sqlserver数据库优化解析(图文剖析)
下面通过图文并茂的方式展示如下:
一、SQL Profiler
事件类 Stored Procedures\RPC:Completed TSQL\SQL:BatchCompleted
事件关键字段 EventSequence、EventClass、SPID、DatabaseName、Error、StartTime、TextData、 HostName、ClientProcessID、ApplicationName、 CPU、Reads、Writes、Duration、RowCounts
1、跟踪慢SQL 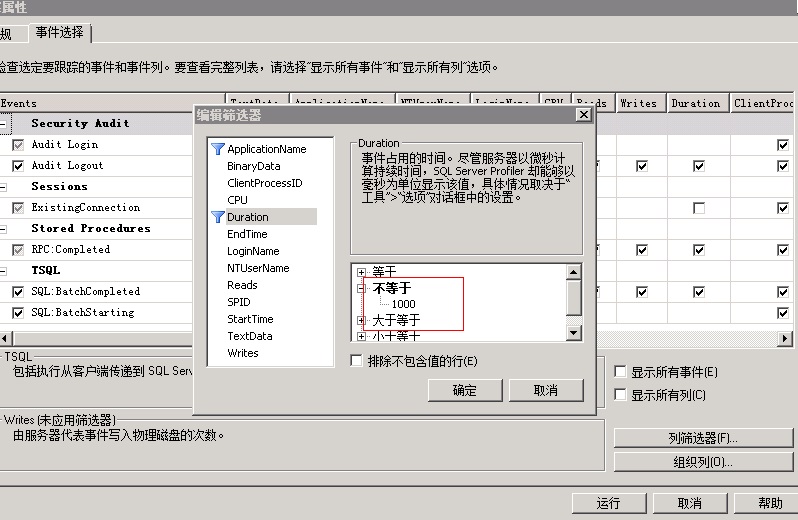
2、跟踪SQL执行错误 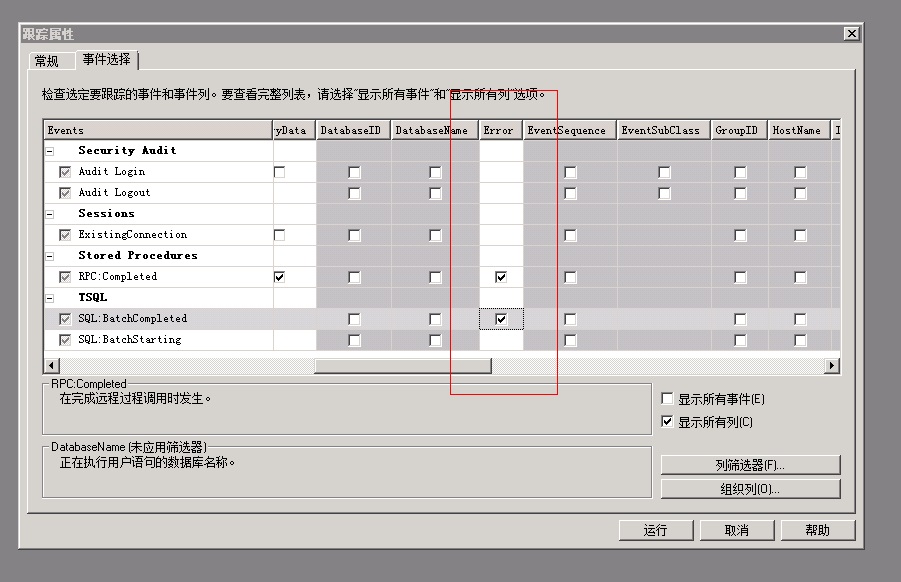
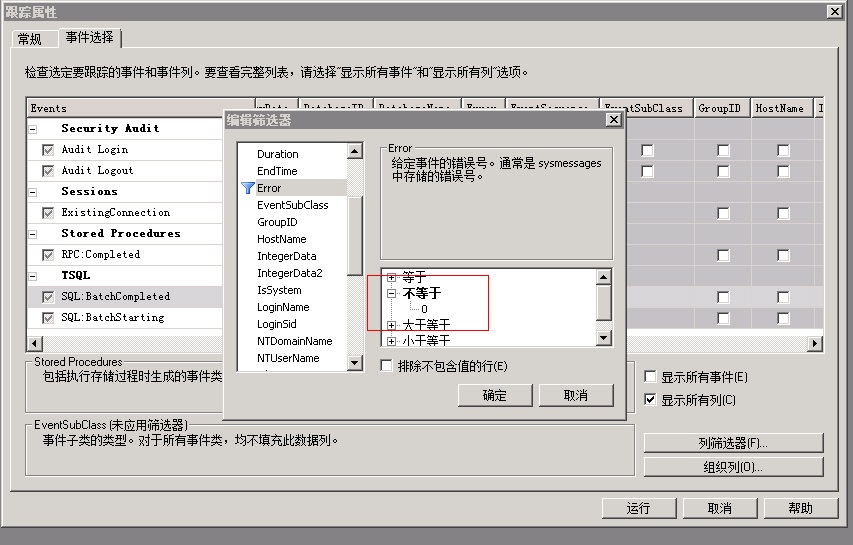
3、调试中找到SQL 以特殊字符作为筛选条件 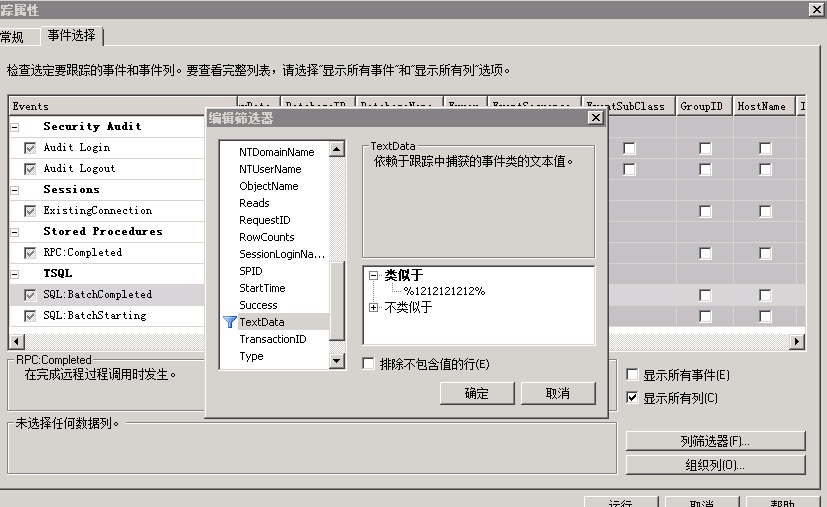
4、T-SQL查询trace表
a、设置抓取的时候段
b、保持成文件 然后用下面语句查询文件
SELECT EventSequence,SPID,RequestID,DatabaseId,DatabaseName ,LoginName,StartTime,EndTime, TextData,Error ,Duration/1000 AS Duration,Reads,CPU,Writes,RowCounts ,HostName,ClientProcessID,ApplicationName INTO bak.dbo.traceFROM ::fn_trace_gettable('C:\trace\DB50 20150623.trc', default)
二、表存储结构
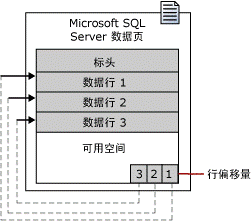
1、页 结构
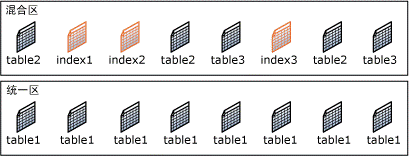
2 区结构
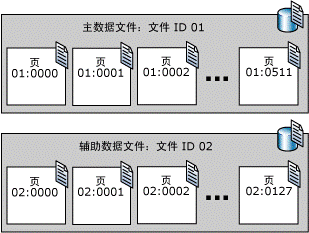
3 文件存储
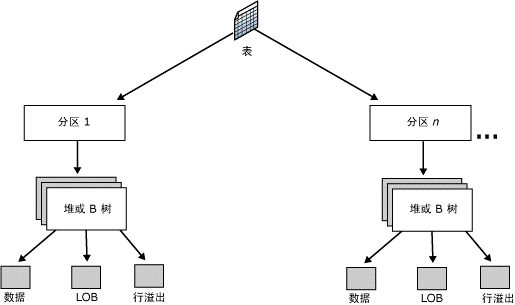
4 、基表
