基于pytorch的lstm参数使用详解
lstm(*input, **kwargs)
将多层长短时记忆(LSTM)神经网络应用于输入序列。
参数:
input_size:输入'x'中预期特性的数量
hidden_size:隐藏状态'h'中的特性数量
num_layers:循环层的数量。例如,设置' ' num_layers=2 ' '意味着将两个LSTM堆叠在一起,形成一个'堆叠的LSTM ',第二个LSTM接收第一个LSTM的输出并计算最终结果。默认值:1
bias:如果' False',则该层不使用偏置权重' b_ih '和' b_hh '。默认值:'True'
batch_first:如果' 'True ' ',则输入和输出张量作为(batch, seq, feature)提供。默认值: 'False'
dropout:如果非零,则在除最后一层外的每个LSTM层的输出上引入一个“dropout”层,相当于:attr:'dropout'。默认值:0
bidirectional:如果‘True',则成为双向LSTM。默认值:'False'
输入:input,(h_0, c_0)
**input**of shape (seq_len, batch, input_size):包含输入序列特征的张量。输入也可以是一个压缩的可变长度序列。
see:func:'torch.nn.utils.rnn.pack_padded_sequence' 或:func:'torch.nn.utils.rnn.pack_sequence' 的细节。
**h_0** of shape (num_layers * num_directions, batch, hidden_size):张量包含批处理中每个元素的初始隐藏状态。
如果RNN是双向的,num_directions应该是2,否则应该是1。
**c_0** of shape (num_layers * num_directions, batch, hidden_size):张量包含批处理中每个元素的初始单元格状态。
如果没有提供' (h_0, c_0) ',则**h_0**和**c_0**都默认为零。
输出:output,(h_n, c_n)
**output**of shape (seq_len, batch, num_directions * hidden_size) :包含LSTM最后一层输出特征' (h_t) '张量,
对于每个t. If a:class: 'torch.nn.utils.rnn.PackedSequence' 已经给出,输出也将是一个打包序列。
对于未打包的情况,可以使用'output.view(seq_len, batch, num_directions, hidden_size)',正向和反向分别为方向' 0 '和' 1 '。
同样,在包装的情况下,方向可以分开。
**h_n** of shape (num_layers * num_directions, batch, hidden_size):包含' t = seq_len '隐藏状态的张量。
与*output*类似, the layers可以使用以下命令分隔
h_n.view(num_layers, num_directions, batch, hidden_size) 对于'c_n'相似
**c_n** (num_layers * num_directions, batch, hidden_size):张量包含' t = seq_len '的单元状态
所有的权重和偏差都初始化自: 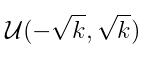 where:
where: 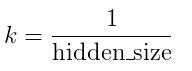
include:: cudnn_persistent_rnn.rst
import torch import torch.nn as nn # 双向rnn例子 # rnn = nn.RNN(10, 20, 2) # input = torch.randn(5, 3, 10) # h0 = torch.randn(2, 3, 20) # output, hn = rnn(input, h0) # print(output.shape,hn.shape) # torch.Size([5, 3, 20]) torch.Size([2, 3, 20]) # 双向lstm例子 rnn = nn.LSTM(10, 20, 2) #(input_size,hidden_size,num_layers) input = torch.randn(5, 3, 10) #(seq_len, batch, input_size) h0 = torch.randn(2, 3, 20) #(num_layers * num_directions, batch, hidden_size) c0 = torch.randn(2, 3, 20) #(num_layers * num_directions, batch, hidden_size) # output:(seq_len, batch, num_directions * hidden_size) # hn,cn(num_layers * num_directions, batch, hidden_size) output, (hn, cn) = rnn(input, (h0, c0)) print(output.shape,hn.shape,cn.shape) >>>torch.Size([5, 3, 20]) torch.Size([2, 3, 20]) torch.Size([2, 3, 20])
以上这篇基于pytorch的lstm参数使用详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
pytorch获取模型某一层参数名及参数值方式
1.Motivation: I wanna modify the value of some param; I wanna check the value of some param. The needed function: 2.state_dict() #generator type model.modules()#generator type named_parameters()#OrderDict type from torch import nn import torch #creat
-
pytorch实现用CNN和LSTM对文本进行分类方式
model.py: #!/usr/bin/python # -*- coding: utf-8 -*- import torch from torch import nn import numpy as np from torch.autograd import Variable import torch.nn.functional as F class TextRNN(nn.Module): """文本分类,RNN模型""" def __ini
-
pytorch 利用lstm做mnist手写数字识别分类的实例
代码如下,U我认为对于新手来说最重要的是学会rnn读取数据的格式. # -*- coding: utf-8 -*- """ Created on Tue Oct 9 08:53:25 2018 @author: www """ import sys sys.path.append('..') import torch import datetime from torch.autograd import Variable from torch im
