详解Python相关文件常见的后缀名
常见的 Python 文件后缀有:py、pyc 、pyo、 pyi、pyw、 pyd、 pyx 等。
本文只介绍相对常见的一些后缀名,至于一些特别冷门的文件格式,例如一些文章提到的pyz、pywz、rpy、pyde、pyp、 pyt等,并没有进行研究。因为这些扩展名资料很少,网上搜到的文章似乎都是同一个出处,只是简单提了一句,说了等于没说。
py
最常见的 Python 源代码文件。
实际上如果用 python + 文件 的方式运行代码,只要文件内容相同,后缀名是不重要的,也就是说下面的运行结果都是等价的:
python test.py python test.txt python test
pyc
常见的 Python 字节码缓存文件。
pyc文件和py文件一样,都可以直接执行,下面的运行结果都是等价的:
python test.py python test.pyc
作用一:提升加载性能
我们知道 Python 代码在执行时,会先由 Python 解析器翻译成 PyCodeObject 对象,俗称字节码 (Byte code),然后交给 Python 解释器来执行字节码。
上述过程中翻译后的字节码是保存在内存中,程序运行结束就没了,而代码没有修改的情况下,每次生成的字节码是一样的,所以每次跑程序都再走一遍翻译字节码的过程有点浪费性能。因此为了提高加载效率,Python 在程序执行结束后会把每个文件的字节码写入到硬盘中保存为 xxx.pyc 文件,这样下一次再执行这个程序时先在目录下找有没有xxx.pyc 文件,如果有这个对应文件且修改时间和xxx.py 文件的修改时间一样,就不用再执行翻译成字节码的过程,直接读取xxx.pyc 文件执行。其实缓存pyc 文件的方式对性能的提升很微小,只有项目文件非常多的时候才能看到显著提升。
默认情况下,我们发现并不是所有的py 文件都会自动生成pyc 文件,只有被其他文件 import 过的文件才会生成对应的pyc 文件。可能 Python 认为被 import 的文件重复使用的概率比较高,而主文件一般只需要加载一次。
简单做个实验可以验证,新建两个 Python 文件hello.py和import.py,内容如下:
# hello.py
print("hello")
# import.py impot hello
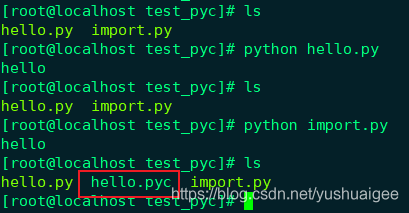
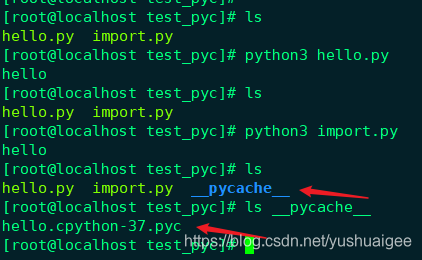
直接运行 python hello.py,并没有生成pyc 文件,而运行python import.py,在当前目录下生成了hello.py对应的pyc 文件。
这里 Python2 和 Python3 有些不同, Python2 是直接在当前目录下生成同名 pyc 文件,Python3 是在当前目录下创建了__pycache__文件夹,然后在文件夹内创建了一个包含 Python 版本信息的xxx.cpython-37.pyc 文件。
Python2
Python3
作用二:隐藏源代码
pyc格式是给解释器看的二进制文件,直接用编辑器打开看上去是乱码,所以将 Python 代码先编译成pyc文件再交付给别人使用,一定程度上实现隐藏源代码的效果。
默认情况下,主文件不会生成pyc文件,可以通过 Python 自带的py_compile或compileall 库,手动将所有py文件"编译"成pyc文件。
python -m py_compile *.py python -m compileall *.py
Python2

Python3

反编译 pyc
前面说了,是“一定程度上实现隐藏源代码的效果”,其实可以通过反编译pyc文件来获得py源码,而且反编译的难度并不大。
uncompyle6是一个专门用于将pyc反编译为py源码的第三方库,安装方式:
pip install uncompyle6
执行下面命令可以将刚才生成的pyc反编译为py文件:
uncompyle6 -o . *.pyc

打开生成的文件hello.cpython-37.py和import.cpython-37.py,可以看到和之前的py代码内容一模一样,不过多了一些 Python 的版本信息。

魔高一尺,道高一丈,有反编译技术就有防止反编译技术,更多了解参见这篇文章:通过字节码混淆来保护Python代码。
pyo
优化后的 Python 字节码缓存文件。
pyo文件的作用和pyc文件没啥区别,唯一的优化就是去掉了断言语句,即assert语句。官方文档描述:
When the Python interpreter is invoked with the -O flag, optimized code is generated and stored in .pyo files. The optimizer currently doesn't help much; it only removes assert statements. When -O is used, all bytecode is optimized; .pyc files are ignored and .py files are compiled to optimized bytecode.
