Golang Compare And Swap算法详细介绍
目录
- CAS算法(compare and swap)
- CAS是如何运行的
- Go中的CAS源码
- CAS的缺陷
CAS算法(compare and swap)
CAS算法涉及到三个操作数
- 需要读写的内存值V
- 进行比较的值A
- 拟写入的新值B
当且仅当 V 的值等于 A时,CAS通过原子方式用新值B来更新V的值,否则不会执行任何操作(比较和替换是一个原子操作)。一般情况下是一个自旋操作,即不断的重试。
CAS算法(Compare And Swap),是原子操作的一种, CAS算法是一种有名的无锁算法。无锁编程,即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程被阻塞的情况下实现变量的同步,所以也叫非阻塞同步(Non-blocking Synchronization)。可用于在多线程编程中实现不被打断的数据交换操作,从而避免多线程同时改写某一数据时由于执行顺序不确定性以及中断的不可预知性产生的数据不一致问题。
该操作通过将内存中的值与指定数据进行比较,当数值一样时将内存中的数据替换为新的值。
Go中的CAS操作是借用了CPU提供的原子性指令来实现。CAS操作修改共享变量时候不需要对共享变量加锁,而是通过类似乐观锁的方式进行检查,本质还是不断的占用CPU 资源换取加锁带来的开销(比如上下文切换开销)。
package main
import (
"fmt"
"sync"
"sync/atomic"
)
var (
counter int32 //计数器
wg sync.WaitGroup //信号量
)
func main() {
threadNum := 5
wg.Add(threadNum)
for i := 0; i < threadNum; i++ {
go incCounter(i)
}
wg.Wait()
}
func incCounter(index int) {
defer wg.Done()
spinNum := 0
for {
// 原子操作
old := counter
ok := atomic.CompareAndSwapInt32(&counter, old, old+1)
if ok {
break
} else {
spinNum++
}
}
fmt.Printf("thread,%d,spinnum,%d\n", index, spinNum)
}
当主函数main首先创建了5个信号量,然后开启五个线程执行incCounter方法,incCounter内部执行, 使用cas操作递增counter的值,atomic.CompareAndSwapInt32具有三个参数,第一个是变量的地址,第二个是变量当前值,第三个是要修改变量为多少,该函数如果发现传递的old值等于当前变量的值,则使用第三个变量替换变量的值并返回true,否则返回false。
这里之所以使用无限循环是因为在高并发下每个线程执行CAS并不是每次都成功,失败了的线程需要重写获取变量当前的值,然后重新执行CAS操作。读者可以把线程数改为10000或者更多就会发现输出thread,5329,spinnum,1其中这个1就说明该线程尝试了两个CAS操作,第二次才成功。
因此呢, go中CAS操作可以有效的减少使用锁所带来的开销,但是需要注意在高并发下这是使用cpu资源做交换的。
CAS是如何运行的
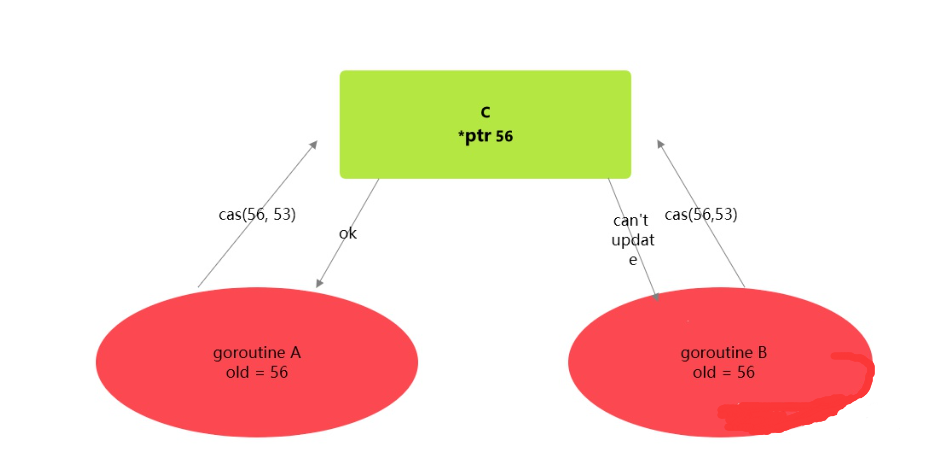
我们有两个goroutineA和goroutineB,接下来我们简称 A 和 B, 共享资源称为C
- A 和 B 均保存 C 当前的值
- A 尝试使用CAS(56,53)更新C的值
- C目前为56,可以更新,然后更新成功
- B尝试使用CAS(56,53)更新C的值
- C已经为53,更新失败
Go中的CAS源码
// CompareAndSwapUint32 executes the compare-and-swap operation for a uint32 value. func CompareAndSwapUint32(addr *uint32, old, new uint32) (swapped bool)
实际代码文件在
Go / src / runtime / internal / atomic / asm_amd.s文件中
