Pandas数据分析之pandas数据透视表和交叉表
目录
- 前言
- 整理透视 pivot
- 聚合透视 Pivot Table
- 聚合透视高级操作
- 交叉表crosstab()
- 数据融合melt()
- 数据堆叠 stack
前言
pandas对数据框也可以像excel一样进行数据透视表整合之类的操作。主要是针对分类数据进行操作,还可以计算数值型数据,去满足复杂的分类数据整理的逻辑。
首先还是导入包:
import numpy as np import pandas as pd
整理透视 pivot
首先介绍的是最简单的整理透视函数pivot,其原理如图:

pivot参数:
- index:新 df 的索引列,用于分组,如果为None,则使用现有索引
- columns:新 df 的列,如果透视后有重复值会报错
- values:用于填充 df 的列。 如果未指定,将使用所有剩余的列,并且结果将具有按层次结构索引的列
用法如下,首先生成案例数据df
df = pd.DataFrame({'foo': ['one', 'one', 'one', 'two', 'two', 'two'],
'bar': ['A', 'B', 'C', 'A', 'B', 'C'],
'baz': [1, 2, 3, 4, 5, 6],
'zoo': ['x', 'y', 'z', 'q', 'w', 't']})
df

df.pivot(index='foo', columns='bar', values='baz')

可以看到是一一对应。简单来说就是把foo、bar两个分类变量整到行列名称上去了,baz作为值
# 多层索引,可以取其中一列 df.pivot(index='foo', columns='bar') #['baz']
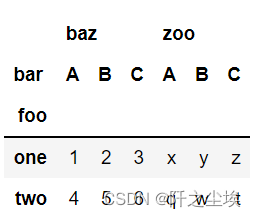
# 指定值 df.pivot(index='foo', columns='bar', values=['baz', 'zoo'])

聚合透视 Pivot Table
上面的pivot只适用于一一对应的情况,如果分类变量的组合一样,但是取值不一样就会报错。此时应该用Pivot Table,他默认计算相同情况的均值。
参数:
- data: 要透视的 DataFrame 对象
- values: 要聚合的列或者多个列
- index: 在数据透视表索引上进行分组的键
- columns: 在数据透视表列上进行分组的键
- aggfunc: 用于聚合的函数, 默认是 numpy.mean'''
df = pd.DataFrame({"A": ["a1", "a1", "a1", "a2", "a2","a2"],
"B": ["b2", "b2", "b1", "b1", "b1","b1"],
"C": ['c1','c1','c2','c2','c1','c1'],
"D": [1, 2, 3, 4, 5, 6]})
df

#索引a,列b使用Pivot会报错,因为他们之间的组合有重复,要用Pivot Table,默认计算均值 pd.pivot_table(df,index='A',columns='B',values='D')
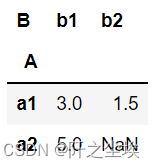
#验证一下b1,a2这个均值5 df.loc[(df.A=='a2')&(df.B=='b1')].D.mean()

聚合透视高级操作
pd.pivot_table(df,index=['A','B'],#指定多个索引
columns=['C'], #指定列
values='D', #数据值列
aggfunc=np.sum, #聚合函数
fill_value=0, #空值填充
margins=True #增加汇总列
)

#多个计算方法
pd.pivot_table(df,index=['A','B'],#指定多个索引
columns=['C'], #指定列
values='D', #数据值列
aggfunc=[np.sum,np.mean,np.std]
)

