Python字符串常规操作小结
目录
- 一、前言
- 二、拼接字符串
- 三、计算字符串的长度
- 四、截取字符串
- 五、分隔字符串
- 六、检索字符串
- 1.count()方法
- 2.find()方法
- 3.index()方法
- 4.startswith()方法
- 5.endswith()方法
- 七、字母的大小写转换
- 1.lower()方法
- 八、去除字符串中的空格和特殊字符
- 1.strip()方法
- 2.lstrip()方法
- 3.rstrip()方法
- 九、格式化字符串
- 1.使用“ %”操作符
- 2.字符串对象的format() 方法
一、前言
在Python开发的过程中,为了实现某项功能,经常需要对某些字符串进行特殊的处理,如拼接字符串、截取字符串、格式化字符串等。下面将对Python中常用字符串操作方法进行介绍。
二、拼接字符串
在使用“+”运算符可完成对多个字符串的拼接,“+”运算符可以连接多个字符串并产生一个字符串对象。
例如,定义两个字符串,一个保存英文版的名言,另一个用于保存中文版的名言,然后使用“+”运算符进行拼接,代码如下:
mot_en = "Rememberance is a form meeting. Frgetfulness is a form of freedom" mot_cn = "记忆是一个相遇。遗忘是一种自由。" print(mot_en + "-" + mot_cn)
运行结果如下:

字符串不允许与其他类型的数据拼接,例如,使用下面代码,字符串与数值相拼接,将产生异常。
str1 = "今天一共走了" num = 23456 str2 = "步" print(str1 + num + str2)
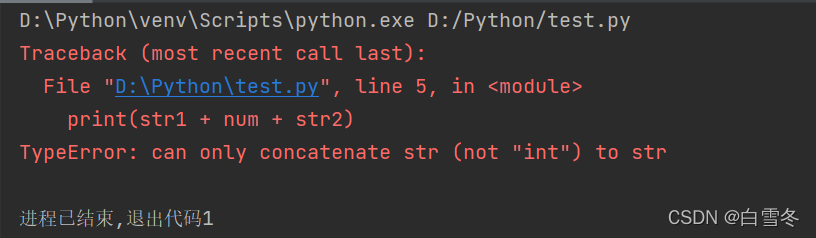
解决该问题,可以将整个数转换为字符串。将正数转换为字符串可以用str()函数。修改后的代码如下:
str1 = "今天一共走了" num = 23456 str2 = "步" print(str1 + str(num) + str2)
运行上面代码,结果如下:

三、计算字符串的长度
由于不同的字符串所占字节不同,所以要计算字符串的长度,需要先了解个字符串所占的字节数。在Python中,数字、英文、小数点、下划线和空格占一个字节;一个汉字可以会占2~4个字节,占几个字节取决于采用的编码。
在Python中,提供了len()函数计算字符串的长度。语法格式如下:
len(str)
其中,string用于指定要统计的字符串。
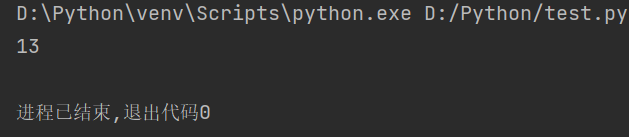
例如:定义一个字符串,内容为“人生苦短,我用Python”,然后用len()函数计算该字符串的长度,代码如下:
str1 = "人生苦短,我用Python" # 定义字符串 string = len(str1) # 计算字符串长度 print(string)
执行上述代码显示为“13”
在实际开发时,有时需要获取字符串所占的字节数,即如果采用UTF-8编码,汉字占3个字节,采用GBK或者GB2312时,汉字占两个字节,可以使用encode()方法进行编码后再进行获取。
str1 = "人生苦短,我用Python" # 定义字符串 string = len(str1.encode()) # 计算UTF-8编码字符串的长度 print(string)
运行代码结果如下:

如果要获取采用GBK编码的字符串的长度,可以使用下列代码:
str1 = "人生苦短,我用Python" # 定义字符串
string = len(str1.encode("gbk")) # 计算GBK编码字符串的长度
print(string)
运行代码结果如下:

四、截取字符串
由于字符串也属于序列,所以要截取字符串,可以采取切片来实现。通过切片的方式截取字符串的语法格式如下:
string[start : end : step]
参数说明:
- string:表示要截取的字符串
- start:表示要截取的第一个字符的索引(包括该字符),如果不指定,则默认为“0”
