Logback配置文件这么写(TPS提高10倍)
通过阅读本篇文章将了解到
1.日志输出到文件并根据LEVEL级别将日志分类保存到不同文件
2.通过异步输出日志减少磁盘IO提高性能
3.异步输出日志的原理
配置文件logback-spring.xml
SpringBoot工程自带logback和slf4j的依赖,所以重点放在编写配置文件上,需要引入什么依赖,日志依赖冲突统统都不需要我们管了。logback框架会默认加载classpath下命名为logback-spring或logback的配置文件。将所有日志都存储在一个文件中文件大小也随着应用的运行越来越大并且不好排查问题,正确的做法应该是将error日志和其他日志分开,并且不同级别的日志根据时间段进行记录存储。
<?xml version="1.0" encoding="utf-8"?>
<configuration>
<property resource="logback.properties"/>
<appender name="CONSOLE-LOG" class="ch.qos.logback.core.ConsoleAppender">
<layout class="ch.qos.logback.classic.PatternLayout">
<pattern>[%d{yyyy-MM-dd' 'HH:mm:ss.sss}] [%C] [%t] [%L] [%-5p] %m%n</pattern>
</layout>
</appender>
<!--获取比info级别高(包括info级别)但除error级别的日志-->
<appender name="INFO-LOG" class="ch.qos.logback.core.rolling.RollingFileAppender">
<filter class="ch.qos.logback.classic.filter.LevelFilter">
<level>ERROR</level>
<onMatch>DENY</onMatch>
<onMismatch>ACCEPT</onMismatch>
</filter>
<encoder>
<pattern>[%d{yyyy-MM-dd' 'HH:mm:ss.sss}] [%C] [%t] [%L] [%-5p] %m%n</pattern>
</encoder>
<!--滚动策略-->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!--路径-->
<fileNamePattern>${LOG_INFO_HOME}//%d.log</fileNamePattern>
<maxHistory>30</maxHistory>
</rollingPolicy>
</appender>
<appender name="ERROR-LOG" class="ch.qos.logback.core.rolling.RollingFileAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>ERROR</level>
</filter>
<encoder>
<pattern>[%d{yyyy-MM-dd' 'HH:mm:ss.sss}] [%C] [%t] [%L] [%-5p] %m%n</pattern>
</encoder>
<!--滚动策略-->
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!--路径-->
<fileNamePattern>${LOG_ERROR_HOME}//%d.log</fileNamePattern>
<maxHistory>30</maxHistory>
</rollingPolicy>
</appender>
<root level="info">
<appender-ref ref="CONSOLE-LOG" />
<appender-ref ref="INFO-LOG" />
<appender-ref ref="ERROR-LOG" />
</root>
</configuration>
部分标签说明
- <root>标签,必填标签,用来指定最基础的日志输出级别
- <appender-ref>标签,添加append
- <append>标签,通过使用该标签指定日志的收集策略
- name属性指定appender命名
- class属性指定输出策略,通常有两种,控制台输出和文件输出,文件输出就是将日志进行一个持久化。ConsoleAppender将日志输出到控制台
- <filter>标签,通过使用该标签指定过滤策略
- <level>标签指定过滤的类型
- <encoder>标签,使用该标签下的<pattern>标签指定日志输出格式
- <rollingPolicy>标签指定收集策略,比如基于时间进行收集
- <fileNamePattern>标签指定生成日志保存地址 通过这样配置已经实现了分类分天手机日志的目标了
logback 高级特性异步输出日志
之前的日志配置方式是基于同步的,每次日志输出到文件都会进行一次磁盘IO。采用异步写日志的方式而不让此次写日志发生磁盘IO,阻塞线程从而造成不必要的性能损耗。异步输出日志的方式很简单,添加一个基于异步写日志的appender,并指向原先配置的appender即可
<!-- 异步输出 -->
<appender name="ASYNC-INFO" class="ch.qos.logback.classic.AsyncAppender">
<!-- 不丢失日志.默认的,如果队列的80%已满,则会丢弃TRACT、DEBUG、INFO级别的日志 -->
<discardingThreshold>0</discardingThreshold>
<!-- 更改默认的队列的深度,该值会影响性能.默认值为256 -->
<queueSize>256</queueSize>
<!-- 添加附加的appender,最多只能添加一个 -->
<appender-ref ref="INFO-LOG"/>
</appender>
<appender name="ASYNC-ERROR" class="ch.qos.logback.classic.AsyncAppender">
<!-- 不丢失日志.默认的,如果队列的80%已满,则会丢弃TRACT、DEBUG、INFO级别的日志 -->
<discardingThreshold>0</discardingThreshold>
<!-- 更改默认的队列的深度,该值会影响性能.默认值为256 -->
<queueSize>256</queueSize>
<!-- 添加附加的appender,最多只能添加一个 -->
<appender-ref ref="ERROR-LOG"/>
</appender>
异步输出日志性能测试
既然能提高性能的话,必须进行一次测试比对,同步和异步输出日志性能到底能提升多少倍?
