Python中使用subprocess库创建附加进程
前言
subprocess库提供了一个API创建子进程并与之通信。这对于运行生产或消费文本的程序尤其有好处,因为这个API支持通过新进行的标准输入和输出通道来回传数据。
本篇,将详细介绍Python创建附加进行的库:subprocess。
run(运行外部命令)
subprocess库本身可以替换os.system(),os.spawnv()等函数。现在我们来通过subprocess库运行一个外部命令,但不采用os.system()。示例如下:
import subprocess
completed = subprocess.run('whoami')
print(completed.returncode)
这里我们运行了一个windows系统常用的whoami命令,返回当前用户的名称,输出如下:
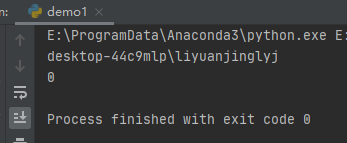
这里,我们使用了subprocess.run调用了子进程运行windows命令。它返回一个CompletedProcess实例,它包含了与进行有关的信息。returncode为子进程的退出状态码。通常情况下,退出状态码为0则表示进程成功运行了;一个负值-N表示这个子进程被信号N终止了。
该函数还有许多参数,比如shell,默认值为False表示直接运行命令,如果主动赋值为True则会创建一个中间shell进程,由这个进程运行命令。
import subprocess
completed = subprocess.run('echo 123',shell=True)
print(completed.returncode)
比如这里,我们打印123。
该库还有一个call()函数,subprocess.run有一个check参数,如果没有设置该参数,等价于调用了call()函数。check默认值为False。
对于run()函数启动的进程,它的标准输入输出通道会绑定到父进程的输入输出。这说明调用程序无法捕获命令的输出。不过,我们可以通过为stdout和stderr参数传入PIPE来捕获输出,以备以后处理。
import subprocess
completed = subprocess.run('whoami',stdout=subprocess.PIPE)
print(completed.returncode)
print(len(completed.stdout))
print(completed.stdout.decode('UTF-8'))
运行之后,效果如下:
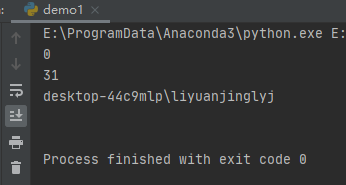
如果设置run()函数的参数check=True与stdout为PIPE,等价于调用了check_output()函数。
通过Shell返回消息
本例会通过一个子shell运行命令,在命令返回错误码并退出之前,将详细输入到控制台。实例如下:
import subprocess
try:
completed = subprocess.run(
'echoa 123',
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE, )
except subprocess.CalledProcessError as err:
print("ERROR:", err)
else:
print("else")
print(completed.returncode)
print(len(completed.stdout))
print(completed.stdout.decode('UTF-8'))
print(len(completed.stderr))
print(completed.stderr.decode('gbk'))
运行之后,效果如下:
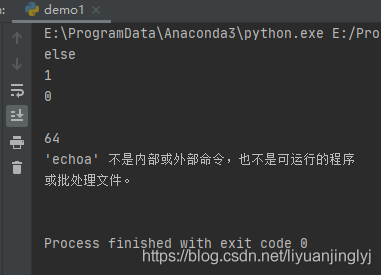
这里我们输入了一个错误的命令,可以看到因为命令错误,并没有输出命令的执行结果,0和64中间就是completed.stdout,为空。而命令将错误消息返回了。这是因为我们设置了stdout与stderr为subprocess.PIPE,表明这些通道要开放。这样我们才能获取子shell运行的结果获取所运行的错误提示。(读者可以将命令改正确后可以发现错误消息没有了,正确执行结果会输出。这就是subprocess库创建进程的通信机制)
需要注意的是,如果需要抑制输出效果,可以将stdout与stderr设置为subprocess.DEVNULL。不过改了之后,上面代码肯定会报错,因为管道关闭,通信也就关闭了。也就是没有这些参数了。
直接处理管道
