Flink开发IDEA环境搭建与测试的方法
一.IDEA开发环境
1.pom文件设置
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.11.12</scala.version>
<scala.binary.version>2.11</scala.binary.version>
<hadoop.version>2.7.6</hadoop.version>
<flink.version>1.6.1</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.10_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.22</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<!-- <arg>-make:transitive</arg> -->
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.0.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>org.apache.spark.WordCount</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
2.flink开发流程
Flink具有特殊类DataSet并DataStream在程序中表示数据。您可以将它们视为可以包含重复项的不可变数据集合。在DataSet数据有限的情况下,对于一个DataStream元素的数量可以是无界的。
这些集合在某些关键方面与常规Java集合不同。首先,它们是不可变的,这意味着一旦创建它们就无法添加或删除元素。你也不能简单地检查里面的元素。
集合最初通过在弗林克程序添加源创建和新的集合从这些通过将它们使用API方法如衍生map,filter等等。
Flink程序看起来像是转换数据集合的常规程序。每个程序包含相同的基本部分:
1.获取execution environment,
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
2.加载/创建初始化数据
DataStream<String> text = env.readTextFile(file:///path/to/file);
3.指定此数据的转换
val mapped = input.map { x => x.toInt }
4.指定放置计算结果的位置
writeAsText(String path) print()
5.触发程序执行
在local模式下执行程序
execute()
将程序达成jar运行在线上
./bin/flink run \ -m node21:8081 \ ./examples/batch/WordCount.jar \ --input hdfs:///user/admin/input/wc.txt\ --outputhdfs:///user/admin/output2\
二.Wordcount案例
1.Scala代码
package com.xyg.streaming
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
/**
* Author: Mr.Deng
* Date: 2018/10/15
* Desc:
*/
object SocketWindowWordCountScala {
def main(args: Array[String]) : Unit = {
// 定义一个数据类型保存单词出现的次数
case class WordWithCount(word: String, count: Long)
// port 表示需要连接的端口
val port: Int = try {
ParameterTool.fromArgs(args).getInt("port")
} catch {
case e: Exception => {
System.err.println("No port specified. Please run 'SocketWindowWordCount --port <port>'")
return
}
}
// 获取运行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 连接此socket获取输入数据
val text = env.socketTextStream("node21", port, '\n')
//需要加上这一行隐式转换 否则在调用flatmap方法的时候会报错
import org.apache.flink.api.scala._
// 解析数据, 分组, 窗口化, 并且聚合求SUM
val windowCounts = text
.flatMap { w => w.split("\\s") }
.map { w => WordWithCount(w, 1) }
.keyBy("word")
.timeWindow(Time.seconds(5), Time.seconds(1))
.sum("count")
// 打印输出并设置使用一个并行度
windowCounts.print().setParallelism(1)
env.execute("Socket Window WordCount")
}
}
2.Java代码
package com.xyg.streaming;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
/**
* Author: Mr.Deng
