Python 之pandas库的安装及库安装方法小结
目录
- 一、pandas库的安装
- 1.打开cmd窗口。
- 2.找到安装的Python路径。
- 3.进入文件路径
- 4.输入命令pip install pandas执行安装。
- 5. 新建test.py文件测试,确定是否能够成功引入pandas库。
- 二、唠唠库安装(敲重点!)
- 1.安装方法总结
- 2.国内的一些镜像站点
如果你连续看了博主的各类Python的库引用,你会发现这都是套路!!!
先上正儿八经的流程,后面一句话总结一下这些库的安装套路。不知道安装库的你们用的什么操作?
请耐心看到最后哦!保证未来的安装一举成功!
一、pandas库的安装
1.打开cmd窗口。
(1)点击开始栏,搜索cmd并打开。
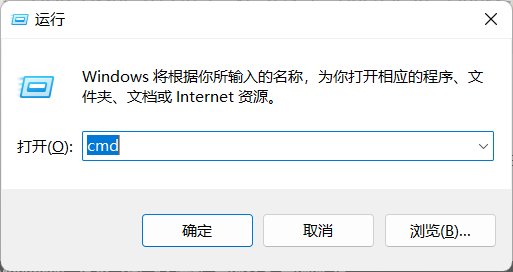
(2)或者快捷键win+R打开。
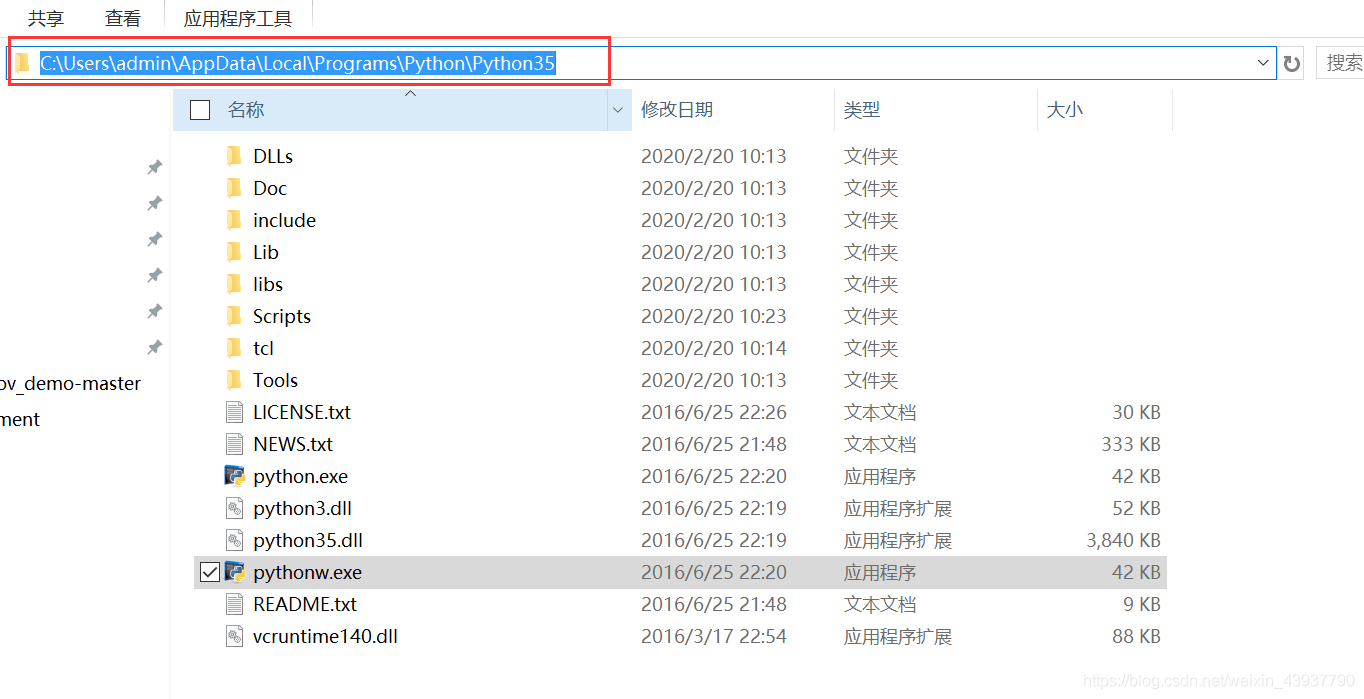
2.找到安装的Python路径。
可以通过右键点击Python快捷键,查找文件路径。(博主电脑并未分盘,故安装到了C盘,这里推荐大家安装到D盘或E盘等路径。)
3.进入文件路径
在输入cd+空格+文件路径,进入文件路径下进行安装。

4.输入命令pip install pandas执行安装。
**提示:**这里要求pandas的安装是在pip库已经安装好的前提下进行的。如果没有安装或无法确定是否安装pip库,可以查看下文连接确定【pip库的安装与版本检查】
可以看到,红色的字中,有runtime超时提示。
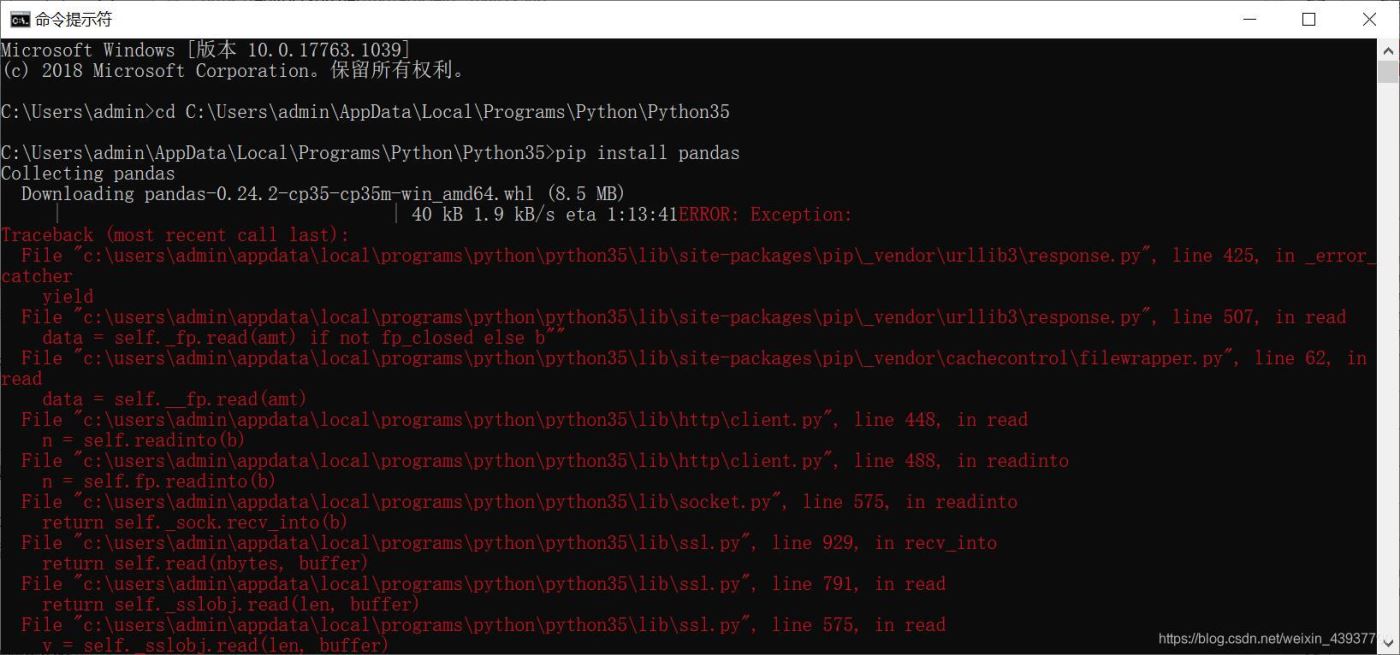
换用了镜像的安装命令,成功!
