SQL语句中的ON DUPLICATE KEY UPDATE使用
目录
- 一:主键索引,唯一索引和普通索引的关系
- 主键索引
- 唯一索引:
- 普通索引:
- 二:ON DUPLICATE KEY UPDATE使用测试(MYSQL下的Innodb引擎)
- 1:ON DUPLICATE KEY UPDATE功能介绍:
- 2:ON DUPLICATE KEY UPDATE测试样例+总结:
- 总结:
一:主键索引,唯一索引和普通索引的关系
主键索引
主键索引是唯一索引的特殊类型。
数据库表通常有一列或列组合,其值用来唯一标识表中的每一行。该列称为表的主键。
在数据库关系图中为表定义一个主键将自动创建主键索引,主键索引是唯一索引的特殊类型。主键索引要求主键中的每个值是唯一的。当在查询中使用主键索引时,它还允许快速访问数据。主键索引不能为空。每个表只能有一个主键
唯一索引:
不允许两行具有相同的索引值。但可以都为NULL,笔者亲试。
如果现有数据中存在重复的键值,则数据库不允许将新创建的唯一索引与表一起保存。当新数据将使表中的键值重复时,数据库也拒绝接受此数据。每个表可以有多个唯一索引
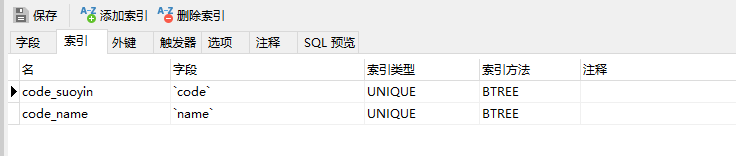
普通索引:
一般的索引结构,可以在条件删选时加快查询效率,索引字段的值可以重复,可以为空值
二:ON DUPLICATE KEY UPDATE使用测试(MYSQL下的Innodb引擎)
上面介绍了索引的知识,是为了介绍这个ON DUPLICATE KEY UPDATE功能做铺垫。
1:ON DUPLICATE KEY UPDATE功能介绍:
有时候由于业务需求,可能需要先去根据某一字段值查询数据库中是否有记录,有则更新,没有则插入。你可能是下面这样写的
if not exists (select node_name from node_status where node_name = target_name)
insert into node_status(node_name,ip,...) values('target_name','ip',...)
else
update node_status set ip = 'ip',site = 'site',... where node_name = target_name
这样写在大多数情况下可以满足我们的需求,但是会有两个问题。
①性能带来开销,尤其是系统比较大的时候。
②在高并发的情况下会出现错误,可能需要利用事务保证安全。
有没有一种优雅的写法来实现有则更新,没有则插入的写法呢?ON DUPLICATE KEY UPDATE提供了这样的一个方式。
2:ON DUPLICATE KEY UPDATE测试样例+总结:
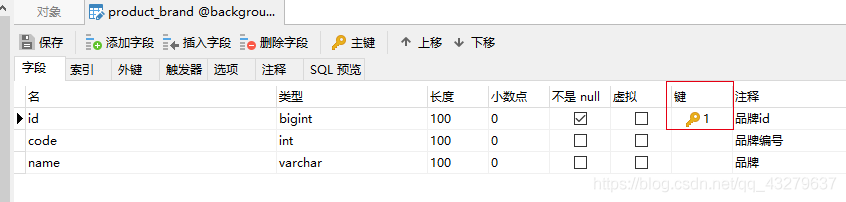
首先我们了解下这个简单的表结构id(主键)、code、name。
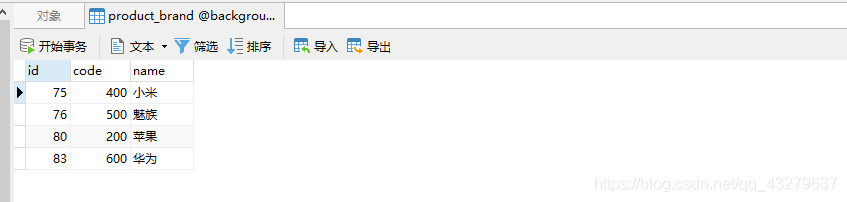
看下表中现有的数据:
执行以下实验进行分析:
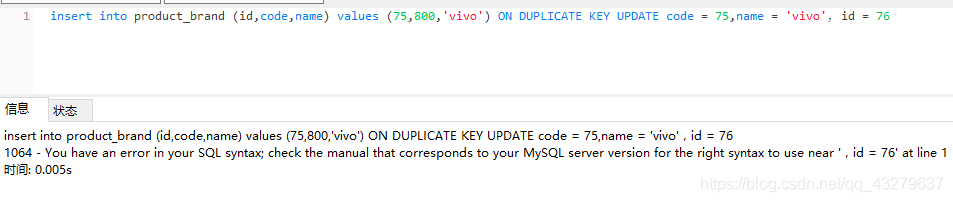
