python爬虫之百度API调用方法
调用百度API获取经纬度信息。
import requests
import json
address = input('请输入地点:')
par = {'address': address, 'key': 'cb649a25c1f81c1451adbeca73623251'}
url = 'http://restapi.amap.com/v3/geocode/geo'
res = requests.get(url, par)
json_data = json.loads(res.text)
geo = json_data['geocodes'][0]['location']
longitude = geo.split(',')[0]
latitude = geo.split(',')[1]
print(longitude,latitude)
其实调用API不难,这里是get方法,参数是地址和key,这个key是我在网上找的,应该是可以用的。
运行下代码。

然后糗事百科的地址处理后,调用API即可获得经纬度,然后利用个人BDP即可完成该图。
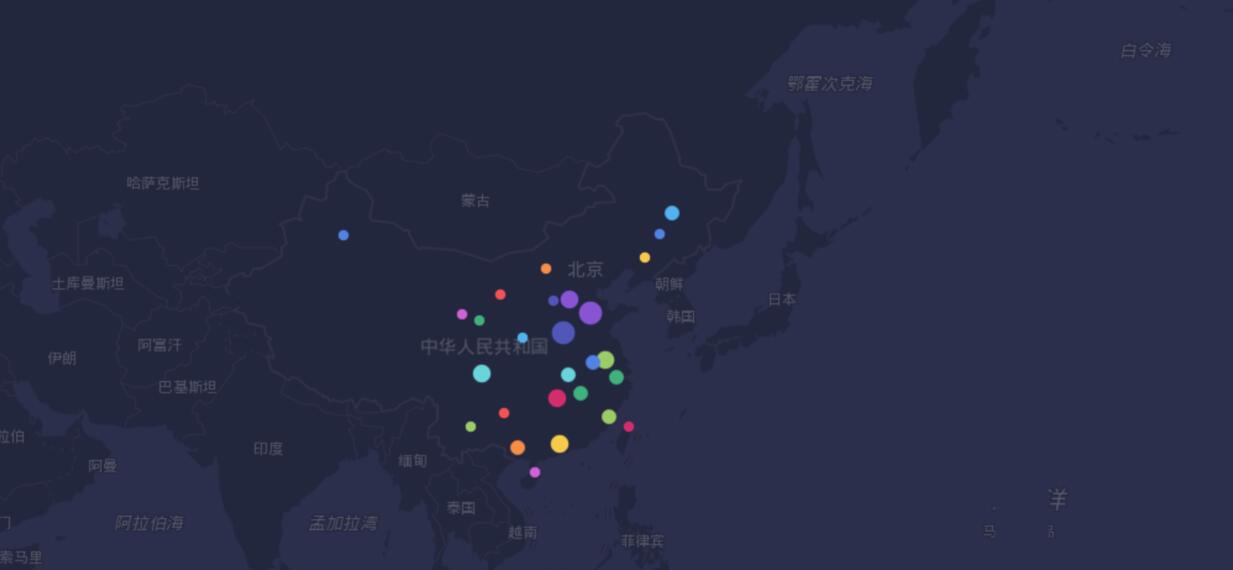
以上这篇python爬虫之百度API调用方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Python实现的异步代理爬虫及代理池
使用python asyncio实现了一个异步代理池,根据规则爬取代理网站上的免费代理,在验证其有效后存入redis中,定期扩展代理的数量并检验池中代理的有效性,移除失效的代理.同时用aiohttp实现了一个server,其他的程序可以通过访问相应的url来从代理池中获取代理. 源码 Github 环境 Python 3.5+ Redis PhantomJS(可选) Supervisord(可选) 因为代码中大量使用了asyncio的async和await语法,它们是在Python3.5中才提供
-
python爬虫框架talonspider简单介绍
1.为什么写这个? 一些简单的页面,无需用比较大的框架来进行爬取,自己纯手写又比较麻烦 因此针对这个需求写了talonspider: •1.针对单页面的item提取 - 具体介绍点这里 •2.spider模块 - 具体介绍点这里 2.介绍&&使用 2.1.item 这个模块是可以独立使用的,对于一些请求比较简单的网站(比如只需要get请求),单单只用这个模块就可以快速地编写出你想要的爬虫,比如(以下使用python3,python2见examples目录): 2.1.1.单页面单目标 比如
-
Python 爬虫图片简单实现
Python 爬虫图片简单实现 经常在逛知乎,有时候希望把一些问题的图片集中保存起来.于是就有了这个程序.这是一个非常简单的图片爬虫程序,只能爬取已经刷出来的部分的图片.由于对这一部分内容不太熟悉,所以只是简单说几句然后记录代码,不做过多的讲解.感兴趣的可以直接拿去用.亲测对于知乎等网站是可用的. 上一篇分享了通过url打开图片的方法,目的就是先看看爬取到的图片时什么样,然后再筛选一下保存. 这里用到了requests库来获取页面信息,需要注意的是,获取页面信息的时候需要一个header,用以把
-
python爬虫的工作原理
1.爬虫的工作原理 网络爬虫,即Web Spider,是一个很形象的名字.把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛.网络蜘蛛是通过网页的链接地址来寻找网页的.从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止.如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来.这样看来,网络爬虫就是一个爬行程序,一个抓取网页的程序
-
基于python爬虫数据处理(详解)