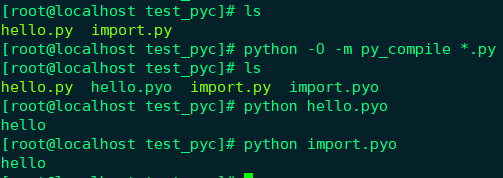
同样可以利用py_compile或compileall 库将上面示例的两个文件编译成pyo文件,只是多加一个参数-O,运行结果也没有任何变化:
python -O -m py_compile *.py python -O -m compileall *.py
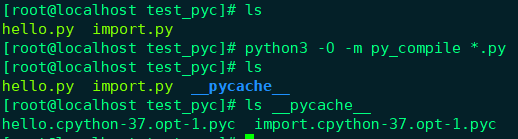
从 Python3.5 开始,Python 只使用 pyc 而不再使用pyo,所以下面命令也无法生成 pyo文件,生成的依然是 pyc 文件:
python3 -O -m py_compile *.py python3 -O -m compileall *.py
pyi
Python 的存根文件,用于代码检查时的类型提示。
pyi文件是PEP484提案规定的一种用于 Python 代码类型提示(Type Hints)的文件。PEP即Python Enhancement Proposals,是经过 Python 社区核心开发者讨论并一致同意后,对外发布的一些正式规范文档,例如我们常说的Python之禅(PEP20),代码风格 PEP8 格式化(PEP8),将 print 改为函数(PEP3105)等,关于PEP的更多了解见这篇文章:学习Python,怎能不懂点PEP呢?。
常用的 IDE 都会有类型检查提示功能,比如在 PyCharm 中,当我们给一个函数传入一个错误的类型时会给出对应的提示,这其实不是 IDE 的特殊开发的功能,它只是集成了PEP484的规定,利用了已经预先生成好的 pyi文件。
举个例子,os.makedirs是标准库中用于创建文件夹路径的函数,它的入参应该是一个字符串类型,如果传入一个 int 类型,IDE 会立刻给出提示。
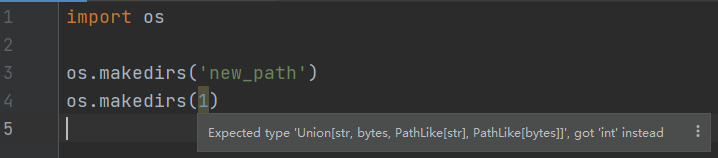
按住ctrl点进去,进入到 os 模块定义os.makedirs的地方,发现前面有个*号,鼠标放上去会提示Has stub item in __init__.pyi。
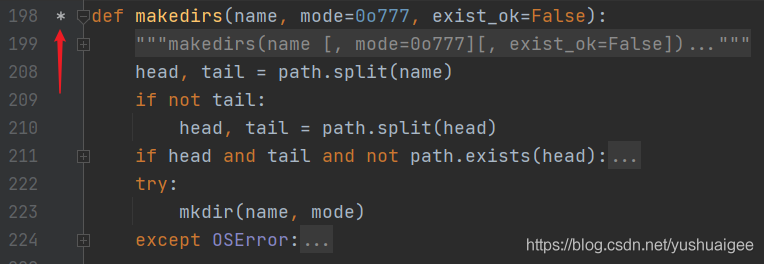
点击*号就会跳到对应的__init__.pyi文件,这个文件里按照PEP484规定,为os模块每个函数都定义了对应的类型检查规则。

关于pyi文件的定义规则以及自己如何生成,详见官方文档:PEP 484 – Type Hints
pyw
一种 Python 源代码文件,一般只存在于 Windows 系统。
pyw文件和py文件除了后缀名不一样之外没有任何区别,两者都是 Python 源码文件,前面 py那一节说过“如果用 python + 文件 的方式运行代码,只要文件内容相同,后缀名是不重要的”,这一点在 Windows 系统和 Linux 系统都是一样的。
Windows 系统,新建两个内容相同的 Python 文件hello.py和hello.pyw,用python + 文件 的方式运行,结果一样:
# hello.py
print("hello")
# hello.pyw
print("hello")

那为什么还要有pyw文件呢?