TEXT runtime∕internal∕atomic·Cas64(SB), NOSPLIT, $0-25 MOVQ ptr+0(FP), BX MOVQ old+8(FP), AX MOVQ new+16(FP), CX LOCK CMPXCHGQ CX, 0(BX) SETEQ ret+24(FP) RET
其中我们可以看作
lock(一个命令前缀,在这里用于CMPXCHGQ)可以锁住总线保证多次内存操作的原子性。
然后执行CMPXCHGQ
cmpxchg %cx, %bx;如果AX与BX相等,则CX送BX且ZF置1;否则BX送CX,且ZF清0
- 拿AX(old) 与 BX(共享数据ptr) 做对比。
- 相等,则修改BX(共享数据ptr),状态码ZX设置为 1 。
- 不相等,则将CX(new)置为目前BX(共享数据ptr)的值, 状态码ZX设置为 0
CAS的缺陷
CAS在共享资源竞争比较激烈的时候,每个goroutine会容易处于自旋状态,影响效率,在竞争激烈的时候推荐使用锁。
无法解决ABA问题
ABA问题是无锁结构实现中常见的一种问题,可基本表述为:
进程P1读取了一个数值A
P1被挂起(时间片耗尽、中断等),进程P2开始执行
P2修改数值A为数值B,然后又修改回A
P1被唤醒,比较后发现数值A没有变化,程序继续执行。
到此这篇关于Golang Compare And Swap算法详细介绍的文章就介绍到这了,更多相关Golang CAS算法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
golang实现分页算法实例代码
前言 本文主要给大家介绍了关于golang分页算法的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧 示例代码如下: //分页方法,根据传递过来的页数,每页数,总数,返回分页的内容 7个页数 前 1,2,3,4,5 后 的格式返回,小于5页返回具体页数 func Paginator(page, prepage int, nums int64) map[string]interface{} { var firstpage int //前一页地址 var lastpage i
-
Golang实现拓扑排序(DFS算法版)
问题描述:有一串数字1到5,按照下面的关于顺序的要求,重新排列并打印出来.要求如下:2在5前出现,3在2前出现,4在1前出现,1在3前出现. 该问题是一个非常典型的拓扑排序的问题,一般解决拓扑排序的方案是采用DFS-深度优先算法,对于DFS算法我的浅薄理解就是递归,因拓扑排序问题本身会有一些前置条件(本文不过多介绍拓扑算法的定义),所以解决该问题就有了以下思路. 先将排序要求声明成map(把map的key,value看作对顺序的要求,key应在value前出现),然后遍历1-5这几个数,将每次遍
-
Golang Compare And Swap算法详细介绍
目录 CAS算法(compare and swap) CAS是如何运行的 Go中的CAS源码 CAS的缺陷 CAS算法(compare and swap) CAS算法涉及到三个操作数 需要读写的内存值V 进行比较的值A 拟写入的新值B 当且仅当 V 的值等于 A时,CAS通过原子方式用新值B来更新V的值,否则不会执行任何操作(比较和替换是一个原子操作).一般情况下是一个自旋操作,即不断的重试. CAS算法(Compare And Swap),是原子操作的一种, CAS算法是一种有名的无锁算法.无
-

golang RPC包原理和使用详细介绍
目录 工作流程 工作模式 http模式 服务器模式 本篇文章旨在通过学习rpc包和github上的一个rpc小项目,熟悉和学习golang中各个包的使用 工作流程 通过阅读官方文档,了解了rpc的基本工作模式 第一步,建立一个用于远程调用的包,存放仅供远程调用使用的方法和类型- 第二步,实例化包的对象,并在rpc中注册该包,以便之后的调用 第三步,建立一个服务端,接收客户端的请求,使用编码器解析请求后,根据请求中的方法和参数,调用第二步注册的实例的方法,然后使用编码器把返回值加密后,返回给客户端
-
Golang分布式锁详细介绍
目录 进程内加锁 trylock 基于redis的setnx 基于zk 基于etcd redlock 如何选择 在单机程序并发或并行修改全局变量时,需要对修改行为加锁以创造临界区.为什么需要加锁呢?可以看看下段代码: package main import ( "sync" ) // 全局变量 var counter int func main() { var wg sync.WaitGroup for i := 0; i < 1000; i++ { wg.Add(1) go f