一.首先理解下面几个函数 设置变量 length()函数 char_length() replace() 函数 max() 函数 1.1.设置变量 set @变量名=值 set @address='中国-山东省-聊城市-莘县'; select @address 1.2 .length()函数 char_length()函数区别 select length('a') ,char_length('a') ,length('中') ,char_length('中') 1.3. replace() 函数
-
python爬虫实现教程转换成 PDF 电子书
写爬虫似乎没有比用 Python 更合适了,Python 社区提供的爬虫工具多得让你眼花缭乱,各种拿来就可以直接用的 library 分分钟就可以写出一个爬虫出来,今天就琢磨着写一个爬虫,将廖雪峰的 Python 教程 爬下来做成 PDF 电子书方便大家离线阅读. 开始写爬虫前,我们先来分析一下该网站1的页面结构,网页的左侧是教程的目录大纲,每个 URL 对应到右边的一篇文章,右侧上方是文章的标题,中间是文章的正文部分,正文内容是我们关心的重点,我们要爬的数据就是所有网页的正文部分,下方是用户的
-
python爬虫框架scrapy实战之爬取京东商城进阶篇
前言 之前的一篇文章已经讲过怎样获取链接,怎样获得参数了,详情请看python爬取京东商城普通篇,本文将详细介绍利用python爬虫框架scrapy如何爬取京东商城,下面话不多说了,来看看详细的介绍吧. 代码详解 1.首先应该构造请求,这里使用scrapy.Request,这个方法默认调用的是start_urls构造请求,如果要改变默认的请求,那么必须重载该方法,这个方法的返回值必须是一个可迭代的对象,一般是用yield返回. 代码如下: def start_requests(self): fo
-
Python的爬虫框架scrapy用21行代码写一个爬虫
开发说明 开发环境:Pycharm 2017.1(目前最新) 开发框架:Scrapy 1.3.3(目前最新) 目标 爬取线报网站,并把内容保存到items.json里 页面分析 根据上图我们可以发现内容都在类为post这个div里 下面放出post的代码 <div class="post"> <!-- baidu_tc block_begin: {"action": "DELETE"} --> <div class=
-
Python爬虫DNS解析缓存方法实例分析
本文实例讲述了Python爬虫DNS解析缓存方法.分享给大家供大家参考,具体如下: 前言: 这是Python爬虫中DNS解析缓存模块中的核心代码,是去年的代码了,现在放出来 有兴趣的可以看一下. 一般一个域名的DNS解析时间在10~60毫秒之间,这看起来是微不足道,但是对于大型一点的爬虫而言这就不容忽视了.例如我们要爬新浪微博,同个域名下的请求有1千万(这已经不算多的了),那么耗时在10~60万秒之间,一天才86400秒.也就是说单DNS解析这一项就用了好几天时间,此时加上DNS解析缓存,效果就
-
python爬虫之百度API调用方法
调用百度API获取经纬度信息. import requests import json address = input('请输入地点:') par = {'address': address, 'key': 'cb649a25c1f81c1451adbeca73623251'} url = 'http://restapi.amap.com/v3/geocode/geo' res = requests.get(url, par) json_data = json.loads(res.text) g
-
Python实现从百度API获取天气的方法
本文实例讲述了Python实现从百度API获取天气的方法.分享给大家供大家参考.具体实现方法如下: 复制代码 代码如下: __author__ = 'saint' import os import urllib.request import urllib.parse import json class weather(object): # 获取城市代码的uri code_uri = "http://apistore.baidu.com/microservice/cityinfo?