subprocess库还有一个非常重要的类Popen,它是用来建立其他API的底层API,对更复杂的进程交互很有用。
比如run(),call(),check_call()和check_output()函数都是Popen类的包装器。直接使用Popen可以更好的控制如何运行命令以及如何处理输入和输出流。Popen的构造函数利用参数建立新进程,使父进程可以通过管道与之通信。
下面,我们来分别介绍进程间通信的方式。
与进程的单项通信
要运行一个进程并读取它的所有输出,可以设置stdout为PIPE并调用communicate()函数。示例如下:
import subprocess
prc = subprocess.Popen('whoami', stdout=subprocess.PIPE)
stdout_value = prc.communicate()[0].decode('utf-8')
print(repr(stdout_value))
如上面代码所示,Popen会在内部管理数据读取。运行之后,效果如下:
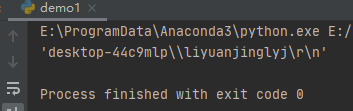
如果你需要调用一个管道,并完成写数据的操作,可以设置stdin为PIPE。
import subprocess
prc = subprocess.Popen(["cmd", "/c", 'type', '-'], stdin=subprocess.PIPE)
prc.communicate('stdin'.encode('UTF-8'))
与进程的双向通信
要完成进程的双向通信,可以直接将stdin与stdout都设置为PIPE即可。示例如下:
import subprocess
cmd = "cmd /c type E:/Project/debug.log"
cmd.encode('utf-8')
prc = subprocess.Popen(cmd, stdin=subprocess.PIPE, stdout=subprocess.PIPE)
msg = 'stdin'.encode('UTF-8')
stdout_value = prc.communicate(msg)[0].decode('utf-8')
print(repr(stdout_value))
至于如果命令行错误需要捕获错误消息,可以直接将stderr也设置为PIPE。
连接管道段
在Linux系统中,我们可以将多个命令连接成一个管线,即可以把它们的输入输出串联在一起。通过Popen我们也可以完成类似的操作,只需要将一个Popen实例的stdout属性被用左管线中下一个Popen实例的stdin参数即可。至于最后肯定还是要设置为PIPE,毕竟我们还是要获取多个管道段消息结果,示例如下:
import subprocess
cmd1 = "cmd /c type E:/Project/debug.log"
proc1 = subprocess.Popen(cmd1, stdout=subprocess.PIPE, encoding='utf-8')
cmd2 = "tree /F | findstr 拒绝访问"
proc2 = subprocess.Popen(cmd1, stdout=subprocess.PIPE, stdin=proc1.stdout, encoding='utf-8')
result = proc2.stdout
for line in result:
print(line.decode('utf-8').strip())
sys的命令交互
在我们学习Python时,一般使用input()进行用户输入数据。但是其实sys库也可以进行输入输出判断,但它涉及的是进程间的交互,示例如下:
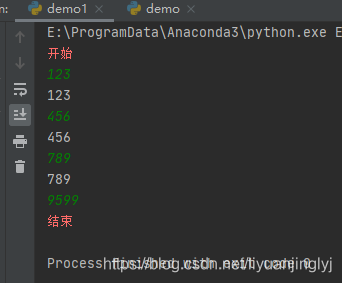
import sys
sys.stderr.write('开始\n')
sys.stderr.flush()
while True:
next_line = sys.stdin.readline()
sys.stderr.flush()
if next_line.strip() == "9599":
break
sys.stdout.write(next_line)
sys.stdout.flush()
sys.stderr.write('结束\n')
sys.stderr.flush()
运行之后,效果如下:
到此这篇关于Python中使用subprocess库创建附加进程的文章就介绍到这了,更多相关Python附加进程内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python标准库06之子进程 (subprocess包) 详解