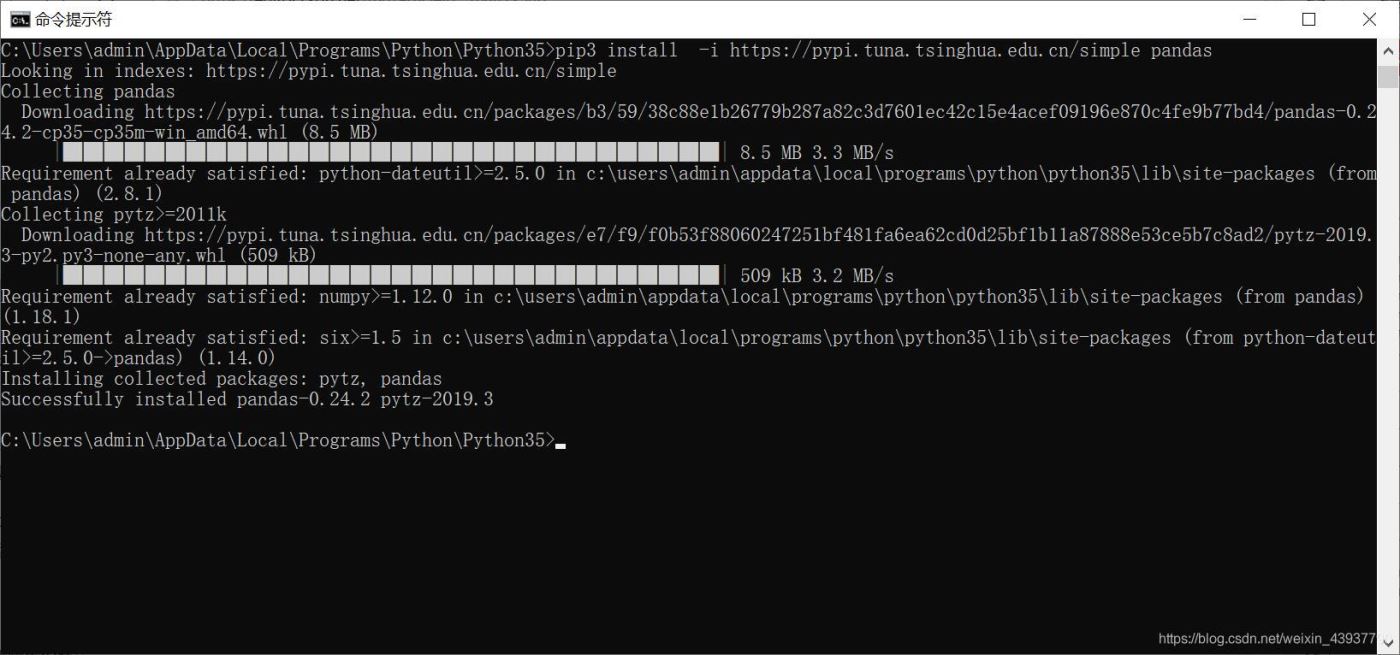
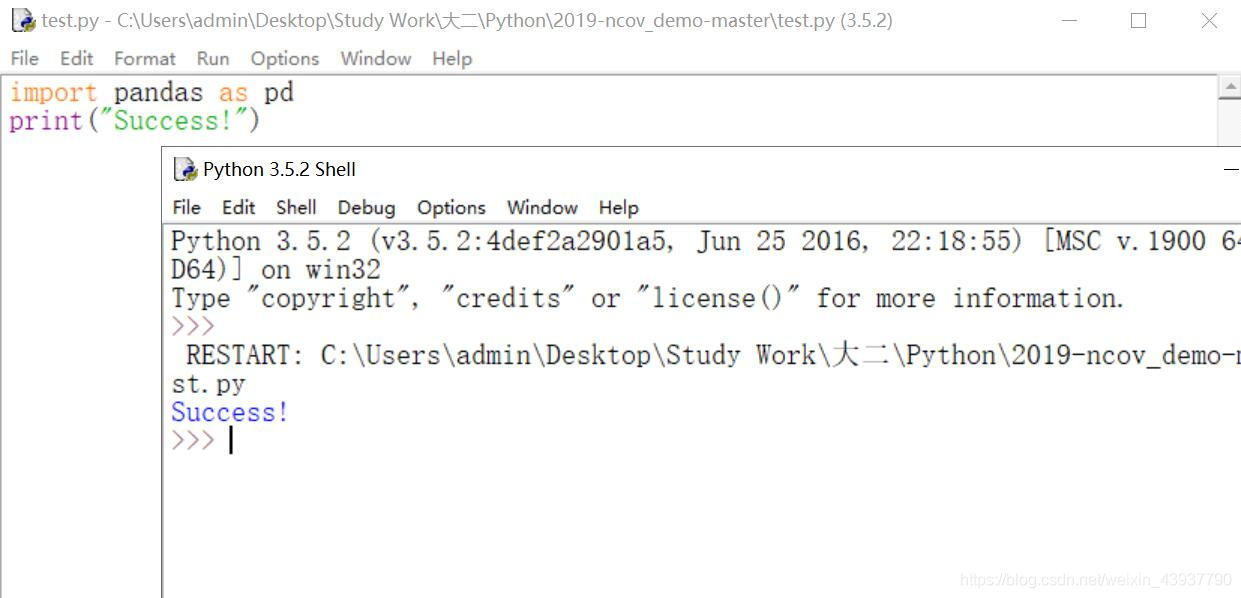
5. 新建test.py文件测试,确定是否能够成功引入pandas库。
import pandas as pdprint("Success!")