服务器硬件
CPU六核- 内存 8G
测试工具
Apache Jmeter
同步输出日志
线程数:100
Ramp-Up Loop(可以理解为启动线程所用时间) :0 可以理解为100个线程同时启用
测试结果
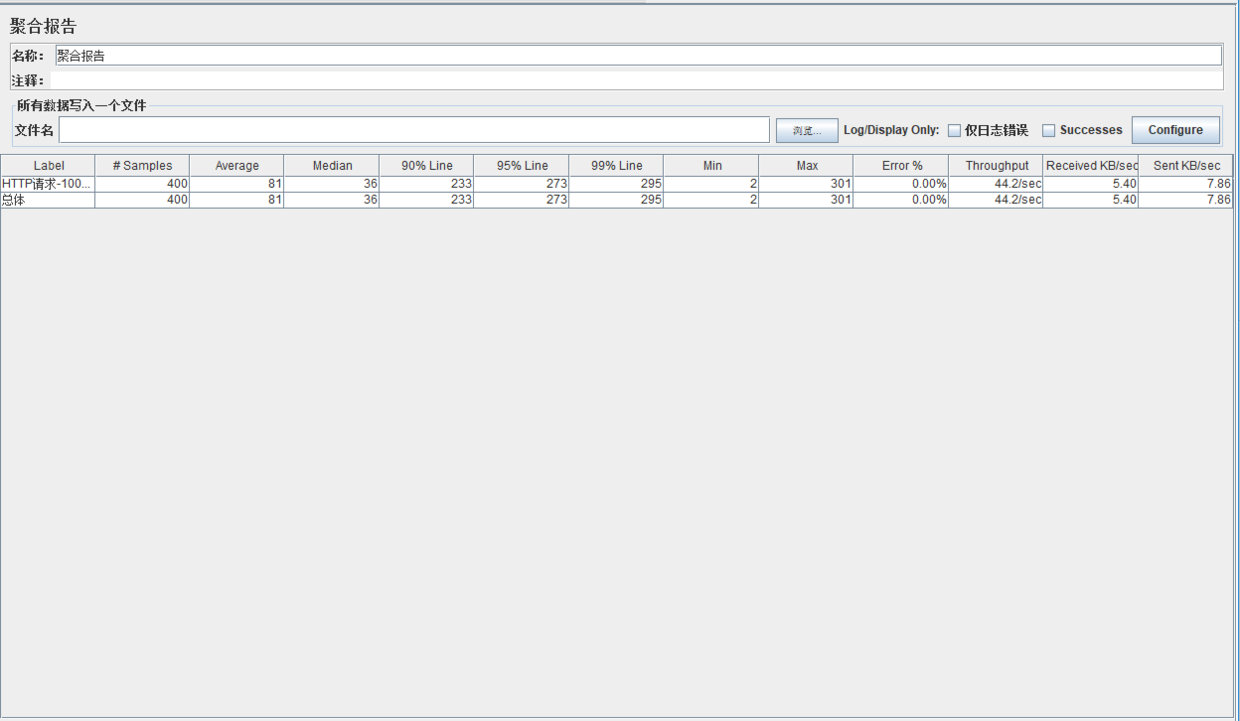
