Linux Shell+Curl网站健康状态检查脚本,抓出中国博客联盟失联站点
一开始搭建中国博客联盟,既有博友提醒我,做网址大全这类网站维护很麻烦,需要大量的精力去Debug一些已夭折的网站,更是拿松哥的博客大全举例。当然,我也是深以为然。前些时间,看到梦轩丽人的boke123网址大全的维护记录,好像是纯手工检查,张戈实在是佩服的五体投地,太有毅力了。
现在博客联盟也收录的博客也已破200了,全部来自自主提交,不管你是草博还是名博,张戈不会强买强卖。由于大部分都是建站不过半年的新站,半路放弃、提前太监的博客估计还是有的,于是我决定还是把站点维护这个工作做起来。
上午用PHP做了一个放到了京东云试了下,发现检测速度一般,要等上半天(我写的php太蹩脚,就不献丑了)。
随后,我在VPS上写了一个多线程的网站状态检测脚本,直接从数据库load站点地址,然后用curl去检测返回码,发现速度非常好,基本1分钟内就能出结果
以下是脚本代码:
#!/bin/bash
#Author:ZhangGe
#Date:2014-08-21
#Desc:Check the site of ZGboke Alliance.
#取出网站数据
data=`/usr/bin/mysql -uroot -p123456 -e "use zgboke;select web_url from dir_websites where web_status='3';" -N -B | awk '{print $1}'`
if [ -z "$data" ];then
echo "Faild to connect database!"
exit 1
fi
test -f result.log && rm -f result.log
function delay {
sleep 3
}
tmp_fifofile=/tmp/$$.fifo
mkfifo $tmp_fifofile
exec 6<>$tmp_fifofile
rm $tmp_fifofile
#定义并发线程数,需根据vps配置进行调整。
thread=100
for ((i=0 ;i<$thread;i++ ))
do
echo
done>&6
#开始多线程循环检测
for url in $data
do
read -u6
{
#curl抓取网站http状态码
code=`curl -o /dev/null --retry 3 --retry-max-time 8 -s -w %{http_code} $url`
echo "$code ---> $url">>result.log
#判断子线程是否执行成功,并输出结果
delay &|| {
echo "Check thread error!"
}
echo >& 6
}&
done
#等待所有线程执行完毕
wait
exec 6>&-
#找出非200返回码的站点
echo List of exception website:
cat result.log | grep -v 200
exit 0
Ps:关于shell多线程脚本,后续文章会有一个详细说明,本文篇幅有限,就不多说了。
以下是中国博客联盟第一次成员站点存活检测的结果:
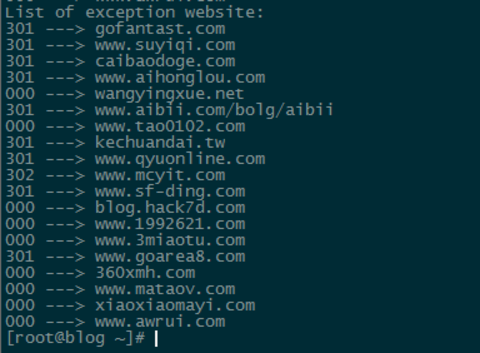
①、 非200返回码的异常站点:
②、脚本抓取的无法访问站点:
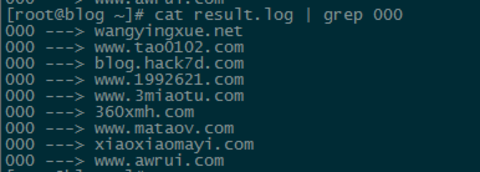
人工访问筛选结果:
wangyingxue.net(王英学博客):无法访问,经确认处于备案中 √
www.tao0102.com(长江博客):可以访问 √
blog.hack7d.com(Mcdull技术博客):无法访问 ×
www.1992621.com(教师日记):可以访问 √
www.3miaotu.com(三秒兔):无法访问 ×
xiaoxiaomayi.com(小小蚂蚁博客):可以访问 √
www.awrui.com(李文栋博客):可以访问 √
Ps:脚本检测机制为:8s内未连通的判定为异常,并重试3次,最后输出结果,若三次均异常则为000。从图中和人工筛选可以看出,存在一些误杀,这个和8s的设定有一定关系。可以考虑设置为更长时间,得到更准确的结果,当然最终还是要结合人工确认的,所以也没多大关系。
后续,中国博客联盟会制订一个检查周期,最短每星期检查一次,最长一个月检查一次,争取让每个展示的站点都能正常访问。当然,我也会将每次检查的结果公布在中国博客联盟的站长资讯专栏,方便所有成员查看。
由于目前中国博客联盟部署在京东云擎,无法远程操控数据库,所以只好暂时用半自动的模式。等以后有时间搬到了阿里云等VPS上后,将会将脚本改成全自动状态,当有网站联系多次检测为失联状态时,将会暂时将其设置为隐藏状态。
相关推荐
-
linux curl命令详解及实例分享
linux curl是一个利用URL规则在命令行下工作的文件传输工具.它支持文件的上传和下载,所以是综合传输工具,但按传统,习惯称url为下载工具. 一,curl命令参数,有好多我没有用过,也不知道翻译的对不对,如果有误的地方,还请指正. -a/--append 上传文件时,附加到目标文件 -A/--user-agent <string> 设置用户代理发送给服务器 - anyauth 可以使用"任何"身份验证方法 -b/--cookie <name=string
-
linux下为php添加curl扩展的方法
步骤如下: 1. 进到对应扩展目录 # cd /usr/local/src/php-5.2.12/ext/curl 2. 调用phpize程序生成编译配置文件 # /usr/local/php5/bin/phpize 3. 调用configure生成Makefile文件,然后调用make编译,make install安装 # ./configure -with-curl=/usr/local/curl -with-php-config=/usr/local/php5/bin/php-config
-
linux命令行下使用curl命令查看自己机器的外网ip
Linux命令行下如何查看自己机器的外网ip?可以在命令行下使用curl命令实现这个功能,试一下下面的命令吧 复制代码 代码如下: curl ifconfig.me 输入此条命令,就可以获取到本机的外网ip.