二、唠唠库安装(敲重点!)
1.安装方法总结
不知道聪明的你有没有发现,这些库的安装是有一定套路的。只要掌握了这些套路,只有你想不到的库,没有你安不了的库。
(1)通用套路:查找文件路径,使用cmd的cd命令进入该路径;输入命令pip install +包名 即可开始安装。
(2)镜像套路:查找文件路径,使用cmd的cd命令进入该路径;输入命令pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple +包名即可开始安装。
如果你是初学者,记得安装pycharm,并配置好环境变量。这样之后就可以直接在pycharm中安装库了,更为方便简洁。
pycharm推荐安装专业版的,这样以后如果想利用pycharm作python的开发,会更加方便,B站有很多破解方法的视频(当事人表示非常后悔,为什么不早早安装专业版)。只是简单的学习如何使用python的话,社区版足够用啦。
2.国内的一些镜像站点
清华:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科技大学 (这个真心快,我用清华镜像的时候反而超时了,难道是用的人少?):https://pypi.mirrors.ustc.edu.cn/simple/
华中理工大学:http://pypi.hustunique.com/
山东理工大学:http://pypi.sdutlinux.org/
到此这篇关于Python 之pandas库的安装及库安装方法小结的文章就介绍到这了,更多相关Python安装pandas库内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python pandas库中的isnull()详解
问题描述 python的pandas库中有一个十分便利的isnull()函数,它可以用来判断缺失值,我们通过几个例子学习它的使用方法. 首先我们创建一个dataframe,其中有一些数据为缺失值. import pandas as pd import numpy as np df = pd.DataFrame(np.random.randint(10,99,size=(10,5))) df.iloc[4:6,0] = np.nan df.iloc[5:7,2] = np.nan df.iloc[
-

python Pandas库read_excel()参数实例详解
目录 1.read_excel函数原型 2.参数使用举例 2.1. io和sheet_name参数 2.2. header参数 2.3. skipfooter参数 2.5. parse_dates参数 2.6. converters参数 2.7. na_values参数 2.8. usecols参数 总结 Pandas read_excel()参数使用详解 1.read_excel函数原型 def read_excel(io, sheet_name=0, header=0, names=None
-
python pandas库读取excel/csv中指定行或列数据
目录 引言 1.根据index查询 2.已知数据在第几行找到想要的数据 3.根据条件查询找到指定行数据 4.找出指定列 5.找出指定的行和指定的列 6.在规定范围内找出符合条件的数据 总结 引言 关键!!!!使用loc函数来查找. 话不多说,直接演示: 有以下名为try.xlsx表: 1.根据index查询 条件:首先导入的数据必须的有index 或者自己添加吧,方法简单,读取excel文件时直接加index_col 代码示例: import pandas as pd #导入pandas库 ex
-
Python pandas库中isnull函数使用方法
前言: python的pandas库中有⼀个⼗分便利的isnull()函数,它可以⽤来判断缺失值,我们通过⼏个例⼦学习它的使⽤⽅法.⾸先我们创建⼀个dataframe,其中有⼀些数据为缺失值. import pandas as pd import numpy as np df = pd.DataFrame(np.random.randint(10,99,size=(10,5))) df.iloc[4:6,0] = np.nan df.iloc[5:7,2] = np.nan df.iloc[7,
-
Python数据分析库pandas高级接口dt的使用详解
Series对象和DataFrame的列数据提供了cat.dt.str三种属性接口(accessors),分别对应分类数据.日期时间数据和字符串数据,通过这几个接口可以快速实现特定的功能,非常快捷. 今天翻阅pandas官方文档总结了以下几个常用的api. 1.dt.date 和 dt.normalize(),他们都返回一个日期的 日期部分,即只包含年月日.但不同的是date返回的Series是object类型的,normalize()返回的Series是datetime64类型的. 这里先简单
-
Python使用Pandas对csv文件进行数据处理的方法
今天接到一个新的任务,要对一个140多M的csv文件进行数据处理,总共有170多万行,尝试了导入本地的MySQL数据库进行查询,结果用Navicat导入直接卡死....估计是XAMPP套装里面全默认配置的MySQL性能不给力,又尝试用R搞一下吧结果发现光加载csv文件就要3分钟左右的时间,相当不给力啊,翻了翻万能的知乎发现了Python下的一个神器包:Pandas(熊猫们?),加载这个140多M的csv文件两秒钟就搞定,后面的分类汇总等操作也都是秒开,太牛逼了!记录一下这次数据处理的过程: 使用