5、堆表
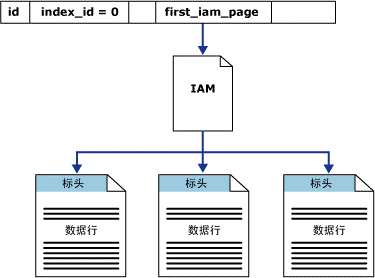
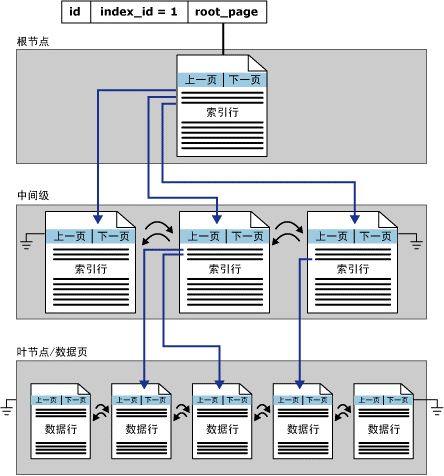
6、聚集索引
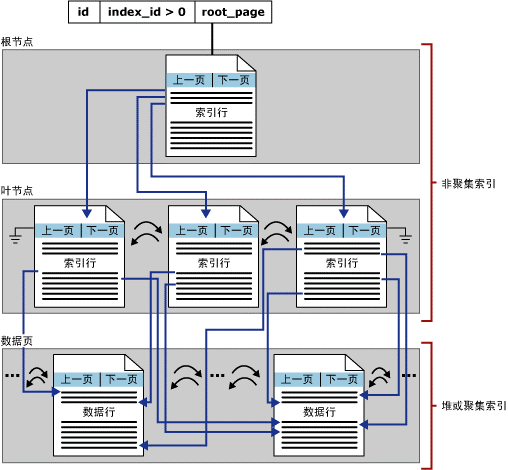
7、 普通索引
三、索引优化
1、选择性高唯一性高的字段放最前面
2、覆盖索引 Select、Where、Orderby字段都在索引中 或者 INCLUDE中 这样就会走到索引
3、控制索引数量,窄索引 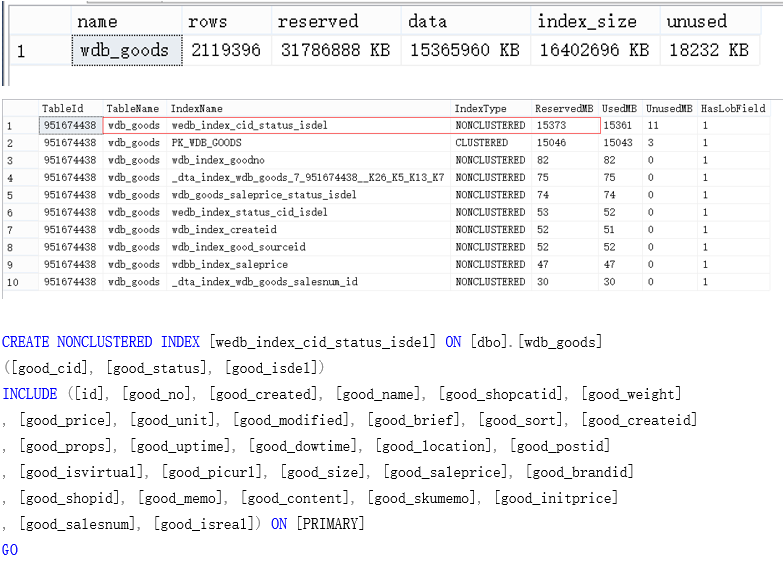 此图索引作用不大
此图索引作用不大
4、改善SQL语句
a、SQL尽量简单
b、参数化SARG的定义 列名 操作符 <常数 或 变量> Name='张三' and 价格>5000
c、非SRAG name like ‘%张' Name='张三' and 价格>5000 NOT、!=、<>、!<、!>、NOT EXISTS、NOT IN、NOT LIKE 四、执行计划
--显示统计信息
SET STATISTICS IO ON SET STATISTICS TIME ON SELECT * FROM dbo.FreezeUserMoney
开启执行重点看下面几个地方 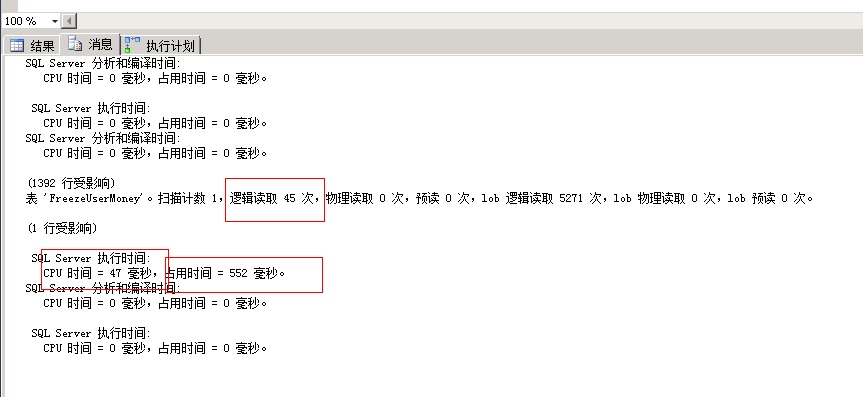
以上是针对优化sqlserver数据库全部内容,希望大家能够喜欢。
相关推荐
-
日常收集整理SqlServer数据库优化经验和注意事项
网上关于SQL优化的教程很多,但是比较杂乱.近日有空整理了一下,写出来跟大家分享一下,其中有错误和不足的地方,还请大家纠正补充. 优化数据库的注意事项: 1.关键字段建立索引. 2.使用存储过程,它使SQL变得更加灵活和高效. 3.备份数据库和清除垃圾数据. 4.SQL语句语法的优化.(可以用Sybase的SQL Expert,可惜我没找到unexpired的序列号) 5.清理删除日志. SQL语句优化的基本原则: 1.使用索引来更快地遍历表. 缺省情况下建立的索引是非群集索引,但有时它并不是最
-

深入学习SQL Server聚合函数算法优化技巧
