R语言编码问题的解决
今天博客主要是解决一个学R语言里面最最痛苦的问题(嗯,python2.x里面也有),就是中文乱码问题:
一般用R语言的同学,多半遇见过以下这个问题:

反正虾神我每次遇见这个问题,立刻就是:

实际上这个问题写代码的人一般都能遇见,不同字符编码的问题,如果是从文件里面读的还好说,可以带这个字符编码集一起读,但是如果这个数据是来自于数据库的,如果经验的话,那就真得各种凉拌了。
下面我简单把我今天通过R语言从Postgresql数据库中处理中文问题的整个流程说说,如果哪位同学也遇上了,可以参考我的整个解决方式。
下面这个代码是简单的从R连接Postgresql获取数据的过程,如果没有中文,就一切ok:
library(ggplot2)
library(RPostgreSQL)
drv= dbDriver("PostgreSQL")
pgCon=dbConnect(drv,user="sde",password="sde",host="127.0.0.1")
s ="select * from chinapop"
rs = dbSendQuery(pgdb, statement = s)
df = fetch(rs, n = -1)
数据是我SDE库里面的,内容如下:

在数据库里面表现如下:

结构非常简单,大部分字段都是数字型,只有name这个字段是中文的,当我们运行连接和查询之后,在R语言里面就变成了这个一个dataframe:

然后我们如果想进行一下查询,比如要查一下以“南”在结尾的省(湖南、河南、海南、云南),那么sql语句变成:

一下就让我们抓狂了……生无可恋啊……
然后我们来看看为什么会出现这个问题,首先当然看看你的R语言的环境,这个可以通过sessionInfo()来实现

原来R语言默认使用的是你系统的字符集——我这里win7中文版,默认的字符集就是cp936,也就是所谓的gb2312编码。
然后再来看看我们数据库用的编码,我这里是Postgersql,其他的数据库查看方式自己百度:

字符编码是UTF-8……好吧,知道这个问题就好解决了。
首先,从数据库里面获取的数据,回来的是UTF8的,那么我们可以转成R的字符编码,转换的函数R语言里面已经提供了,叫做iconv(), 如下:

将df里面的name数列,从UTF8的编码,转换为CP936,这样就变成了中文了。
下面就可以用同样的方式来处理中文查询的问题:
这次是从CP936转换为UTF8来执行,语句如下:
s =paste("select * from chinapop where name like '%",iconv("南","CP936","UTF8"),"'",sep = "")
paster函数,是R语言里面的字符串连接函数。

下面抛出了一个警告,所里面有个字段类型是st_geometry类型的,R语言读不了……这个是ArcGIS的东西,直接不管。
然后我们可以看出,查出来4条数据,说明SQL语句执行成功了,但是回来的还是乱码,接下去用上面说的iconv()函数转换一下就行:

到此,中文问题解决.
后面就是R语言老本行分析&可视化了,我们把这4个省的2008年的GDP做一个柱状图,代码如下(用的是ggplot2)
qplot(name,gdp_2008,data=df,fill=gdp_2008)+geom_bar(stat='identity')
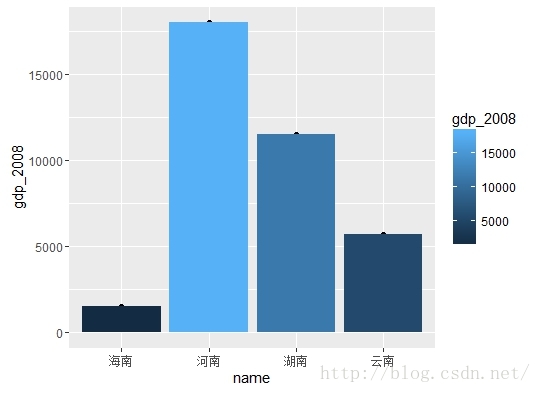
如果还需要其他的各种分析可视化,敲命令就可以了,打完收工。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

