SQL Server里书签查找的性能伤害
在我的博客上,以前我经常谈到SQL Serverl里的书签查找,还有它们带来的很多问题。在今天的文章里,我想从性能角度进一步谈下书签查找,还有它们如何拉低你整个SQL Server性能。
书签查找——反复循环
如果你的非聚集索引不是个覆盖非聚集索引,SQL Server的查询优化器会引入书签查找。对于从非聚集索引你返回的每一行,SQL Server需要在聚集索引里或堆表里进行额外的查找操作。
例如当你的的聚集索引包含3层,为了返回必要的信息,对于每一行,你需要3页额外的读取。因此,查询优化器再执行计划里选择书签查找操作,仅在有意义的时候发生——基于你查询的选择度。下图展示了有书签查找操作的执行计划。
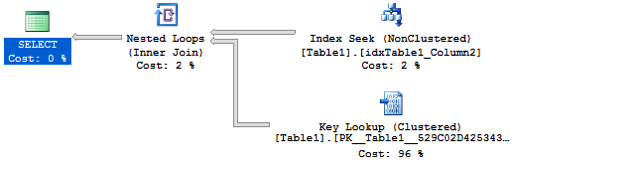
通常人们不会太关注书签查找,因为它们只执行几次。如果你的查询选择度太低,查询优化器会用聚集索引扫描或表扫描运算符直接扫描整个表。但只在SQL Server重用缓存的执行计划,这个计划是有多次不同运行值,包含书签查找的(基于最初提供的输入值),因此这个情况很容易发生,书签查找反复执行。
为了演示这个性能问题,接下来的查询我指定查询优化器使用特定的非聚集索引。查询本身返回80000行,因为对于每个查询执行,SQL Server需要进行书签查找80000次——反复执行。
CREATE PROCEDURE RetrieveData AS SELECT * FROM Table1 WITH (INDEX(idxTable1_Column2)) WHERE Column3 = 2 GO
下图展示了查询执行后的实际执行计划。

执行计划看起来非常恐怖(查询优化器甚至启用了并行计划!),因为书签查找运算符这里执行了80000次,查询本身产生了超过165000个逻辑读!(逻辑读个数可以从STATISTIC IO里获取)。

接下来向你展示下,当你有很多并行用户执行这个糟糕查询时,SQL Server会发生什么。我会使用ostress.exe(RML工具的一部分)来模拟100个并行用户的查询。
ostress.exe -Q”EXEC BookmarkLookupsPerformance.dbo.RetrieveData” -n100 -q
在我的测试系统上花费了近15秒来完成100个并行查询。在此期间,CPU占用很高,因为SQL Server需要嵌套循环运算符来进行书签查找操作。嵌套循环操作当然很占CPU资源。
现在让我们修改索引设计,为这个查询创建覆盖非聚集索引。有了非聚集索引,查询优化器不需要再执行计划里进行书签查找。一个非聚集索引查找就可以返回同样的结果:
CREATE NONCLUSTERED INDEX idxTable1_Column2 ON Table1(Column3) INCLUDE (Column2) WITH (DROP_EXISTING = ON) GO
这次当我们再次用ostress.exe执行同个查询,我们看到每个查询在5秒内完成。和我们刚才看到的15秒有很大的区别。这就是覆盖非聚集索引的威力:在我们查询里气门请求的数据都可以在非聚集索引里直接找到,因此书签查找就可以避免。
小结
在这个文章里我向你展示了不好的书签查找会伤及性能。因此,对于重要的查询快速完成查询非常重要——而使用并行的书签查找的执行计划并不是好的选择。这里覆盖非聚集索引可以帮到你。下次设计索引时可以考虑下这个方法。
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,同时也希望多多支持我们!
相关推荐
-