Sql server聚合函数在实际工作中应对各种需求使用的还是很广泛的,对于聚合函数的优化自然也就成为了一个重点,一个程序优化的好不好直接决定了这个程序的声明周期.Sql server聚合函数对一组值执行计算并返回单一的值.聚合函数对一组值执行计算,并返回单个值.除了 COUNT 以外,聚合函数都会忽略空值. 聚合函数经常与 SELECT 语句的 GROUP BY 子句一起使用. 一.写在前面 如果有对Sql server聚合函数不熟或者忘记了的可以看我之前的一片博客. 本文中所有数据演示都是用
-
SqlServer 执行计划及Sql查询优化初探
网上的SQL优化的文章实在是很多,说实在的,我也曾经到处找这样的文章,什么不要使用IN了,什么OR了,什么AND了,很多很多,还有很多人拿出仅几S甚至几MS的时间差的例子来证明着什么(有点可笑),让许多人不知道其是对还是错.而SQL优化又是每个要与数据库打交道的程序员的必修课,所以写了此文,与朋友们共勉. 谈到优化就必然要涉及索引,就像要讲锁必然要说事务一样,所以你需要了解一下索引,仅仅是索引,就能讲半天了,所以索引我就不说了(打很多字是很累的,况且我也知之甚少),可以去参考相关的文章,这个网上
-
SQLServer 优化SQL语句 in 和not in的替代方案
但是用IN的SQL性能总是比较低的,从SQL执行的步骤来分析用IN的SQL与不用IN的SQL有以下区别: SQL试图将其转换成多个表的连接,如果转换不成功则先执行IN里面的子查询,再查询外层的表记录,如果转换成功则直接采用多个表的连接方式查询.由此可见用IN的SQL至少多了一个转换的过程.一般的SQL都可以转换成功,但对于含有分组统计等方面的SQL就不能转换了. 推荐在业务密集的SQL当中尽量不采用IN操作符 NOT IN 此操作是强列推荐不使用的,因为它不能应用表的索引.推荐用NOT EXIS
-
开启SQLSERVER数据库缓存依赖优化网站性能
很多时候,我们服务器的性能瓶颈会是在查询数据库的时候,所以对数据库的缓存非常重要,那么有没有一种方法,可以实现SQL SERVER数据库的缓存,当数据表没有更新时,就从缓存中读取,当有更新的时候,才从数据表中读取呢,答案是肯定的,这样的话我们对一些常用的基础数据表就可以缓存起来,比如做新闻系统的新闻类别等,每次就不需要从数据库中读取了,加快网站的访问速度. 那么如何开启SQLSERVER数据库缓存依赖,方法如下: 第一步:修改Web.Config的<system.web>节的配置,代码如下,让
