kafka的消息存储机制和原理分析
目录
- 消息的保存路径
- 数据分片
- log分段
- 日志和索引文件内容分析
- 在 partition 中通过 offset 查找 message过程
- 日志的清除策略以及压缩策略
- 日志的清理策略有两个
- 日志压缩策略
- 消息写入的性能
- 顺序写
- 零拷贝
消息的保存路径
消息发送端发送消息到 broker 上以后,消息是如何持久化的?
数据分片
kafka 使用日志文件的方式来保存生产者和发送者的消息,每条消息都有一个 offset 值来表示它在分区中的偏移量。
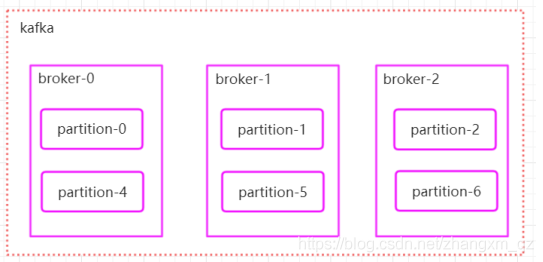
Kafka 中存储的一般都是海量的消息数据,为了避免日志文件过大,一个分片 并不是直接对应在一个磁盘上的日志文件,而是对应磁盘上的一个目录,这个目录的命名规则是<topic_name>_<partition_id>。
比如创建一个名为firstTopic的topic,其中有3个partition,那么在 kafka 的数据目录(/tmp/kafka-log)中就有 3 个目录,firstTopic-0~3
多个分区在集群中多个broker上的分配方法
1.将所有 N Broker 和待分配的 i 个 Partition 排序
2.将第 i 个 Partition 分配到第(i mod n)个 Broker 上
log分段
每个分片目录中,kafka 通过分段的方式将 数据 分为多个 LogSegment,一个 LogSegment 对应磁盘上的一个日志文件(00000000000000000000.log)和一个索引文件(如上:00000000000000000000.index),其中日志文件是用来记录消息的。索引文件是用来保存消息的索引。
每个LogSegment 的大小可以在server.properties 中log.segment.bytes=107370 (设置分段大小,默认是1gb)选项进行设置。

segment 的 index file 和 data file 2 个文件一一对应,成对出现,后缀".index"和“.log”分别表示为 segment 索引文件、数据文件.命名规则:partion 全局的第一个 segment从 0 开始,后续每个 segment 文件名为上一个 segment文件最后一条消息的 offset 值进行递增。数值最大为 64 位long 大小,20 位数字字符长度,没有数字用 0 填充
第一个 log 文件的最后一个 offset 为:5376,所以下一个segment 的文件命名为: 0000000000000005376.log。
对应的 index 为 00000000000000005376.index
kafka 这种分片和分段策略,避免了数据量过大时,数据文件文件无限扩张带来的隐患,更有助于消息文件的维护以及被消费的消息的清理。
日志和索引文件内容分析
通过下面这条命令可以看到 kafka 消息日志的内容
sh kafka-run-class.sh kafka.tools.DumpLogSegments --files /tmp/kafka-logs/test-0/00000000000000000000.log --print-data-log
输出结果为:
offset: 5376 position: 102124 CreateTime: 1531477349287isvalid: true keysize: -1 valuesize: 12 magic: 2compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: []payload: message_5376
可以看到一条消息,会包含很多的字段,如下:
offset: 5371 position: 102124 CreateTime: 1531477349286isvalid: true keysize: -1 valuesize: 12 magic: 2compresscodec: NONE producerId: -1 producerEpoch: -1 sequence: -1 isTransactional: false headerKeys: []payload: message_5371
各字段的意义:
offset:记录号 ;position:偏移量;createTime:创建时间、keysize和valuesize表示key和value的大小compresscodec:表示压缩编码payload:表示消息的具体内容
为了提高查找消息的性能,kafka为每一个日志文件添加 了2 个索引文件:OffsetIndex 和 TimeIndex,分别对应*.index以及*.timeindex, *.TimeIndex 是映射时间戳和相对 offset的文件
查看索引内容命令:
sh kafka-run-class.shkafka.tools.DumpLogSegments --files /tmp/kafka-logs/test-0/00000000000000000000.index --print-data-log
索引文件和日志文件内容关系如下
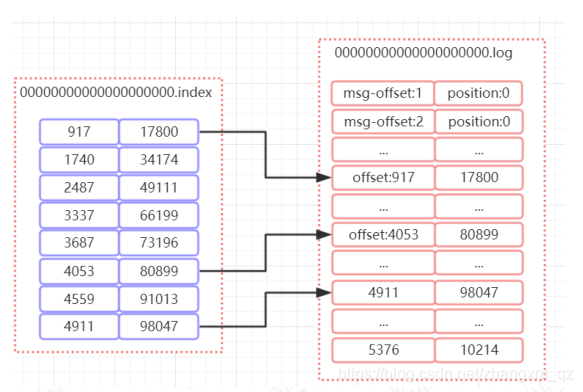
如上图所示,index 文件中存储了索引以及物理偏移量。
log 文件存储了消息的内容。
索引文件中保存了部分offset和偏移量position的对应关系。
比如 index文件中 [4053,80899],表示在 log 文件中,对应的是第 4053 条记录,物理偏移量(position)为 80899.
在 partition 中通过 offset 查找 message过程
- 根据 offset 的值,查找 segment 段中的 index 索引文件。由于索引文件命名是以上一个文件的最后一个offset 进行命名的,所以,使用二分查找算法能够根据offset 快速定位到指定的索引文件
- 找到索引文件后,根据 offset 进行定位,找到索引文件中的匹配范围的偏移量position。(kafka 采用稀疏索引的方式来提高查找性能)
- 得到 position 以后,再到对应的 log 文件中,从 position处开始查找 offset 对应的消息,将每条消息的 offset 与目标 offset 进行比较,直到找到消息
比如说,我们要查找 offset=2490 这条消息,那么先找到00000000000000000000.index, 然后找到[2487,49111]这个索引,再到 log 文件中,根据 49111 这个 position 开始查找,比较每条消息的 offset 是否大于等于 2490。最后查找到对应的消息以后返回
日志的清除策略以及压缩策略
日志的清理策略有两个
- 根据消息的保留时间,当消息在 kafka 中保存的时间超过了指定的时间,就会触发清理过程
- 根据 topic 存储的数据大小,当 topic 所占的日志文件大小大于一定的阀值,则可以开始删除最旧的消息。
通过 log.retention.bytes 和 log.retention.hours 这两个参数来设置,当其中任意一个达到要求,都会执行删除。默认的保留时间是:7 天
kafka会启动一个后台线程,定期检查是否存在可以删除的消息。
日志压缩策略
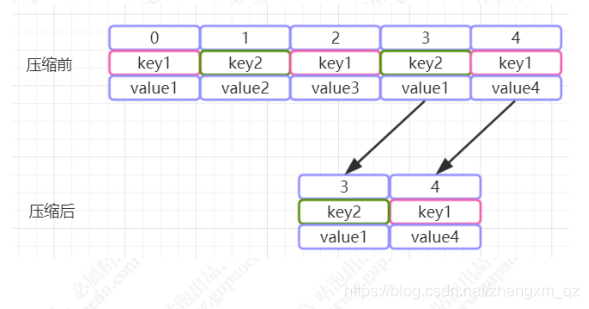
Kafka 还提供了“日志压缩(Log Compaction)”功能,通过这个功能可以有效的减少日志文件的大小,缓解磁盘紧张的情况,在很多实际场景中,消息的 key 和 value 的值之间的对应关系是不断变化的,就像数据库中的数据会不断被修改一样,消费者只关心 key 对应的最新的 value。