-
Golang实现常见排序算法的示例代码
目录 前言 五种基础排序算法对比 1.冒泡排序 2.选择排序 3.插入排序 4.快速排序 前言 现在的面试真的是越来越卷了,算法已经成为了面试过程中必不可少的一个环节,你如果想进稍微好一点的公司,「算法是必不可少的一个环节」.那么如何学习算法呢?很多同学的第一反应肯定是去letcode上刷题,首先我并不反对刷题的方式,但是对于一个没有专门学习过算法的同学来说,刷题大部分是没什么思路的,花一个多小时暴力破解一道题意义也不大,事后看看别人比较好的解法大概率也记不住,所以我觉得「专门针对算法进行一些简
-
Java探索之Hibernate主键生成策略详细介绍
1.increment 由Hibernate从数据库中去除主键的最大值(每个session只取一次),以该值为基础,每次增量为1,在内存中生成主键,不依赖于底层的数据库,因此可以跨数据库. <id name="id" column="id"> <generator class="increment" /> </id> Hibernate调用org.hibernate.id.IncrementGenerator类
-
Java 对象序列化 NIO NIO2详细介绍及解析
Java 对象序列化 NIO NIO2详细介绍及解析 概要: 对象序列化 对象序列化机制允许把内存中的Java对象转换成与平台无关的二进制流,从而可以保存到磁盘或者进行网络传输,其它程序获得这个二进制流后可以将其恢复成原来的Java对象. 序列化机制可以使对象可以脱离程序的运行而对立存在 序列化的含义和意义 序列化 序列化机制可以使对象可以脱离程序的运行而对立存在 序列化(Serialize)指将一个java对象写入IO流中,与此对应的是,对象的反序列化(Deserialize)则指从IO流中恢
-
Linux启动过程详细介绍
Linux启动过程详细介绍 启动第一步--加载BIOS 当你打开计算机电源,计算机会首先加载BIOS信息,BIOS信息是如此的重要,以至于计算机必须在最开始就找到它.这是因为BIOS中包含了CPU的相关信息.设备启动顺序信息.硬盘信息.内存信息.时钟信息.PnP特性等等.在此之后,计算机心里就有谱了,知道应该去读取哪个硬件设备了. 启动第二步--读取MBR 众所周知,硬盘上第0磁道第一个扇区被称为MBR,也就是Master Boot Record,即主引导记录,它的大小是512字节,别看地方不大
-
C语言 strcpy和memcpy区别详细介绍
C语言 strcpy和memcpy区别详细介绍 PS:初学算法,开始刷leetcode,Rotate array的预备知识(写的代码Time Limit Exceed难过)于是百度高效算法,本篇作为预备知识. 1.strcpy和strncpy函数 这个不陌生,大一学C语言讲过,其一般形式为strcpy(字符数组1,字符串2)作用是将字符串2复制到字符数组1中去. EX: char str1[10]='',str2[]={"China"}; strcpy(str1,str2); strn
-
10个python3常用排序算法详细说明与实例(快速排序,冒泡排序,桶排序,基数排序,堆排序,希尔排序,归并排序,计数排序)
我简单的绘制了一下排序算法的分类,蓝色字体的排序算法是我们用python3实现的,也是比较常用的排序算法. Python3常用排序算法 1.Python3冒泡排序--交换类排序 冒泡排序(Bubble Sort)也是一种简单直观的排序算法. 它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来. 走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成.这个算法的名字由来是因为越小的元素会经由交换慢慢"浮"到数列的顶端. 作为最简单的排序算法
-
Go 实现热重启的详细介绍
最近在优化公司框架 trpc 时发现了一个热重启相关的问题,优化之余也总结沉淀下,对 go 如何实现热重启这方面的内容做一个简单的梳理. 1.什么是热重启? 热重启(Hot Restart),是一项保证服务可用性的手段.它允许服务重启期间,不中断已经建立的连接,老服务进程不再接受新连接请求,新连接请求将在新服务进程中受理.对于原服务进程中已经建立的连接,也可以将其设为读关闭,等待平滑处理完连接上的请求及连接空闲后再行退出.通过这种方式,可以保证已建立的连接不中断,连接上的事务(请求.处理.响应)