重点关注指标Throughput【TPS】吞吐量:系统在单位时间内处理请求的数量,在同步输出日志中TPS为44.2/sec
异步输出日志
- 线程数 100
Ramp-Up Loop:0- 测试结果
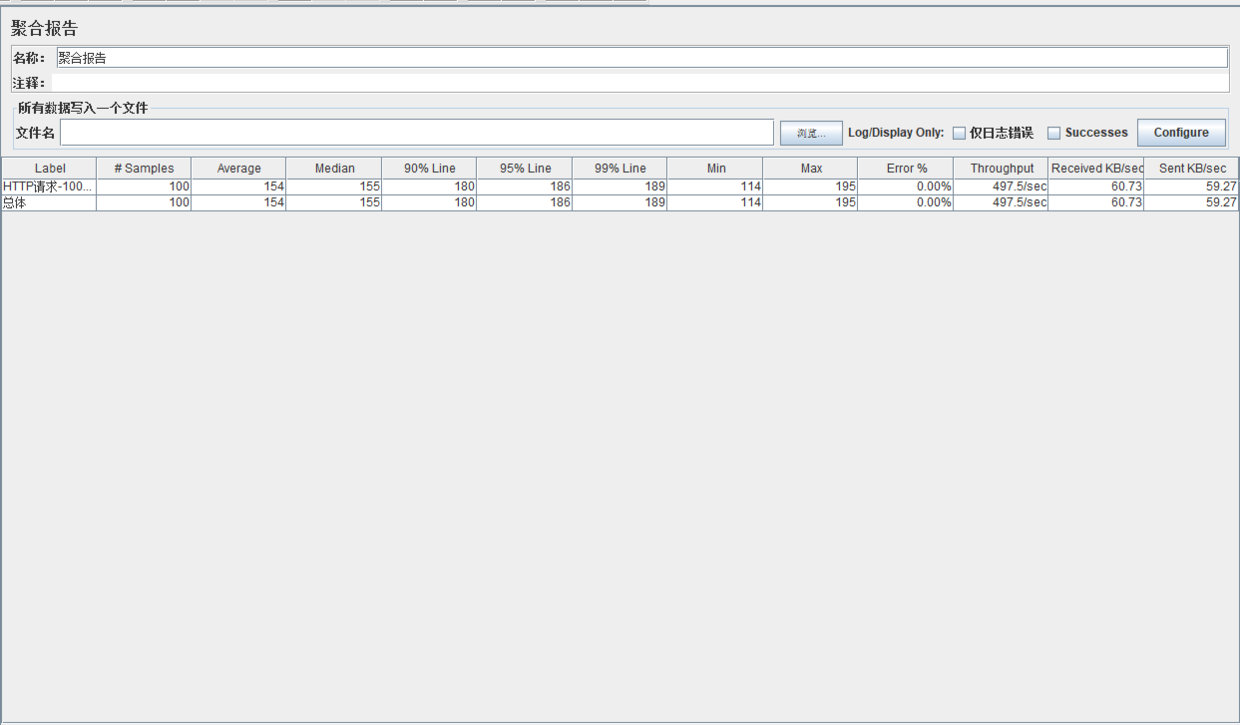
TPS为497.5/sec,性能提升了10多倍!!!