在Windows 系统上双击文件时,系统会根据文件扩展名来调用关联的exe程序来运行这个文件,打开 Python 安装目录,可以看到有python.exe和pythonw.exe两个exe,其中python.exe关联了py文件,pythonw.exe关联了pyw文件。跟 python.exe 相比,pythonw.exe运行时不会弹出控制台窗口, stdout 、stderr 和 stdin 都无效,所以像 print 这种把内容输出到 stdout 的操作就不会有打印结果(cmd 窗口都没有了也没有地方显示了)。

所以在用 Python 开发 GUI 程序时,如果不想让程序运行的时候弹出一个黑乎乎的 cmd 框,就可以将源码文件后缀名改为pyw格式。但是我感觉这个pww格式用处并不大,实际使用很少有人双击py或者pyw文件来运行 Python 代码。我之前曾用tkinter开发过带 Windows 界面的 Python 程序,当时是通过双击 bat脚本启动 Python 脚本同时关闭 cmd 界面框,来避免弹出黑框框的。
pyd
Python 可直接调用的 C 语言动态链接库文件,一般只存在于 Windows 系统。
Python 是一种胶水语言,我们可以将对速度要求比较高的那一部分代码使用 C 语言编写,编译成动态链接库文件,再通过 Python 来调用。一般来说,在 Linux 上是 so文件,在 Windows 系统上是DLL文件。
例如有一个 C 语言编写的 Windows 动态链接库 test_lib.dll,编译前的代码如下:
int sum(int x, int y)
{
return x + y;
}
我们可以在 Python 代码中通过下面的方式来调用
# test_lib.dll 放在当前目录下
import ctypes
from ctypes import *
test_lib = ctypes.windll.LoadLibrary("test_lib.dll")
a = ctypes.c_int(1)
b = ctypes.c_int(2)
out = test_lib.sum(a, b)
print(out) # 3
在 Windows 系统上,Python 还有一种 pyd格式的动态链接库,上面的调用方式是先通过ctypes.windll.LoadLibrary 方法将动态链接库加载进来,而pyd格式就可以在 Python 代码中直接import进来,类似下面这样:
# test_lib.pyd 放在当前目录下 import test_lib out = test_lib.sum(1, 2) print(out) # 3
关于 pyd文件和dll文件的区别,可参考官方文档的说明:
Is a
*.pydfile the same as a DLL?Yes, .pyd files are dll's, but there are a few differences. If you have a DLL named
foo.pyd, then it must have a functionPyInit_foo(). You can then write Python “import foo”, and Python will search for foo.pyd (as well as foo.py, foo.pyc) and if it finds it, will attempt to callPyInit_foo()to initialize it. You do not link your .exe with foo.lib, as that would cause Windows to require the DLL to be present.Note that the search path for foo.pyd is PYTHONPATH, not the same as the path that Windows uses to search for foo.dll. Also, foo.pyd need not be present to run your program, whereas if you linked your program with a dll, the dll is required. Of course, foo.pyd is required if you want to say
import foo. In a DLL, linkage is declared in the source code with__declspec(dllexport). In a .pyd, linkage is defined in a list of available functions.
