python浅拷贝与深拷贝使用方法详解
目录
- 一、对象赋值
- 二、浅拷贝
- 三、深拷贝
- 四、深入解析
浅拷贝和深拷贝在面试和日常的开发中都会经常遇到
我们就从 对象赋值、浅拷贝、深拷贝 三个方面来讲
一、对象赋值
In [1]: list1 = [1, 2, ['a', 'b']] list2 = list1 print(list1) print(list2) [1, 2, ['a', 'b']] [1, 2, ['a', 'b']] In [2]: list1[0] = 3 print(list1) print(list2) [3, 2, ['a', 'b']] [3, 2, ['a', 'b']] In [3]: list2[1]=[1,2] print(list1) print(list2) [3, [1, 2], ['a', 'b']] [3, [1, 2], ['a', 'b']] In [4]: print(id(list1)) print(id(list2)) 1742901832264 1742901832264
结论:直接对象赋值,两个对象的地址是一样的,也就是这两个变量指向是同一个对象,两个变量会同步变化
二、浅拷贝
In [5]:
import copy
A = [1, 'a', ['a', 'b']]
# B = A.copy() # 浅拷贝
B = copy.copy(A) # 浅拷贝
print(A)
print(B)
print(id(A))
print(id(B))
[1, 'a', ['a', 'b']]
[1, 'a', ['a', 'b']]
1742901926344
1742901925512
两个对象的内存地址不一样,也就是不是同一个对象
In [6]:
# 循环分别打印每个对象中的成员的地址
# 打印A
for i in A:
print("值 {} 的地址是:{}".format(i,id(i)))
值 1 的地址是:140724000563600
值 a 的地址是:1742860054320
值 ['a', 'b'] 的地址是:1742901889800
In [7]:
# 循环分别打印每个对象中的成员的地址
# 打印B
for i in B:
print("值 {} 的地址是:{}".format(i,id(i)))
值 1 的地址是:140724000563600
值 a 的地址是:1742860054320
值 ['a', 'b'] 的地址是:1742901889800
int类型的1和字符串型的a都是不可变数据类型,不可变数据类型值一样,地址一样,值不一样,地址就不一样
列表[‘a’, ‘b’]是可变数据类型,可变数据类型是 变量中数据变的时候,地址不会变,值相同的两个对象,地址是不一样的,如果地址一样,表示指的是同一个对象
现在 A[2] 和 B[2] 指向的是同一个地址,说明是同一个列表,一个改变,另外的一个也会同步改变
通常来讲不可变元素包含:
int,float,complex,long,str,unicode,tuple
In [8]: # 在 A[2] 中增加元素 A[2].append(3) print(A) print(B) [1, 'a', ['a', 'b', 3]] [1, 'a', ['a', 'b', 3]] In [9]: # 向A中增加元素 A.append(3) print(A) print(B) [1, 'a', ['a', 'b', 3], 3] [1, 'a', ['a', 'b', 3]] In [10]: A[0]=2 print(A) print(B) [2, 'a', ['a', 'b', 3], 3] [1, 'a', ['a', 'b', 3]]
浅拷贝(copy.copy()):拷贝父对象,不会拷贝对象的内部的子对象,也就是子对象共用
如果子对象是不可变数据类型,那么复制的对象和原来的对象互不影响
如果是可变数据类型,那么复制的对象和原来的对象共用
In [11]: A[2]=[1,2] print(A) print(B) [2, 'a', [1, 2], 3] [1, 'a', ['a', 'b', 3]] In [12]: print(id(A[2])) print(id(B[2])) 1742901889416 1742901889800
可以看到 现在 A[2] 和 B[2] 的地址不一样了,那么他们就互不影响了
其实看两个可变数据类型是否互相影响,就是看他们的地址是否一样
三、深拷贝