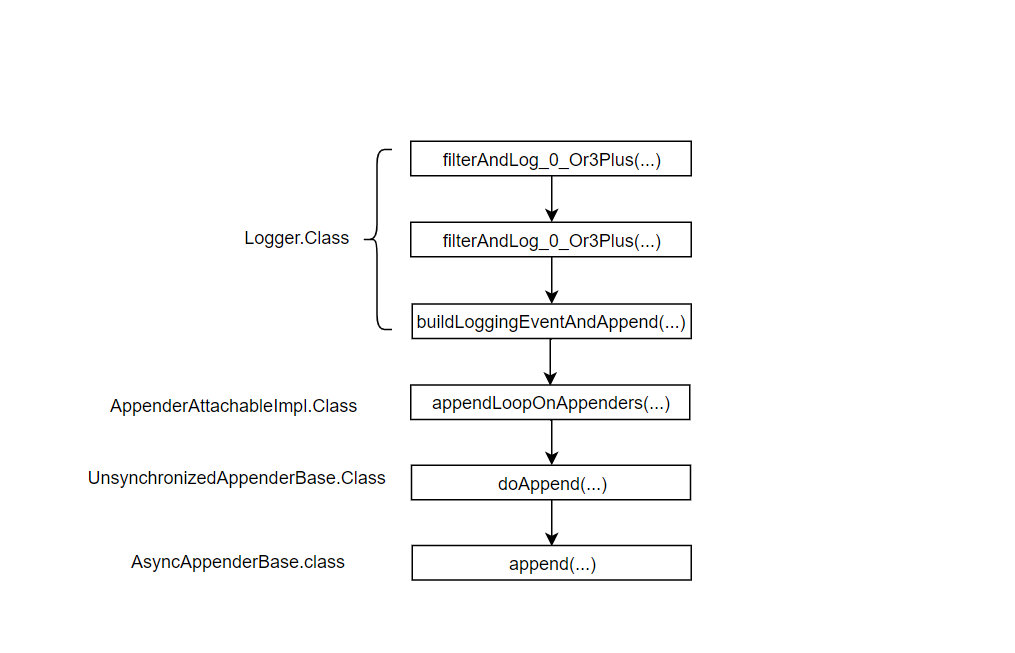
异步日志输出原理
从logback框架下的Logger.info方法开始追踪。一路的方法调用路径如下图所示:
异步输出日志中最关键的就是配置文件中ch.qos.logback.classic``AsyncAppenderBase``append
protected void append(E eventObject) {
if(!this.isQueueBelowDiscardingThreshold() || !this.isDiscardable(eventObject)) {
this.preprocess(eventObject);
this.put(eventObject);
}
}
通过队列情况判断是否需要丢弃日志,不丢弃的话将它放到阻塞队列中,通过查看代码,这个阻塞队列为ArrayBlockingQueueu,默认大小为256,可以通过配置文件进行修改。Logger.info(...)到append(...)就结束了,只做了将日志塞入到阻塞队列的事,然后继续执行Logger.info(...)下面的语句了。 在AsyncAppenderBase类中定义了一个Worker线程,run方法中的关键部分代码如下:
E e = parent.blockingQueue.take(); aai.appendLoopOnAppenders(e);
从阻塞队列中取出一个日志,并调用AppenderAttachableImpl类中的appendLoopOnAppenders方法维护一个Append列表。Worker线程中调用方法过程主要如下图:
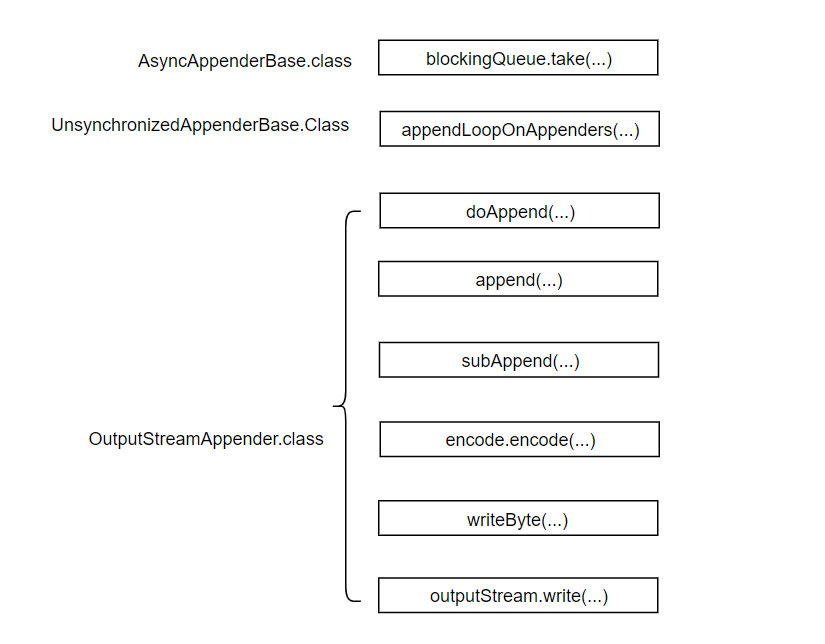
最主要的两个方法就是encode和write方法,前一个法方会根据配置文件中encode指定的方式转化为字节码,后一个方法将转化成的字节码写入到文件中去。所以写文件是通过新起一个线程去完成的,主线程将日志扔到阻塞队列中,然后又去做其他事情了。
最后附:项目完整代码
到此这篇关于Logback配置文件这么写(TPS提高10倍)的文章就介绍到这了,更多相关Logback配置文件内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Logback配置文件这么写,还说你不会整理日志?
摘要: 1.日志输出到文件并根据LEVEL级别将日志分类保存到不同文件 2.通过异步输出日志减少磁盘IO提高性能 3.异步输出日志的原理 1.配置文件logback-spring.xml SpringBoot工程自带logback和slf4j的依赖,所以重点放在编写配置文件上,需要引入什么依赖,日志依赖冲突统统都不需要我们管了. logback框架会默认加载classpath下命名为logback-spring.xml或logback.xml的配置文件. 如果将所有日志都存储在一个文件中,文件大
