Python下载网易云歌单歌曲的示例代码
今天写了个下载脚本,记录一下
效果:
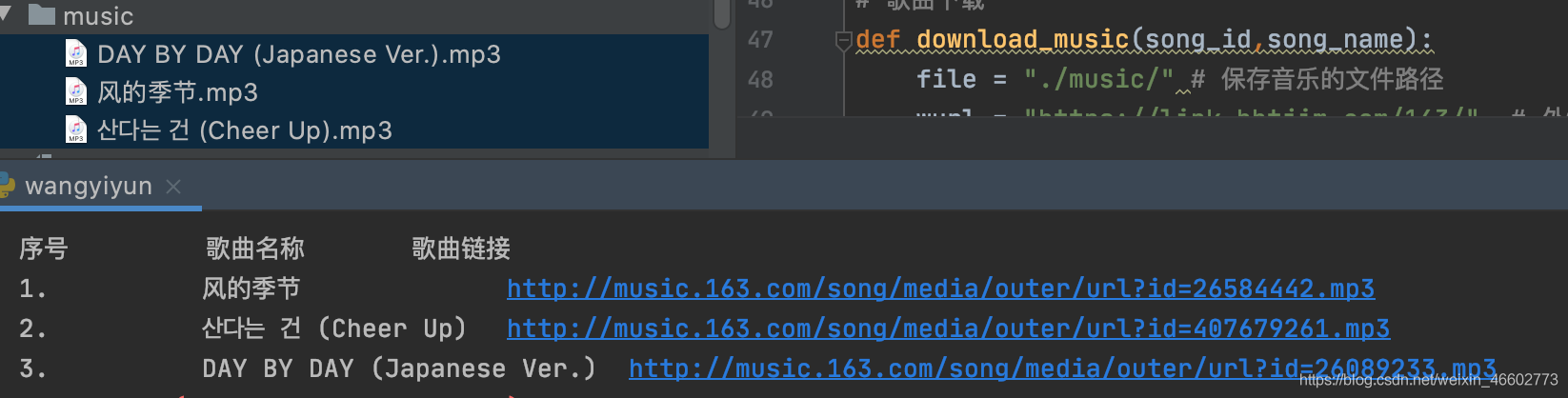
直接上代码:
# 网易云 根据歌单链接下载MP3歌曲
import requests
from bs4 import BeautifulSoup
def main():
url = "https://music.163.com/#/playlist?id=3136952023" # 歌单地址 请自行更换
if '/#/' in url:
url = url.replace('/#/', '/')
headers = {
'Referer': 'http://music.163.com/',
'Host': 'music.163.com',
'cookie': '自己去网站拿,获取方式在下边',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
}
s = requests.session()
try:
response = s.get(url, headers=headers).content
soup = BeautifulSoup(response, 'lxml')
lis = list(soup.find('ul'))
fatherlis = ['歌单名:' + str(soup.find('h2').string)]
for i in lis:
sonlis = []
sonlis.append(str(len(fatherlis)) + '.')
sonlis.append(i.a.string)
sonlis.append(str(i.a.get('href'))[str(i.a.get('href')).find('=') + 1:-1] + str(i.a.get('href'))[-1])
fatherlis.append(sonlis)
except:
print("\n\t歌曲链接输入错误")
exit('ERROR!')
format = '{0:<10}\t{1:{3}<10}\t{2:<10}'
print("从'{}'中找到了{}条歌曲".format(str(soup.find('h2').string), len(fatherlis) - 1))
print('-------------------------------------------------------------------------------------------------')
print('序号 歌曲名称 歌曲链接')
for i in fatherlis:
if fatherlis.index(i) == 0:
continue
else:
print(
format.format(i[0], i[1], 'http://music.163.com/song/media/outer/url?id=' + i[2] + '.mp3', chr(12288)))
download_music(i[2],i[1])
print('##########################下载完成##########################')
# 歌曲下载
def download_music(song_id,song_name):
file = "./music/" # 保存音乐的文件路径
wurl = "https://link.hhtjim.com/163/" # 外链地址
song_url = wurl + song_id + ".mp3"
# 获取歌曲16进制编码
song = requests.get(song_url).content
# 获取歌曲名称
# 保存文件
with open(file + song_name + '.mp3', 'wb') as f:
f.write(song)
if __name__ == '__main__':
main()
cookie获取方式
登录网易云web版 https://music.163.com/
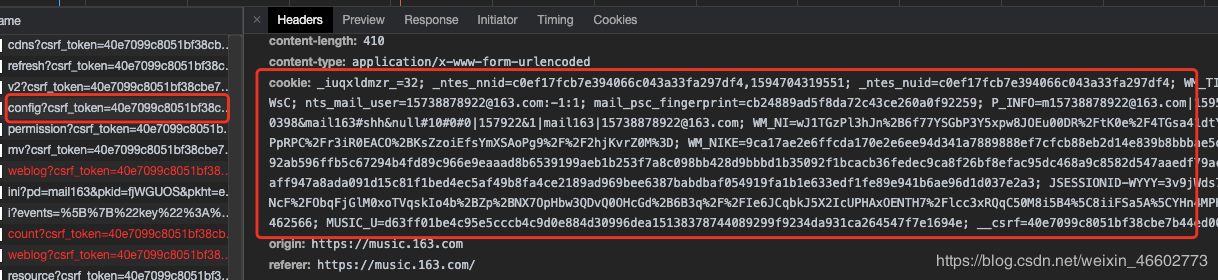
复制粘贴到上方代码中,开始下载就好了
到此这篇关于Python下载网易云歌单歌曲的示例代码的文章就介绍到这了,更多相关Python下载网易云歌单内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python 根据网易云歌曲的ID 直接下载歌曲的实例
特么的,上次写了一堆,发现,原来下载网易云的歌曲根本不用这么费劲,直接用! http://music.163.com/song/media/outer/url?id=这里填歌曲id.mp3 这个URL就可以下载了,真特么操蛋!! 现在再来做一次!根据歌单下载歌曲 import requests,os,time,sys,re from scrapy.selector import Selector class wangyiyun(): def __init__(self): self.header
-
使用Python实现下载网易云音乐的高清MV
Python下载网易云音乐的高清MV,没有从首页进去解析,直接循环了.... downPage1.py 复制代码 代码如下: #coding=utf-8 import urllib import re import os def getHtml(url): page = urllib.urlopen(url) html = page.read() return html def getVideo(html): reg = r'hurl=(.+?\.jpg)'
-
Python下载网易云歌单歌曲的示例代码
