Python Pytorch gpu 分析环境配置
目录
- Apple silicon
- Windows NVIDIA
- 手写数据性能测试
Pytorch是目前最火的深度学习框架之一,另一个是TensorFlow。不过我之前一直用到是CPU版本,几个月前买了一台3070Ti的笔记本(是的,我在40系显卡出来的时候,买了30系,这确实一言难尽),同时我也有一台M1芯片Macbook Pro,目前也支持了pytorch的GPU加速,所以我就想着,在这两个电脑上装个Pytorch,浅度学习深度学习。
Apple silicon
首先是M1芯片,这个就特别简单了。先装一个conda,只不过是内置mamba包管理器,添加conda-forge频道,arm64版本。
# 下载 wget https://github.com/conda-forge/miniforge/releases/latest/download/Mambaforge-MacOSX-arm64.sh # 安装 bash Mambaforge-MacOSX-arm64.sh
然后我们用mamba创建一个环境,用的是开发版的pytorch,所以频道指定pytorch-nightly
mamba create -n pytorch \ jupyterlab jupyterhub pytorch torchvision torchaudio -c pytorch-nightly
最后,用conda activate pytorch,然后测试是否正确识别到GPU
import torch
torch.has_mps
# True
# 配置device
device = torch.device("mps")
参考资料: https://developer.apple.com/metal/pytorch/
Windows NVIDIA
首先,需要确保你的电脑安装的是NVIDIA的显卡,以及有了相应的CUDA驱动。
CUDA的显卡架构要求: https://docs.nvidia.com/deeplearning/cudnn/support-matrix/index.html
新一代的电脑上基本都自带CUDA驱动。可以通过打开NVIDIA控制面板的系统信息
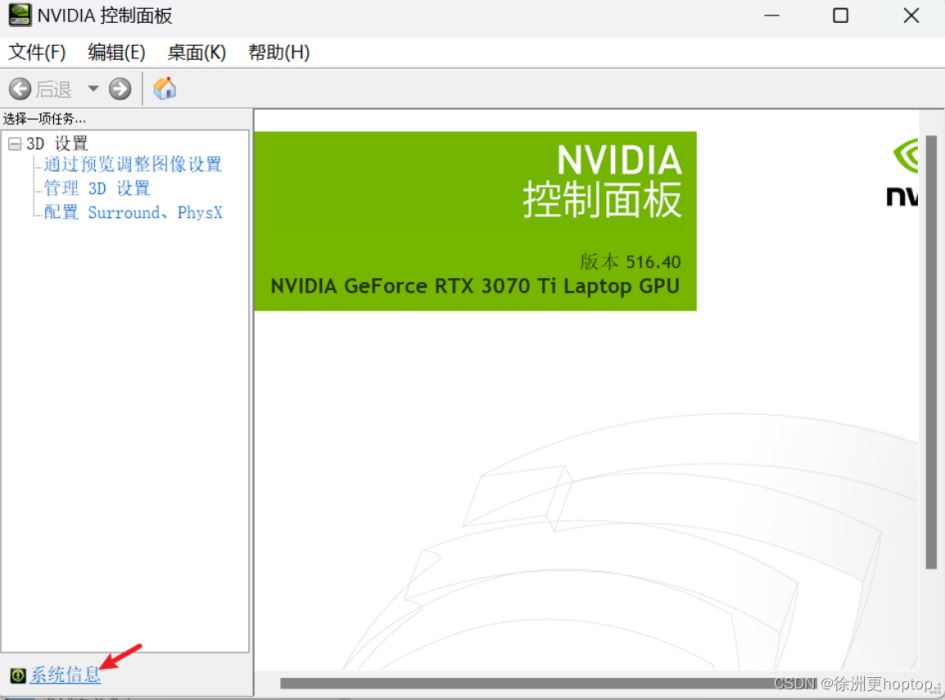
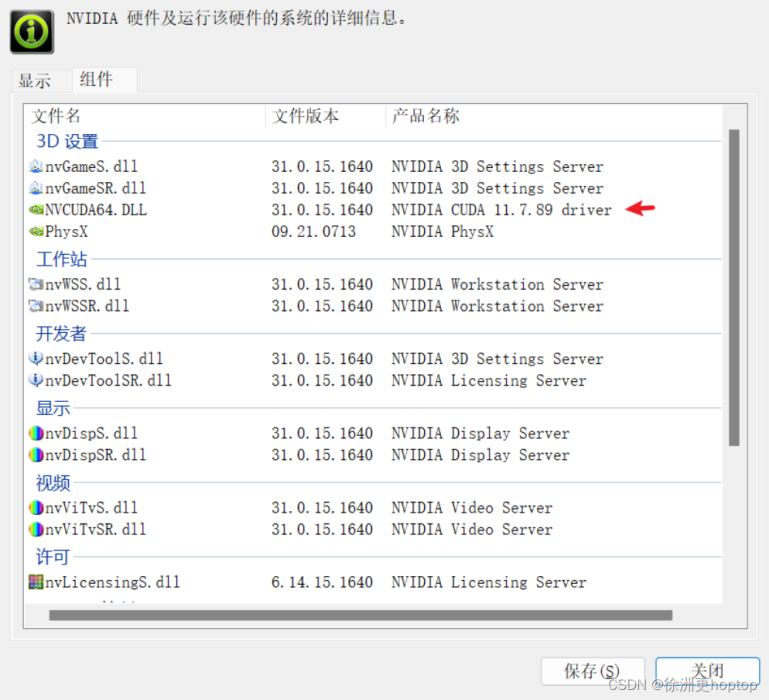