-
Logback配置文件这么写(TPS提高10倍)
通过阅读本篇文章将了解到 1.日志输出到文件并根据LEVEL级别将日志分类保存到不同文件 2.通过异步输出日志减少磁盘IO提高性能 3.异步输出日志的原理 配置文件logback-spring.xml SpringBoot工程自带logback和slf4j的依赖,所以重点放在编写配置文件上,需要引入什么依赖,日志依赖冲突统统都不需要我们管了.logback框架会默认加载classpath下命名为logback-spring或logback的配置文件.将所有日志都存储在一个文件中文件大小也随着应用
-

JAVA下单接口优化实战TPS性能提高10倍
概述 最近公司的下单接口有些慢,老板担心无法支撑双11,想让我优化一把,但是前提是不允许大改,因为下单接口太复杂了,如果改动太大,怕有风险.另外开发成本和测试成本也非常大.对于这种有挑战性的任务,我向来是非常喜欢的,因为在解决问题的过程中,可以学习到很多东西. 当时我只是知道下单接口慢,但是没人告诉我慢在哪里,也即是说,哪些瓶颈导致下单接口慢了.其实没人知道也没关系的,因为我们可以通过压测来找到具体的瓶颈. 下面会详细介绍一下,在本次压测中遇到的问题以及如何解决,期间用了什么工具. 用到的工具和
-
一行代码让 Python 的运行速度提高100倍
python一直被病垢运行速度太慢,但是实际上python的执行效率并不慢,慢的是python用的解释器Cpython运行效率太差. "一行代码让python的运行速度提高100倍"这绝不是哗众取宠的论调. 我们来看一下这个最简单的例子,从1一直累加到1亿. 最原始的代码: import time def foo(x,y): tt = time.time() s = 0 for i in range(x,y): s += i print('Time used: {} sec'.form
-
MongoDB数据库查询性能提高40倍的经历分享
前言 数据库性能对软件整体性能有着至关重要的影响,本文给大家分享了一次MongoDB数据库查询性能提高40倍的经历,感兴趣的朋友们可以参考学习. 背景说明 1.数据库:MongoDB 2.数据集: A:字段数不定,这里主要用到的两个UID和Date B:三个字段,UID.Date.Actions.其中Actions字段是包含260元素JSON数组,每个JSON对象有6个字段.共有数据800万条左右. 3.业务场景:求平均数 通过组合条件从A数据表查询出(UID,Date)列表,最多可能包含数万条
-
Python自动化之数据驱动让你的脚本简洁10倍【推荐】