因此,我们可以开启 kafka 的日志压缩功能,服务端会在后台启动Cleaner线程池,定期将相同的key进行合并,只保留最新的 value 值。日志的压缩原理如下图:
消息写入的性能
顺序写
我们现在大部分企业仍然用的是机械结构的磁盘,如果把消息以随机的方式写入到磁盘,那么磁盘首先要做的就是寻址,也就是定位到数据所在的物理地址,在磁盘上就要找到对应的柱面、磁头以及对应的扇区;
这个过程相对内存来说会消耗大量时间,为了规避随机读写带来的时间消耗,kafka 采用顺序写的方式存储数据。
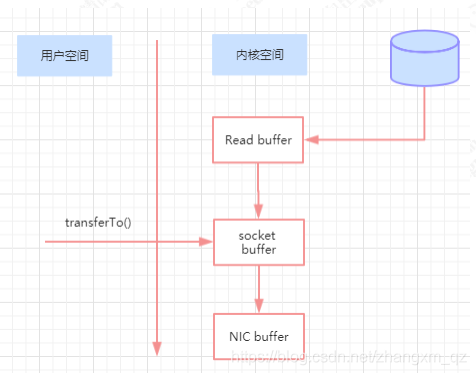
零拷贝
即使采用顺序写,但是频繁的 I/O 操作仍然会造成磁盘的性能瓶颈,所以 kafka还有一个性能策略:零拷贝
消息从发送到落地保存,broker 维护的消息日志本身就是文件目录,每个文件都是二进制保存,生产者和消费者使用相同的格式来处理。
在消费者获取消息时,服务器先从硬盘读取数据到内存,然后把内存中的数据原封不动的通过 socket 发送给消费者。
虽然这个操作描述起来很简单,但实际上经历了很多步骤。如下:
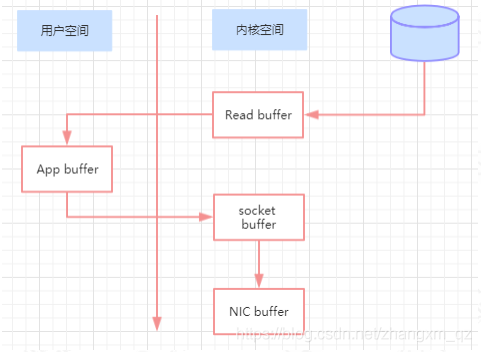
- 操作系统将数据从磁盘读入到内核空间的页缓存
- 应用程序将数据从内核空间读入到用户空间缓存中
- 应用程序将数据写回到内核空间到 socket 缓存中
- 操作系统将数据从 socket 缓冲区复制到网卡缓冲区,以便将数据经网络发出
这个过程涉及到 4 次上下文切换以及 4 次数据复制,并且有两次复制操作是由 CPU 完成。但是这个过程中,数据完全没有进行变化,仅仅是从磁盘复制到网卡缓冲区。通过“零拷贝”技术,可以去掉这些没必要的数据复制操作,同时也会减少上下文切换次数。
现代的 unix 操作系统提供一个优化的代码路径,用于将数据从页缓存传输到 socket;在 Linux 中,是通过 sendfile 系统调用来完成的。
Java 提供了访问这个系统调用的方法:FileChannel.transferTo API。
使用 sendfile,只需要一次拷贝就行,允许操作系统将数据直接从页缓存发送到网络上。
所以在这个优化的路径中,只有最后一步将数据拷贝到网卡缓存中是需要的
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Kafka Producer中的消息缓存模型图解详解
目录 前言 什么是消息累加器RecordAccumulator 消息缓存模型 ProducerBatch的内存大小 内存分配 Batch的创建和释放 问题和答案 总结 前言 在阅读本文之前, 希望你可以思考一下下面几个问题, 带着问题去阅读文章会获得更好的效果. 发送消息的时候, 当Broker挂掉了,消息体还能写入到消息缓存中吗? 当消息还存储在缓存中的时候, 假如Producer客户端挂掉了,消息是不是就丢失了? 当最新的ProducerBatch还有空余的内存,但是接下来的一条消息很大,不
-
分布式之全面了解Kafka的使用与特性
不啰嗦,我们直接开始! 引言 2020年,Kafka 依旧炙手可热,一线大公司即使不用Kafka,但是自研产品也都是基于Kafka,或者完全借鉴Kafka设计思想,理论上来说,如果你还没熟练掌握一个MQ框架,Kafka绝对是不错的选择. 关于历史,如果你感兴趣了解一下,至少知道是哪个公司开源的,Kafka最初于2011年在 LinkedIn 开发,自那时起经历了很多改进,后来捐献给Apache基金,如今发展成为一个完整的平台,采用Scala和Java开发的开源流处理软件. Kafka 是我工作多
-