-
sqlserver关于分页存储过程的优化【让数据库按我们的意思执行查询计划】
复制代码 代码如下: --代码一DECLARE @cc INT SELECT NewsId,ROW_NUMBER() OVER(ORDER BY SortNum DESC) AS RowIndex INTO #tb FROM news WITH(NOLOCK) WHERE NewsTypeId=@NewsTypeId AND IsShow=1 SET @cc = @@ROWCOUNT SELECT n.* FROM news AS n WITH(NOLOCK), #tb As t WHERE t
-
SQLSERVER SQL性能优化技巧
1.选择最有效率的表名顺序(只在基于规则的优化器中有效) SQLSERVER的解析器按照从右到左的顺序处理FROM子句中的表名,因此FROM子句中写在最后的表(基础表driving table)将被最先处理,在FROM子句中包含多个表的情况下,必须选择记录条数最少的表作为基础表,当SQLSERVER处理多个表时,会运用排序及合并的方式连接它们, 首先,扫描第一个表(FROM子句中最后的那个表)并对记录进行排序:然后扫描第二个表(FROM子句中最后第二个表):最后将所有从第二个表中检索出的记录与第
-
SqlServer 索引自动优化工具
鉴于人手严重不足(当时算两个半人的资源),打消了逐个库手动去改的念头.当前的程序结构不允许搞革命的做法,只能搞搞改良,所以准备搞个自动化工具去处理.原型刚开发完,开会的时候以拿出来就遭到运维DBA团队强烈抵制,具体原因不详.最后无限延期.这里把思路分享下.欢迎拍砖. 整个思路是这样的,索引都是为查询和更新服务的,但是不合适的索引又会对插入和更新带来负面影响.面对表上现有的索引想识别那些是有效的不太可能.那么根据现有的数据使用情况重建所有的新索引不就解决了嘛.根据查询生成全新索引,然后和现有对比,
-
sqlserver数据库优化解析(图文剖析)