前言 数据驱动是一种思想,让数据和代码进行分离,比如爬虫时,我们需要分页爬取数据时,我们往往把页数 page 参数化,放在 for 循环 range 中,假如没有 range 这个自带可以生产数字序列的方法可以用,我们是不是得手动逐个添加? 现实场景中就存在大量这样的例子,比如我之前写的爬取上海各地区房租情况的时候,对地区进行遍历的时候,为了偷懒,我直接把这些地区的拼音全称放在了列表里,组合成各地区房源的链接.最后文章写完了,有读者反馈,少了徐汇区的统计数据.这种小数量的数据都出现了纰漏,可想而
-
只需要这一行代码就能让python计算速度提高十倍
一.前言 Python语言近年来人气爆棚.它广泛应用于数据科学,人工智能,以及网络安全问题中,由于代码可读性较强,学习效率较高,吸引了许多非科班的同学进行学习.然而,使用Python一段时间以后,发现它在速度上完全没有优势可言,特别是计算密集型任务里,性能问题一直是Python的软肋.本文主要介绍了Python的JIT编译器Numba,能够在对代码侵入最少的情况下,极大加速计算核心函数的运行速度,适合数据分析业务相关的同学使用. 首先要回答这样一个问题:当运行同一个程序时,为什么Python会
-
利用JuiceFS使MySQL 备份验证性能提升 10 倍
目录 数据准备 使用默认参数 增大XtraBackup的内存缓冲区 增大XtraBackup读线程数 JuiceFS启用异步写 增大JuiceFS的磁盘缓存 增大数据库数据量 总结 前言: JuiceFS 非常适合用来做 MySQL 物理备份,具体使用参考官方文档.在测试时,备份验证的数据准备(xtrabackup --prepare)过程非常慢.我们借助 JuiceFS 提供的性能分析工具做了分析,快速发现性能瓶颈,通过不断调整 XtraBackup 的参数和 JuiceFS 的挂载参数,在一
-
将你的Apache速度提高十倍的经验分享
这个神通广大的模块就是mod_gzip. 它通过用和gzip一样的压缩算法对apache发出的页面进行压缩,可能的话可以把页面压缩成为原来大小的十份之一.哪,如果10K的页面只要传1K这不就是提速10倍嘛.当然一般网页只可以达到3-6倍.那也很不错.对吧.连google这样一个大的网站都采用这个技术.你还不快跟上? 这样一个好东东,来来来,我告诉你如何安装:分3步,1.下载,2.修改配置,3.测试. 1.下载 到http://www.remotecommunications.com/apache
-
15张Vim速查表-帮你提高N倍效率
去年上半年开始全面使用linux进行开发和娱乐了,现在已经回不去windows了. 话归正传,在Linux上一直使用vim,慢慢熟悉了它的命令,才终于领悟了什么是编辑器之神. 最近抽空整理了这份速查表,收获颇丰,并分享给大家. 进入vim vim配置 移动光标 屏幕滚动 插入文本类 删除命令 复制粘贴 撤销 搜索及替换 书签 visual模式 行方式命令 若不指定n1,n2,则表示将整个文件内容作为command的输入 | 宏 窗口操作 文件及其他 推荐: 感兴趣的朋友可以关注小编的微信公众号[