今天写了个下载脚本,记录一下 效果: 直接上代码: # 网易云 根据歌单链接下载MP3歌曲 import requests from bs4 import BeautifulSoup def main(): url = "https://music.163.com/#/playlist?id=3136952023" # 歌单地址 请自行更换 if '/#/' in url: url = url.replace('/#/', '/') headers = { 'Referer': 'ht
-
使用Python对网易云歌单数据分析及可视化
目录 项目概述 1.1项目来源 1.2需求描述 数据获取 2.1数据源的选取 2.2数据的获取 2.2.1 设计 2.2.2 实现 2.2.3 效果 数据预处理 3.1 设计 3.2 实现 3.3 效果 数据分析及可视化 4.1 歌单播放量Top10 4.1.1 实现 4.1.2 结果 4.1.3 可视化 4.2 歌单收藏量Top10 4.2.1 实现 4.2.2 结果 4.2.3 可视化 4.3 歌单评论数Top10 4.3.1 实现 4.3.2 结果 4.3.3 可视化 4.4 歌单歌曲收
-

python 根据列表批量下载网易云音乐的免费音乐
运行效果 代码 # -*- coding:utf-8 -*- import requests, hashlib, sys, click, re, base64, binascii, json, os from Crypto.Cipher import AES from http import cookiejar """ Website:http://cuijiahua.com Author:Jack Cui Refer:https://github.com/darknesso
-
python算法与数据结构之单链表的实现代码
=一.链表 链表是一种物理存储单元上非连续.非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的.链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成.每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域. 相比于线性表顺序结构,操作复杂.由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间,而线性表和顺序表相应的时间复杂度分别是
-
Python使用pickle模块存储数据报错解决示例代码
本文研究的主要是Python使用pickle模块存储数据报错解决方法,以代码的形式展示,具体如下. 首先来了解下pickle模块 pickle提供了一个简单的持久化功能.可以将对象以文件的形式存放在磁盘上. pickle模块只能在python中使用,python中几乎所有的数据类型(列表,字典,集合,类等)都可以用pickle来序列化, pickle序列化后的数据,可读性差,人一般无法识别. 接下来我们看下Python使用pickle模块存储数据报错解决方法. 代码: # 写入错误 TypeEr
-
Python 实现黑客帝国中的字符雨的示例代码
本教程很简单吧,除了复制代码之外,希望你也抽点时间去看下"注意",教程很简单,有问题请留言 废话不多数,先上图 注意 本项目中,需要用到文件库"pygame",不会的小伙伴,可以参考我的PyCharm教程里面有详细的讲解如何添加库:对于没有字体ttf的小伙伴,也不必担心,可以去这个链接下载,完全能够满足你的平日使用需求: # !/usr/bin/env python # -*- coding:utf-8 -*- # @Time : 2020.2 # @Author
-
python图片验证码识别最新模块muggle_ocr的示例代码
一.官方文档 https://pypi.org/project/muggle-ocr/ 二模块安装 pip install muggle-ocr # 因模块过新,阿里/清华等第三方源可能尚未更新镜像,因此手动指定使用境外源,为了提高依赖的安装速度,可预先自行安装依赖:tensorflow/numpy/opencv-python/pillow/pyyaml 三.使用代码 # 导入包 import muggle_ocr # 初始化:model_type 包含了 ModelType.OCR/Model
-
Python 保存加载mat格式文件的示例代码
mat为matlab常用存储数据的文件格式,python的scipy.io模块中包含保存和加载mat格式文件的API,使用极其简单,不再赘述:另附简易示例如下: # -*- coding: utf-8 -*- import numpy as np import scipy.io as scio # data data = np.array([1,2,3]) data2 = np.array([4,5,6]) # save mat (data format: dict) scio.savemat(
-
Python结合Window计划任务监测邮件的示例代码
说起自动化绝对算是茶余饭后最有显B格的谈资,毕竟解放双手是从老祖先那里就流传下来的基因,都2020了,你每天上班还要登录各个邮箱账号查收邮件?快来解锁本章内容 整体思路 通过Python zemail库实现邮件读取 将最新一封邮件ID进行保存,第二次执行时比对邮件ID,判断是否是新邮件 通过Python pymsgbox库实现window弹窗提示 配置Window计划任务,每1分钟执行一次 步骤一:邮件读取 读取邮件通过Python zemail库进行,使用前通过 pip install zem