* Date: 2018/10/15
* Desc: 使用flink对指定窗口内的数据进行实时统计,最终把结果打印出来
* 先在node21机器上执行nc -l 9000
*/
public class StreamingWindowWordCountJava {
public static void main(String[] args) throws Exception {
//定义socket的端口号
int port;
try{
ParameterTool parameterTool = ParameterTool.fromArgs(args);
port = parameterTool.getInt("port");
}catch (Exception e){
System.err.println("没有指定port参数,使用默认值9000");
port = 9000;
}
//获取运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//连接socket获取输入的数据
DataStreamSource<String> text = env.socketTextStream("node21", port, "\n");
//计算数据
DataStream<WordWithCount> windowCount = text.flatMap(new FlatMapFunction<String, WordWithCount>() {
public void flatMap(String value, Collector<WordWithCount> out) throws Exception {
String[] splits = value.split("\\s");
for (String word:splits) {
out.collect(new WordWithCount(word,1L));
}
}
})//打平操作,把每行的单词转为<word,count>类型的数据
//针对相同的word数据进行分组
.keyBy("word")
//指定计算数据的窗口大小和滑动窗口大小
.timeWindow(Time.seconds(2),Time.seconds(1))
.sum("count");
//把数据打印到控制台,使用一个并行度
windowCount.print().setParallelism(1);
//注意:因为flink是懒加载的,所以必须调用execute方法,上面的代码才会执行
env.execute("streaming word count");
}
/**
* 主要为了存储单词以及单词出现的次数
*/
public static class WordWithCount{
public String word;
public long count;
public WordWithCount(){}
public WordWithCount(String word, long count) {
this.word = word;
this.count = count;
}
@Override
public String toString() {
return "WordWithCount{" +
"word='" + word + '\'' +
", count=" + count +
'}';
}
}
}
3.运行测试
首先,使用nc命令启动一个本地监听,命令是:
[admin@node21 ~]$ nc -l 9000
通过netstat命令观察9000端口。netstat -anlp | grep 9000,启动监听如果报错:-bash: nc: command not found,请先安装nc,在线安装命令:yum -y install nc。
然后,IDEA上运行flink官方案例程序
node21上输入

IDEA控制台输出如下
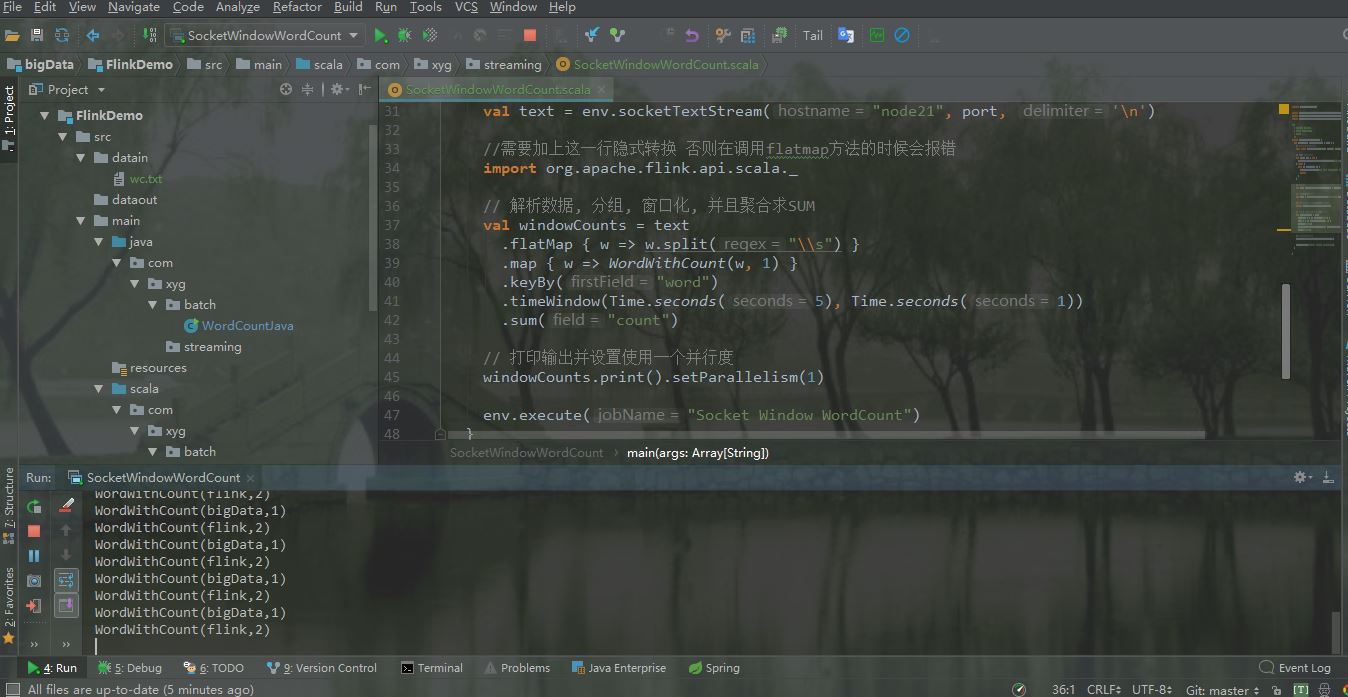
4.集群测试
这里单机测试官方案例
[admin@node21 flink-1.6.1]$ pwd /opt/flink-1.6.1 [admin@node21 flink-1.6.1]$ ./bin/start-cluster.sh Starting cluster. Starting standalonesession daemon on host node21. Starting taskexecutor daemon on host node21. [admin@node21 flink-1.6.1]$ jps StandaloneSessionClusterEntrypoint TaskManagerRunner Jps [admin@node21 flink-1.6.1]$ ./bin/flink run examples/streaming/SocketWindowWordCount.jar --port 9000
程序连接到套接字并等待输入。您可以检查Web界面以验证作业是否按预期运行:


单词在5秒的时间窗口(处理时间,翻滚窗口)中计算并打印到stdout。监视TaskManager的输出文件并写入一些文本nc(输入在点击后逐行发送到Flink):


三.使用IDEA开发离线程序
Dataset是flink的常用程序,数据集通过source进行初始化,例如读取文件或者序列化集合,然后通过transformation(filtering、mapping、joining、grouping)将数据集转成,然后通过sink进行存储,既可以写入hdfs这种分布式文件系统,也可以打印控制台,flink可以有很多种运行方式,如local、flink集群、yarn等.