交叉表crosstab()
交叉表是用于统计分组频率的特殊透视表。简单来说,就是将两个或者多个列重中不重复的元素组成一个新的 DataFrame,新数据的行和列交叉的部分值为其组合在原数据中的数量
语法结构如下:
pd.crosstab(index, columns, values=None, rownames=None,colnames=None, aggfunc=None, margins=False,
margins_name: str = 'All', dropna: bool = True,normalize=False) #→ 'DataFrame'
参数说明:
index:类数组,在行中按分组的值。
columns:类数组的值,用于在列中进行分组。
values:类数组的,可选的,要根据因素汇总的值数组。
aggfunc:函数,可选,如果未传递任何值数组,则计算频率表。
rownames:序列,默认为None,必须与传递的行数组数匹配。
colnames:序列,默认值为None,如果传递,则必须与传递的列数组数匹配。
margins:布尔值,默认为False,添加行/列边距(小计)
normalize:布尔值,{'all','index','columns'}或{0,1},默认为False。 通过将所有值除以值的总和进行归一化。'
生成案例数据:
df = pd.DataFrame({"A": ["a1", "a1", "a1", "a2", "a2","a2"],
"B": ["b2", "b2", "b1", "b1", "b1","b1"],
"C": ['c1','c1','c2','c2','c1','c1'],
"D": [1, 2, 3, 4, 5, 6]})
df

pd.crosstab(df['A'],df['B']) #都是分类数据,计算频率
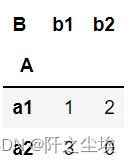
pd.crosstab(df['A'],df['C']) #都是分类数据

#对交叉结果进行归一化: pd.crosstab(df['A'], df['B'], normalize=True)

#对每列进行归一化: pd.crosstab(df['A'], df['B'], normalize='columns')

#聚合,指定列做为值,并将这些值按一定算法进行聚合: pd.crosstab(df['A'], df['C'], values=df['D'], aggfunc=np.sum) #分类和数值

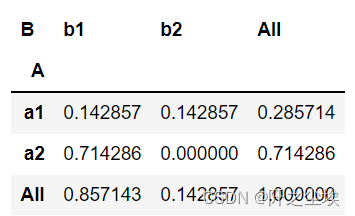
#边距汇总,在最右边增加一个汇总列:
pd.crosstab(df['A'], df['B'],values=df['D'],aggfunc=np.sum,
normalize=True,margins=True)
数据融合melt()
#df.melt() 是 df.pivot() 逆转操作函数。简单说就是将指定的列放到铺开放到行上名为variable(可指定)列,值在value(可指定)列

语法结构:
具体语法结构如下:
pd.melt(frame: pandas.core.frame.DataFrame,id_vars=None, value_vars=None, var_name='variable', value_name='value',col_level=None)
其中:
- id_varstuple:list或ndarray(可选),用作标识变量的列。
- value_varstuple:列表或ndarray,可选,要取消透视的列。 如果未指定,则使用未设置为id_vars的所有列。
- var_namescalar:用于“变量”列的名称。 如果为None,则使用frame.columns.name或“variable”。
- value_namescalar:默认为“ value”,用于“ value”列的名称。
- col_levelint或str:可选,如果列是MultiIndex,则使用此级别来融化。
生成案例数据:
df=pd.DataFrame({'A':['a1','a2','a3','a4','a5'],
'B':['b1','b2','b3','b4','b5'],
'C':[1,2,3,4,5]})
df

pd.melt(df)

#指定标识和值, pd.melt(df,id_vars=['A']) #只对BC展开

pd.melt(df,value_vars=['B','C']) #保留BC,并展开

#同时指定,并命名 pd.melt(df,id_vars=['A'],value_vars=['B'],var_name='B_label',value_name='B_value')
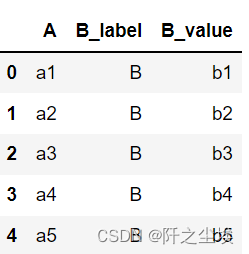
数据堆叠 stack
#stack就是把列变量堆到行上,unstack就是行变到列上