这里的内容以Linux进程基础和Linux文本流为基础.subprocess包主要功能是执行外部的命令和程序.比如说,我需要使用wget下载文件.我在Python中调用wget程序.从这个意义上来说,subprocess的功能与shell类似. subprocess以及常用的封装函数 当我们运行python的时候,我们都是在创建并运行一个进程.正如我们在Linux进程基础中介绍的那样,一个进程可以fork一个子进程,并让这个子进程exec另外一个程序.在Python中,我们通过标准库中的subp
-
Python3-异步进程回调函数(callback())介绍
废话不多说,大家之家看代码吧! #异步 ''' 举例: 你喊你朋友吃饭,你朋友正忙, 如果你一直在那等他,等你朋友忙完了,你们一块去.--同步调用 你喊你朋友吃饭,你朋友正忙, 如果你自己做你自己的事,你朋友忙完,找到你,一块去吃饭.--异步调用 ''' # from bs4 import BeautifulSoup from multiprocessing import Process,Pool import os import time #子进程任务 def download(): prin
-
python多进程 主进程和子进程间共享和不共享全局变量实例
Python 多进程默认不能共享全局变量 主进程与子进程是并发执行的,进程之间默认是不能共享全局变量的(子进程不能改变主进程中全局变量的值). 如果要共享全局变量需要用(multiprocessing.Value("d",10.0),数值)(multiprocessing.Array("i",[1,2,3,4,5]),数组)(multiprocessing.Manager().dict(),字典)(multiprocessing.Manager().list(ran
-
Python subprocess库的使用详解
介绍 使用subprocess模块的目的是用于替换os.system等一些旧的模块和方法. 运行python的时候,我们都是在创建并运行一个进程.像Linux进程那样,一个进程可以fork一个子进程,并让这个子进程exec另外一个程序.在Python中,我们通过标准库中的subprocess包来fork一个子进程,并运行一个外部的程序. subprocess包中定义有数个创建子进程的函数,这些函数分别以不同的方式创建子进程,所以我们可以根据需要来从中选取一个使用.另外subprocess还提供了
-
Python使用多进程运行含有任意个参数的函数
1. 问题引出 许多时候,我们对程序的速度都是有要求的,速度自然是越快越好.对于Python的话,一般都是使用multiprocessing这个库来实现程序的多进程化,例如: 我们有一个函数my_print,它的作用是打印我们的输入: def my_print(x): print(x) 但是我们嫌它的速度太慢了,因此我们要将这个程序多进程化: from multiprocessing import Pool def my_print(x): print(x) if __name__ == "__
-

Python中使用subprocess库创建附加进程
前言 subprocess库提供了一个API创建子进程并与之通信.这对于运行生产或消费文本的程序尤其有好处,因为这个API支持通过新进行的标准输入和输出通道来回传数据. 本篇,将详细介绍Python创建附加进行的库:subprocess. run(运行外部命令) subprocess库本身可以替换os.system(),os.spawnv()等函数.现在我们来通过subprocess库运行一个外部命令,但不采用os.system().示例如下: import subprocess complet
-
python中的subprocess.Popen()使用详解
从python2.4版本开始,可以用subprocess这个模块来产生子进程,并连接到子进程的标准输入/输出/错误中去,还可以得到子进程的返回值. subprocess意在替代其他几个老的模块或者函数,比如:os.system os.spawn* os.popen* popen2.* commands.* 一.subprocess.Popen subprocess模块定义了一个类: Popen class subprocess.Popen( args, bufsize=0, executable
-
Python中logging日志库实例详解
