Java底层基于二叉搜索树实现集合和映射/集合Set功能详解
本文实例讲述了Java底层基于二叉搜索树实现集合和映射功能。分享给大家供大家参考,具体如下:
前言:在第5章的系列学习中,已经实现了关于二叉搜索树的相关操作,详情查看第5章即可。在本节中着重学习使用底层是我们已经封装好的二叉搜索树相关操作来实现一个基本的集合(set)这种数据结构。
集合set的特性:
集合Set存储的元素是无序的、不可重复的。为了能达到这种特性就需要寻找可以作为支撑的底层数据结构。
这里选用之前自己实现的二叉搜索树,这是由于该二叉树是不能盛放重复元素的。因此我们可以使用二叉搜索树这种底层来实现集合(set)。
1、集合set相关功能

1.1 add()方法特性
二分搜索树的添加操作add:不能盛放重复元素
2. set应用
典型应用:1.客户统计 2.词汇量统计
3.集合实现
3.1 Set接口定义
/**
* 集合的接口
*/
public interface Set<E> {
void add(E e);//添加 <——<不能添加重复元素
void remove(E e);//移除
int getSize();//获取大小
boolean isEmpty();//是否为空
boolean contains(E e);//是否包含元素
}
3.2 基于二分搜索树实现集合Set
//基于BST二分搜索树实现的集合Set
public class BSTSet<E extends Comparable<E>> implements Set<E> {//元素E必须满足可比较的
//基于BST类的对象
private BST<E> bst;
//构造函数
public BSTSet() {
bst = new BST<>();
}
//返回集合大小
@Override
public int getSize() {
return bst.size();
}
//返回集合是否为空
@Override
public boolean isEmpty() {
return bst.isEmpty();
}
//Set添加元素
@Override
public void add(E e) {
bst.add(e);
}
//是否包含元素
@Override
public boolean contains(E e) {
return bst.contains(e);
}
//移除元素
@Override
public void remove(E e) {
bst.remove(e);
}
}
3.3测试:两本名著的词汇量 和不重复的词汇量
public static void main(String[] args) {
System.out.println("Pride and Prejudice");
//新建一个ArrayList存放单词
ArrayList<String> words1=new ArrayList<>();
//通过这个方法将书中所以单词存入word1中
FileOperation.readFile("pride-and-prejudice.txt",words1);
System.out.println("Total words : "+words1.size());
BSTSet<String> set1=new BSTSet<>();
//增强for循环,定一个字符串word去遍历words
//底层的话会把ArrayList words1中的值一个一个的赋值给word
for(String word:words1)
set1.add(word);//不添加重复元素
System.out.println("Total different words : "+set1.getSize());
System.out.println("-------------------");
System.out.println("Pride and Prejudice");
//新建一个ArrayList存放单词
ArrayList<String> words2=new ArrayList<>();
//通过这个方法将书中所以单词存入word1中
FileOperation.readFile("a-tale-of-two-cities.txt",words2);
System.out.println("Total words : "+words2.size());
BSTSet<String> set2=new BSTSet<>();
//增强for循环,定一个字符串word去遍历words
//底层的话会把ArrayList words1中的值一个一个的赋值给word
for(String word:words2)
set2.add(word);//不添加重复元素
System.out.println("Total different words : "+set2.getSize());
}
结果:
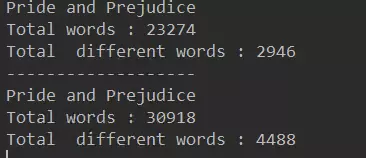
这里需要说明一下就是关于我们统计的单词数只考虑了每个单词组成的不用,并没有对单词的特殊形式做区分。
在下一小节中继续学习【集合和映射--集合Set->底层基于链表实现】。
源码地址https://github.com/FelixBin/dataStructure/tree/master/src/SetPart
更多关于java算法相关内容感兴趣的读者可查看本站专题:《Java数据结构与算法教程》、《Java操作DOM节点技巧总结》、《Java文件与目录操作技巧汇总》和《Java缓存操作技巧汇总》
希望本文所述对大家java程序设计有所帮助。
相关推荐
-
Java删除二叉搜索树最大元素和最小元素的方法详解
本文实例讲述了Java删除二叉搜索树最大元素和最小元素的方法.分享给大家供大家参考,具体如下: 在前面一篇<Java二叉搜索树遍历操作>中完成了树的遍历,这一节中将对如何从二叉搜索树中删除最大元素和最小元素做介绍: 我们要想删除二分搜索树的最小值和最大值,就需要先找到二分搜索树的最小值和最大值,其实也还是很容易的,因为根据二叉搜索树的特点,它的左子树一定比当前节点要小,所以二叉搜索树的最小值一定是左子树一直往下走,一直走到底.同样在二叉搜索树中,右子树节点值,一定比当前节点要大,所以右子树一直
-

Java 实现二叉搜索树的查找、插入、删除、遍历
由于最近想要阅读下JDK1.8 中HashMap的具体实现,但是由于HashMap的实现中用到了红黑树,所以我觉得有必要先复习下红黑树的相关知识,所以写下这篇随笔备忘,有不对的地方请指出- 学习红黑树,我觉得有必要从二叉搜索树开始学起,本篇随笔就主要介绍Java实现二叉搜索树的查找.插入.删除.遍历等内容. 二叉搜索树需满足以下四个条件: 若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值: 若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值: 任意节点的左.右子
-
Java基于二分搜索树、链表的实现的集合Set复杂度分析实例详解
本文实例讲述了Java基于二分搜索树.链表的实现的集合Set复杂度分析.分享给大家供大家参考,具体如下: 两种集合类的复杂度分析 在Java底层基于二叉搜索树实现集合和映射 和Java底层基于链表实现集合和映射中以二分搜索树和链表作为底层实现了集合Set,在本节就两种集合类的复杂度分析进行分析: 测试内容:Java底层基于二叉搜索树实现集合和映射和Java底层基于链表实现集合和映射中使用的书籍. 测试方法:测试两种集合类查找单词所用的时间 //创建一个测试方法 Set<String> set:
-
Java二叉搜索树遍历操作详解【前序、中序、后序、层次、广度优先遍历】
本文实例讲述了Java二叉搜索树遍历操作.分享给大家供大家参考,具体如下: 前言:在上一节Java二叉搜索树基础中,我们对树及其相关知识做了了解,对二叉搜索树做了基本的实现,下面我们继续完善我们的二叉搜索树. 对于二叉树,有深度遍历和广度遍历,深度遍历有前序.中序以及后序三种遍历方法,广度遍历即我们寻常所说的层次遍历,如图: 因为树的定义本身就是递归定义,所以对于前序.中序以及后序这三种遍历我们使用递归的方法实现,而对于广度优先遍历需要选择其他数据结构实现,本例中我们使用队列来实现广度优先遍历.