实验一:含有ON DUPLICATE KEY UPDATE的INSERT语句中包含主键:
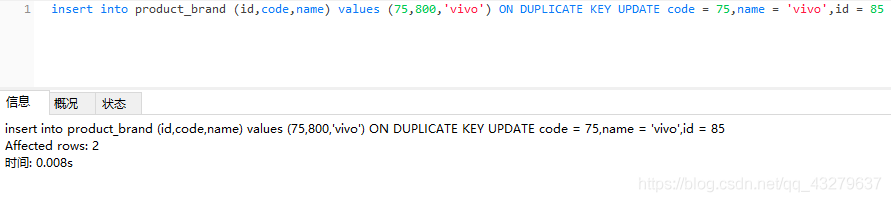
①插入更新都失败,原因是因为把主键id改成了已经存在的id
②执行更新操作。这里的数据还是四条。不过第四条的id由75变化为85
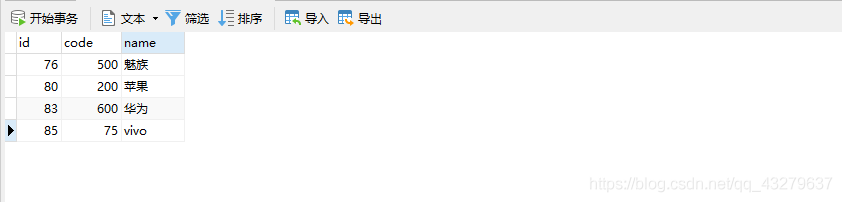
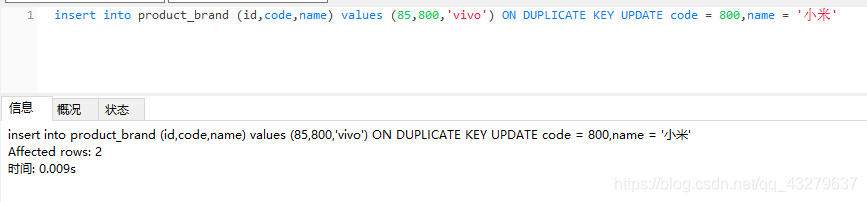
③执行更新操作。数据总量是四条

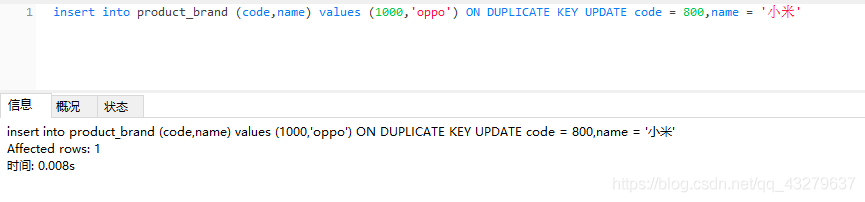
④insert语句中未包含主键,执行插入操作。数据量变为5条
实验二:含有ON DUPLICATE KEY UPDATE的INSERT语句中包含唯一索引:
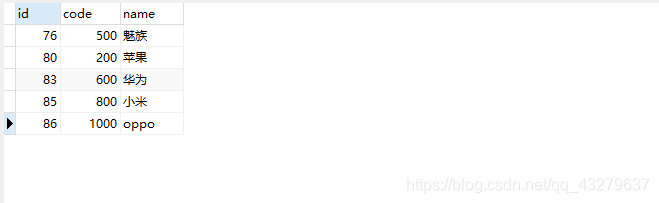
表结构中增加code的唯一索引,表中现有的数据:
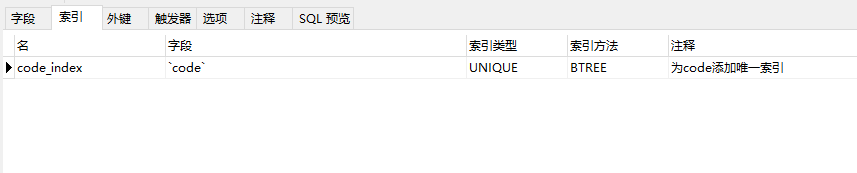
①插入更新都失败,原因是因为把code改成了已经存在的code值
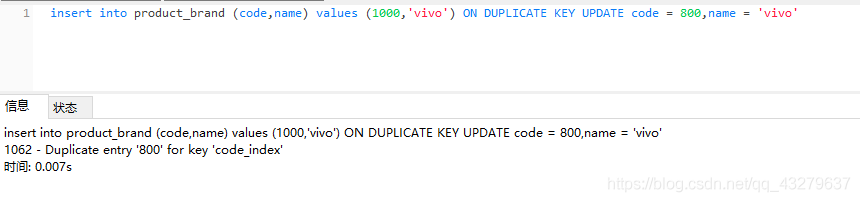
②执行更新操作。这里的数据总量为5条。不过第五条的code由1000变化为1200


③执行更新操作。数据总量五条,没有变化
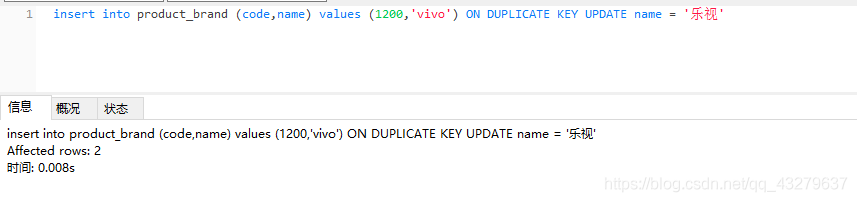

④insert语句中未包含唯一索引,执行插入操作。数据量变为6条

总结:
1:ON DUPLICATE KEY UPDATE需要有在INSERT语句中有存在主键或者唯一索引的列,并且对应的数据已经在表中才会执行更新操作。而且如果要更新的字段是主键或者唯一索引,不能和表中已有的数据重复,否则插入更新都失败。
2:不管是更新还是增加语句都不允许将主键或者唯一索引的对应字段的数据变成表中已经存在的数据。
最后感谢博主文章:MySQL:插入更新语句ON DUPLICATE KEY UPDATE
到此这篇关于SQL语句中的ON DUPLICATE KEY UPDATE使用的文章就介绍到这了,更多相关SQL ON DUPLICATE KEY UPDATE内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

mysql ON DUPLICATE KEY UPDATE重复插入时更新方式
目录 mysql当插入重复时更新的方法 第一种方法 第二种方法 第三种方法 Mysql on duplicate key update 解决插入重复数据时更新值的问题以及其存在的问题 一.使用 二.存在问题 mysql当插入重复时更新的方法 第一种方法 示例一:插入多条记录 假设有一个主键为 client_id 的 clients 表,可以使用下面的语句: INSERT INTO clients (client_id,client_name,client_type) SELECT supplie
-