logging的简单使用 用作记录日志,默认分为六种日志级别(括号为级别对应的数值) NOTSET(0) DEBUG(10) INFO(20) WARNING(30) ERROR(40) CRITICAL(50) special 在自定义日志级别时注意不要和默认的日志级别数值相同 logging 执行时输出大于等于设置的日志级别的日志信息,如设置日志级别是 INFO,则 INFO.WARNING.ERROR.CRITICAL 级别的日志都会输出. |2logging常见对象 Logger:日志,
-
python中ThreadPoolExecutor线程池和ProcessPoolExecutor进程池
目录 1.ThreadPoolExecutor多线程 <1>为什么需要线程池呢? <2>标准库concurrent.futures模块 <3>简单使用 <4>as_completed(一次性获取所有的结果) <5>map()方法 <6>wait()方法 2.ProcessPoolExecutor多进程 <1>同步调用方式: 调用,然后等返回值,能解耦,但是速度慢 <2>异步调用方式:只调用,不等返回值,可能存在
-
python中的多进程的创建与启动方式
目录 一.多进程的创建:多进程的创建方法有两种: 1.通过Process创建多进程 Process语法结构: 2.通过进程池创建并启动多进程 3.通过继承的方法创建多进程 4.进程创建与启动完整代码 python中的并发有三种形式,多进程.多线程.协程.执⾏并发任务的⽬的是为了提⾼程序运⾏的效率. 一.多进程的创建:多进程的创建方法有两种: 1.通过Process创建多进程 Process语法结构: Process(group, target, name, args, kwargs) group
-
利用Python中的pandas库对cdn日志进行分析详解
前言 最近工作工作中遇到一个需求,是要根据CDN日志过滤一些数据,例如流量.状态码统计,TOP IP.URL.UA.Referer等.以前都是用 bash shell 实现的,但是当日志量较大,日志文件数G.行数达数千万亿级时,通过 shell 处理有些力不从心,处理时间过长.于是研究了下Python pandas这个数据处理库的使用.一千万行日志,处理完成在40s左右. 代码 #!/usr/bin/python # -*- coding: utf-8 -*- # sudo pip instal
-
对python中的xlsxwriter库简单分析
一.xlsxwriter 基本用法,创建 xlsx 文件并添加数据 官方文档:http://xlsxwriter.readthedocs.org/ xlsxwriter 可以操作 xls 格式文件 注意:xlsxwriter 只能创建新文件,不可以修改原有文件.如果创建新文件时与原有文件同名,则会覆盖原有文件 Linux 下安装: sudo pip install XlsxWriter Windows 下安装: pip install XlsxWriter # coding=utf-8 from
-
Python中的tkinter库简单案例详解
目录 案例一 Label & Button 标签和按钮 案例二 Entry & Text 输入和文本框 案例三 Listbox 部件 案例四 Radiobutton 选择按钮 案例五 Scale 尺度 案例六 Checkbutton 勾选项 案例七 Canvas 画布 案例八 Menubar 菜单 案例九 Frame 框架 案例十 messagebox 弹窗 案例十一 pack grid place 放置 登录窗口 TKinterPython 的 GUI 库非常多,之所以选择 Tkinte
-
在Python中如何优雅地创建表格的实现
目录 1. 引言 2. 准备工作 3. 举个栗子 3.1 使用list生成表格 3.2 使用dict生成表格 3.3 增加索引列 3.4 缺失值处理 4. 总结 1. 引言 如果能够将我们的无序数据快速组织成更易读的格式,对于数据分析非常有帮助. Python 提供了将某些表格数据类型轻松转换为格式良好的纯文本表格的能力,这就是 tabulate 库. 闲话少说,我们直接开始吧. :) 2. 准备工作 安装tabulate库安装tabulate库非常容易,使用pip即可安装,代码如下: pip
-
python中h5py开源库的使用样例详解
目录 一.h5py模块介绍 二.h5py模块使用 1.h5py接口简单介绍 2.h5py的使用样例 一.h5py模块介绍 本文只是简单的对h5py库的基本创建文件,数据集和读取数据的方式进行介绍!如果读者需要进一步详细的学习h5py的更多知识,请参考h5py的官方文档. h5py简单介绍 一个HDF5文件是一种存放两类对象的容器:dataset和group. Dataset是类似于数组的数据集,而group是类似文件夹一样的容器,它好比python中的字典,有键(key)和值(value),存放