post_data = {
'_xsrf': _xsrf,
account_name: username,
'password': password,
'remember_me': 'true',
'captcha':raw_input("Please input captcha: ")
}
#请求的头内容
header ={
'Accept':'*/*' ,
'Content-Type':'application/x-www-form-urlencoded; charset=UTF-8',
'X-Requested-With':'XMLHttpRequest',
'Referer':'https://www.zhihu.com/',
'Accept-Language':'en-GB,en;q=0.8,zh-CN;q=0.6,zh;q=0.4',
'Accept-Encoding':'gzip, deflate, br',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36',
'Host':'www.zhihu.com'
}
url = r"https://www.zhihu.com/login/" + account_name
spy.setRequestData(url, post_data, header)
resText = spy.getHtmlText()
jsonText = json.loads(resText)
if jsonText["r"] == 0:
logger.info("Login success!")
else:
logger.error("Login Failed!")
logger.error("Error info ---> " + jsonText["msg"])
text = spy.opener.open(homepage).read() #重新打开主页,查看源码可知此时已经处于登录状态
spy.output(text, "out/home.html") #out目录需手动创建
if __name__ == '__main__':
zhiHuLogin()
关于源码的分析,可以参考代码中的注解。
运行结果
在控制台中运行python zhiHuLogin.py,然后按提示输入相应的内容,最后可得到以下不同的结果(举了三个实例):
结果一:密码错误

结果二:验证码错误

结果三:成功登录

通过代码,可以成功的登录到知乎,接着如果要爬取知乎里面的内容,就比较方便了。
以上就是利用Python实现模拟登录知乎的详细内容,更多关于Python模拟登录知乎的资料请关注我们其它相关文章!
相关推荐
-

Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的文章,重点是如何解析页面和提高爬虫的效率.由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了一下python模拟登陆,网上关于这部分的资料很多,很多demo都是登陆知乎的,原因是知乎的登陆比较简单,只需要post几个参数,保存cookie.而且还没有进行加密,很适合用来做教学.我也是是新手,一点点的摸索终于成功登陆上了知乎.就通过这篇文章分享一下学习这部分的心得,希望对那些和我一样的初学者
-
python实现登陆知乎获得个人收藏并保存为word文件
这个程序其实很早之前就完成了,一直没有发出了,趁着最近不是很忙就分享给大家. 使用BeautifulSoup模块和urllib2模块实现,然后保存成word是使用python docx模块的,安装方式网上一搜一大堆,我就不再赘述了. 主要实现的功能是登陆知乎,然后将个人收藏的问题和答案获取到之后保存为word文档,以便没有网络的时候可以查阅.当然,答案中如果有图片的话也是可以获取到的.不过这块还是有点问题的.等以后有时间了在修改修改吧. 还有就是正则,用的简直不要太烂-鄙视下自己- 还有,现在是
-
python 利用浏览器 Cookie 模拟登录的用户访问知乎的方法
首先在火狐浏览器上登录知乎,然后使用火狐浏览器插件 Httpfox 获取 GET 请求的Cookie,这里注意使用状态值为 200(获取成功)的某次GET. 将 Cookies 复制出来,注意这一行非常长,不要人为添加换行符.而且 Cookie 中使用了双引号,最后复制到代码里使用单引号包起来. 使用下边代码检验是否是模拟了登录的用户的请求: import requests import re headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT
-
Python爬虫之模拟知乎登录的方法教程
前言 对于经常写爬虫的大家都知道,有些页面在登录之前是被禁止抓取的,比如知乎的话题页面就要求用户登录才能访问,而 "登录" 离不开 HTTP 中的 Cookie 技术. 登录原理 Cookie 的原理非常简单,因为 HTTP 是一种无状态的协议,因此为了在无状态的 HTTP 协议之上维护会话(session)状态,让服务器知道当前是和哪个客户在打交道,Cookie 技术出现了 ,Cookie 相当于是服务端分配给客户端的一个标识. 浏览器第一次发起 HTTP 请求时,没有携带任何 Co
-
利用Python实现模拟登录知乎
目录 环境与开发工具 模拟过程概述 参数探索 模拟源码 运行结果 结果一:密码错误 结果二:验证码错误 结果三:成功登录 环境与开发工具 在抓包的时候,开始使用的是Chrome开发工具中的Network,结果没有抓到,后来使用Fiddler成功抓取数据.下面逐步来细化上述过程. 模拟知乎登录前,先看看本次案例使用的环境及其工具: Windows 7 + Python 2.75 Chrome + Fiddler: 用来监控客户端与服务器的通讯情况,以及查找相关参数的位置. Github源码下载 模
-
利用Python优雅的登录校园网
前言 今天这篇文章的思路来源于校园网,很多的校园网在每次连接时都需要进入一个网址进行登录,这个步骤真的是非常非常的麻烦(大学生都懂~).所以这次来教大家如何实现一键登录校园网. 一键登录校园网 首先我们来看下整个的流程.首先需要进行网络连接,连接之后会跳转到一个网址,也就是校园网登录的网址. 然后输入账号密码登录. 我们需要做到的效果就是点击一个可执行文件然后实现校园网的自动登录.(这里的可执行文件在mac中为excu文件.win中为exe) 我们首先解决如何通过Python进行登录,然后再解决
-
Python实现模拟登录及表单提交的方法
本文实例讲述了Python实现模拟登录及表单提交的方法.分享给大家供大家参考.具体实现方法如下: # -*- coding: utf-8 -*- import re import urllib import urllib2 import cookielib #获取CSDN博客标题和正文 url = "http://blog.csdn.net/[username]/archive/2010/07/05/5712850.aspx" sock = urllib.urlopen(url) ht
-
Android利用爬虫实现模拟登录的实现实例
Android利用爬虫实现模拟登录的实现实例 为了用手机登录校网时不用一遍一遍的输入账号密码,于是决定用爬虫抓取学校登录界面,然后模拟填写本次保存的账号.密码,模拟点击登录按钮.实现过程折腾好几个. 一开始选择的是htmlunit解析登录界面html,在pc上测的能实现,结果在android上运行不起来,因为htmlunit利用了javax中的类实现的解析,android不支持javax,所以就跑不起来. 不过pc还是ok的 实例代码: package com.yasin; import jav
-
Python Requests模拟登录实现图书馆座位自动预约
本文实例为大家分享了Python实现图书馆座位自动预约的具体代码,供大家参考,具体内容如下 配置 通过公网主机定时运行脚本,并发送邮件到自己的qq邮箱,这样在微信就会有消息提示是否预约成功 vim /etc/crontab 设置每到早上7:01自动运行脚本即可 程序流程 (以yuyue.juneberry.cn网站为例) get访问登录页面,获取cookie和表单里面的隐藏post字段 构造登录post数据,加入从表单里面拿到的隐藏post字段 post构造后的数据,模拟登录,激活cookie(
-
Python实现模拟登录网易邮箱的方法示例
本文实例讲述了Python实现模拟登录网易邮箱的方法.分享给大家供大家参考,具体如下: #coding:utf-8 import urllib2,urllib import cookielib from bs4 import BeautifulSoup #设置代理IP proxy_support = urllib2.ProxyHandler({'http':'120.197.234.164:80'}) #设置cookie cookie_support = urllib2.HTTPCookiePr
-
如何利用Python动态模拟太阳系运转
前言 提到太阳系,大家可能会想到哥白尼和他的日心说,或是捍卫.发展日心说的斗士布鲁诺,他们像一缕光一样照亮了那个时代的夜空,对历史感兴趣的小伙伴可以深入了解一下,这里就不多说了. 太阳以巨大的引力使周边行星.卫星等绕其运转,构成了太阳系,它主要包括太阳.8 个行星.205 个卫星以及几十万个小行星等,本文我们使用 Python 来简单的动态模拟一下太阳系的运转. 实现 功能的实现,主要要到的还是 Python 的 pygame 库,我们先导入需要的所有 Python 库,代码如下所示: impo
-
python爬虫模拟登录之图片验证码实现详解
我们在用爬虫对门户网站进行模拟登录是总会有输入图片验证码的,例如这种 那我们怎么解决这个问题实现全自动的模拟登录呢?只要思想不滑坡,办法总比困难多.我这里使用的是百度智能云里面的文字识别功能,每天好像可以免费使用个几百次,识别效果也还行,对一般人而言是够用了. 接下来说说,怎么使用. 首先,打开百度智能云(https://cloud.baidu.com/)进行登入,再进入人工智能->文字识别里创建应用. 在使用名称和底下应用描述随便写写,然后点立即创建. 创建完成,就可以拿到 AppID .AP
-
Python爬虫模拟登录带验证码网站
爬取网站时经常会遇到需要登录的问题,这是就需要用到模拟登录的相关方法.python提供了强大的url库,想做到这个并不难.这里以登录学校教务系统为例,做一个简单的例子. 首先得明白cookie的作用,cookie是某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据.因此我们需要用Cookielib模块来保持网站的cookie. 这个是要登陆的地址 http://202.115.80.153/ 和验证码地址 http://202.115.80.153/CheckCode.