Flink时间和窗口逻辑处理源码分析
目录
- 概览
- 时间
- 重要类
- WatermarkStrategy
- WatermarkGenerator
- TimerService
- 处理逻辑
- 窗口
- 重要类
- Window
- WindowAssigner
- Triger
- Evictor
- WindowOperator
- InternalAppendingState
- 处理逻辑
- 总结
概览
- 计算模型
- DataStream基础框架
- 事件时间和窗口
- 部署&调度
- 存储体系
- 底层支撑
在实时计算处理时,需要跟时间来打交道,如实时风控场景的时间行为序列,实时分析场景下的时间窗口统计等。而由于网络等问题,会导致处理时的数据存在乱序问题,Flink通过吸收Google Dataflow/Bean的编程模型思想,提供了灵活的处理方式,本篇来分析下Flink中具体提供的功能和底层机制。
时间
Flink中提供了3种时间类型来满足不同场景的需求,即处理时间、事件时间和接入时间
- 处理时间(Processing time):数据在流式系统中处理时的机器系统时间
- 事件时间(Event time):每条单独的事件在产出设备上发生的时间,即事件实际发生的时间。这个时间保存在发送给Flink系统的数据记录中
- 接入时间(Ingestion time):Flink读取事件时的时间 下图是Flink官方文档中3个时间的标识
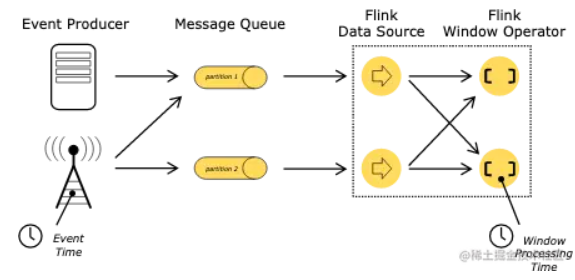
而在使用事件时间的场景下,需要一种方式来度量目前处理的事件时间,如使用事件时间窗口时,需要知道什么时候来关闭这个窗口,所以这里引入了Watermark的机制。 这里先介绍Watermark关联的3个概念
- WatermarkStrategy:org.apache.flink.table.sources.wmstrategies.WatermarkStrategy,定义怎么在DataStream中去生成Watermark的策略,其子类有定义了多种不同的策略
- WatermarkGenerator:具体生成Watermark的生成器类
- TimestampAssigner:从数据记录中提取时间戳
重要类
WatermarkStrategy
Flink中提供了一些常用的watermark策略,主要我们看看PeriodicWatermarkAssigner这个策略,周期性水位策略,其有2个子类
- BoundedOutOfOrderTimestamps:没有顺序的数据,指定对应的延迟来产生watermark,产生的watermark为获取的数据中的最大时间-指定的delay
- AscendingTimestamps:对于有顺序的数据使用,产生的watermark为获取的数据中最大的时间-1
WatermarkGenerator
WatermarkGenerator接口有2个方法
@Public
public interface WatermarkGenerator<T> {
/**
* 每来一条事件数据调用一次,可以检查或者记录事件的时间戳,或者也可以基于事件数据本身去生成 watermark。
*/
void onEvent(T event, long eventTimestamp, WatermarkOutput output);
/**
* 周期性的调用,也许会生成新的 watermark,也许不会。
*
* <p>调用此方法生成 watermark 的间隔时间由 {@link ExecutionConfig#getAutoWatermarkInterval()} 决定。
*/
void onPeriodicEmit(WatermarkOutput output);
}
watermark生成的方式分为2种:周期性生成和标记生成 周期性生成的通过onEvent()方法来更新最大时间戳,而在框架调用onPeriodicEmit()时发出watermark 标记生成通过onEvent()来处理,如果有满足条件的记录出现,就发出watermark
TimerService
如何获取当前的处理时间和watermark呢,这个在Flink中通过TimerService来负责,下面先看看这个接口的相关方法
//返回当前处理时间
/** Returns the current processing time. */
long currentProcessingTime();
//返回当前事件时间watermark
/** Returns the current event-time watermark. */
long currentWatermark();
//注册一个timer,当事件时间水位超过给定时间时触发
void registerEventTimeTimer(long time);
上面介绍了时间和watermark相关的重要类,下面通过一个例子把这些串联起来,看其是如何来运转的
处理逻辑
我们以Flink官方文档中的watermark代码例子结合来介绍
WatermarkStrategy<Event> strategy = WatermarkStrategy