MYSQL的REPLACE和ON DUPLICATE KEY UPDATE语句介绍解决问题实例
在对看看的后台进行排序的时候,遇到了一个像这样的需求,在电影表中有ID(主键自增)和orderby(排序字段) ,假设有十条数据id分别从1-10之间,对应的orderby也是从1-10之间,我现在想把id=9的数据移动到第三的位置(id=3)的这个位置,并且保证之前的数据排列顺序(即id=3的orderby=4,id=4的orderby=5-id=8的orderby=9),这样如果用循环的形式是可以解决数据的问题,但是这样操作数据库过程太多,现在就想用一条sql语句来解决这个问题. 下面来看看
-
深入mysql "ON DUPLICATE KEY UPDATE" 语法的分析
mysql "ON DUPLICATE KEY UPDATE" 语法如果在INSERT语句末尾指定了ON DUPLICATE KEY UPDATE,并且插入行后会导致在一个UNIQUE索引或PRIMARY KEY中出现重复值,则在出现重复值的行执行UPDATE:如果不会导致唯一值列重复的问题,则插入新行. 例如,如果列 a 为 主键 或 拥有UNIQUE索引,并且包含值1,则以下两个语句具有相同的效果: 复制代码 代码如下: INSERT INTO TABLE (a,c) VALUES
-
MySQL的Replace into 与Insert into on duplicate key update真正的不同之处
看下面的例子吧: 1 Replace into ...1.1 录入原始数据mysql> use test;Database changedmysql> mysql> CREATE TABLE t1 SELECT 1 AS a, 'c3' AS b, 'c2' AS c;ALTER TABLE t1 CHANGE a a INT PRIMARY KEY AUTO_INCREMENT ;Query OK, 1 row affected (0.03 sec)Records: 1 Duplic
-
mysql ON DUPLICATE KEY UPDATE语句示例
MySQL 自4.1版以后开始支持INSERT - ON DUPLICATE KEY UPDATE语法,使得原本需要执行3条SQL语句(SELECT,INSERT,UPDATE),缩减为1条语句即可完成.例如ipstats表结构如下: 复制代码 代码如下: CREATE TABLE ipstats (ip VARCHAR(15) NOT NULL UNIQUE,clicks SMALLINT(5) UNSIGNED NOT NULL DEFAULT '0'); 原本需要执行3条SQL语句,如下:
-
Mysql中Insert into xxx on duplicate key update问题
例如,如果列a被定义为unique,并且值为1,则下列语句有同样的效果,也就是说一旦出入的记录中存在a=1的情况,直接更新c = c + 1,而不执行c = 3的操作. 复制代码 代码如下: insert into table(a, b, c) values (1, 2, 3) on duplicate key update c = c + 1;1 update table set c = c + 1 where a = 1; 另外值得一提的是,这个语句知识mysql中,而标准sql语句中是没有