- end:示要截取的后一个字符的索引(不包括该字符),如果不指定,则默认为字符串的长度
- step:表示切片的步长,如果省略,则默认为“1”,当省略步长时,最后一个冒号可以省略
定义一个字符,然后截取不同长度的子字符,代码如下:
str1 = "人生苦短,我用Python" # 原生字符串
substr1 = str1[1] # 截取第2字符
substr2 = str1[5:] # 从第6字符截取
substr3 = str1[:5] # 从左边数截取5个字符
substr4 = str1[2:5] # 截取第3到第5个字符
print("原生字符串", str1)
print(substr1 + "\n" + substr2 + "\n" + substr3 + "\n" + substr4)
运行结果如下:

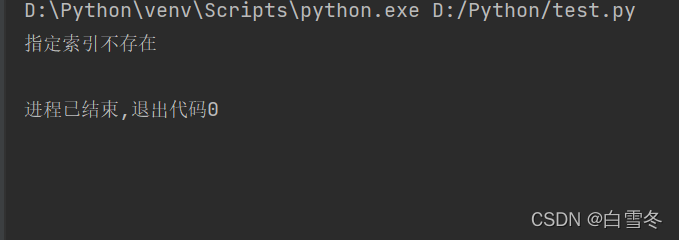
在进行字符串截取的时候,如果指定的索引不存在,则会抛出异常,如下图所示:

要解决该问题,可以使用try…except语句抛出异常,代码如下:
str1 = "人生苦短,我用Python" # 原生字符串
try:
sbustr1 = str1[15]
except IndexError:
print("指定索引不存在")
运行结果如下:
五、分隔字符串
在Python中,字符串对象提供了分隔字符串的方法,分隔字符串是把字符串分隔为列表。
字符串对象的split()方法可以实现分割,split()方法的语法格式如下:
str.split(sep,maxsplit)
参数说明:
- str:表示要进行分割的字符串。
- sep:用于指定分割符,可以包含多个字符,默认为None,即所有空字符(包括空格、换行“\n”、制表符“\t”等)
- maxsplit:可选参数,用于指定分割的次数,如果不指定或者为-1,则分割次数没有限制,否则返回结果列表的元素个数最多为maxsplit+1
- 返回值:分隔后的字符串列表
说明:在split方法中,如果不指定sep参数,那么也不能指定maxsplit参数。
例如:定义一个百度网址的字符串,然后用split()方法根据不同的分隔符进行分割,代码如下:
str1 = "百 度 网 址 >>> https://www.baidu.com/" #
print("原字符串", str1)
list1 = str1.split() # 采用默认分隔符分割
list2 = str1.split(">>>") # 采用多个分隔符分割
list3 = str1.split(".") # 采用“.”进行分割
list4 = str1.split(" ", 4) # 采用空格进行分割,并且只分割前四个
print(str(list1) + "\n" + str(list2) + "\n" + str(list3) + "\n" + str(list4))
运行结果如下:

六、检索字符串
在Python中,字符串对象提供了很多应用于字符串查找的方法,这里主要介绍以下几种:
1.count()方法
检索指定字符串在列外一个字符串中出现的次数检索对象不存在,怎返回0,否则返回出现的次数,其语法如下:
str.count(sub[, start[,end]])
参数说明:
- str:表示原字符串
- sub:表示要检索的子字符串
- start:可选参数,表示检索范围的起始位置的索引,如不指定,默认从头检索
- end:可选参数,表示检索范围的结束位置的索引,如不指定,则检索到结尾。
2.find()方法
该方法用于检索是否包含指定的子字符串,检索对象不存在,怎返回-1,否则返回首次出现的索引值,其语法如下:
str.findt(sub[, start[,end]])
参数说明:
- str:表示原字符串
- sub:表示要检索的子字符串
- start:可选参数,表示检索范围的起始位置的索引,如不指定,默认从头检索
- end:可选参数,表示检索范围的结束位置的索引,如不指定,则检索到结尾。
3.index()方法
index()方法同find()方法类似,也是用于检索是否包含指定的子字符串。只不过使用index()方法,当指定的字符串不存在时,会抛出异常,其语法格式如下:
str.index(sub[, start[,end]])
参数说明:
- str:表示原字符串
- sub:表示要检索的子字符串
- start:可选参数,表示检索范围的起始位置的索引,如不指定,默认从头检索
- end:可选参数,表示检索范围的结束位置的索引,如不指定,则检索到结尾。
4.startswith()方法
该方法用于检索是否指定字符串开头。如果是则返回True,否则返回False。其语法格式如下:
str.startswith(prefix[, start[, end]])
参数说明:
- str:表示原字符串
- prefix:表示要检索的子字符串
- start:可选参数,表示检索范围的起始位置的索引,如不指定,默认从头检索
- end:可选参数,表示检索范围的结束位置的索引,如不指定,则检索到结尾。
5.endswith()方法
该方法用于检索是否指定字符串结尾。如果是则返回True,否则返回False。其语法格式如下:
str.endswith(prefix[, start[, end]])
参数说明:
- str:表示原字符串
- prefix:表示要检索的子字符串
- start:可选参数,表示检索范围的起始位置的索引,如不指定,默认从头检索
- end:可选参数,表示检索范围的结束位置的索引,如不指定,则检索到结尾。
七、字母的大小写转换
在Python中,字符串对象提供了lower()方法和upper()方法进行字母大小写转换。
1.lower()方法
将字符串中大写字母转换为小写,其语法如下:
str.lower()
2.upper()方法
将字符串中小写字母转换为大写,其语法如下:
str.upper()
八、去除字符串中的空格和特殊字符
这里的特殊字符是指制表符“\t”、回车符“\r”、换行符“\n”等。
1.strip()方法
strip()方法用于去除字符串左、右两侧的空格和特殊字符,语法如下:
str.strip([chars])
参数说明:
- str:表示要去除空格字符串
- chars:可选参数,用于指定要去除的字符,可以指定多个,如果设置chars为“@.”,则去除左右侧包括的“@”或“.”,如不知定,则默认去除制表符“\t”、回车符“\r”、换行符“\n”等。
2.lstrip()方法
lstrip()方法用于去除左侧的空格和特殊字符,语法格式如下:
str.lstrip([chars])
参数说明:
- str:表示要去除空格字符串
- chars:可选参数,用于指定要去除的字符,可以指定多个,如果设置chars为“@.”,则去除左侧包括的“@”或“.”,如不知定,则默认去除制表符“\t”、回车符“\r”、换行符“\n”等。
3.rstrip()方法
rstrip()方法用于去除右侧的空格和特殊字符,语法格式如下:
str.rstrip([chars])
参数说明:
- str:表示要去除空格字符串
- chars:可选参数,用于指定要去除的字符,可以指定多个,如果设置chars为“@.”,则去除右侧包括的“@”或“.”,如不知定,则默认去除制表符“\t”、回车符“\r”、换行符“\n”等。
九、格式化字符串
Python 的字符串格式化有两种方式: “% ”操作符方式,字符串对象的format() 方法
1.使用“ %”操作符
【1】 % 格式化方式
%[(name)][flags][width].[precision]typecode
(name): 可选,用于选择指定的key
flags: 可选,可供选择的值有:
+: 右对齐;正数前加正好,负数前加负号;
-: 左对齐;正数前无符号,负数前加负号;
: 右对齐;正数前加空格,负数前加负号;
0: 右对齐;正数前无符号,负数前加负号;用 0 填充空白处
width: 可选,占有宽度
.precision: 可选,小数点后保留的位数
typecode: 必选
s,获取传入对象的 __str__ 方法的返回值,并将其格式化到指定位置
r,获取传入对象的 __repr__ 方法的返回值,并将其格式化到指定位置