.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(20))
.withTimestampAssigner((event, timestamp) -> event.timestamp);
DataStream<Event> withTimestampsAndWatermarks =
stream.assignTimestampsAndWatermarks(strategy);
这里通过WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(20))生成了一个延迟为20秒的有界限的watermark策略,然后指定了TimestampAssigner为时间戳为事件的timestamp字段。 stream.assignTimestampsAndWatermarks方法返回的是一个DataStream,通过第一篇的介绍,这里对应有一个Transformation(TimestampsAndWatermarksTransformation),同时也对应有一个StreamOperator(TimestampsAndWatermarksOperator, 注意这个是在Translator(TimestampsAndWatermarksTransformationTranslator)中定义的),我们看看具体的watermark在TimestampsAndWatermarksOperator中的处理逻辑如何
public void open() throws Exception {
super.open();
timestampAssigner = watermarkStrategy.createTimestampAssigner(this::getMetricGroup);
// 创建watermarkGenerator
watermarkGenerator =
emitProgressiveWatermarks
? watermarkStrategy.createWatermarkGenerator(this::getMetricGroup)
: new NoWatermarksGenerator<>();
wmOutput = new WatermarkEmitter(output);
//获取周期性watermark的调度周期
watermarkInterval = getExecutionConfig().getAutoWatermarkInterval();
if (watermarkInterval > 0 && emitProgressiveWatermarks) {
final long now = getProcessingTimeService().getCurrentProcessingTime();
// 获取timerService 注册Timer
getProcessingTimeService().registerTimer(now + watermarkInterval, this);
}
}
在StreamOperator的前处理方法中,创建了WatermarkGenerator,然后获取watermark触发周期,注册到TimerService里面 后续再StreamOperator的每条数据处理方法中(processElement)调用了
watermarkGenerator.onEvent(event, newTimestamp, wmOutput);
这里实际会更新最大事件时间戳 而前面注册Timer时会传入一个ProcessingTimeCallback对象,该接口有个onProcessingTime方法,而TimestampsAndWatermarksOperator实现了该接口
// ProcessingTimeCallback.java ScheduledFuture<?> registerTimer(long timestamp, ProcessingTimeCallback target);
//TimestampsAndWatermarksOperator.java
@Override
public void onProcessingTime(long timestamp) throws Exception {
// 发送watermark
watermarkGenerator.onPeriodicEmit(wmOutput);
// 更新下次触发时间
final long now = getProcessingTimeService().getCurrentProcessingTime();
getProcessingTimeService().registerTimer(now + watermarkInterval, this);
}
这里通过回调,触发发送watermark和再次注册下一个调度时间点,而下游算子收到了watermark如何处理呢,如在window算子里面,回去更新算子里面TimerService的currentWatermark,这样如果新数据小于当前watermark那就会丢掉或按siteOutput处理,具体我们再分析窗口时再介绍。