-
python爬虫获取百度首页内容教学
由传智播客教程整理,我们这里使用的是python2.7.x版本,就是2.7之后的版本,因为python3的改动略大,我们这里不用它.现在我们尝试一下url和网络爬虫配合的关系,爬浏览器首页信息. 1.首先我们创建一个urllib2_test01.py,然后输入以下代码: 2.最简单的获取一个url的信息代码居然只需要4行,执行写的python代码: 3.之后我们会看到一下的结果 4. 实际上,如果我们在浏览器上打开网页主页的话,右键选择"查看源代码",你会发现,跟我们刚打印出来的是一模
-
详解用Python爬虫获取百度企业信用中企业基本信息
一.背景 希望根据企业名称查询其经纬度,所在的省份.城市等信息.直接将企业名称传给百度地图提供的API,得到的经纬度是非常不准确的,因此希望获取企业完整的地理位置,这样传给API后结果会更加准确. 百度企业信用提供了企业基本信息查询的功能.希望通过Python爬虫获取企业基本信息.目前已基本实现了这一需求. 本文最后会提供具体的代码.代码仅供学习参考,希望不要恶意爬取数据! 二.分析 以苏宁为例.输入"江苏苏宁"后,查询结果如下: 经过分析,这里列示的企业信息是用JavaScript动
-
python爬虫中get和post方法介绍以及cookie作用
首先确定你要爬取的目标网站的表单提交方式,可以通过开发者工具看到.这里推荐使用chrome. 这里我用163邮箱为例 打开工具后再Network中,在Name选中想要了解的网站,右侧headers里的request method就是提交方式.status如果是200表示成功访问下面的有头信息,cookie是你登录之后产生的存储会话(session)信息的.第一次访问该网页需要提供用户名和密码,之后只需要在headers里提供cookie就可以登陆进去. 引入requests库,会提供get和po
-
python爬虫之BeautifulSoup 使用select方法详解
本文介绍了python爬虫之BeautifulSoup 使用select方法详解 ,分享给大家.具体如下: <html><head><title>The Dormouse's story</title></head> <body> <p class="title" name="dromouse"><b>The Dormouse's story</b></
-
python抓取百度首页的方法
本文实例讲述了python抓取百度首页的方法.分享给大家供大家参考.具体实现方法如下: import urllib def downURL(url,filename): try: fp=urllib.urlopen(url) except: print('download error') return 0 op=open(filename,'wb') while 1: s=fp.read() if not s: break op.write(s) fp.close() op.close() re
-
php有道翻译api调用方法实例
本文实例讲述了php有道翻译api调用方法,这里我们利用了file_get_contents函数直接读取由api返回的数据进行处理,分享给大家供大家参考.具体分析如下: 调用之前我们需申请一个有道翻译API数据接口的key,地址如: 复制代码 代码如下: http://fanyi.youdao.com/openapi?path=data-mode 方法说明,数据接口: 复制代码 代码如下: http://fanyi.youdao.com/openapi.do?keyfrom=<keyfrom>
-
Python爬虫设置代理IP的方法(爬虫技巧)
在学习Python爬虫的时候,经常会遇见所要爬取的网站采取了反爬取技术,高强度.高效率地爬取网页信息常常会给网站服务器带来巨大压力,所以同一个IP反复爬取同一个网页,就很可能被封,这里讲述一个爬虫技巧,设置代理IP. (一)配置环境 安装requests库 安装bs4库 安装lxml库 (二)代码展示 # IP地址取自国内髙匿代理IP网站:http://www.xicidaili.com/nn/ # 仅仅爬取首页IP地址就足够一般使用 from bs4 import BeautifulSoup
-
Python爬虫的两套解析方法和四种爬虫实现过程
对于大多数朋友而言,爬虫绝对是学习 python 的最好的起手和入门方式.因为爬虫思维模式固定,编程模式也相对简单,一般在细节处理上积累一些经验都可以成功入门.本文想针对某一网页对 python 基础爬虫的两大解析库( BeautifulSoup 和 lxml )和几种信息提取实现方法进行分析,以开 python 爬虫之初见. 基础爬虫的固定模式 笔者这里所谈的基础爬虫,指的是不需要处理像异步加载.验证码.代理等高阶爬虫技术的爬虫方法.一般而言,基础爬虫的两大请求库 urllib 和