-
mysql insert的几点操作(DELAYED,IGNORE,ON DUPLICATE KEY UPDATE )
INSERT语法 INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE] [INTO] tbl_name [(col_name,...)] VALUES ({expr | DEFAULT},...),(...),... [ ON DUPLICATE KEY UPDATE col_name=expr, ... ] 或: INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE] [INT
-
mysql 中 replace into 与 insert into on duplicate key update 的用法和不同点实例分析
本文实例讲述了mysql 中 replace into 与 insert into on duplicate key update 的用法和不同点.分享给大家供大家参考,具体如下: replace into和insert into on duplicate key update都是为了解决我们平时的一个问题 就是如果数据库中存在了该条记录,就更新记录中的数据,没有,则添加记录. 我们创建一个测试表test CREATE TABLE `test` ( `id` int(11) unsigned N
-
SQL语句中的ON DUPLICATE KEY UPDATE使用
目录 一:主键索引,唯一索引和普通索引的关系 主键索引 唯一索引: 普通索引: 二:ON DUPLICATE KEY UPDATE使用测试(MYSQL下的Innodb引擎) 1:ON DUPLICATE KEY UPDATE功能介绍: 2:ON DUPLICATE KEY UPDATE测试样例+总结: 总结: 一:主键索引,唯一索引和普通索引的关系 主键索引 主键索引是唯一索引的特殊类型. 数据库表通常有一列或列组合,其值用来唯一标识表中的每一行.该列称为表的主键. 在数据库关系图中为表定义一个
-
insert into … on duplicate key update / replace into 多行数据介绍
场景是这样的,我有KV型的表,建表语句如下: 复制代码 代码如下: CREATE TABLE `dkv` ( `k1` int(11) NOT NULL DEFAULT '0', `k2` int(11) NOT NULL DEFAULT '0', `val` varchar(30) DEFAULT NULL, PRIMARY KEY (`k1`,`k2`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 数据大概是这样的: +----+----+---