窗口
在实际场景中有很多对一段时间的数据来进行处理的需求,Flink中提供了不同种类的窗口来支持
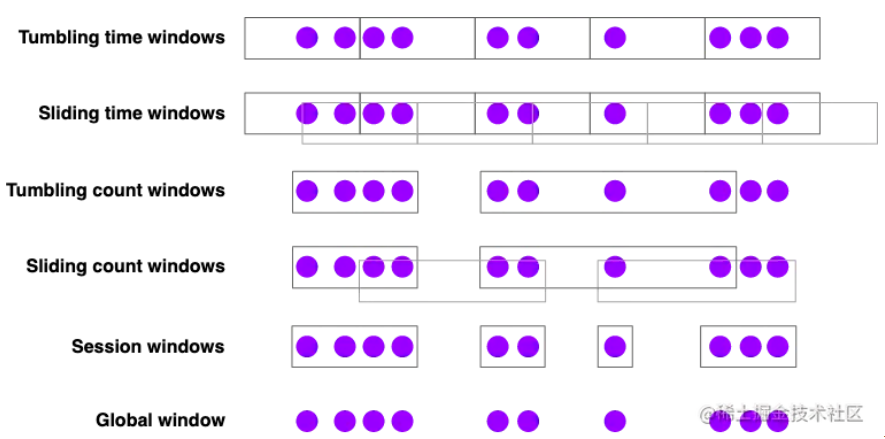
具体的类型有
- 滚动窗口:按固定的区间划分,各个之间不重叠,如近1分钟的页面访问量
- 滑动窗口:按固定区间划分,但窗口间会存在重叠,如每10秒计算近1分钟的页面访问量
- 会话窗口:超过一段时间该窗口没有数据则视为该窗口结束
重要类
Window
定义了窗口的类型,目前有2个子类TimeWindow和GlobalWindow。TimeWindow指一个时间区间的,指定了开始时间(含)和结束时间(不含); GlobalWindow指一个单独的窗口,包括所有的数据
WindowAssigner
分配哪些窗口给输入的元素,按照不同的窗口类型和时间类型有不同的分配方式的子类。
- SlidingProcessingTimeWindows
- SlidingEventTimeWindows
- TumblingEventTimeWindows
- TumblingProcessingTimeWindows
- GlobalWindows 另外在session Window场景会涉及到window的合并,这里有一类单独的MergingWindowAssigner类来实现
Triger
用于确定每片窗口什么时候进行计算或清理,如有按时间、数量等方式。Triger后有如下几种结果(定义在TriggerResult中)
//不做任何操作
CONTINUE(false, false),
/** {@code FIRE_AND_PURGE} evaluates the window function and emits the window result. */
//执行窗口函数并发送结果,然后清除窗口
FIRE_AND_PURGE(true, true),
/**
* On {@code FIRE}, the window is evaluated and results are emitted. The window is not purged,
* though, all elements are retained.
*/
//执行窗口函数并发送结果,但窗口不清除
FIRE(true, false),
/**
* All elements in the window are cleared and the window is discarded, without evaluating the
* window function or emitting any elements.
*/
//直接清理数据和丢弃窗口
PURGE(false, true);
Evictor
用于在Triger触发后,在执行WindowFunction前,按指定条件移除一些数据,如TimeEvictor,移除指定时间之前的数据
WindowOperator
针对window的处理的StreamOperator,还有一个子类EvictingWindowOperator。针对每条数据的具体处理逻辑都在该类中处理,后面我们单独展开来介绍
InternalAppendingState
在窗口数据没有被触发时,这些数据需要有个地方进行保存。该类来保存相关的数据信息(针对滑动和滚动窗口的,session窗口的处理比较复杂有其他的类来处理),InternalAppendingState类是InternalKvState的子类,这里的key是对应的窗口,这里还有比较多的优化和细节,这块我们下篇介绍状态时来深入分析
处理逻辑
下面我们深入来了解下具体的处理流程,见下图
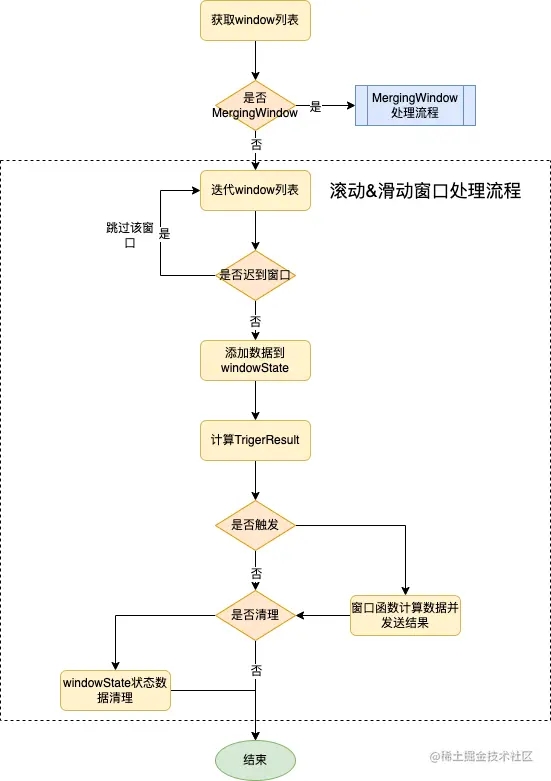
WindowOperator对数据的处理流程分为如下几个步骤
- 对传入的数据获取其对应的窗口列表
- 对获取的窗口列表进行迭代处理,判断是否迟到的窗口,如果是迟到的就直接下一个
- 把数据插入到windowState中
- 计算看是否会触发Triger,如果结果为FIRE,那就对窗口数据进行计算并发送出来;如果结果为需要清理,就清理对应的windowState. session window的处理流程与此类似,只是在前面会判断窗口是否需要做合并,如果需要会进行合并处理
实现细节注意 1.key在多窗口复制,如果是滑动窗口,那一个key会同时命中多个窗口,那这里的处理模式是把该key的值存放到多个窗口的状态中
总结
Flink中通过多时间语义和watermark,提供了灵活的方式处理时效性、准确性和成本之间的关系。本篇深入介绍了相关的机制信息。另介绍了窗口相关内容,窗口把要处理的数据做了个缓存,直到满足条件了才触发进行计算和发送到下游。这里的缓存需要使用到Flink的状态的机制,这个我们下一篇来介绍。最后附录提供了2篇讲流式处理的经典文章
附录
Streaming 101: The world beyond batch
Streaming 102:The world beyond batch
以上就是Flink时间和窗口逻辑处理源码分析的详细内容,更多关于Flink 时间窗口的资料请关注我们其它相关文章!