生成案例数据 :
#堆叠 stack 单层索引:
df = pd.DataFrame({'A':['a1','a1','a2','a2'],
'B':['b1','b2','b1','b2'],
'C':[1,2,3,4],
'D':[5,6,7,8],
'E':[5,6,7,8]})
df.set_index(['A','B'],inplace=True)
df

stack 堆叠
df.stack()

unstack 解堆
df.stack().unstack()
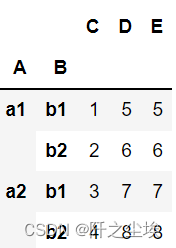
df.stack().unstack().unstack()
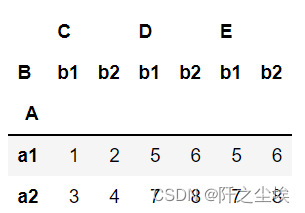
df.stack().unstack().unstack().unstack()

可以看到,解堆就是不停地把列变量弄到行上去作为索引。
到此这篇关于Pandas数据分析之pandas数据透视表和交叉表的文章就介绍到这了,更多相关pandas数据透视表内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python+Pandas实现数据透视表
目录 导入示例数据 参数说明 常用操作 大家好,我是丁小杰. 对于数据透视表,相信对于 Excel 比较熟悉的小伙伴都知道如何使用它,并了解它的强大之处,而在pandas中要实现数据透视就要用到pivot_table了. 导入示例数据 首先导入演示的数据集. import pandas as pd df = pd.read_csv('销售目标.csv') df.head() 参数说明 主要参数: data:待操作的 DataFrame values:被聚合操作的列,可选项 index:行分组键,
-
一文搞懂Python中pandas透视表pivot_table功能详解
目录 一.概述 1.1 什么是透视表? 1.2 为什么要使用pivot_table? 二.如何使用pivot_table 2.1 读取数据 2.2Index 2.3Values 2.4Aggfunc 2.5Columns 一文看懂pandas的透视表pivot_table 一.概述 1.1 什么是透视表? 透视表是一种可以对数据动态排布并且分类汇总的表格格式.或许大多数人都在Excel使用过数据透视表,也体会到它的强大功能,而在pandas中它被称作pivot_table. 1.2 为什么要使用
-
pandas 透视表中文字段排序方法
前几天有一个需求,透视表中的年级这一列要按照一年级,二年级这样的序列进行排序,但是用过透视表的人都知道,透视表对中文的排序不是太理想,放弃pandas自带的排序方法.测试了很久,想到一个办法.先把dataframe中需要特殊排序的列中的汉字转换成数字,然后生成透视表,生成透视表之后,再把透视表的index或者columns中的数字替换成相应的汉字,透视表的结果就会按照你想要的顺序进行排序. def get_special_sort_data(self, groupby, columns): #
-
Pandas透视表(pivot_table)详解
介绍 也许大多数人都有在Excel中使用数据透视表的经历,其实Pandas也提供了一个类似的功能,名为pivot_table.虽然pivot_table非常有用,但是我发现为了格式化输出我所需要的内容,经常需要记住它的使用语法.所以,本文将重点解释pandas中的函数pivot_table,并教大家如何使用它来进行数据分析. 如果你对这个概念不熟悉,wikipedia上对它做了详细的解释.顺便说一下,你知道微软为PivotTable(透视表)注册了商标吗?其实以前我也不知道.不用说,下面我将讨论
-
pandas实现excel中的数据透视表和Vlookup函数功能代码
在孩子王实习中做的一个小工作,方便整理数据. 目前这几行代码是实现了一个数据透视表和匹配的功能,但是将做好的结果写入了不同的excel中, 如何实现将结果连续保存到同一个Excel的同一个工作表中? 还需要探索. import pandas as pd import numpy as np a = [1601,1602,1603,1604,1605,1606,1607,1608,1609,1610,1611,1612,1701,1702,1703,1704] for i in a: b = st
-
python 用pandas实现数据透视表功能