1. scala程序
package com.xyg.batch
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
/**
* Author: Mr.Deng
* Date: 2018/10/19
* Desc:
*/
object WordCountScala{
def main(args: Array[String]) {
//初始化环境
val env = ExecutionEnvironment.getExecutionEnvironment
//从字符串中加载数据
val text = env.fromElements(
"Who's there?",
"I think I hear them. Stand, ho! Who's there?")
//分割字符串、汇总tuple、按照key进行分组、统计分组后word个数
val counts = text.flatMap { _.toLowerCase.split("\\W+") filter { _.nonEmpty } }
.map { (_, 1) }
.groupBy(0)
.sum(1)
//打印
counts.print()
}
}
2. java程序
package com.xyg.batch;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* Author: Mr.Deng
* Date: 2018/10/19
* Desc:
*/
public class WordCountJava {
public static void main(String[] args) throws Exception {
//构建环境
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//通过字符串构建数据集
DataSet<String> text = env.fromElements(
"Who's there?",
"I think I hear them. Stand, ho! Who's there?");
//分割字符串、按照key进行分组、统计相同的key个数
DataSet<Tuple2<String, Integer>> wordCounts = text
.flatMap(new LineSplitter())
.groupBy(0)
.sum(1);
//打印
wordCounts.print();
}
//分割字符串的方法
public static class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) {
for (String word : line.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
3.运行

到此这篇关于Flink开发IDEA环境搭建与测试的方法的文章就介绍到这了,更多相关Flink IDEA环境搭建 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Java lambda表达式实现Flink WordCount过程解析
这篇文章主要介绍了Java lambda表达式实现Flink WordCount过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 本篇我们将使用Java语言来实现Flink的单词统计. 代码开发 环境准备 导入Flink 1.9 pom依赖 <dependencies> <dependency> <groupId>org.apache.flink</groupId> <artifactId>
-
Flink开发IDEA环境搭建与测试的方法
一.IDEA开发环境 1.pom文件设置 <properties> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <encoding>UTF-8</encoding> <scala.version>2.11.12</scala.version>
-
Spring框架的环境搭建和测试实现
Spring简介 1.什么是Spring spring是分层的JavaSE及JavaEE应用于全栈的轻量级开源框架,以 IoC (Inverse Of Control:控制反转/反转控制)和 AOP (Aspact Oriented Programming:面向切面编程)为核心,提供了表现层SpringMVC和持久层Spring JDBC以及业务层事务管理等众多模块的企业级应用技术,还能整合开源世界中众多著名的第三方框架和类库,逐渐成为使用最多的JavaEE企业应用开源框架. 2.Spring的
-

Koa2微信公众号开发之本地开发调试环境搭建