相关推荐
-
Flink DataStream基础框架源码分析
目录 引言 概览 深入DataStream DataStream 属性和方法 类体系 Transformation 属性和方法 类体系 StreamOperator 属性和方法 类体系 Function DataStream生成提交执行的Graph StreamGraph 属性和方法 StreamGraph生成 JobGraph 属性和方法 总结 引言 希望通过对Flink底层源码的学习来更深入了解Flink的相关实现逻辑.这里新开一个Flink源码解析的系列来深入介绍底层源码逻辑.说明:这里默
-
Flink状态和容错源码解析
目录 引言 概述 State Keyed State 状态实例管理及数据存储 HeapKeyedStateBackend RocksDBKeyedStateBackend OperatorState 上层封装 总结 引言 计算模型 DataStream基础框架 事件时间和窗口 状态和容错 部署&调度 存储体系 底层支撑 Flink中提供了State(状态)这个概念来保存中间计算结果和缓存数据,按照不同的场景,Flink提供了多种不同类型的State,同时为了实现Exactly once的语义,F
-
Flink作业Task运行源码解析
目录 引言 概览 调度框架 JobMaster ScheduleNG TaskExecutor Task 计算框架 算子计算处理 总结 引言 上一篇我们分析了Flink部署集群的过程和作业提交的方式,本篇我们来分析下,具体作业是如何被调度和计算的.具体分为2个部分来介绍 作业运行的整体框架,对相关的重要角色有深入了解 计算流程,重点是如何调度具体的operator机制 概览 首先我们来了解下整体的框架 JobMaster: 计算框架的主节点,负责运行单个JobGraph,包括任务的调度,资源申请
-
详解Flink同步Kafka数据到ClickHouse分布式表
目录 引言 什么是ClickHouse? 创建复制表 通过jdbc写入 引言 业务需要一种OLAP引擎,可以做到实时写入存储和查询计算功能,提供高效.稳健的实时数据服务,最终决定ClickHouse 什么是ClickHouse? ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS). 列式数据库更适合于OLAP场景(对于大多数查询而言,处理速度至少提高了100倍),下面详细解释了原因(通过图片更有利于直观理解),图片来源于ClickHouse中文官方文档. 行式 列
-
Flink JobGraph生成源码解析
目录 引言 概念 JobGraph生成 生成hash值 生成chain 总结 引言 在DataStream基础中,由于其中的内容较多,只是介绍了JobGraph的结果,而没有涉及到StreamGraph到JobGraph的转换过程.本篇我们来介绍下JobGraph的生成的详情,重点是Operator可以串联成Chain的条件 概念 首先我们来回顾下JobGraph中的相关概念 JobVertex:job的顶点,即对应的计算逻辑(这里用的是Vertex, 而前面用的是Node,有点差异),通过in
-
Flink部署集群整体架构源码分析
目录 概览 部署模式 Application mode 客户端提交请求 服务端启动&提交Application session mode Cluster架构 Cluster的启动流程 DispatcherResourceManagerComponent Runner代码 HA代码框架 总结 概览 本篇我们来了解Flink的部署模式和Flink集群的整体架构 部署模式 Flink支持如下三种运行模式 运行模式 描述 Application Mode Flink Cluster只执行提交的整个job
-

Apache Hudi结合Flink的亿级数据入湖实践解析
目录 1. 实时数据落地需求演进 2. 基于Spark+Hudi的实时数据落地应用实践 3. 基于Flink自定义实时数据落地实践 4. 基于Flink + Hudi的落地数据实践 5. 后续应用规划及展望 5.1 取代离线报表,提高报表实时性及稳定性 5.2 完善监控体系,提升落数据任务稳定性 5.3 落数据中间过程可视化探索 本次分享分为5个部分介绍Apache Hudi的应用与实践 1. 实时数据落地需求演进 实时平台上线后,主要需求是开发实时报表,即抽取各类数据源做实时etl后,吐出实时
-
Flink时间和窗口逻辑处理源码分析