In [13]:
m = [1, 'a', ['a', 'b']]
n = copy.deepcopy(m)
print(m)
print(n)
print(id(m))
print(id(n))
[1, 'a', ['a', 'b']]
[1, 'a', ['a', 'b']]
1742900283720
1742900260680
In [14]:
# 循环分别打印每个对象中的成员的地址
# 打印m
for i in m:
print("值 {} 的地址是:{}".format(i,id(i)))
值 1 的地址是:140724000563600
值 a 的地址是:1742860054320
值 ['a', 'b'] 的地址是:1742900341320
In [15]:
# 循环分别打印每个对象中的成员的地址
# 打印n
for i in n:
print("值 {} 的地址是:{}".format(i,id(i)))
值 1 的地址是:140724000563600
值 a 的地址是:1742860054320
值 ['a', 'b'] 的地址是:1742900283208
可以看到,m和n两个对象本身的地址是不一样的,
并且m和n中成员中的可变数据类型的地址也是不一样的,所以它们两个是完全互不影响的
''' 学习中遇到问题没人解答?小编创建了一个Python学习交流群:711312441 寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书! ''' In [16]: m[2].append(3) n[1]=5 print(m) print(n) [1, 'a', ['a', 'b', 3]] [1, 5, ['a', 'b']]
浅拷贝(copy.copy()):拷贝父对象,不会拷贝对象的内部的子对象,也就是子对象共用
- 如果子对象是不可变数据类型,那么复制的对象和原来的对象互不影响
- 如果是可变数据类型,那么复制的对象和原来的对象共用
深拷贝(copy.deepcopy()):完全拷贝父对象跟子对象,复制的对象和原来的对象互不相关
四、深入解析
1、b = a.copy(): 浅拷贝, a 和 b 是一个独立的对象,但他们的子对象还是指向统一对象(是引用)。
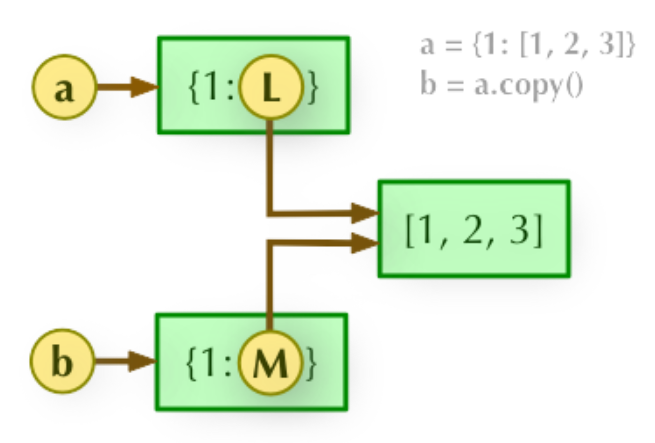
2、b = copy.deepcopy(a): 深度拷贝, a 和 b 完全拷贝了父对象及其子对象,两者是完全独立的。
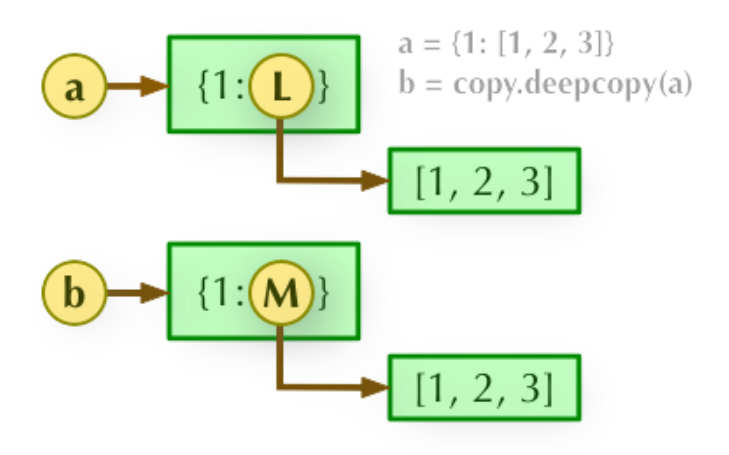
到此这篇关于python浅拷贝与深拷贝使用方法详解的文章就介绍到这了,更多相关python浅拷贝与深拷贝内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python详细讲解浅拷贝与深拷贝的使用
目录 1.变量的赋值操作 2.浅拷贝 3.深拷贝 4.总结 1.变量的赋值操作 只是多生成了一个变量,实际上还是指向同一个对象 # -*- coding: utf-8 -*- class CPU: pass class Disk: pass class Computer: def __init__(self, cpu, disk): # 给对象的实例属性进行初始化 self.cpu = cpu self.disk = disk # 变量的赋值 cp1 = Computer(cpu='CPU',
-
python 中赋值,深拷贝,浅拷贝的区别
目录 一.赋值实例 二.浅拷贝实例 三.深拷贝实例 赋值:其实就是对象的引用(相当于取别名). 浅拷贝(copy):拷贝父对象,不会拷贝对象内部的子对象,会引用子对象. 深拷贝(deepcopy): copy 模块的 deepcopy 方法,完全拷贝了父对象及其子对象. 一.赋值实例 # a这个大列表是一个父对象,里面的小列表是a的一个子对象 a = [1, 2, 3, ["a", "b"]] # 赋值实例 b = a print("a:", a
-
Python中深拷贝与浅拷贝的区别介绍
首先,我们知道 Python 中有6个标准的数据类型,他们又分为可以变和不可变.不可变:Number(数字).String(字符串).Tuple(元组).可以变:List(列表).Dictionary(字典).Set(集合). 浅拷贝 改变原始对象中为可变类型的元素的值,会同时影响拷贝对象.改变原始对象中为不可变类型的元素的值,不会响拷贝对象. 代码演示 import copy #定义一个列表,其中第一个元素是可变类型. list1 = [[1,2], 'fei', 66]; #进行浅copy