c,整数:将数字转换成其 unicode 对应的值,10进制范围为 0 <= i <= 1114111(py27则只支持 0-255);字符:将字符添加到指定位置
o,将整数转换成八进制表示,并将其格式化到指定位置
x,将整数转换成十六进制表示,并将其格式化到指定位置
d,将整数、浮点数转换成十进制表示,并将其格式化到指定位置
e,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(小写 e )
E,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(大写 E )
f,将整数、浮点数转换成浮点数表示,并将其格式化到指定位置(默认保留小数点后6位)
F,同上
g,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是 e;)
G,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是 E;)
%,当字符串中存在格式化标志时,需要用 %% 表示一个百分号
【2】% 格式化方式例子
[[fill]align][sign][#][0][width][,][.precision][type]
fill: 【可选】空白处填充的字符
align:【可选】对齐方式(需配合width使用)
<: 内容左对齐
>: 内容右对齐(默认)
=: 内容右对齐,将符号放置在填充字符的左侧,且只对数字类型有效。 即使:符号 + 填充物 + 数字
^: 内容居中
sign: 【可选】有无符号数字
+: 正号加正,负号加负;
-: 正号不变,负号加负;
空格: 正号空格,负号加负;
#:【可选】对于二进制、八进制、十六进制,如果加上 #,会显示 0b/0o/0x,否则不显示
,: 【可选】为数字添加分隔符,如:1,000,000
width: 【可选】格式化位所占宽度
.precision: 【可选】小数位保留精度
type: 【可选】格式化类型
传入” 字符串类型 “的参数
s: 格式化字符串类型数据
空白: 未指定类型,则默认是 None,同 s
传入“ 整数类型 ”的参数
b: 将十进制整数自动转换成二进制表示然后格式化
c: 将十进制整数自动转换为其对应的 unicode 字符
d: 十进制整数
o: 将十进制整数自动转换成8进制表示然后格式化;
x: 将十进制整数自动转换成16进制表示然后格式化(小写 x )
X: 将十进制整数自动转换成16进制表示然后格式化(大写 X )
传入“ 浮点型或小数类型 ”的参数
e: 转换为科学计数法(小写 e )表示,然后格式化;
E: 转换为科学计数法(大写 E )表示,然后格式化;
f: 转换为浮点型(默认小数点后保留 6 位)表示,然后格式化;
F: 转换为浮点型(默认小数点后保留 6 位)表示,然后格式化;
g: 自动在e和f中切换
G: 自动在E和F中切换
%: 显示百分比(默认显示小数点后 6 位)
2.字符串对象的format() 方法
【1】 format 格式化方式
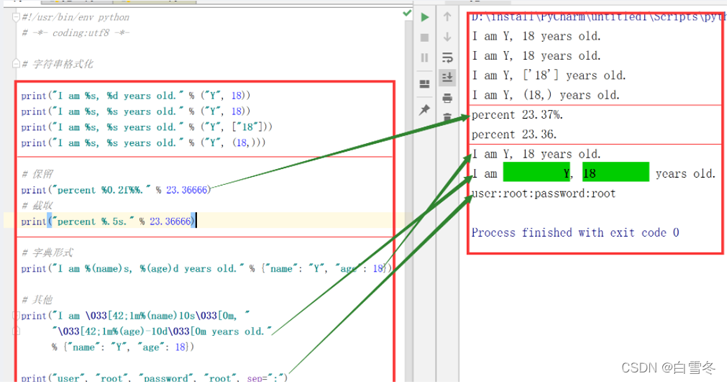
# 字符串格式化
print("I am %s, %d years old." % ("Y", 18))
print("I am %s, %s years old." % ("Y", 18))
print("I am %s, %s years old." % ("Y", ["18"]))
print("I am %s, %s years old." % ("Y", (18,)))
# 保留
print("percent %0.2f%%." % 23.36666)
# 截取
print("percent %.5s." % 23.36666)
# 字典形式
print("I am %(name)s, %(age)d years old." % {"name": "Y", "age": 18})
# 其他
print("I am \033[42;1m%(name)10s\033[0m, "
"\033[42;1m%(age)-10d\033[0m years old."