在组件中查看你已经安装的CUDA驱动,例如我的是11.7.89 。
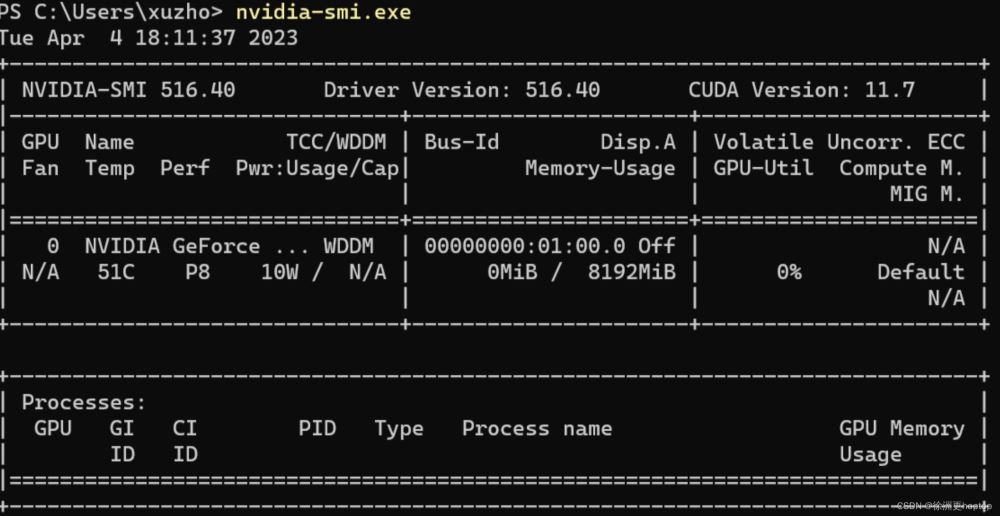
也可以通过命令行的方式查看,
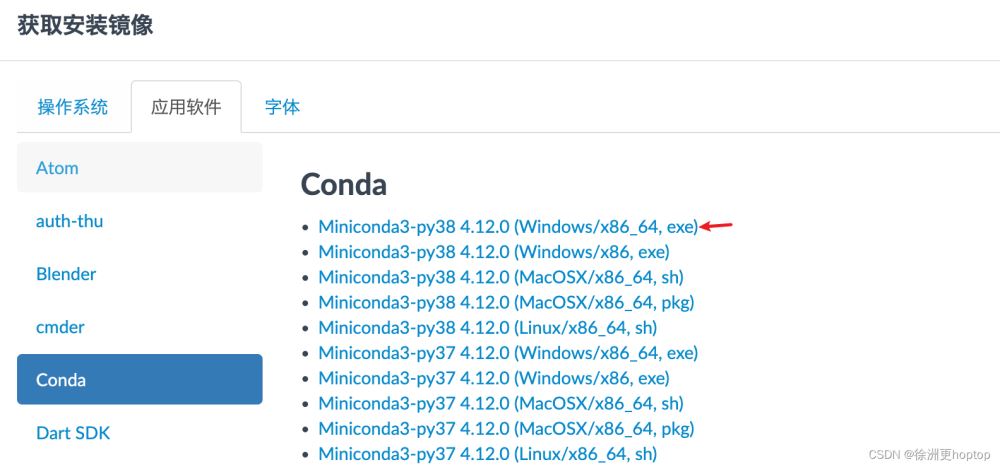
接下来,我们来安装pytorch。同样也是推荐conda的方法,我们先从清华镜像源中下载Miniconda。

选择Windows的安装包
安装完之后,我们就可以通过Anaconda Prompt进入命令行,根据pytorch网站上的推荐进行安装。
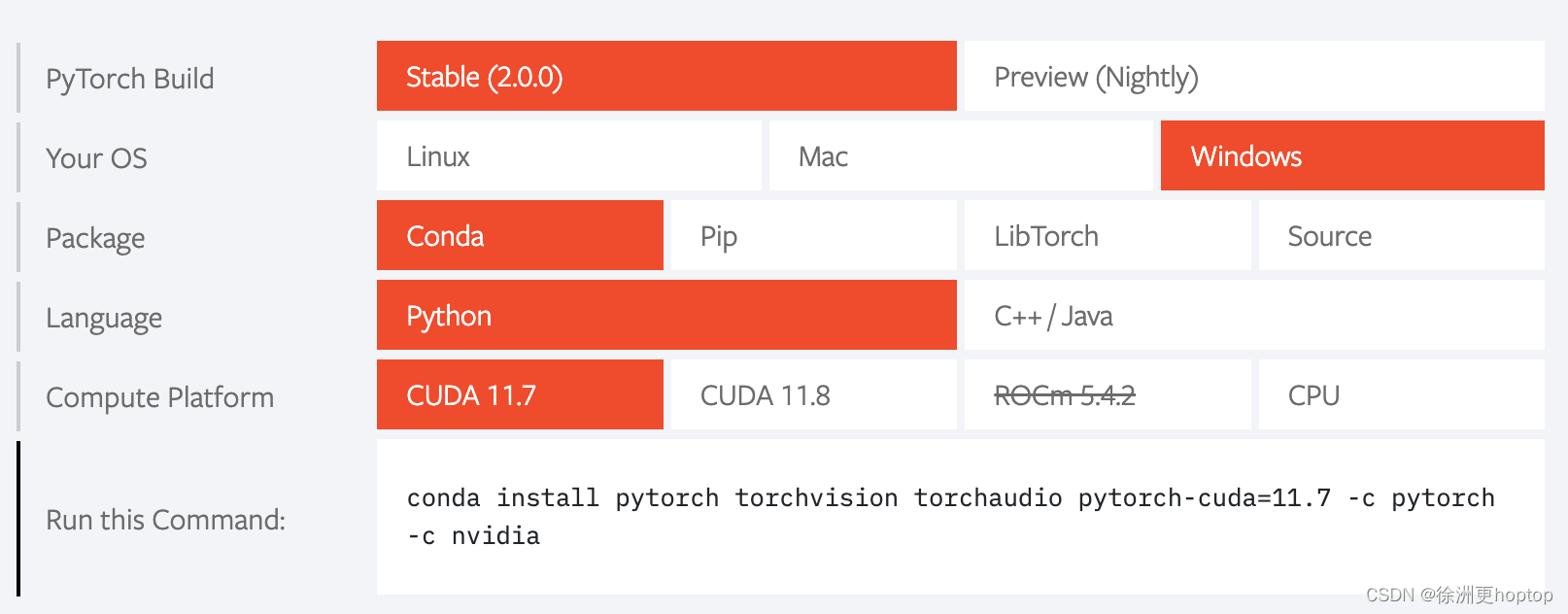
但是有一点不同,为了避免环境冲突,最好是单独创建一个环境,所以代码如下
conda create -n pytorch pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia
接着用 conda activate pytorch启动环境,然后在python环境中测试
import torch torch.has_cuda # True
几个常见的问题(至少我在写文章想到的问题):
Q: 使用conda和pip安装的区别是什么?