下面通过图文并茂的方式展示如下: 一.SQL Profiler 事件类 Stored Procedures\RPC:Completed TSQL\SQL:BatchCompleted 事件关键字段 EventSequence.EventClass.SPID.DatabaseName.Error.StartTime.TextData. HostName.ClientProcessID.ApplicationName. CPU.Reads.Writes.Duration.RowCounts
-
SQLSERVER数据库升级脚本图文步骤
只能远程协助的方式.我特意做了一个脚本,用电话指导客户在SSMS里执行一下脚本就可以了 1.0的数据库跟1.1的数据库的区别是1.1的数据库里的其中一个[CT_OuterCard]表比1.0的多了6个字段,其他所有表都一样 还有存储过程增加了很多,其他都没有改变 首先,先在公司的服务器数据库上生成存储过程脚本,数据库是1.1版本的,下面的图片里没有说明的,都是默认设置,下一步即可 选中数据库->右键->任务->生成脚本 当然,如果你的数据库里有自定义函数的话,也可以勾选函数,如果我们的数
-
远程连接阿里云SqlServer 2012 数据库服务器的图文教程
前言: 在使用 阿里云 上的一些产品时,遇到不少坑. 安装IIS 时,遇到因买的配置过低,虚拟内存不足,而导致 IIS 总是安装失败: 现在 在上面安装了个 Sql Sever 2012,远程老是 不能连接,百度找半天,终于能够连接上了. 实现步骤如下: 1. 找到 安全组配置,打开 安全组配置,点击配置规则,增加 地址段访问的 授权规则,Sql Server的默认端口时 1433 . 2. 服务器上 win + R 键入 compmgmt.msc ,打开 计算机管理,按照如图所示 设置.注
-
在SQLserver数据库之间进行传表和传数据的图文教程
一.如何传表? 1.简单的生成脚本,修改数据库名字完成传表(这里以Person表和People做示例) Person里已有表 生成脚本文件 直接下一步 选择要传的文件 文件路径自选,另存为ANSI文本,然后下一步 直接下一步 脚本生成 找到并打开此文件 USE [Person]修改成 USE [People] F5执行后表就传过去了,但数据传没传过去,下一步介绍传数据 二.如何传数据? 1.将数据导出到另一个数据库 People数据库中没有数据 从Person数据库中传入数据 身份验证后,下拉框
-
Navicat 连接SQLServer数据库(图文步骤)