% {"name": "Y", "age": 18})
print("user", "root", "password", "root", sep=":")
运行结果:
【2】format 格式化方式例子
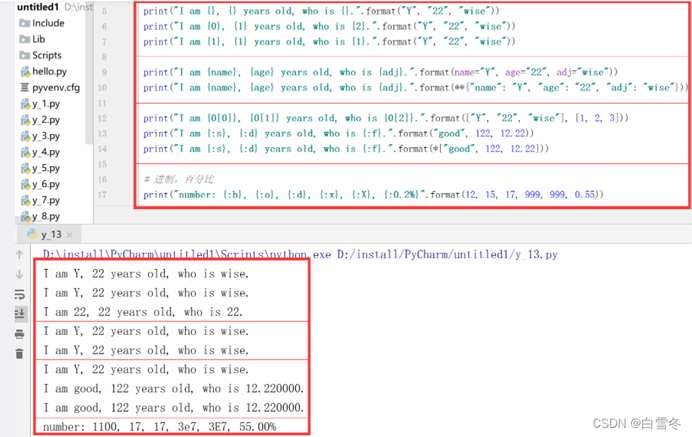
# format 格式
print("I am {}, {} years old, who is {}.".format("Y", "22", "wise"))
print("I am {0}, {1} years old, who is {2}.".format("Y", "22", "wise"))
print("I am {1}, {1} years old, who is {1}.".format("Y", "22", "wise"))
print("I am {name}, {age} years old, who is {adj}.".format(name="Y", age="22", adj="wise"))
print("I am {name}, {age} years old, who is {adj}.".format(**{"name": "Y", "age": "22", "adj": "wise"}))
print("I am {0[0]}, {0[1]} years old, who is {0[2]}.".format(["Y", "22", "wise"], [1, 2, 3]))
print("I am {:s}, {:d} years old, who is {:f}.".format("good", 122, 12.22))
print("I am {:s}, {:d} years old, who is {:f}.".format(*["good", 122, 12.22]))
# 进制,百分比
print("number: {:b}, {:o}, {:d}, {:x}, {:X}, {:0.2%}".format(12, 15, 17, 999, 999, 0.55))
运行结果:
到此这篇关于Python字符串常规操作小结的文章就介绍到这了,更多相关Python字符串操作内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python对字符串实现去重操作的方法示例
前言 最近在工作经常会碰到对字符串进行去重操作,下面就给大家列出用Python如何处理的,话不多说了,来一起看看详细的介绍吧. 比如说,要拿下面的字符传去掉重复的AA, A(B,C) S = 'AA, BB, EE, DD, AA, A(B,C), CC, A(B,C)' 代码如下: 备注: 1. 用str.split(',')只能分隔逗号一种:如果涉及到多重分隔的话就需要使用re.split(',|:') 2. 原字符串以逗号分隔的,后面有一个或多个字符串,所以re.split(', | ')
-
python中字符串的操作方法大全
前言 python中字符串对象提供了很多方法来操作字符串,功能相当丰富. print(dir(str)) [..........'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isdecimal', 'isdigit', 'isidentifier', 'i
-
Python中的字符串查找操作方法总结
基本的字符串位置查找方法 Python 查找字符串使用 变量.find("要查找的内容"[,开始位置,结束位置]),开始位置和结束位置,表示要查找的范围,为空则表示查找所有.查找到后会返回位置,位置从0开始算,如果每找到则返回-1. str = 'a,hello' print str.find('hello') # 在字符串str里查找字符串hello >> 2 # 输出结果 朴素匹配算法 朴素匹配算法是对目标字符串和模板字符串的一一匹配.如果匹配得上,下标向右移一位, 否
-
Python 字符串操作(string替换、删除、截取、复制、连接、比较、查找、包含、大小写转换、分割等)