A: conda是pytorch官方推荐的安装方式,因为conda会一并帮你装好pytorch运行所需要的CUDA驱动和相关工具集。这意味着为conda所占用的空间会更多一些。
Q: 可以在非常老的硬件上安装最新的pytorch吗?
A: 我觉得这个跟装游戏类似,你虽然能装上游戏,但是不满足游戏的最低配置需求,照样跑不动。
Q: 电脑上必须要安装CUDA驱动和安装CUDA toolkit吗?
A: 其实我个人不是很确定如何回答,如下是我目前的一些见解。如果你用的conda,那么他会帮你解决一些依赖问题。如果你是用pip,那么就需要你自己动手配置。其中,CUDA驱动是必须要安装的,因为CUDA驱动负责将GPU硬件与计算机操作系统相连接,不装驱动,操作系统就不识别CUDA核心,相当你没装NVIDIA显卡。而CUDA toolkit是方便我们调用CUDA核心的各种开发工具集合,你装CUDA toolkit的同时会配套安装CUDA驱动。除非你要做底层开发,或者你需要从源码编译一个pytorch,否则我们大可不装CUDA toolkit。
Q: 如果我电脑上的CUDA驱动版本比较旧怎么办?或者说我CUDA的驱动版本是11.7,但是我安装了cuda=11.8的pytorch,或者版本不一样的pytorch会怎么样?
A: 我们在安装cuda=11.7的pytorch,本质上安装的是在CUDA Toolkit版本为11.7环境下编译好的pytorch版本。当cuda版本之间的差异不是特别的大,或者说不是破坏性的升级的情况下,那么理论上也是能运行的。
手写数据性能测试
下面用的是GPT3.5给我提供一段手写字识别(MNIST)案例代码,用来测试不同的平台的速度。
import torch
import torchvision
import torchvision.transforms as transforms
# 转换数据格式并且加载数据
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))])
trainset = torchvision.datasets.MNIST(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64,
shuffle=True, num_workers=2)
testset = torchvision.datasets.MNIST(root='./data', train=False,
download=False, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=64,
shuffle=False, num_workers=2)
# 定义网络模型
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 6, 5)
self.pool = torch.nn.MaxPool2d(2, 2)
self.conv2 = torch.nn.Conv2d(6, 16, 5)
self.fc1 = torch.nn.Linear(16 * 4 * 4, 120)
self.fc2 = torch.nn.Linear(120, 84)
self.fc3 = torch.nn.Linear(84, 10)
def forward(self, x):
x = self.pool(torch.nn.functional.relu(self.conv1(x)))
x = self.pool(torch.nn.functional.relu(self.conv2(x)))
x = x.view(-1, 16 * 4 * 4)
x = torch.nn.functional.relu(self.fc1(x))
x = torch.nn.functional.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
# 这里的代码比较随意,就是用哪个平台运行哪个
# CPU
device = torch.device("cpu")
# CUDA
device = torch.device("cuda:0")
# MPS
device = torch.device("mps")
net.to(device)
# 定义损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 训练网络
import time
start_time = time.time() # 记录开始时间
for epoch in range(10): # 进行10次迭代训练
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 100 == 99:
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 100))
running_loss = 0.0
end_time = time.time() # 记录结束时间
training_time = end_time - start_time # 计算训练时间
print('Training took %.2f seconds.' % training_time)
print('Finished Training')
# 测试网络
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data[0].to(device), data[1].to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
))
最后统计下来的结果为
Windows平台
- 3070Ti Training took 45.02 seconds.