大数据Kafka:消息队列和Kafka基本介绍
目录 一.什么是消息队列 二.消息队列的应用场景 异步处理 应用耦合 限流削峰 消息驱动系统 三.消息队列的两种方式 点对点模式 发布/订阅模式 四.常见的消息队列的产品 1) RabbitMQ 2) activeMQ: 3) RocketMQ 4) kafka 五.Kafka的基本介绍 一.什么是消息队列 消息队列,英文名:Message Queue,经常缩写为MQ.从字面上来理解,消息队列是一种用来存储消息的队列 .来看一下下面的代码 上述代码,创建了一个队列,先往队列中添加了一个消息,然后
-
深入解析kafka 架构原理
kafka 架构原理 大数据时代来临,如果你还不知道Kafka那就真的out了!据统计,有三分之一的世界财富500强企业正在使用Kafka,包括所有TOP10旅游公司,7家TOP10银行,8家TOP10保险公司,9家TOP10电信公司等等.LinkedIn.Microsoft和Netflix每天都用Kafka处理万亿级的信息.本文就让我们一起来大白话kafka的架构原理. kafka官网:http://kafka.apache.org/ 01 kafka简介 Kafka最初由Linkedin公
-
kafka的消息存储机制和原理分析
目录 消息的保存路径 数据分片 log分段 日志和索引文件内容分析 在 partition 中通过 offset 查找 message过程 日志的清除策略以及压缩策略 日志的清理策略有两个 日志压缩策略 消息写入的性能 顺序写 零拷贝 消息的保存路径 消息发送端发送消息到 broker 上以后,消息是如何持久化的? 数据分片 kafka 使用日志文件的方式来保存生产者和发送者的消息,每条消息都有一个 offset 值来表示它在分区中的偏移量. Kafka 中存储的一般都是海量的消息数据,为了避免
-
javascript垃圾收集机制的原理分析
前面的话 javascript具有自动垃圾收集机制,执行环境会负责管理代码执行过程中使用的内存.在编写javascript程序时,开发人员不用再关心内存使用问题,所需内存的分配以及无用内存的回收完全实现了自动管理.下面将详细介绍javascript的垃圾收集机制 原理 垃圾收集机制的原理很简单:找出那些不再继续使用的变量,然后释放其占用的内存,垃圾收集器会按照固定的时间间隔,或代码执行中预定的收集时间,周期性地执行这一操作 局部变量只在函数执行的过程中存在.而在这个过程中,会为局部变量在栈(或堆
-
javascript类继承机制的原理分析
目前 javascript的实现继承方式并不是通过"extend"关键字来实现的,而是通过 constructor function和prototype属性来实现继承.首先我们创建一个animal 类 js 代码 复制代码 代码如下: var animal = function (){ //这就是constructor function 了 this .name = 'pipi'; this .age = 10; this .height = 0; } //建立一个动物的实例 var
-
Android Handler 机制实现原理分析
handler在安卓开发中是必须掌握的技术,但是很多人都是停留在使用阶段.使用起来很简单,就两个步骤,在主线程重写handler的handleMessage( )方法,在工作线程发送消息.但是,有没有人想过这种技术是怎么实现的呢?下面我们一起探讨下. 先上图,让大家好理解下handler机制: handler机制示例图 上面一共出现了几种类,ActivityThread,Handler,MessageQueue,Looper,msg(Message),对这些类作简要介绍: ActivityThr
-
Android Handler 机制实现原理分析
