在pytorch中对非叶节点的变量计算梯度实例
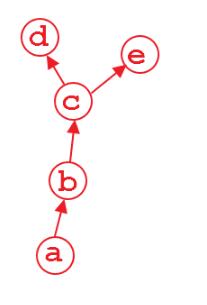
在pytorch中一般只对叶节点进行梯度计算,也就是下图中的d,e节点,而对非叶节点,也即是c,b节点则没有显式地去保留其中间计算过程中的梯度(因为一般来说只有叶节点才需要去更新),这样可以节省很大部分的显存,但是在调试过程中,有时候我们需要对中间变量梯度进行监控,以确保网络的有效性,这个时候我们需要打印出非叶节点的梯度,为了实现这个目的,我们可以通过两种手段进行。
注册hook函数
Tensor.register_hook[2] 可以注册一个反向梯度传导时的hook函数,这个hook函数将会在每次计算 关于该张量  的时候 被调用,经常用于调试的时候打印出非叶节点梯度。当然,通过这个手段,你也可以自定义某一层的梯度更新方法。[3] 具体到这里的打印非叶节点的梯度,代码如:
的时候 被调用,经常用于调试的时候打印出非叶节点梯度。当然,通过这个手段,你也可以自定义某一层的梯度更新方法。[3] 具体到这里的打印非叶节点的梯度,代码如:
def hook_y(grad): print(grad) x = Variable(torch.ones(2, 2), requires_grad=True) y = x + 2 z = y * y * 3 y.register_hook(hook_y) out = z.mean() out.backward()
输出如:
tensor([[4.5000, 4.5000], [4.5000, 4.5000]])
retain_grad()
Tensor.retain_grad()显式地保存非叶节点的梯度,当然代价就是会增加显存的消耗,而用hook函数的方法则是在反向计算时直接打印,因此不会增加显存消耗,但是使用起来retain_grad()要比hook函数方便一些。代码如:
x = Variable(torch.ones(2, 2), requires_grad=True) y = x + 2 y.retain_grad() z = y * y * 3 out = z.mean() out.backward() print(y.grad)
输出如:
tensor([[4.5000, 4.5000], [4.5000, 4.5000]])
以上这篇在pytorch中对非叶节点的变量计算梯度实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
PyTorch中的Variable变量详解
一.了解Variable 顾名思义,Variable就是 变量 的意思.实质上也就是可以变化的量,区别于int变量,它是一种可以变化的变量,这正好就符合了反向传播,参数更新的属性. 具体来说,在pytorch中的Variable就是一个存放会变化值的地理位置,里面的值会不停发生片花,就像一个装鸡蛋的篮子,鸡蛋数会不断发生变化.那谁是里面的鸡蛋呢,自然就是pytorch中的tensor了.(也就是说,pytorch都是有tensor计算的,而tensor里面的参数都是Variable的形式).如果
-
pytorch的梯度计算以及backward方法详解
基础知识 tensors: tensor在pytorch里面是一个n维数组.我们可以通过指定参数reuqires_grad=True来建立一个反向传播图,从而能够计算梯度.在pytorch中一般叫做dynamic computation graph(DCG)--即动态计算图. import torch import numpy as np # 方式一 x = torch.randn(2,2, requires_grad=True) # 方式二 x = torch.autograd.Variabl
-
在pytorch中对非叶节点的变量计算梯度实例
在pytorch中一般只对叶节点进行梯度计算,也就是下图中的d,e节点,而对非叶节点,也即是c,b节点则没有显式地去保留其中间计算过程中的梯度(因为一般来说只有叶节点才需要去更新),这样可以节省很大部分的显存,但是在调试过程中,有时候我们需要对中间变量梯度进行监控,以确保网络的有效性,这个时候我们需要打印出非叶节点的梯度,为了实现这个目的,我们可以通过两种手段进行. 注册hook函数 Tensor.register_hook[2] 可以注册一个反向梯度传导时的hook函数,这个hook函数将会在
-
pytorch中交叉熵损失(nn.CrossEntropyLoss())的计算过程详解
公式 首先需要了解CrossEntropyLoss的计算过程,交叉熵的函数是这样的: 其中,其中yi表示真实的分类结果.这里只给出公式,关于CrossEntropyLoss的其他详细细节请参照其他博文. 测试代码(一维) import torch import torch.nn as nn import math criterion = nn.CrossEntropyLoss() output = torch.randn(1, 5, requires_grad=True) label = tor
-

浅谈Pytorch中autograd的若干(踩坑)总结
关于Variable和Tensor 旧版本的Pytorch中,Variable是对Tensor的一个封装:在Pytorch大于v0.4的版本后,Varible和Tensor合并了,意味着Tensor可以像旧版本的Variable那样运行,当然新版本中Variable封装仍旧可以用,但是对Varieble操作返回的将是一个Tensor. import torch as t from torch.autograd import Variable a = t.ones(3,requires_grad=
-
在pytorch中查看可训练参数的例子
pytorch中我们有时候可能需要设定某些变量是参与训练的,这时候就需要查看哪些是可训练参数,以确定这些设置是成功的. pytorch中model.parameters()函数定义如下: def parameters(self): r"""Returns an iterator over module parameters. This is typically passed to an optimizer. Yields: Parameter: module paramete
-
Pytorch 中retain_graph的用法详解
用法分析 在查看SRGAN源码时有如下损失函数,其中设置了retain_graph=True,其作用是什么? ############################ # (1) Update D network: maximize D(x)-1-D(G(z)) ########################### real_img = Variable(target) if torch.cuda.is_available(): real_img = real_img.cuda() z = V
-
pytorch中的自定义反向传播,求导实例
pytorch中自定义backward()函数.在图像处理过程中,我们有时候会使用自己定义的算法处理图像,这些算法多是基于numpy或者scipy等包. 那么如何将自定义算法的梯度加入到pytorch的计算图中,能使用Loss.backward()操作自动求导并优化呢.下面的代码展示了这个功能` import torch import numpy as np from PIL import Image from torch.autograd import gradcheck class Bicu
-
PyTorch中model.zero_grad()和optimizer.zero_grad()用法
废话不多说,直接上代码吧~ model.zero_grad() optimizer.zero_grad() 首先,这两种方式都是把模型中参数的梯度设为0 当optimizer = optim.Optimizer(net.parameters())时,二者等效,其中Optimizer可以是Adam.SGD等优化器 def zero_grad(self): """Sets gradients of all model parameters to zero.""
-
pytorch 中autograd.grad()函数的用法说明
我们在用神经网络求解PDE时, 经常要用到输出值对输入变量(不是Weights和Biases)求导: 在训练WGAN-GP 时, 也会用到网络对输入变量的求导. 以上两种需求, 均可以用pytorch 中的autograd.grad() 函数实现. autograd.grad(outputs, inputs, grad_outputs=None, retain_graph=None, create_graph=False, only_inputs=True, allow_unused=False
-
Pytorch中的backward()多个loss函数用法
Pytorch的backward()函数 假若有多个loss函数,如何进行反向传播和更新呢? x = torch.tensor(2.0, requires_grad=True) y = x**2 z = x # 反向传播 y.backward() x.grad tensor(4.) z.backward() x.grad tensor(5.) ## 累加 补充:Pytorch中torch.autograd ---backward函数的使用方法详细解析,具体例子分析 backward函数 官方定义