最近沉迷吃鸡不能自拔,好久没更新文章了.后续将陆续完善<Koa2微信公众号开发>. 一.简介 关于微信公众号的介绍就省略了,自行搜索.注册过程也不说了.我们会直接注册测试号来实现代码.这将会是个全面讲解微信公众号开发的系列教程.本篇是该系列的第一篇,本地开发环境搭建以及接入微信. 在开始之前最好去看看开发者文档微信公众平台技术文档 二.本地开发调试环境搭建 2.1 开发环境 MacOs Node v8.9.1 Koa2 2.2 微信公众平台开发的基本原理 我们先来看看微信公众平台开发的基本原理
-
Vue.js 2.0和Cordova开发webApp环境搭建方法
HTML5开发APP技术文档 一.环境参数 1.技术语言:HTML.CSS.ES6.Node.js等: 2.框架:Vue.js 2.x.Cordova: 3.开发系统:mac.windows等: 4.环境配置: node 6+ npm 3+ (最好下载Node.js官方最新版本) .jdk1.8.SDK(请直接下载Androidstudio软件官方最新版本,已集成AndroidSDk,建议以默认路径安装) . 二.系统环境变量配置(以window7为例) 1.AndroidSDK配置 A)添加用
-
Android NDK开发的环境搭建与简单示例
一.NDK与JNI简介 NDK全称为native development kit本地语言(C&C++)开发包.而对应的是经常接触的Android-SDK,(software development kit)软件开发包(只支持java语言开发). 简单来说利用NDK,可以开发纯C&C++的代码,然后编译成库,让利用Android-SDK开发的Java程序调用.NDK开发的可以称之为底层开发或者jni(java native interface)层开发,SDK开发可以称为上层开发. Andro
-
mac开发android环境搭建步骤图解
1.Java JDK 需要先说明下,OS X系统是自带有Java JDK1.6的.不过这里我安装的是JDK7,下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html.见下图: 下载后,双击安装,如下图: 2.ADT(Android Develop Bundle) 下载地址:http://developer.android.com/sdk/index.html 如下图: 下载成
-
VUE+Element环境搭建与安装的方法步骤
1,安装node,确保安装4.0版本以上,具体的安装可以百度. 2,在命令行创建文件夹 3,安装Vue-cli 输入:cnpm install -g vue-cli , 回车, 等待安装.... 输入:vue ,查看vue相关信息 4,初始化项目 vue init webpack last_demo 然后等一下就会出现相关的信息,再自己去选择安装的一些设置 安装完的时候,你的文件夹就变成了这样了: 如果你的文件夹中没有node_modules的文件,那么你就要在命令行中打开你的项目并输入: np
-
AngularJs入门教程之环境搭建+创建应用示例
本文简单讲述了AngularJs环境搭建+创建应用的方法.分享给大家供大家参考,具体如下: 概述 AngularJS是Google工程师研发的一款JS框架,官方文档中对它的描述是,它是完全使用JavaScript编写的客户端技术,同其他历史悠久的Web技术(HTML,CSS等)配合使用,使得Web开发变得更简单.更高效.它是笔者用过的比较有特色的一款框架,以HTML作为模版语言并扩展HTML属性,使得应用组件开发保持高度的清晰和一致.本系列文章將以实际的案例简单的介绍AngularJs的特性和用
-
java微信公众号开发(搭建本地测试环境)
俗话说,工欲善其事,必先利其器.要做微信公众号开发,两样东西不可少,那就是要有一个用来测试的公众号,还有一个用来调式代码的开发环境. 测试公众号 微信公众号有订阅号.服务号.企业号,在注册的时候看到这样的信息,只有订阅号可以个人申请,服务号和企业号要有企业资质才可以.这里所说的微信公众号开发指的是订阅号和服务号. 另外,未认证的个人订阅号有一些接口是没有权限的,并且目前个人订阅号已不支持微信认证,也就是说个人订阅号无法调用一些高级的权限接口,下图就是一个未认证的个人订阅号所具备权限列表,像生成二
-
详解Angular 开发环境搭建
Angular 是一款开源 JavaScript 框架,由Google 维护,用来协助单一页面应用程序运行的.它的目标是增强基于浏览器的应用,使开发和测试变得更加容易.目前最新的 Angular 版本是 v4.2.3 开始搭建 Angular 开发环境 搭建 Angular 开发环境需要的步骤: Node.js 配置 npm Angular CLI 安装 Node.js 下载安装Node.js,下载最新的 LTS 版本即可,目前最新的版本是 v6.11.0 LTS 配置 npm 安装好 Node