透视表是一种可以对数据动态排布并且分类汇总的表格格式.对于熟练使用 excel 的伙伴来说,一定很是亲切! pd.pivot_table() 语法: pivot_table(data, # DataFrame values=None, # 值 index=None, # 分类汇总依据 columns=None, # 列 aggfunc='mean', # 聚合函数 fill_value=None, # 对缺失值的填充 margins=False, # 是否启用总计行/列 dropna=True,
-
Pandas数据分析之pandas数据透视表和交叉表
目录 前言 整理透视 pivot 聚合透视 Pivot Table 聚合透视高级操作 交叉表crosstab() 数据融合melt() 数据堆叠 stack 前言 pandas对数据框也可以像excel一样进行数据透视表整合之类的操作.主要是针对分类数据进行操作,还可以计算数值型数据,去满足复杂的分类数据整理的逻辑. 首先还是导入包: import numpy as np import pandas as pd 整理透视 pivot 首先介绍的是最简单的整理透视函数pivot,其原理如图: pi
-
Pandas数据分析之pandas文本处理
目录 前言 文本数据类型 字符操作 文本格式 文本对齐 文本计数和编码 格式判断 文本高级处理 文本分割 文本切片选择 slice 划分 partition 文本替换 指定位置替换 重复替换 文本连接 文本查询 文本包含 文本匹配 文本提取 提取虚拟变量 前言 pandas对文本数据也有很多便捷处理方法,可以不用写循环,向量化操作运算速度快,还可以进行高级的正则表达式,各种复杂的逻辑筛选和匹配提取信息.对于机器学习来说,从文本中做特征工程很是很有用的. 还是先导入包,读取案例数据: impor
-
Pandas使用stack和pivot实现数据透视的方法
目录 前言 一.经过统计得到多维度指标数据 二.使用unstack实现数据的二维透视 三.使用pivot简化透视 四.stack.unstack.pivot的语法 1.stack 2.unstack 3.pivot 总结 前言 笔者最近正在学习Pandas数据分析,将自己的学习笔记做成一套系列文章.本节主要记录Pandas中使用stack和pivot实现数据透视. 一.经过统计得到多维度指标数据 非常场景的统计场景,指定多个维度,计算聚合后的指标 实例:统计得到"电影评分数据集",每个
-
一文搞懂Pandas数据透视的4个函数的使用
目录 pandas.melt() pandas.pivot() pandas.pivot_table() pandas.crosstab() 大家好,我是丁小杰! 今天和大家分享Pandas中四种有关数据透视的通用函数,在数据处理中遇到这类需求时,能够很好地应对. pandas.melt() melt函数的主要作用是将DataFrame从宽格式转换成长格式. “ pandas.melt(frame,id_vars=None, value_vars=None, var_name=None, val
-
Python数据分析之pandas读取数据
一.三种数据文件的读取 二.csv.tsv.txt 文件读取 1)CSV文件读取: 语法格式:pandas.read_csv(文件路径) CSV文件内容如下: import pandas as pd file_path = "e:\\pandas_study\\test.csv" content = pd.read_csv(file_path) content.head() # 默认返回前5行数据 content.head(3) # 返回前3行数据 content.shape # 返回
-
Pandas数据分析-pandas数据框的多层索引
目录 前言 创建多层索引 多层索引操作 索引名称的查看 索引的层级 索引内容的查看 数据查询 数据分组 前言 pandas数据框针对高维数据,也有多层索引的办法去应对.多层数据一般长这个样子 可以看到AB两大列,下面又有xy两小列. 行有abc三行,又分为onetwo两小行. 在分组聚合的时候也会产生多层索引,下面演示一下. 导入包和数据: import numpy as np import pandas as pd df=pd.read_excel('team.xlsx') 分组聚合: df.
-
Pandas数据分析的一些常用小技巧
Pandas小技巧 import pandas as pd pandas生成数据 d = {"sex": ["male", "female", "male", "female"], "color": ["red", "green", "blue", "yellow"], "age": [1