-
Python深拷贝浅拷贝图文示例清晰整理
python共有两种浅拷贝的方法,一个是python的内置函数copy(),另一个是copy模块中的copy.copy(). python的六种数据类型(数字.字符串.列表.元组.字典.集合)中,数字.字符串.元组这三个不可变类型是没有copy()这个属性的,但是可以用copy.copy()进行浅复制. 本文以copy模块中的copy()和deepcopy()来说说两者的区别. 如上图所示,浅拷贝只拷贝了父对象,不会拷贝里面的子对象.如果拷贝的数据改变了父对象中的值,是不会影响源数据中父对象的值
-
Python中Numpy的深拷贝和浅拷贝
目录 1. 引言 2. 浅拷贝 2.1 问题引入 2.2 问题剖析 3. 深拷贝 3.1 举个栗子 3.2 探究原因 4. 技巧总结 4.1 判断是否指向同一内存 4.2 其他数据类型 5. 总结 1. 引言 深拷贝和浅拷贝是Python中重要的概念,本文重点介绍在NumPy中深拷贝和浅拷贝相关操作的定义和背后的原理.闲话少说,我们直接开始吧! 2. 浅拷贝 2.1 问题引入 我们来举个栗子,如下所示我们有两个数组a和b,样例代码如下: import numpy as np a = np.arr
-
Python深拷贝与浅拷贝引用
目录 (1).存在父对象和子对象 (2).如果只存在父对象 前言: 在Python中,对象赋值在本质上是对对象的引用,当创建一个对象把它赋值给另一个变量的时候,Python并没有拷贝这个对象,而只是拷贝了这个对象的引用,这里通过程序,借用Python中的copy模块进一步理解深拷贝.浅拷贝和对象赋值有什么不同. 这里分两种情况: (1).存在父对象和子对象 演示代码如下: import copy #调用copy模块 Dict = {'animal':'cat','num':[10,20,30
-
Python可变与不可变数据和深拷贝与浅拷贝
目录 浅拷贝和深拷贝 什么是可变数据和不可变数据 那么拷贝函数是干什么的? 浅拷贝 深拷贝 总结 浅拷贝和深拷贝 拷贝函数是专门为可变数据类型list.set.dict使用的一种函数.作用是,当一个值指向另一个值的时候,也不会影响指向的值,如果被指向的数据是可变数据,那么它一旦被修改,指向的数据也会随之改变. 什么是可变数据和不可变数据 我们来举一个例子,整型是不可变的数据,那么为什么是不可变的数据呢?一个数据是不是可变的就要关系到python的缓存机制. 当一个数据发生变化,如果它的内存地址没
-
python浅拷贝与深拷贝使用方法详解
目录 一.对象赋值 二.浅拷贝 三.深拷贝 四.深入解析 浅拷贝和深拷贝在面试和日常的开发中都会经常遇到 我们就从 对象赋值.浅拷贝.深拷贝 三个方面来讲 一.对象赋值 In [1]: list1 = [1, 2, ['a', 'b']] list2 = list1 print(list1) print(list2) [1, 2, ['a', 'b']] [1, 2, ['a', 'b']] In [2]: list1[0] = 3 print(list1) print(list2) [3, 2
-
JS中实现浅拷贝和深拷贝的代码详解
(一)JS中基本类型和引用类型 JavaScript的变量中包含两种类型的值:基本类型值 和 引用类型值,在内存中的表现形式在于:前者是存储在栈中的一些简单的数据段,后者则是保存在堆内存中的一个对象. 基本类型值 在JavaScript中基本数据类型有 String , Number , Undefined , Null , Boolean ,在ES6中,又定义了一种新的基本数据类型 Symbol ,所以一共有6种. 基本类型是按值访问的,从一个变量复制基本类型的值到另一个变量后,这两个变量的值
-
C/C++ 浅拷贝和深拷贝的实例详解
C/C++ 浅拷贝和深拷贝的实例详解 深拷贝是指拷贝对象的具体内容,而内存地址是自主分配的,拷贝结束之后,两个对象虽然存的值是相同的,但是内存地址不一样,两个对象也互不影响,互不干涉. 浅拷贝就是对内存地址的复制,让目标对象指针和源对象指向同一片内存空间. 浅拷贝只是对对象的简单拷贝,让几个对象共用一片内存,当内存销毁的时候,指向这片内存的几个指针需要重新定义才可以使用,要不然会成为野指针. 在iOS开发中也会涉及到浅拷贝和深拷贝,简而言之: 浅拷贝:拷贝指针变量的值 深拷贝:拷贝指针所指向内存