R语言-实现按日期分组求皮尔森相关系数矩阵
R语言按日期分组求相关系数 前几天得到了3700+支股票一周内的波动率,想要计算每周各个股票之间的相关系数并将其可视化.最终结果保存在制定文件夹中. 部分数据如下: 先读取数据 data<-read.csv("D:/data/stock_day_close_price_week_series.csv", header = TRUE,blank.lines.skip = TRUE) 利用mice包处理缺失值: library(lattice) library(MASS) libra
-
R语言-进行数据的重新编码(recode)操作
在分析数据时我们经常会遇到将变量值转换成其他的值的情况(如:将连续变量转成分类变量)这时就需要我们对原有数据进行重新编码.本文将介绍R软件中常用的三种重编吗方法: 1.使用逻辑判断式编码. 2.使用cut函数编码. 3.使用car程序包的recode函数. (一)使用逻辑判断式 (1)现假设我们需要将下面的连续型变量x按照10与20分成三个组,新的分组名称为1.2.3: > x2=1*(x<=10)+2*(x>10&x<=20)+3*(x>20) > x2 [1
-
R语言变量级别的数据处理操作
变量级别的数据处理无非是对变量的增删改查. 增 即增加新的变量 R语言中,增加一个新变量形式语句如下: 变量名 <- 表达式 表达式可以包含多种运算符和函数.常见运算符包括: 运算符 描述 + 加 - 减 * 乘 / 除 ^或** 求幂 x%%y 求余(x mod y).5%%2的结果为1. x%/%y 整数除法.5%/%2的结果为2. 示例: #创建一个数据框 mydata <- data.frame(x1 = c(2,2,6,4), + x2 = c(3,4,2,8)) mydata x1
-
R语言差异检验:非参数检验操作
非参数检验是在总体方差未知或知道甚少的情况下,利用样本数据对总体分布形态进行推断的方法.它利用数据的大小间的次序关系(秩Rank),而不是具体数值信息,得出推断结论. 它是参数检验所需要的某些条件不满足时所使用的方法. 和参数检验相比,非参数检验的优势如下: 稳健性.对总体分布的条件要求放宽 对数据类型要求不严格,适用有序分类变量 适用范围广 劣势: 没有利用实际数值,损失了部分信息,检验的有效性较差. 非参数性检验的方法非常多,基于方法的检验功效性角度,本文只涉及 双独立样本:Mann-Whi
-
R语言 UTF-8各种问题的解决方案
R语言在碰到读UTF-8文件,或者处理UTF-8数据时总是会遇到各种各样的问题,本姑娘也是在碰了n多次壁,被气得吐血好多次之后,终于对这类总结出了一些解决办法: 1. 读UTF-8文件,例如UTF-8格式的csv: 最好的处理办法就是: a1=read.table('C:\\test11.csv',sep=',',fileEncoding = 'UTF-8',header = F) 如果使用如下方法可能会出错(全是血泪教训啊): a2=read.csv('C:\\test11.csv',file
-
R语言-因子与向量的转换方式
一.因子的特点或性质 1.因子可视为C或JAVA语言中的枚举,适用于有限状态的表示. 2.因子不可以赋枚举集合外的值,如一个因子包含male,female,则不能再赋male和female以为的值,赋其他值会将该元素设置为空值. 二.因子的建立 1.因子的建立 假定有因子gendor,为一组人的性别: > gendor<-factor(c('m','f','f','m'),labels=c('male','female')) 则通过上式建立一个性别因子. > gendor [1] fem
-
R语言编码问题的解决
今天博客主要是解决一个学R语言里面最最痛苦的问题(嗯,python2.x里面也有),就是中文乱码问题: 一般用R语言的同学,多半遇见过以下这个问题: 反正虾神我每次遇见这个问题,立刻就是: 实际上这个问题写代码的人一般都能遇见,不同字符编码的问题,如果是从文件里面读的还好说,可以带这个字符编码集一起读,但是如果这个数据是来自于数据库的,如果经验的话,那就真得各种凉拌了. 下面我简单把我今天通过R语言从Postgresql数据库中处理中文问题的整个流程说说,如果哪位同学也遇上了,可以参考我的整个解
-
R语言多线程运算操作(解决R循环慢的问题)