-
Python使用pandas对数据进行差分运算的方法
如下所示: >>> import pandas as pd >>> import numpy as np # 生成模拟数据 >>> df = pd.DataFrame({'a':np.random.randint(1, 100, 10),\ 'b':np.random.randint(1, 100, 10)},\ index=map(str, range(10))) >>> df a b 0 21
-
在python中pandas读文件,有中文字符的方法
后面要加encoding='gbk' import pandas as pd datt=pd.read_csv('D:\python_prj_1\data_1.txt',encoding='gbk') print(datt) 以上这篇在python中pandas读文件,有中文字符的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
python 环境安装及编辑器配置方法小结
第一步:python解释器,到网上下载安装下就行. 网址:https://www.python.org/downloads/windows/ 值得注意的是,你需要关注python的版本号,因为3和2版本已经不兼容了,如果你要学习的话就学3吧. 我的是安装在c盘. 配置环境 在安装的时候当然可以选择自动配置,但是也可能是电脑的一些问题冲突了,就可能没有配置好,这时候需要我们手动去配置. 配置到达指定路径: 选择path,然后把python安装目录放下去,我的是C:\Program Files\Py
-
python对指定字符串逆序的6种方法(小结)
对于一个给定的字符串,逆序输出,这个任务对于python来说是一种很简单的操作,毕竟强大的列表和字符串处理的一些列函数足以应付这些问题 了,今天总结了一下python中对于字符串的逆序输出的几种常用的方法 方法一:直接使用字符串切片功能逆转字符串 #!usr/bin/env python # encoding:utf-8 def strReverse(strDemo): return strDemo[::-1] print(strReverse('pythontab.com')) 结果: moc
-
Python使用pandas和xlsxwriter读写xlsx文件的方法示例
python使用pandas和xlsxwriter读写xlsx文件 已有xlsx文件如下: 1. 读取前n行所有数据 # coding: utf-8 import pandas as pd # 1. 读取前n行所有数据 df = pd.read_excel('school.xlsx')#读取xlsx中第一个sheet data1 = df.head(7) # 读取前7行的所有数据,dataFrame结构 data2 = df.values #list形式,读取表格所有数据 print("获取到所
-
Windows下anaconda安装第三方包的方法小结(tensorflow、gensim为例)
anaconda 集成了很多科学计算中所需要的包,如numpy,scipy等等,具体查看anaconda中已经预先安装配置好的包有哪些,可以通过cmd命令,输入conda list 查看,如下图所示: 但是,因为实际需求,我们会需要导入列表中没有的第三方包,如gemsim,在anaconda中,我们可以参考以下步骤安装所需要的第三方包: 1.启动anaconda 命令窗口: 开始 > 所有程序 > anaconda >anaconda prompt 2.安装gens
-
SQL Server 2005 更改安装路径目录的方法小结
今天晚上小编在加班时有朋友咨询关于SQL Server 2005 更改安装路径目录的问题,告诉了朋友,顺手又在网上找了其它几个方法,第一个方法是默认的,是小编告诉朋友的. 方法1. 在安装过程中,安装到选择需要安装的组件时,点高级就可以了.之后就会看到更改安装路径的地方 方法2.更改注册表的默认安装路径: 安装完成需要站500M左右空间 可以更改路径安装,下面是更改方法: 打开注册表找到:"HEKY_LOCAL_MACHINE\Software\Microsoft\Windows\Current
-
python中快速进行多个字符替换的方法小结
先给出结论: 要替换的字符数量不多时,可以直接链式replace()方法进行替换,效率非常高: 如果要替换的字符数量较多,则推荐在 for 循环中调用 replace() 进行替换. 可行的方法: 1. 链式replace() string.replace().replace() 1.x 在for循环中调用replace() 「在要替换的字符较多时」 2. 使用string.maketrans 3. 先 re.compile 然后 re.sub -- def a(text): chars = "
-
python使用Pandas库提升项目的运行速度过程详解
前言 如果你从事大数据工作,用Python的Pandas库时会发现很多惊喜.Pandas在数据科学和分析领域扮演越来越重要的角色,尤其是对于从Excel和VBA转向Python的用户. 所以,对于数据科学家,数据分析师,数据工程师,Pandas是什么呢?Pandas文档里的对它的介绍是: "快速.灵活.和易于理解的数据结构,以此让处理关系型数据和带有标签的数据时更简单直观." 快速.灵活.简单和直观,这些都是很好的特性.当你构建复杂的数据模型时,不需要再花大量的开发时间在等待数据处理的