-
Linux 中 CURL常用命令详解
下载单个文件,默认将输出打印到标准输出中(STDOUT)中 curl http://www.centos.org 通过-o/-O选项保存下载的文件到指定的文件中: -o:将文件保存为命令行中指定的文件名的文件中 -O:使用URL中默认的文件名保存文件到本地 # 将文件下载到本地并命名为mygettext.html curl -o mygettext.html http://www.gnu.org/software/gettext/manual/gettext.html # 将文件保存到本地并命名
-
Linux中curl命令和wget命令的使用介绍与比较
本文介绍的是Linux中curl命令和wget命令,这两者都是用来下载文件的工具,下面来看看详细的介绍: 一.wget wget是linux最常用的下载命令, 一般的使用方法是: wget + 空格 + 要下载文件的url路径 例1: wget http://www.minjieren.com/wordpress-3.1-zh_CN.zip 下载文件保存到当前目录,文件名默认是url最后一个/后面的内容,这里就是 wordpress-3.1-zh_CN.zip 例2: wget -O myfil
-
Linux下命令行cURL的10种常见用法示例
前言 在Linux中curl是一个利用URL规则在命令行下工作的文件传输工具,可以说是一款很强大的http命令行工具.它支持文件的上传和下载,是综合传输工具,但按传统,习惯称url为下载工具. 语法: # curl [option] [url] 本文主要跟大家分享了Linux命令行cURL的10种常见用法,分享出来供大家参考学习,下面来一起看看详细的介绍: 1. 获取页面内容 当我们不加任何选项使用 curl 时,默认会发送 GET 请求来获取链接内容到标准输出. curl http://www
-
Linux下模拟http的get/post请求(curl or wget)详解
Linux下模拟http的get/post请求(curl or wget)详解 背景 最近项目中需要测试接口,但是测试服务器通过堡垒机才能访问,暂时又没有通过Nginx进行转发,只好直接在Linux上模拟http请求进行测试. 方法 get请求 curl "http://www.baidu.com" 如果URL指向的是一个文件或者一幅图可以直接下载到本地 curl -i "http://www.baidu.com" 显示全部信息 curl -l "http
-
Linux中的curl命令详解
语法 # curl [option] [url] 常见参数: -A/--user-agent <string> 设置用户代理发送给服务器 -b/--cookie <name=string/file> cookie字符串或文件读取位置 -c/--cookie-jar <file> 操作结束后把cookie写入到这个文件中 -C/--continue-at <offset> 断点续转 -D/--dump-header <file> 把header信息
-

Linux Shell+Curl网站健康状态检查脚本,抓出中国博客联盟失联站点
一开始搭建中国博客联盟,既有博友提醒我,做网址大全这类网站维护很麻烦,需要大量的精力去Debug一些已夭折的网站,更是拿松哥的博客大全举例.当然,我也是深以为然.前些时间,看到梦轩丽人的boke123网址大全的维护记录,好像是纯手工检查,张戈实在是佩服的五体投地,太有毅力了. 现在博客联盟也收录的博客也已破200了,全部来自自主提交,不管你是草博还是名博,张戈不会强买强卖.由于大部分都是建站不过半年的新站,半路放弃.提前太监的博客估计还是有的,于是我决定还是把站点维护这个工作做起来. 上午用PH
-
Shell+Curl网站状态检查脚本 抓出无法访问的站点
一开始搭建中国博客联盟,既有博友提醒我,做网址大全这类网站维护很麻烦,需要大量的精力去Debug一些已夭折的网站,更是拿松哥的博客大全举例.当然,我也是深以为然.前些时间,看到梦轩丽人的boke123网址大全的维护记录,好像是纯手工检查,张戈实在是佩服的五体投地,太有毅力了. 现在博客联盟也收录的博客也已破200了,全部来自自主提交,不管你是草博还是名博,张戈不会强买强卖.由于大部分都是建站不过半年的新站,半路放弃.提前太监的博客估计还是有的,于是我决定还是把站点维护这个工作做起来. 上午用PH
-
Linux Shell中curl和wget使用代理IP的方法教程