-
java实现 二叉搜索树功能
一.概念 二叉搜索树也成二叉排序树,它有这么一个特点,某个节点,若其有两个子节点,则一定满足,左子节点值一定小于该节点值,右子节点值一定大于该节点值,对于非基本类型的比较,可以实现Comparator接口,在本文中为了方便,采用了int类型数据进行操作. 要想实现一颗二叉树,肯定得从它的增加说起,只有把树构建出来了,才能使用其他操作. 二.二叉搜索树构建 谈起二叉树的增加,肯定先得构建一个表示节点的类,该节点的类,有这么几个属性,节点的值,节点的父节点.左节点.右节点这四个属性,代码如下 sta
-
Java二叉搜索树基础原理与实现方法详解
本文实例讲述了Java二叉搜索树基础原理与实现方法.分享给大家供大家参考,具体如下: 前言:本文通过先通过了解一些二叉树基础知识,然后在转向学习二分搜索树. 1 树 1.1 树的定义 树(Tree)是n(n>=0)个节点的有限集.n=0时称为空树.在任意一颗非空树中: (1)有且仅有一个特定的称为根(Root)的节点: (2)当n>1时,其余节点可分为m(m>0)个互不相交的有限集T1.T2........Tn,其中每一个集合本身又是一棵树,并且称为根的子树. 此外,树的定义还需要强调以
-
Java创建二叉搜索树,实现搜索,插入,删除的操作实例
Java实现的二叉搜索树,并实现对该树的搜索,插入,删除操作(合并删除,复制删除) 首先我们要有一个编码的思路,大致如下: 1.查找:根据二叉搜索树的数据特点,我们可以根据节点的值得比较来实现查找,查找值大于当前节点时向右走,反之向左走! 2.插入:我们应该知道,插入的全部都是叶子节点,所以我们就需要找到要进行插入的叶子节点的位置,插入的思路与查找的思路一致. 3.删除: 1)合并删除:一般来说会遇到以下几种情况,被删节点有左子树没右子树,此时要让当前节点的父节点指向当前节点的左子树:当被删节点
-
Java删除二叉搜索树的任意元素的方法详解
本文实例讲述了Java删除二叉搜索树的任意元素的方法.分享给大家供大家参考,具体如下: 一.删除思路分析 在删除二叉搜索树的任意元素时,会有三种情况: 1.1 删除只有左孩子的节点 节点删除之后,将左孩子所在的二叉树取代其位置:连在原来节点父亲元素右节点的位置,比如在图中需要删除58这个节点. 删除58这个节点后,如下图所示: 1.2 删除只有右孩子的节点: 节点删除之后,将右孩子所在的二叉树取代其位置:连在原来节点的位置,比如在下图中需要删除58这个节点. 删除58这个节点后,如下图所示: 这
-
Java均摊复杂度和防止复杂度的震荡原理分析
本文实例讲述了Java均摊复杂度和防止复杂度的震荡.分享给大家供大家参考,具体如下: 关于上一节封装数组的简单复杂度分析方法中我们对添加操作的时间复杂度归结为O(n)是考虑了扩容操作(resize)在内的.就addLast(e)操作而言,时间复杂度为O(1),在考虑最坏情况下,每次添加均会触发扩容操作,需要移动n个元素,因此此时addLast操作的时间复杂度为O(n). (1)addLast(e)均摊时间复杂度分析 resize(n) O(n) 假设当前capacity=8,并且每一次添加操
-
Java针对封装数组的简单复杂度分析方法
本文实例讲述了Java针对封装数组的简单复杂度分析方法.分享给大家供大家参考,具体如下: 完成了数组的封装之后我们还需对其进行复杂度分析: 此处的复杂度分析主要是指时间复杂度分析,算法的时间复杂度反映了程序执行时间随输入规模增长而增长的量级,在很大程度上能很好反映出算法的优劣与否. 1.简单概念 在各种不同算法中,若算法中语句执行次数为一个常数,则时间复杂度为O(1),另外,在时间频度不相同时,时间复杂度有可能相同,如T(n)=n2+3n+4与T(n)=4n2+2n+1它们的频度不同,但时间复杂