去空格及特殊符号 s.strip().lstrip().rstrip(',') Python strip() 方法用于移除字符串头尾指定的字符(默认为空格). 复制字符串 #strcpy(sStr1,sStr2) sStr1 = 'strcpy' sStr2 = sStr1 sStr1 = 'strcpy2' print sStr2 连接字符串 #strcat(sStr1,sStr2) sStr1 = 'strcat' sStr2 = 'append' sStr1 += sStr2 print
-
Python中的字符串替换操作示例
字符串的替换(interpolation), 可以使用string.Template, 也可以使用标准字符串的拼接. string.Template标示替换的字符, 使用"$"符号, 或 在字符串内, 使用"${}"; 调用时使用string.substitute(dict)函数. 标准字符串拼接, 使用"%()s"的符号, 调用时, 使用string%dict方法. 两者都可以进行字符的替换. 代码: # -*- coding: utf-8 -
-
Python 字符串操作方法大全
1.去空格及特殊符号 复制代码 代码如下: s.strip().lstrip().rstrip(',') 2.复制字符串 复制代码 代码如下: #strcpy(sStr1,sStr2)sStr1 = 'strcpy'sStr2 = sStr1sStr1 = 'strcpy2'print sStr2 3.连接字符串 复制代码 代码如下: #strcat(sStr1,sStr2)sStr1 = 'strcat'sStr2 = 'append'sStr1 += sStr2print sStr1 4.查
-
Python中拆分字符串的操作方法
使用字符串时,常见的操作之一是使用给定的分隔符将字符串拆分为子字符串数组.在本文中,我们将讨论如何在Python中拆分字符串. .split()方法 在Python中,字符串表示为不可变的str对象. str类带有许多字符串方法,允许您操作字符串. .split()方法返回由分隔符分隔的子字符串列表. 它采用以下语法: str.split(delim=None, maxsplit=-1) 分隔符可以是字符或字符序列,而不是正则表达式. 在下面的示例中,字符串s将使用逗号分隔,作为分隔符. s =
-
python字符串的常用操作方法小结
本文实例为大家分享了python字符串的操作方法,供大家参考,具体内容如下 1.去除空格 str.strip():删除字符串两边的指定字符,括号的写入指定字符,默认为空格 >>> a=' hello ' >>> b=a.strip() >>> print(b) hello str.lstrip():删除字符串左边的指定字符,括号的写入指定字符,默认为空格 >>> a=' hello ' >>> b=a.lstrip(
-
Python字符串常规操作小结
目录 一.前言 二.拼接字符串 三.计算字符串的长度 四.截取字符串 五.分隔字符串 六.检索字符串 1.count()方法 2.find()方法 3.index()方法 4.startswith()方法 5.endswith()方法 七.字母的大小写转换 1.lower()方法 八.去除字符串中的空格和特殊字符 1.strip()方法 2.lstrip()方法 3.rstrip()方法 九.格式化字符串 1.使用“ %”操作符 2.字符串对象的format() 方法 一.前言 在Python开
-
python字符串常规操作大全
拼接字符串 使用"+"运算符可完成对多个字符串的拼接,"+"运算符可以连接多个字符串并产生一个字符串对象. 字符串不允许直接与其他类型数据拼接. 如果要用来和其他类型拼接,先用str()函数转换成字符串类型. str1 = 'Hello World' str2 = '你好,世界' print(str1+str2) num = 2021 print(str1+str2+str(num)) 计算字符串长度 由于不同的字符所占字节数不同,所以要计算字符串长度,需先了解字符
-
python文件读写操作小结
目录 读文件 写文件 关于open()的mode参数: file_obj.seek(offset,whence=0) 字符编码 读文件 打开一个文件用open()方法(open()返回一个文件对象,它是可迭代的): >>> f = open('test.txt', 'r') r表示是文本文件,rb是二进制文件.(这个mode参数默认值就是r) 如果文件不存在,open()函数就会抛出一个IOError的错误,并且给出错误码和详细的信息告诉你文件不存在: >>> f=op