Sql Server查询性能优化之不可小觑的书签查找介绍
小小程序猿SQL Server认知的成长 1.没毕业或工作没多久,只知道有数据库.SQL这么个东东,浑然分不清SQL和Sql Server Oracle.MySql的关系,通常认为SQL就是SQL Server 2.工作好几年了,也写过不少SQL,却浑然不知道索引为何物,只知道数据库有索引这么个东西,分不清聚集索引和非聚集索引,只知道查询慢了建个索引查询就快了,到头来索引也建了不少,查询也确实快了,偶然问之:汝建之索引为何类型?答曰:... 3.终于受到刺激开始奋发图强,买书,gg查资料终于知道
-
SQL Server里书签查找的性能伤害
在我的博客上,以前我经常谈到SQL Serverl里的书签查找,还有它们带来的很多问题.在今天的文章里,我想从性能角度进一步谈下书签查找,还有它们如何拉低你整个SQL Server性能. 书签查找--反复循环 如果你的非聚集索引不是个覆盖非聚集索引,SQL Server的查询优化器会引入书签查找.对于从非聚集索引你返回的每一行,SQL Server需要在聚集索引里或堆表里进行额外的查找操作. 例如当你的的聚集索引包含3层,为了返回必要的信息,对于每一行,你需要3页额外的读取.因此,查询优化器再执
-
简单介绍SQL Server里的闩锁
在今天的文章里我想谈下SQL Server使用的更高级的,轻量级的同步对象:闩锁(Latch).闩锁是SQL Server存储引擎使用轻量级同步对象,用来保护多线程访问内存内结构.文章的第1部分我会介绍SQL Server里为什么需要闩锁,在第2部分我会给你介绍各个闩锁类型,还有你如何能对它们进行故障排除. 为什么我们需要闩锁? 闩锁首次在SQL Server 7.0里引入,同时微软首次引入了行级别锁(row-level locking).对于行级别锁引入闩锁的概念是非常重要的,不然的话在内存中
-
sql server查询语句阻塞优化性能
在生产环境下,有时公司客服反映网页半天打不到,除了在浏览器按F12的Network响应来排查,确定web服务器无故障后.就需要检查数据库是否有出现阻塞 当时数据库的生产环境中主表数据量超过2000w,子表数据量超过1亿,且更新和新增频繁.再加上做了同步镜像,很消耗资源. 这时就要新建一个会话,大概需要了解以下几点: 1.当前活动会话量有多少? 2.会话运行时间? 3.会话之间有没有阻塞? 4.阻塞时间 ? 查询阻塞的方法有很多.有sql 2000 的sp_lock, 有sql 2005及以上的d
-
Access和SQL Server里面的SQL语句的不同之处
我的感觉是,Accees数据库虽然可以称得上是小型的关系型数据库,并且也是使用的结构化查询语言SQL,但它的语法(主要体现在函数上),却类似vbscript的语法,我想,这应该和Access属于Office系列有关,基于它的开发和应用,自然就与VBA扯上关系,因而Access的函数库也就是VBA的函数库,而非SQL函数库.下面,我们来具体看下Access和SQL Server在查询语句的编写上具体的不同. 一.数据类型转换: Access: SELECT '调查'+CStr(Did) as di
-
为什么我们需要在SQL Server里更新锁
每次讲解SQL Server里的锁和阻塞(Locking & Blocking)都会碰到的问题:在SQL Server里,为什么我们需要更新锁?在我们讲解具体需要的原因前,首先我想给你介绍下当更新锁(Update(U)Lock)获得时,根据它的兼容性锁本身是如何应对的. 一般来说,当执行UPDATE语句时,SQL Server会用到更新锁(Update Lock).如果你查看对应的执行计划,你会看到它包含3个部分: 读取数据 计算新值 写入数据 在查询计划的第1部分,SQL Server初始读取
-
SQL SERVER 里的错误处理(try catch)
BEGIN TRY -- END TRY BEGIN CATCH -- END CATCH. 另外,WITH 语句如果前面还有别的SQL语句,应该在前面的SQL语句结尾加上分号";".比如在这个TRY CATCH里,就应该在前面加个";",如下: BEGIN TRY WITH w AS( SELECT f1,f2,f3 ,ROW_NUMBER() OVER(ORDER BY Id DESC) AS Row FROM [t1] WHERE Code=@Code ) I
-
SQL Server 2008 R2——查找最小nIndex,nIndex存在而nIndex+1不存在 求最小连续数组中的最大值
其实大家稍微动下大脑,问题可以转化为,是求最小连续数组中的最大值,数组大小可以为1. ======================================================================= 做戏做全套,送佛送到西. 为了便于学习研究,必然是要写全套示例代码的. ------------------------------------------------------------------------------------- --by wls --非专
-
Sql Server里删除数据表中重复记录的例子
[项目] 数据库中users表,包含u_name,u_pwd两个字段,其中u_name存在重复项,现在要实现把重复的项删除! [分析] 1.生成一张临时表new_users,表结构与users表一样: 2.对users表按id做一个循环,每从users表中读出一个条记录,判断new_users中是否存在有相同的u_name,如果没有,则把它插入新表:如果已经有了相同的项,则忽略此条记录: 3.把users表改为其它的名称,把new_users表改名为users,实现我们的需要. [程序] 复制代
-
Sql Server 查询性能优化之走出索引的误区分析
据了解绝大多数开发人员对于索引的理解都是一知半解,局限于大多数日常工作没有机会.也什么没有必要去关心.了解索引,实在哪天某个查询太慢了找到查询条件建个索引就ok,哪天又有个查询慢了,再建立个索引就是,或者干脆把整个查询SQL直接发给DBA,让DBA直接帮忙优化了,所以造成的状况就是开发人员对于索引的理解.认识很局限,以下就把我个人对于索引的理解及浅薄认识和大家分享下,希望能解除一些大家的疑惑,一起走出索引的误区 误区1.在表上建立了索引,在查询时用到了索引的列,索引就一定会生效 首先明确下这样的
-
SQL Server 2016 查询存储性能优化小结
作为一个DBA,排除SQL Server问题是我们的职责之一,每个月都有很多人给我们带来各种不能解释却要解决的性能问题. 我就多次听到,以前的SQL Server的性能问题都还好且在正常范围内,但现在一切已经改变,SQL Server开始糟糕, 疯狂的事情不能解释.在这个情况下我介入,分析下整个SQL Server的安装,最后用一些神奇的调查方法找出性能问题的根源. 但很多时候问题的根源是一样的:所谓的计划回归(Plan Regression),即特定查询的执行计划已经改变.昨天SQL Serv