-
Python对象类型及其运算方法(详解)
基本要点: 程序中储存的所有数据都是对象(可变对象:值可以修改 不可变对象:值不可修改) 每个对象都有一个身份.一个类型.一个值 例: >>> a1 = 'abc' >>> type(a1) str 创建一个字符串对象,其身份是指向它在内存中所处的指针(在内存中的位置) a1就是引用这个具体位置的名称 使用type()函数查看其类型 其值就是'abc' 自定义类型使用class 对象的类型用于描述对象的内部表示及其支持的方法和操作 创建特定类型的对象,也将该对象称为该类
-
Python 常用模块 re 使用方法详解
一.re模块的查找方法: 1.findall 匹配所有每一项都是列表中的一个元素 import re ret = re.findall('\d+','asd鲁班七号21313') # 正则表达式,待匹配的字符串,flag # ret = re.findall('\d','asd鲁班七号21313') # 正则表达式,待匹配的字符串,flag # print(ret) 2.search 只匹配从左到右的第一个,等到的不是直接的结果,而是一个变量,通过这个变量的group方法来获取结果 impo
-
在自动化中用python实现键盘操作的方法详解
原来在robotframework中使用press key方法进行键盘的操作,但是该方法需要写被操作对象的locator,不是很方便,现在找到了一种win32api库写键盘操作的一个方法(注意:此方法被操作界面必须在顶层),首先,需要安装win32api的python库,使用命令: pip install pywin32 具体实现代码如下: import win32api import win32con class MyLibrary(object): def keybd_event(self,
-
对Python实现累加函数的方法详解
这个需求比较奇怪,要求实现Sum和MagaSum函数,实现以下功能 Sum(1) =>1 Sum(1,2,3) =>6 MegaSum(1)() =>1 MegaSum(1)(2)(3)() =>6 实际上Sum就是Python自建的sum函数,它支持变参,变参怎么实现,自然是*args,所以很容易写出雏形: Sum def Sum(*args): count = 0 for i in args: count+=i return count 第二个函数就有点皮了,它要求有参数的时候
-
python对于requests的封装方法详解
由于requests是http类接口的核心,因此封装前考虑问题比较多: 1. 对多种接口类型的支持: 2. 连接异常时能够重连: 3. 并发处理的选择: 4. 使用方便,容易维护: 当前并未全部实现,后期会不断完善.重点提一下并发处理的选择:python的并发处理机制由于存在GIL的原因,实现起来并不是很理想,综合考虑多进程.多线程.协程,在不考虑大并发性能测试的前提下使用了多线程-线程池的形式实现.使用的是 concurrent.futures模块.当前仅方便支持webservice接口. #
-
对Python捕获控制台输出流的方法详解
有时候我们的代码里可能要调用控制台命令,比如我想用Python写一个批量编译 .java 文件的脚本,用到如下代码 常规用法 os.system import os,traceback try: p = os.system("javac Test.java") print p except: print "\nexcept:\n" print traceback.format_exc() 如然编译成功会返回一个0,如果错误会返回一个非0的值给p,这种方法可以知道执行
-
python文件处理fileinput使用方法详解
这篇文章主要介绍了python文件处理fileinput使用方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.介绍 fileinput模块可以对一个或多个文件中的内容进行迭代.遍历等操作,我们常用的open函数是对一个文件进行读写操作. fileinput模块的input()函数比open函数更高效和好用,体现在: input()函数生成一个迭代器,保证了在遇到大文件的读取时不会占用太大的内存. 用fileinput对文件进行循环遍历