handler在安卓开发中是必须掌握的技术,但是很多人都是停留在使用阶段.使用起来很简单,就两个步骤,在主线程重写handler的handleMessage( )方法,在工作线程发送消息.但是,有没有人想过这种技术是怎么实现的呢?下面我们一起探讨下. 先上图,让大家好理解下handler机制: handler机制示例图 上面一共出现了几种类,ActivityThread,Handler,MessageQueue,Looper,msg(Message),对这些类作简要介绍: ActivityThr
-
RAC cache fusion机制实现原理分析
在单实例中,进程要想修改数据块,必须在数据块的当前版本(Currentcopy)上进行修改RAC环境也一样 这便涉及到一系列问题: 如何获得数据块的版本在集群节点间的分布图? 如何知道哪个节点拥有的是当前版本? 如何完成传递过程? 这一系列问题的解决依靠内存融合技术(cachefusion) cachefusion通过高速的privateinterconnect,在实例间进行数据块传递 这是RAC最核心的工作机制,他把所有实例的SGA虚拟成一个大的SGA区 每当不同的实例请求相同的数据块,这个数
-
MyBatis Plus插件机制与执行流程原理分析详解
MyBatis Plus插件 MyBatis Plus提供了分页插件PaginationInterceptor.执行分析插件SqlExplainInterceptor.性能分析插件PerformanceInterceptor以及乐观锁插件OptimisticLockerInterceptor. Mybatis 通过插件 (Interceptor) 可以做到拦截四大对象相关方法的执行 ,根据需求完成相关数据的动态改变. 四大对象是: Executor StatementHandler Parame
-
elasticsearch的灵魂唯一master选举机制原理分析
master作为cluster的灵魂必须要有,还必须要唯一,否则集群就出大问题了.因此master选举在cluster分析中尤为重要.对于这个问题我将分两篇来分析.第一篇也就是本篇,首先会简单说一说mater选举的一些算法,及elasticsearch的选举原理.第二篇也就是下一篇,会结合zenDiscovery代码为仔细分析elasticsearch的master选举的实现. 简单来说master的作用跟单个jvm中的同步关键字synchronized相同,集群中多节点协调工作必须要保证数据的
-
elasticsearch的zenDiscovery和master选举机制原理分析
目录 前言 join的代码 findMaster方法 总结 前言 上一篇通过 ElectMasterService源码,分析了master选举的原理的大部分内容:master候选节点ID排序保证选举一致性及通过设置最小可见候选节点数目避免brain split.节点排序后选举只能保证局部一致性,如果发生节点接收到了错误的集群状态就会选举出错误的master,因此必须有其它措施来保证选举的一致性.这就是上一篇所提到的第二点:被选举的数量达到一定的数目同时自己也选举自己,这个节点才能成为master
-
Java 动态代理原理分析
Java 动态代理原理分析 概要 AOP的拦截功能是由java中的动态代理来实现的.说白了,就是在目标类的基础上增加切面逻辑,生成增强的目标类(该切面逻辑或者在目标类函数执行之前,或者目标类函数执行之后,或者在目标类函数抛出异常时候执行.Spring中的动态代理是使用Cglib进行实现的.我们这里分析的是JDK中的动态代理实现机制. 下面我们通过例子快速了解JDK中的动态代理实现方式. 示例 需要代理的接口 public interface IHello { public void sayHel