C 语言代码和 Python 代码都可以通过一定的方法编译成pyd格式的文件,本人并没有实际使用过pyd文件
PyTorch中的C++扩展实现 https://www.jb51.net/article/184030.htm
Python文件编译生成pyd/so库 https://www.jb51.net/article/148711.htm
pyx
Cython 源代码文件。
注意是 Cython 不是 CPython。Cython 可以说是一种编程语言, 它结合了Python 的语法和有 C/C++的效率,用 Cython 写完的代码可以很容易转成 C 语言代码,然后又可以再编译成动态链接库(pyd或dll)供 Python 调用,所以 Cython 一般用来编写 Python 的 C 扩展,上面说的 Python 文件编译生成 pyd 文件就是利用 Cython 来实现的 。Cython 的源代码文件一般为pyx后缀。
总结
| 后缀名 | 作用 |
|---|---|
| py | 最常见的 Python 源代码文件。 |
| pyc | 常见的 Python 字节码缓存文件,可以反编译成 py 文件。 |
| pyo | 另一种 Python 字节码缓存文件,只存在于 Python2 及 Python3.5 之前的版本。 |
| pyi | Python 的存根文件,常用于 IDE 代码格式检查时的类型提示。 |
| pyw | 另一种 Python 源代码文件,一般只存在于 Windows 系统。 |
| pyd | 一种 Python 可直接调用的 C 语言动态链接库文件,一般只存在于 Windows 系统。 |
| pyx | Cython 源代码文件,一般用来编写 Python 的 C 扩展。 |
到此这篇关于Python 相关文件常见的后缀名详解的文章就介绍到这了,更多相关Python 文件后缀名内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python获取文件路径、文件名、后缀名的实例
实例如下所示: #########start 获取文件路径.文件名.后缀名############ def jwkj_get_filePath_fileName_fileExt(filename): (filepath,tempfilename) = os.path.split(filename); (shotname,extension) = os.path.splitext(tempfilename); return filepath,shotname,extension #########
-
python获取文件后缀名及批量更新目录下文件后缀名的方法
本文实例讲述了python获取文件后缀名及批量更新目录下文件后缀名的方法.分享给大家供大家参考.具体实现方法如下: 1. 获取文件后缀名: 复制代码 代码如下: #!/usr/bin/python import os dict = {} for d, fd, fl in os.walk('/home/ahda/Program/'): for f in fl: sufix = os.path.splitext(f)[1][1:]
-
python文件操作之批量修改文件后缀名的方法
1.引言 需要把.dat 格式 转化成 .txt格式 2.实现 ##python批量更换后缀名 import os # 列出当前目录下所有的文件 files = os.listdir('.') #print('files',files) for filename in files: portion = os.path.splitext(filename) # 如果后缀是.dat if portion[1] == ".dat": # 重新组合文件名和后缀名 newname = porti
-

Python实现的批量修改文件后缀名操作示例
本文实例讲述了Python实现的批量修改文件后缀名操作.分享给大家供大家参考,具体如下: windows和linux下都支持该程序 以下程序可以进行批量修改文件后缀名: #!/usr/bin/env python #coding:utf8 #! python3 #批量修改一个文件下的文件后缀 import sys import os def Rename(): #Path = "F:\\test\\" # windows下的文件目录 Path = input("请输入你需要操
-
python3 遍历删除特定后缀名文件的方法
U盘中毒了,U盘内的每个文件夹内都多了一个.lnk文件,处女座又犯了,实在不能忍,就写了个脚本把所有的.lnk文件删除了. 多级目录递归删除 import os n = 0 for root, dirs, files in os.walk('./'): for name in files: if(name.endswith(".lnk")): n += 1 print(n) os.remove(os.path.join(root, name)) 把这个脚本另存为rm.py,然后放到U盘
-
python 拷贝特定后缀名文件,并保留原始目录结构的实例
如下所示: #!/usr/bin/python # -*- coding: UTF-8 -*- import os import shutil def cp_tree_ext(exts,src,dest): """ Rebuild the director tree like src below dest and copy all files like XXX.exts to dest exts:exetens seperate by blank like "jpg
-
详解Python相关文件常见的后缀名