-
JavaScript 字符串常用操作小结(非常实用)
字符串截取 1. substring() xString.substring(start,end) substring()是最常用到的字符串截取方法,它可以接收两个参数(参数不能为负值),分别是要截取的开始位置和结束位置,它将返回一个新的字符串,其内容是从start处到end-1处的所有字符.若结束参数(end)省略,则表示从start位置一直截取到最后. let str = 'www.jeffjade.com' console.log(str.substring(0,3)) // www co
-
python图像常规操作
使用python进行基本的图像操作与处理 前言: 与早期计算机视觉领域多数程序都是由 C/C++ 写就的情形不同.随着计算机硬件速度越来越快,研究者在考虑选择实现算法语言的时候会更多地考虑编写代码的效率和易用性,而不是像早年那样把算法的执行效率放在首位.这直接导致近年来越来越多的研究者选择 Python 来实现算法. 今天在计算机视觉领域,越来越多的研究者使用 Python 开展研究,所以有必要去学习一下十分易用的python在图像处理领域的使用,这篇博客将会介绍如何使用Python的几个著名的
-
Python字符串切片操作知识详解
一:取字符串中第几个字符 print "Hello"[0] 表示输出字符串中第一个字符 print "Hello"[-1] 表示输出字符串中最后一个字符 二:字符串分割 print "Hello"[1:3] #第一个参数表示原来字符串中的下表 #第二个阐述表示分割后剩下的字符串的第一个字符 在 原来字符串中的下标 这句话说得有点啰嗦,直接看输出结果: el 三:几种特殊情况 (1)print "Hello"[:3] 从第一个字
-
python字符串基础操作详解
目录 字符串的赋值 单引号字符串赋值给变量 双引号字符串赋值给变量 三引号字符串赋值给变量(多行) 字符串的截取 截取指定位置的字符 获取指定位置之后的所有字符 截取指定位置之前的所有字符 获取所有的字符 获取指定倒数位置的字符,用[-]来进行表示 获取指定位置倒数之前的字符 获取两个位置之间的字符 字符串的基础使用方法 strip() lstrip() rstrip() lower() upper() capitalize() title() index() rindex() split()
-
Python字符串的常见操作实例小结
本文实例讲述了Python字符串的常见操作.分享给大家供大家参考,具体如下: 如果我们想要查看以下功能:help(mystr .find) 1.find 例: mystr="hello world itcast" print(mystr.find("world")) 结果为 6 find括号中填写要查找的内容,如果找不到返回-1,找到返回从左往右找到的第一个位置 2.index 功能和find一样,只是找不到时,这个返回错误 3.rfind 从右往左找的第一个位置
-
10个有用的Python字符串函数小结
目录 前言 一.capitalize() 函数 二.lower( ) 函数 三.title( ) 函数 四.casefold() 函数 五.upper( ) 函数 六.count( ) 函数 七.find( ) 函数 八.replace() 函数 九.swapcase( ) 函数 十.join () 函数 前言 Python 字符串是一个内置的类型序列.字符串可用于处理 Python 中的文本数据.Python 字符串是 Unicode 点的不可变序列.在 Python 中创建字符串是最简单易用
-
Python中关于列表的常规操作范例以及介绍
目录 1.列表的介绍 2.打印出列表的数据 1.我们可以根据下标取值进行打印 2.使用for循环遍历 3.使用while循环遍历 3.列表的添加操作 1.append()方法 2.extend()方法 3.insert()方法 4.列表的修改操作 5.列表的查找操作 1.in 方法 2.not in 方法 3.index 方法 4.count 方法 6.列表中的删除操作 1.del 方法 2.pop 方法 3.remove 方法 7.列表的排序操作 8.小练习送给你们 (一) (二) 1.列表的