-
pytorch下使用LSTM神经网络写诗实例
在pytorch下,以数万首唐诗为素材,训练双层LSTM神经网络,使其能够以唐诗的方式写诗. 代码结构分为四部分,分别为 1.model.py,定义了双层LSTM模型 2.data.py,定义了从网上得到的唐诗数据的处理方法 3.utlis.py 定义了损失可视化的函数 4.main.py定义了模型参数,以及训练.唐诗生成函数. 参考:电子工业出版社的<深度学习框架PyTorch:入门与实践>第九章 main代码及注释如下 import sys, os import torch as t fr
-
pytorch 求网络模型参数实例
用pytorch训练一个神经网络时,我们通常会很关心模型的参数总量.下面分别介绍来两种方法求模型参数 一 .求得每一层的模型参数,然后自然的可以计算出总的参数. 1.先初始化一个网络模型model 比如我这里是 model=cliqueNet(里面是些初始化的参数) 2.调用model的Parameters类获取参数列表 一个典型的操作就是将参数列表传入优化器里.如下 optimizer = optim.Adam(model.parameters(), lr=opt.lr) 言归正传,继续回到参
-
基于pytorch的lstm参数使用详解
lstm(*input, **kwargs) 将多层长短时记忆(LSTM)神经网络应用于输入序列. 参数: input_size:输入'x'中预期特性的数量 hidden_size:隐藏状态'h'中的特性数量 num_layers:循环层的数量.例如,设置' ' num_layers=2 ' '意味着将两个LSTM堆叠在一起,形成一个'堆叠的LSTM ',第二个LSTM接收第一个LSTM的输出并计算最终结果.默认值:1 bias:如果' False',则该层不使用偏置权重' b_ih '和' b
-
基于Pytorch实现分类器的示例详解
目录 Softmax分类器 定义 训练 测试 感知机分类器 定义 训练 测试 本文实现两个分类器: softmax分类器和感知机分类器 Softmax分类器 Softmax分类是一种常用的多类别分类算法,它可以将输入数据映射到一个概率分布上.Softmax分类首先将输入数据通过线性变换得到一个向量,然后将向量中的每个元素进行指数函数运算,最后将指数运算结果归一化得到一个概率分布.这个概率分布可以被解释为每个类别的概率估计. 定义 定义一个softmax分类器类: class SoftmaxCla
-
基于python及pytorch中乘法的使用详解
numpy中的乘法 A = np.array([[1, 2, 3], [2, 3, 4]]) B = np.array([[1, 0, 1], [2, 1, -1]]) C = np.array([[1, 0], [0, 1], [-1, 0]]) A * B : # 对应位置相乘 np.array([[ 1, 0, 3], [ 4, 3, -4]]) A.dot(B) : # 矩阵乘法 ValueError: shapes (2,3) and (2,3) not aligned: 3 (dim
-
Pytorch技巧:DataLoader的collate_fn参数使用详解
DataLoader完整的参数表如下: class torch.utils.data.DataLoader( dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=<function default_collate>, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None) D
-

python神经网络Keras实现LSTM及其参数量详解
目录 什么是LSTM 1.LSTM的结构 2.LSTM独特的门结构 3.LSTM参数量计算 在Keras中实现LSTM 实现代码 什么是LSTM 1.LSTM的结构 我们可以看出,在n时刻,LSTM的输入有三个: 当前时刻网络的输入值Xt: 上一时刻LSTM的输出值ht-1: 上一时刻的单元状态Ct-1. LSTM的输出有两个: 当前时刻LSTM输出值ht: 当前时刻的单元状态Ct. 2.LSTM独特的门结构 LSTM用两个门来控制单元状态cn的内容: 遗忘门(forget gate),它决定了
-
Python深度学习pytorch神经网络图像卷积运算详解
目录 互相关运算 卷积层 特征映射 由于卷积神经网络的设计是用于探索图像数据,本节我们将以图像为例. 互相关运算 严格来说,卷积层是个错误的叫法,因为它所表达的运算其实是互相关运算(cross-correlation),而不是卷积运算.在卷积层中,输入张量和核张量通过互相关运算产生输出张量. 首先,我们暂时忽略通道(第三维)这一情况,看看如何处理二维图像数据和隐藏表示.下图中,输入是高度为3.宽度为3的二维张量(即形状为 3 × 3 3\times3 3×3).卷积核的高度和宽度都是2. 注意,
-
基于angular中的重要指令详解($eval,$parse和$compile)
在angular的服务中,有一些服务你不得不去了解,因为他可以说是ng的核心,而今天,我要介绍的就是ng的两个核心服务,$parse和$compile.其实这两个服务讲的人已经很多了,但是100个读者就有100个哈姆雷特,我在这里讲讲自己对于他们两个服务的理解. 大家可能会疑问,$eval呢,其实他并不是一个服务,他是scope里面的一个方法,并不能算服务,而且它也基于parse的,所以只能算是$parse的另一种写法而已,我们看一下ng源码中$eval的定义是怎样的就知道了 $eval: fu
-
基于java servlet过滤器和监听器(详解)
1 过滤器 1.过滤器是什么? servlet规范当中定义的一种特殊的组件,用于拦截容器的调用. 注:容器收到请求之后,如果有过滤器,会先调用过滤器,然后在调用servlet. 2.如何写一个过滤器? 1.写一个java类,实现Filter接口; 2.在接口方法中实现拦截方法; 3.配置过滤器(web.xml); 3.配置初始化参数 1.配置初始化参数.(init-param) 2.通过filterconfig提供的getinitparamenter方法读取初始化的值. 4.优先级: 当有多个过
-
基于C++中setiosflags()的用法详解
cout<<setiosflags(ios::fixed)<<setiosflags(ios::right)<<setprecision(2); setiosflags 是包含在命名空间iomanip 中的C++ 操作符,该操作符的作用是执行由有参数指定区域内的动作: iso::fixed 是操作符setiosflags 的参数之一,该参数指定的动作是以带小数点的形式表示浮点数,并且在允许的精度范围内尽可能的把数字移向小数点右侧: iso::right 也是se
-
基于Java中的StringTokenizer类详解(推荐)
StringTokenizer是字符串分隔解析类型,属于:Java.util包. 1.StringTokenizer的构造函数 StringTokenizer(String str):构造一个用来解析str的StringTokenizer对象.java默认的分隔符是"空格"."制表符('\t')"."换行符('\n')"."回车符('\r')". StringTokenizer(String str,String delim)