常见的 Python 文件后缀有:py.pyc .pyo. pyi.pyw. pyd. pyx 等. 本文只介绍相对常见的一些后缀名,至于一些特别冷门的文件格式,例如一些文章提到的pyz.pywz.rpy.pyde.pyp. pyt等,并没有进行研究.因为这些扩展名资料很少,网上搜到的文章似乎都是同一个出处,只是简单提了一句,说了等于没说. py 最常见的 Python 源代码文件. 实际上如果用 python + 文件 的方式运行代码,只要文件内容相同,后缀名是不重要的,也就是说下面的运行结果
-
详解 Python 与文件对象共事的实例
详解 Python 与文件对象共事的实例 Python 有一个内置函数,open,用来打开在磁盘上的文件.open 返回一个文件对象,它拥有一些方法和属性,可以得到被打开文件的信息,以及对被打开文件进行操作. >>> f = open("/music/_singles/kairo.mp3", "rb") (1) >>> f (2) <open file '/music/_singles/kairo.mp3', mode 'r
-
详解python持久化文件读写
持久化文件读写: f=open('info.txt','a+') f.seek(0) str1=f.read() if len(str1)==0: f1 = open('info.txt', 'w+') str1 = f.read() # 如果数据没有就写入数据到文件 time_list = ["早上", "中午", "晚上"] character_list = ["小赵","小钱", "小孙&q
-
详解Python 解压缩文件
zipfile模块及相关方法介绍: 1 压缩 1.1 创建zipfile对象 zipfile.ZipFile(file, mode='r', compression=0, allowZip64=True, compresslevel=None) 创建Zipfile对象,主要参数: 1>file压缩包名称: 2>mode:读'r'或者写'w'模式: 3>compression:设置压缩格式: 4>compresslevel:压缩等级: 压缩格式分类: 1.2 添加压缩文件 zipob
-
详解Python的文件处理
目录 先学会文件的读写! 我们看看一些文件操作示例吧 读取文件数据 写数据简单展示 按行读取 总结 先学会文件的读写! 比如像以前在学校读书的时候,第一门编程课设计要求是制作学生管理系统. 这就需要使用文件来处理(也可以用数据库,但是一般C语言都是很多计算机系新生的首选语言,这时候大概率也不知道数据库). python 最常用的是open和write函数,如下: #open函数:接收一个文件名,还有其他参数可省略不写. one_file = open('myfile.txt') #读取数据赋值给
-
详解python os.path.exists判断文件或文件夹是否存在
os即operating system(操作系统),Python 的 os 模块封装了常见的文件和目录操作. os.path模块主要用于文件的属性获取,exists是"存在"的意思,所以顾名思义,os.path.exists()就是判断括号里的文件是否存在的意思,括号内的可以是文件路径. 举个栗子: import os #判断文件夹是否存在 dir = os.path.exists('C:\\Users\\Desktop') print('dir:', dir) #判断文件是否存在 f
-
详解Python自动化之文件自动化处理
一.生成随机的测验试卷文件 假如你是一位地理老师, 班上有 35 名学生, 你希望进行美国各州首府的一个小测验.不妙的是,班里有几个坏蛋, 你无法确信学生不会作弊.你希望随机调整问题的次序, 这样每份试卷都是独一无二的, 这让任何人都不能从其他人那里抄袭答案.当然,手工完成这件事又费时又无聊. 下面是程序所做的事: • 创建 35 份不同的测验试卷. • 为每份试卷创建 50 个多重选择题,次序随机. • 为每个问题提供一个正确答案和 3 个随机的错误答案,次序随机. • 将测验试卷写到 35
-
一文详解Python中实现单例模式的几种常见方式
目录 Python 中实现单例模式的几种常见方式 元类(Metaclass): 装饰器(Decorator): 模块(Module): new 方法: Python 中实现单例模式的几种常见方式 元类(Metaclass): class SingletonType(type): """ 单例元类.用于将普通类转换为单例类. """ _instances = {} # 存储单例实例的字典 def __call__(cls, *args, **kwa
-
详解Python文本操作相关模块
详解Python文本操作相关模块 linecache--通过使用缓存在内部尝试优化以达到高效从任何文件中读出任何行. 主要方法: linecache.getline(filename, lineno[, module_globals]):获取指定行的内容 linecache.clearcache():清除缓存 linecache.checkcache([filename]):检查缓存的有效性 dircache--定义了一个函数,使用缓存读取目录列表.使用目录的mtime来实现缓存失效.此外还定义
-
详解python中的文件与目录操作
详解python中的文件与目录操作 一 获得当前路径 1.代码1 >>>import os >>>print('Current directory is ',os.getcwd()) Current directory is D:\Python36 2.代码2 如果将上面的脚本写入到文件再运行 Current directory is E:\python\work 二 获得目录的内容 Python代码 >>> os.listdir (os.getcwd