- i9 12900H Training took CPU 75.65
Mac平台
- M1 Max Training took 50.79 seconds.
- M1 MAX CPU Training took 109.61 seconds.
总体上来说,GPU加速很明显,无论是mac还是Windows。其次是GPU加速效果对比,M1 max芯片比3070Ti差个10%?。
不过目前测试都是小数据集,等我学一段时间,试试大数据集的效果。
到此这篇关于Python Pytorch(gpu)分析环境配置的文章就介绍到这了,更多相关python pytorch配置内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Pytorch Mac GPU 训练与测评实例
目录 正文 加速原理 环境配置 跑一个MNIST 跑一下VAE模型 一个愿景 正文 Pytorch的官方博客发了Apple M1 芯片 GPU加速的文章,这是我期待了很久的功能,因此很兴奋,立马进行测试,结论是在MNIST上,速度与P100差不多,相比CPU提速1.7倍.当然这只是一个最简单的例子,不能反映大部分情况.这里详细记录操作的一步步流程,如果你也感兴趣,不妨自己上手一试. 加速原理 苹果有自己的一套GPU实现API Metal,而Pytorch此次的加速就是基于Metal,具体来说,使
-
Pytorch中实现CPU和GPU之间的切换的两种方法
目录 方法一:.to(device) 1.不知道电脑GPU可不可用时: 2.指定GPU时 3.指定cpu时: 方法二: 总结: 如何在pytorch中指定CPU和GPU进行训练,以及cpu和gpu之间切换 由CPU切换到GPU,要修改的几个地方: 网络模型.损失函数.数据(输入,标注) # 创建网络模型 tudui = Tudui() if torch.cuda.is_available(): tudui = tudui.cuda() # 损失函数 loss_fn = nn.CrossEntro
-
pytorch-gpu安装的经验与教训
首先说明 本文并不是安装教程,网上有很多,这里只是自己遇到的一些问题 我是以前安装的tensorflow-gpu的,但是发现现在的学术论文大部分都是用pytorch复现的,因此才去安装的pytorch-gpu 查看自己安装的CUDA nvcc -V 这里我提供一个安装tensorflow时所用的CUDA对应表 安装cuDNN时版本一定要对应正确 安装完CUDA时要改一下环境变量 只用添加这个就好,其他三个CUDA会自动为你添加 我的是cuda-11.2 但是官网没有配套的,直接就挑自己喜欢的下就
-

pytorch安装及环境配置的完整过程
虚拟环境的创建 命令行窗口中使用 conda create -n 环境名 python=所需python版本 即可创建虚拟环境 pytorch的gpu版本安装 首先确定自己电脑的gpu版本 打开显卡控制面板 点击系统信息,选择组件 产品名称中CUDA后的11.0便是gpu版本 再在pytorch官网选择对应版本 进入为pytorch创建的虚拟环境,输入命令,等待片刻,pytorch便安装完成了. 再在NVIDIA官网安装cuda和cudnn 将cudnn的三个文件分别放入cuda安装目录下,即可
-
Python 机器学习第一章环境配置图解流程
前言 本文主要是分享一下机器学习初期,基本的环境搭建.也适用于其他python工程化项目环境搭建.都差不多. Anaconda安装 anaconda官方链接:Anaconda | The World's Most Popular Data Science Platform 点击Get Started 点击Download Anaconda installers 根据自己的操作系统,下载对应的安装包. 安装anaconda 一路点下去,安装完成. 使用conda配置python3.6环境 目前py
-
Python连接Oracle之环境配置、实例代码及报错解决方法详解
Oracle Client 安装 1.环境 日期:2019年8月1日 公司已经安装好Oracle服务端 Windows版本:Windows10专业版 系统类型:64位操作系统,基于x64的处理器 Python版本:Python 3.6.4 :: Anaconda, Inc. 2.下载网址 https://www.oracle.com/database/technologies/instant-client/downloads.html 3.解压至目录 解压后(这里放D盘) 4.配置环境变量 控制