已经大半年没有更新博客了..最近都跑去写分析报告半年没有R 这次记录下关于R循环(百万级以上)死慢死慢的问题,这个问题去年就碰到过,当时也尝试过多线程,but failed......昨天试了下,终于跑通了,而且过程还挺顺利 step1 先查下自己电脑几核的,n核貌似应该选跑n个线程,线程不是越多越好,线程个数和任务运行时间是条开口向下的抛物线,最高点预计在电脑的核数上. detectCores( )检查当前电脑可用核数 我的是4所以step2选的是4 library(parallel) cl.
-
解决R语言 数据不平衡的问题
R语言解决数据不平衡问题 一.项目环境 开发工具:RStudio R:3.5.2 相关包:dplyr.ROSE.DMwR 二.什么是数据不平衡?为什么要处理数据不平衡? 首先我们要知道的第一个问题就是"什么是数据不平衡",从字面意思上进行解释就是数据分布不均匀.在我们做有监督学习的时候,数据中有一个类的比例远大于其他类,或者有一个类的比值远小于其他类时,我们就可以认为这个数据存在数据不平衡问题. 那么这样的一个问题会对我们后续的分析工作带来怎样的影响呢?我举个简单的例子,或许大家就明白
-
用R语言实现霍夫曼编码的示例代码
可读性极低,而且其实也没必要用R语言写,图个乐罢了 p=c(0.4,0.2,0.2,0.1,0.1)###输入形如c(0.4,0.2,0.2,0.1,0.1)的概率向量,即每个待编码消息的发生概率 p1=p###将概率向量另存,最后计算编码效率要用 mazijuzhen=matrix(,nrow=length(p),ncol=length(p)-1)###码字矩阵:第i行对应向量p的第i个分量所对应的那个待编码消息的编码后的码字 group=matrix(c(1:length(p),rep(NA
-
R语言变量重编码、重命名的操作
1.变量重编码 重编码涉及根据同一个变量和/或其他变量的现有值创建新值的过程,如将符合某个条件的值重新赋值等,这里主要介绍两种常见的方法: #第一种方法 per <- data.frame(name = c("张三","李四","王五","赵六"), age = c(23,45,34,1000)) per per$age[per$age == 1000] <- NA #设置缺失值 per$age1[per$age
-
解决R语言安装时出现辑程包不存在的问题
[解决方案] 1.使用命令单独安装caret,安装的时间很长. install.packages("caret", dependencies = c("Depends", "Suggests")) 需要安装依赖的包全部安装之后,就可以了. 依赖包如下: dependencies 'doMC', 'rpvm', 'Rcompression', 'RMySQL', 'globaltest', 'OpenMx', 'pryr', 'gpclib', '
-
R语言 解决安装ggplot2报错的问题
如下所示: install.packages('xxx',repos='http://cran.us.r-project.org') xxx 改为 ggplot2 补充:R包安装时,出现的错误解决合集 如下所示: 1.library(devtools) #error:Error in get(genname, envir = envir) : object 'testthat_print' not found #解决 options("repos" = c(CRAN="htt
-
R语言 解决无法打开链结的问题
近期,在项目中遇到一个棘手的问题. R脚本在centos服务器上通过"R --no-save filename.R"的方式运行R脚本可以成功,分析结果也可以存入MySQL,该种方式适合算法工程师测试脚本使用. 但是,同样的脚本,在Java后台调用时却失败了. 为了定位问题位置,在脚本内插入很多打印语句,锁定了问题出现在利用RMySQL包将分析结果存入数据库部分,由于Java调用R脚本时R报错信息无法获取,因此又在R脚本中抓取了try函数的执行结果,并存储于自建的R运行日志中. 查看日志
-
R语言编程学习从Github上安装包解决网络问题
目录 1. remotes 包安装 2. devtools 包安装 3. 从 gitee.com 上安装 4. 离线安装 1)先从 GitHub 上 下载 zip 压缩文件: 2)在本地 R Studio 上进行安装: 当我们想使用 R 安装一些 Github 相关的软件包,经常会遇到或者或那的网络问题,此时我们需要怎么做呢? 以最近大家分析疫情数据经常用的 Y叔的 nCov2019 包为例,通常我们可以使用如下的尝试顺序: 1. remotes 包安装 install.packages("re