前言 大家都知道,在Linux Shell中提供两个非常实用的命令来爬取网页,它们分别是 curl 和 wget,本文将给大家详细介绍关于在Linux Shell中curl和wget使用代理IP的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看吧. curl 和 wget 使用代理 curl 支持 http.https.socks4.socks5 wget 支持 http.https 代理示例: #!/bin/bash # # curl 支持 http.https.socks4.so
-
使用Linux shell脚本实现FTP定时执行批量下载指定文件
使用FTP定时批量下载指定文件的shell脚本,具体实例介绍如下所示: 1.目标FTP服务器地址 #FTP服务器地址 ip=10.19.15.23 2.FTP账号和密码 u=账号 p=密码 3.使用mget结合正则表达式下载文件 #获取昨天日期,为后面下载使用 T=`date -d yesterday +%Y%m%d` 4.连接FTP服务器,到指定路径下下载文件 ftp -n <<EOF open $ip user $u $p binary cd /hour #远程服务器文件目录 lcd /h
-
Linux shell脚本输出日志笔记整理(必看篇)
1.日志方法简介: #日志名称 log="./upgrade.log" #操作日志存放路径 fsize=2000000 #如果日志大小超过上限,则保存旧日志,重新生成日志文件 exec 2>>$log #如果执行过程中有错误信息均输出到日志文件中 #日志函数 #参数 #参数一,级别,INFO ,WARN,ERROR #参数二,内容 #返回值 function zc_log() { #判断格式 if [ 2 -gt $# ] then echo "parameter
-
如何调试Linux shell脚本
shell也有一个真实的调试模式.如果在脚本"strangescript" 中有错误,您可以这样来进行调试: sh -x strangescript 这将执行该脚本并显示所有变量的值. shell还有一个不需要执行脚本只是检查语法的模式.可以这样使用: sh -n your_script 这将返回所有语法错误. linux/unix shell l脚本调试方法 Shell提供了一些用于调试脚本的选项,如下所示: -n 读一遍脚本中的命令但不执行,用于检查脚本中的语法错误 -v 一边执行
-
Linux Shell脚本实现检测tomcat
Linux Shell脚本检测tomcat并自动重启 后台运行命令 sh xxx.sh & 查看后台任务:jobs 召唤到前台:fg jobs编号 可以删掉while循环的代码放到crontab里面定时执行,可以将脚本直接后台运行, #!/bin/bash while [ true ] do url="http://www.jb51.net/"; httpOK=`curl --connect-timeout 10 -m 60 --head --silent $url | awk
-
Linux shell脚本全面学习入门
1. Linux 脚本编写基础 1.1 语法基本介绍 1.1.1 开头 程序必须以下面的行开始(必须方在文件的第一行): #!/bin/sh 符号#!用来告诉系统它后面的参数是用来执行该文件的程序.在这个例子中我们使用/bin/sh来执行程序. 当编辑好脚本时,如果要执行该脚本,还必须使其可执行. 要使脚本可执行: 编译 chmod +x filename 这样才能用./filename 来运行 1.1.2 注释 在进行shell编程时,以#开头的句子表示注释,直到这一行的结束.我们真诚地建议您
-
Linux Shell脚本的编程之正则表达式
一 正则表达式与通配符 1 正则表达式是用在文件中匹配符合条件的字符串,正则是包含匹配,grep,awk,sed等命令可以支持正则表达式 2 通配符是用来匹配符合条件的文件名,通配符是完全匹配,ls,find,cp这些命令不支持正则表达式,所以只能用Shell自己的通配符来进行匹配了. 二 基础正则表达式 这里引用兄弟连的测试文本 1 * 前一个字符匹配0次或任意多次 grep "a*" test_rule.txt 匹配所有内容,包括空白行(由于*可以匹配0次) grep "
-
Linux Shell脚本系列教程(一):Shell入门
一.Shell简介 诸多类Unix操作系统的设计令人惊叹.即便是在数十年后的今天,Unix式的操作系统架构仍是有史以来最佳的设计之一.这种架构最重要的一个特性就是命令行界面或者shell.shell环境使得用户能与操作系统的核心功能进行交互.术语脚本更多涉及的便是这种环境.编写脚本通常使用某种基于解释器的编程语言.shell脚本本质上就是一些文本文件,我们可以将一系列需要执行的命令写入其中,然后通过shell来执行. 在这里我们介绍的是Bash shell(Bourne Again Shell)