-
Python Selenium安装及环境配置的实现
一.Python安装 Window系统下,python的安装很简单.访问python.org/download,下载最新版本,安装过程与其他windows软件类似.记得下载后设置path环境变量,然后Windows命令行就可以调用了: 二.Selenium安装 Python3.x安装后就默认就会有pip(pip.exe默认在python的Scripts路径下),使用pip安装selenium: pip install selenium 因我已安装selenium,不可重复安装. 可使用以下命令查
-
PyTorch CUDA环境配置及安装的步骤(图文教程)
Pytorch版本介绍 torch:1.6 CUDA:10.2 cuDNN:8.1.0 ✨安装 NVIDIA 显卡驱动程序 一般 电脑出厂/装完系统 会自动安装显卡驱动 如果有 可直接进行下一步 下载链接 http://www.nvidia.cn/Download/index.aspx?lang=cn 选择和自己显卡相匹配的显卡驱动 下载安装 ✨确认项目所需torch版本 # pip install -r requirements.txt # base ---------------------
-
关于PyTorch环境配置及安装教程(Windows10)
目录 一.Anaconda安装 二.安装pytorch环境 1. 停留在上面 Anaconda Prompt 页面上 2. 出现上述页面 3. 按照上图 4. pytorch安装 三.可能遇到的一些问题 新手在配置pytorch过程中总会或多或少遇到些问题,同时网上关于pytorch的环境配置琳琅满目,不知道应该按照哪个配置,这里笔者记录一下自己在windows10下配置Pytorch的全过程. 笔者电脑环境以及安装版本为:Windows10 企业版 + python 3.7.9 + Anaco
-
如何在conda虚拟环境中配置cuda+cudnn+pytorch深度学习环境
首先,我们要明确,我们是要在虚拟环境中安装cuda和cuDNN!!!只需要在虚拟环境中安装就可以了. 下面的操作默认你安装好了python 一.conda创建并激活虚拟环境 前提:确定你安装好了anaconda并配置好了环境变量,如果没有,网上有很多详细的配置教程,请自行学习 在cmd命令提示符中输入conda命令查看anaconda 如果显示和上图相同,那么可以继续向下看 1.进入anaconda的base环境 方法1 在cmd命令提示符中输入如下命令 activate 方法2 直接在搜索栏里
-
pytorch环境配置及安装图文详解(包括anaconda的安装)
目录 下载安装anaconda 如何验证是否已经安装成果 管理环境 查看计算机GPU型号是否支持coda 安装pytorch 查看驱动版本 进入pytorch首页PyTorch 检验安装是否成果 检查torch是否使用于计算机cpu 下载安装anaconda 打开anaconda官网Anaconda | The World's Most Popular Data Science Platform 点击安装(这里安装的版本是Python 3.9 • 64-Bit Graphical Install
-
Ubuntu 下 vim 搭建python 环境 配置
1. 安装完整的vim # apt-get install vim-gnome 2. 安装ctags,ctags用于支持taglist,必需! # apt-get install ctags 3. 安装taglist #apt-get install vim-scripts #apt-get install vim-addon-manager # vim-addons install taglist 4. 安装pydiction(实现代码补全) #wget http://www.pythoncl
-
全面了解Python环境配置及项目建立
一.安装Python Python比较稳定的两个版本是Python 3.5和Python 2.7,我用的是Python 2.7,下载地址是:https://www.python.org/downloads/,下载之后按照正常的软件安装过程安装即可. 配置Python环境变量:控制面板->系统->高级系统设置->环境变量->Path,在Path中添加python的安装路径,例如:C:\Python27:然后,一直点击 确定 or OK.python环境变量即配置完成,打开cmd,输入