目录 概览 时间 重要类 WatermarkStrategy WatermarkGenerator TimerService 处理逻辑 窗口 重要类 Window WindowAssigner Triger Evictor WindowOperator InternalAppendingState 处理逻辑 总结 概览 计算模型 DataStream基础框架 事件时间和窗口 部署&调度 存储体系 底层支撑 在实时计算处理时,需要跟时间来打交道,如实时风控场景的时间行为序列,实时分析场景下的时间窗
-
Android ViewGroup事件分发和处理源码分析
目录 正文 处理ACTION_DOWN事件 检测是否截断事件 不截断ACTION_DOWN事件 寻找处理事件的子View 事件分发给子View ViewGroup自己处理ACTION_DOWN事件 处理ACTION_DOWN总结 处理ACTION_MOVE事件 检测是否截断ACTION_MOVE事件 不截断ACTION_MOVE 事件分发给mFirstTouchTarget.child 截断ACTION_MOVE 处理 ACTION_UP 和 ACTION_CANCEL 事件 正确地使用requ
-
浅谈ASP.NET Core静态文件处理源码探究
前言 静态文件(如 HTML.CSS.图像和 JavaScript)等是Web程序的重要组成部分.传统的ASP.NET项目一般都是部署在IIS上,IIS是一个功能非常强大的服务器平台,可以直接处理接收到的静态文件处理而不需要经过应用程序池处理,所以很多情况下对于静态文件的处理程序本身是无感知的.ASP.NET Core则不同,作为Server的Kestrel服务是宿主到程序上的,由宿主运行程序启动Server然后可以监听请求,所以通过程序我们直接可以处理静态文件相关.静态文件默认存储到项目的ww
-
spring-session简介及实现原理源码分析
一:spring-session介绍 1.简介 session一直都是我们做集群时需要解决的一个难题,过去我们可以从serlvet容器上解决,比如开源servlet容器-tomcat提供的tomcat-redis-session-manager.memcached-session-manager. 或者通过nginx之类的负载均衡做ip_hash,路由到特定的服务器上.. 但是这两种办法都存在弊端. spring-session是spring旗下的一个项目,把servlet容器实现的httpSe
-
java开发RocketMQ之NameServer路由管理源码分析
目录 1.前言 2.路由元信息 3.路由注册 3.1Broker路由注册 3.2NameServer处理路由注册 3.3路由删除 3.3.1Broker异常关闭 3.3.2Broker正常关闭 3.4路由发现 3.5总结 1.前言 NameServer主要作用是为消息消费者和消息生产者提供关于主题Topic的路由信息,那么NameServer需要存储路由的基本信息,还要管理Broker节点,包括路由注册.路由删除等. 2.路由元信息 路由元信息主要由RouteInfoManager来进行管理,这
-
vue parseHTML 函数拿到返回值后的处理源码解析
目录 引言 parseStartTag函数返回值 handleStartTag源码 tagName 及unarySlash 调用parser钩子函数 引言 继上篇文章: parseHTML 函数源码解析 var startTagMatch = parseStartTag(); if (startTagMatch) { handleStartTag(startTagMatch); if (shouldIgnoreFirstNewline(startTagMatch.tagName, html))
-
jdk动态代理源码分析过程
代理对象的生成方法是: Proxy.newProxyInstance(...) ,进入这个方法内部,一步一步往下走会发现会调用 ProxyGenerator.generateProxyClass() ,这个方法用来生成代理类的字节码. 下面通过调用 ProxyGenerator.generateProxyClass()方法在本地生成代理类. 1.首先要有一个接口 2.生成代理类的方法如下 3.将生成的代理类导入到idea中查看是长这样 // // Source code recreated fr
-
java 1.8 动态代理源码深度分析
JDK8动态代理源码分析 动态代理的基本使用就不详细介绍了: 例子: class proxyed implements pro{ @Override public void text() { System.err.println("本方法"); } } interface pro { void text(); } public class JavaProxy implements InvocationHandler { private Object source; public Jav