连接配置方式如图: 有时候Navicat并没有初始化安装sqlncli, 所以连接的时候会报 没有默认驱动,如图: 解决方法:在navicat目录下找到对应驱动,点击安装即可, 安装过程中设置为全部允许安装 到此这篇关于Navicat 连接SQLServer数据库(图文步骤)的文章就介绍到这了,更多相关Navicat 连接SQLServer内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
-
监视SQLServer数据库镜像[图文]
1.首先,打开SMS,在任意一个数据库上面点右键,任务,启动数据库镜像监视器. 2.点击注册镜像数据库,在服务器实例下拉菜单中选择镜像数据库的实例名,如果没有,可以直接点连接,然后在链接到服务器窗口中进行设置,如下图所示: 3.设置好后点确定就出现如下窗口所示了: 4. 点击警告选项卡,可以设置对警告的阈值进行设置,如下图所示: 5.在步骤3的窗口上点击历史记录,就可以查看SQLServer数据库镜像运行的历史记录了.如下图所示:
-
sqlserver数据库导入方法的详细图文教程
目录 第一种方法: 第二种方法: 总结 第一种方法: ****1.****打开SQL Server,写好登录名和密码点击连接. ****2.****打开数据库,右键某一个数据库,选择“新建查询(Q)”. ****3.****再代码界面输入如下代码,点击F5键或者点击运行按钮即可. 代码如下: EXEC sp_attach_db @dbname = '你的数据库名', @filename1 = 'mdf文件路径(包缀名)', @filename2 = 'Ldf文件路径(包缀名)' ****4.**
-
SQLServer数据库中开启CDC导致事务日志空间被占满的原因
SQLServer中开启CDC之后,在某些情况下会导致事务日志空间被占满的现象为: 在执行增删改语句(产生事务日志)的过程中提示,The transaction log for database '***' is full due to 'REPLICATION'(数据库"***"的事务日志已满,原因为"REPLICATION"). CDC以及复制的基本原理粗略地讲,对于日志的使用步骤如下: 1,每当基础表(开启了CDC或者replication的表)产生事务性操作