OpenCV停车场车位实时检测项目实践
目录
- 1. 写在前面
- 2. 整体流程梳理
- 3. 数据预处理
- 3.1 背景过滤
- 3.2 Canny边缘检测
- 3.3 停车场区域提取
- 3.4 霍夫变换检测直线
- 3.5 以列为单位,划分停车位
- 3.6 锁定每个停车位
- 3.7 为CNN生成预测图片
- 4. 模型的训练和预测
- 4.1 模型训练
- 4.2 模型预测
- 5. 小结
1. 写在前面
今天整理OpenCV入门的第三个实战小项目,前面的两篇文章整理了信用卡数字识别以及文档OCR扫描, 大部分用到的是OpenCV里面的基础图像预处理技术,比如轮廓检测,边缘检测,形态学操作,透视变换等, 而这篇文章的项目呢,不仅需要一些基础的图像预处理,还需要搭建模型进行识别和预测,所以通过这个项目,能把图像预处理以及建模型等一整套流程拉起来,并应用到实际的应用场景,还是非常有意思的。
停车场车位实时检测任务,是拿到停车场的一段视频video,主要完成两件事情:
- 检测整个停车场当中,当前一共有多少辆车,一共有多少个空余的车位
- 把空余的停车位标识出来,这样用户停车的时候,就可以直接去空余的停车位处, 为停车节省了很多时间
所以这个项目还是非常有实践应用价值的,用了大约一天半的时间搞定这个项目,参考的是唐老师的OpenCV入门教程视频, 不过这里面对于这个任务做的相对粗糙,我在这个基础上基于我的理解进行了一些优化,主要改动如下:
- 据处理方面,按列框出停车位之后,我对每一列框的坐标手工进行了调整,确保每个停车位不遗漏,不多余, 然后是对每个停车位的坐标位置进行了微调,尽量让其标记的准一些
- 模型方面,原视频采用迁移学习方式,基于keras对VGG网络进行的微调,而我模型这里统一基于pytorch,用的ResNet32预训练模型进行的finetune,验证集正确率能到0.94多,但第一版还是有少量预测的不是很准,所以又基于已有的帧图片做了数据增强,额外增加了一些数据,把准确率提升到0.98左右
- 项目的整体架构全部改变,算是听懂了上面的思想,然后基于自己的理解进行的重构,好处是后面可以进行各种优化,按照自己需求做数据增强,数据预处理以及训练各种高级模型等。
不过,发现小resnet就够强大的了,最终的预测效果如下:

这是视频中的某一帧图像,实际运行的时候,是读入视频,快速分开帧,每一帧做出这样的预测标记,然后实时显示。这样在每个时刻,都能动态的知道该停车场有哪些车位空了出来。
下面就对这个项目中用到的关键技术进行整理,由于这个项目稍微大一些,代码量多,不可能在这里全部展示,但想记录下对于这个项目我的思考过程,以及各种处理的动机,以及如何进行的处理,我觉得这个才是对以后有用的东西。
2. 整体流程梳理
首先,拿到这个任务之后, 得大致上梳理下流程,才能确定行动方案。 我们开始拿到了这样的一段视频,那么为了完成上面停车位检测以及识别的任务,就需要考虑两步:
- 我得先把停车场的每个停车位给提取出来
- 有了每个停车位,我训练一个模型,去预测这个停车位上有没有车就行啦,把没有车的标识出来,然后统计个数
其实宏观上就这么两大步。那么后面的问题就是怎么把每个车位提取出来,又怎么训练模型预测呢?
我这里主要分为了两大步, 数据预处理以及模型的训练及预测:
数据预处理方面
- 以视频中某一帧的图像为单位,进行处理
- 通过二值化,灰度化,边缘检测,特定点标定连线等,把图片中多余的部分去掉,只保留停车场内的这部分对象
- 霍夫变换的直线检测,去找图片中的直线,根据直线坐标,先按列为单位,把车位按列框起来, 然后对框手动微调
- 在每一列中,锁定每个停车位的位置,并对每个停车位进行标号,把这个保存成字典
- 有了每个停车位的位置,就能提取出对应图片,可以作为后面模型的训练以及验证的数据集,不过需要人工手动划分
通过上面步骤,会积累一些数据,大约800多张图片,接下来就可以训练模型,但是由于数据量太少,从头训练模型往往效果不好,所以这里采用迁移学习的方式,使用了预训练的resnet34,用这800多张图片微调。
训练好了模型保存,接下来,对于每一帧图像,有了停车位位置字典,就能直接提取出每一个停车位,然后对于这每个停车位,模型预测有没有车即可
所以有了这样的一个流程,就能再进一步分解细化,就可以大处着眼小处着手啦,下面整理每一步里面的关键细节。
3. 数据预处理
3.1 背景过滤
首先,把一帧图像读入进来,原始图像如下:

先通过二值化的方式过滤掉背景,突出重要信息,然后转成灰度图。
def select_rgb_white_yellow(image):
# 过滤背景
lower = np.uint8([120, 120, 120])
upper = np.uint8([255, 255, 255])
# 三个通道内,低于lower和高于upper的部分分别变成0, 在lower-upper之间的值变成255, 相当于mask,过滤背景
# 保留了像素值在120-255之间的像素值
white_mask = cv2.inRange(image, lower, upper)
masked_img = cv2.bitwise_and(image, image, mask=white_mask)
return masked_img
masked_img = select_rgb_white_yellow(test_image)
这里看到inRange(),想到了之前用到的二值化的方法threshold, 我在想这俩有啥区别? 为啥这里不用这个了? 下面是我经过探索得到的几点使用经验:
cv2.threshold(src, thresh, maxval, type[, dst]):针对的是单通道图像(灰度图), 二值化的标准,type=THRESH_BINARY: if x > thresh, x = maxval, else x = 0, 而type=THRESH_BINARY_INV: 和上面的标准反着,目前常用到了这俩个cv2.inRange(src, lowerb, upperb):可以是单通道图像,可以是三通道图像,也可以进行二值化,标准是if x >= lower and x <= upper, x = 255, else x = 0
这里做了一个实验, 事先把图片转化成灰度图warped = cv2.cvtColor(test_image, cv2.COLOR_BGR2GRAY),然后下面两句代码的执行结果是一样的:
cv2.threshold(warped, 119, 255, cv2.THRESH_BINARY)[1]cv2.inRange(warped, 120, 255)
处理之后的图片长这样:

3.2 Canny边缘检测
接下来,采用Canny边缘检测算法,检测出边缘来
low_threshold, high_threshold = 50, 200 edges_img = cv2.Canny(gray_img, low_threshold, high_threshold)
结果如下:

下面尝试把停车场这块提取出来, 把其余那些没用的去掉。
3.3 停车场区域提取
这里的思路就是,先用6个标定点把停车场的这几个角给他定住,这个标定点得需要自己找。 找到之后, 采用OpenCV中的填充函数,就能制作一个mask矩阵,然后就能把其余部分去掉了。
def select_region(image):
"""这里手动选择区域"""
rows, cols = image.shape[:2]
# 下面定义6个标定点, 这个点的顺序必须让它化成一个区域,如果调整,可能会交叉起来,所以不要动
pt_1 = [cols*0.06, rows*0.90] # 左下
pt_2 = [cols*0.06, rows*0.70] # 左上
pt_3 = [cols*0.32, rows*0.51] # 中左
pt_4 = [cols*0.6, rows*0.1] # 中右
pt_5 = [cols*0.90, rows*0.1] # 右上
pt_6 = [cols*0.90, rows*0.90] # 右下
vertices = np.array([[pt_1, pt_2, pt_3, pt_4, pt_5, pt_6]], dtype=np.int32)
point_img = image.copy()
point_img = cv2.cvtColor(point_img, cv2.COLOR_GRAY2BGR)
for point in vertices[0]:
cv2.circle(point_img, (point[0], point[1]), 10, (0, 0, 255), 4)
# cv_imshow('points_img', point_img)
# 定义mask矩阵, 只保留点内部的区域
mask = np.zeros_like(image)
if len(mask.shape) == 2:
cv2.fillPoly(mask, vertices, 255) # 点框住的地方填充为白色
#cv_imshow('mask', mask)
roi_image = cv2.bitwise_and(image, mask)
return roi_image
roi_image = select_region(edges_img)
处理的效果如下:

这样处理好了,我们就需要找到这里面的直线,然后通过直线去猜测大致的位置。
3.4 霍夫变换检测直线
这里采用霍夫变换检测直线, 函数是cv2.HoughLinesP, 该函数能检测直线的两个端点(x0,y0, x1, y1)。函数原型:
HoughLinesP(image, rho, theta, threshold[, lines[, minLineLength[, maxLineGap]]]) -> lines
- image: 边缘检测的输出图像,这里要注意必须是边缘检测的输出图像
- rho: 参数极径r以像素值为单位的分辨率,一般1
- threa: 以弧度为单位的分辨率,一般1
- threshold: 检测一条直线所需最少的曲线交点
- minLineLength: 能形成一条直线的最小长度,太短,不认为是一条直线
- maxLineGap: 两条直线直接最大间隔,小于这个值,认为是一条直线
所以,这个函数拿来直接用。
def hough_lines(image):
# 输入的图像需要是边缘检测后的结果
# minLineLengh(线的最短长度,比这个短的都被忽略)和MaxLineCap(两条直线之间的最大间隔,小于此值,认为是一条直线)
# rho距离精度,theta角度精度,threshod超过设定阈值才被检测出线段
return cv2.HoughLinesP(image, rho=0.1, theta=np.pi/10, threshold=15, minLineLength=9, maxLineGap=4)
list_of_lines = hough_lines(roi_image) # (2338, 1, 4)
竟然检测到了2338条直线,这里面肯定有很多不能用的,所以后面处理,需要对直线先进行一波筛选。筛选原则是线不能是斜的,且水平方向不能太长或者是太短。 具体代码下面会看到,这里先展示下过滤之后的效果。

过滤完了,总共628条直线。
3.5 以列为单位,划分停车位
下面的代码会稍微复杂,所以需要分块讲思路。
首先,我们拿到了停车场的直线以及它的坐标位置。 过滤操作已经做好,接下来,就是对每条直线进行排序。 让这些线,从一列一列的,从上往下依次排列好。
def identity_blocks(image, lines, make_copy=True):
if make_copy:
new_image = image.copy()
# 过滤部分直线
stayed_lines = []
for line in lines:
for x1, y1, x2, y2 in line:
# 这里是过滤直线,必须保证不能是斜的线,且水平方向不能太长或者太短
if abs(y2-y1) <=1 and abs(x2-x1) >=25 and abs(x2-x1) <= 55:
stayed_lines.append((x1,y1,x2,y2))
# 对直线按照x1排序, 这样能让这些线从上到下排列好, 这个排序是从第一列的第一条横线,往下走,然后是第二列第一条横线往下,...
list1 = sorted(stayed_lines, key=operator.itemgetter(0, 1))
排列好之后,遍历所有线, 看看相邻两条线之间的距离,如果是一列, 那么两条线的x_1应该离得非常近,毕竟是同一列,如果这个值太大了,说明是下一列了。根据这个准则,遍历完之后,就能把这些线划分到不同的列里面。这里是用了一个字典,键表示列,值表示每一列里面的直线。
代码接上:
# 找到多个列,相当于每列是一排车
clusters = collections.defaultdict(list)
dIndex = 0
clus_dist = 10 # 每一列之间的那个距离
for i in range(len(list1) - 1):
# 看看相邻两条线之间的距离,如果是一列的,那么x1这个距离应该很近,毕竟是同一列上的
# 如果这个值大于10了,说明是下一列的了,此时需要移动dIndex, 这个表示的是第几列
distance = abs(list1[i+1][0] - list1[i][0])
if distance <= clus_dist:
clusters[dIndex].append(list1[i])
clusters[dIndex].append(list1[i+1])
else:
dIndex += 1
有了每一列里面的直线,下面就是就是遍历每一列,先拿到所有直线,然后找到纵坐标的最大值和最小值,以及横坐标的最大和最小值,但由于横坐标这里,首尾列都一排车位,中间排都是两列,不好直接取到最大最小坐标,所以这里采用了求平均的方式。 这样遍历完,针对每一列,就能得到左上角点和右下角点,这是一个矩形框。
代码接上:
# 得到每列停车位的矩形框
rects = {}
i = 0
for key in clusters:
all_list = clusters[key]
cleaned = list(set(all_list))
# 有5个停车位至少
if len(cleaned) > 5:
cleaned = sorted(cleaned, key=lambda tup: tup[1])
avg_y1 = cleaned[0][1]
avg_y2 = cleaned[-1][1]
if abs(avg_y2-avg_y1) < 15:
continue
avg_x1 = 0
avg_x2 = 0
for tup in cleaned:
avg_x1 += tup[0]
avg_x2 += tup[2]
avg_x1 = avg_x1 / len(cleaned)
avg_x2 = avg_x2 / len(cleaned)
rects[i] = [avg_x1, avg_y1, avg_x2, avg_y2]
i += 1
print('Num Parking Lanes: ', len(rects))
下面,把矩形框画出来:
# 把列矩形画出来
buff = 7
for key in rects:
tup_topLeft = (int(rects[key][0] - buff), int(rects[key][1]))
tup_botRight = (int(rects[key][2] + buff), int(rects[key][3]))
cv2.rectangle(new_image, tup_topLeft, tup_botRight, (0, 255, 0), 3)
return new_image, rects
这里的buff,也是进行了一点微调操作。 这种是根据实际场景来的,不是死的。 效果如下:

这样就会发现,对于每一列的停车位,有了大致上的矩形框标定,但是这个非常粗糙。 原视频里面就基于这个往后面走了。 我这里对于每一列框进行微调,因为这个框非常重要。不准的话影响后面的具体车位划分。
def rect_finetune(image, rects, copy_img=True):
if copy_img:
image_copy = image.copy()
# 下面需要对上面的框进行坐标微调, 让框更加准确
# 这个框很重要,影响后面停车位的统计,尽量不能有遗漏
for k in rects:
if k == 0:
rects[k][1] -= 10
elif k == 1:
rects[k][1] -= 10
rects[k][3] -= 10
elif k == 2 or k == 3 or k == 5:
rects[k][1] -= 4
rects[k][3] += 13
elif k == 6 or k == 8:
rects[k][1] -= 18
rects[k][3] += 12
elif k == 9:
rects[k][1] += 10
rects[k][3] += 10
elif k == 10:
rects[k][1] += 45
elif k == 11:
rects[k][3] += 45
buff = 8
for key in rects:
tup_topLeft = (int(rects[key][0]-buff), int(rects[key][1]))
tup_botRight = (int(rects[key][2]+buff), int(rects[key][3]))
cv2.rectangle(image_copy, tup_topLeft, tup_botRight, (0, 255, 0), 3)
return image_copy, rects
微调之后的效果如下:
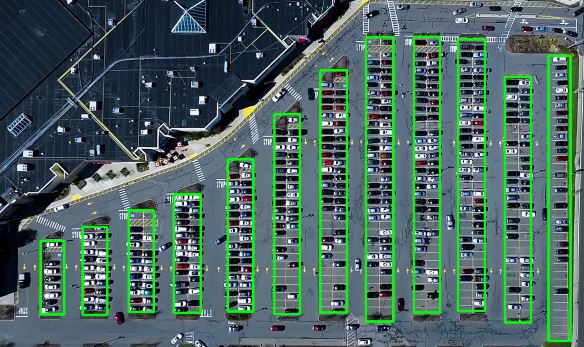
原则就是不遗漏,不多余。
3.6 锁定每个停车位
这里就是针对每个矩形框, 对里面的停车位用直线切割成一个个的,每个停车位用(x1,y1,x2,y2)标识,左上角和右下角的坐标。并进行标号,最终形成一个字典,字典的键就是位置,值就是序号。当然,这里的一个细节,依然是中间排是两排,首尾是一排,这个在具体划分停车位的时候,一定要注意。
def draw_parking(image, rects, make_copy=True, save=True):
gap = 15.5
spot_dict = {} # 一个车位对应一个位置
tot_spots = 0
#微调
adj_x1 = {0: -8, 1:-15, 2:-15, 3:-15, 4:-15, 5:-15, 6:-15, 7:-15, 8:-10, 9:-10, 10:-10, 11:0}
adj_x2 = {0: 0, 1: 15, 2:15, 3:15, 4:15, 5:15, 6:15, 7:15, 8:10, 9:10, 10:10, 11:0}
fine_tune_y = {0: 4, 1: -2, 2: 3, 3: 1, 4: -3, 5: 1, 6: 5, 7: -3, 8: 0, 9: 5, 10: 4, 11: 0}
for key in rects:
tup = rects[key]
x1 = int(tup[0] + adj_x1[key])
x2 = int(tup[2] + adj_x2[key])
y1 = int(tup[1])
y2 = int(tup[3])
cv2.rectangle(new_image, (x1, y1),(x2,y2),(0,255,0),2)
num_splits = int(abs(y2-y1)//gap)
for i in range(0, num_splits+1):
y = int(y1+i*gap) + fine_tune_y[key]
cv2.line(new_image, (x1, y), (x2, y), (255, 0, 0), 2)
if key > 0 and key < len(rects) - 1:
# 竖直线
x = int((x1+x2) / 2)
cv2.line(new_image, (x, y), (x, y2), (0, 0, 255), 2)
# 计算数量 除了第一列和最后一列,中间的都是两列的
if key == 0 or key == len(rects) - 1:
tot_spots += num_splits + 1
else:
tot_spots += 2 * (num_splits + 1)
# 字典对应好
if key == 0 or key == len(rects) - 1:
for i in range(0, num_splits+1):
cur_len = len(spot_dict)
y = int(y1 + i * gap) + fine_tune_y[key]
spot_dict[(x1, y, x2, y+gap)] = cur_len + 1
else:
for i in range(0, num_splits+1):
cur_len = len(spot_dict)
y = int(y1 + i * gap) + fine_tune_y[key]
x = int((x1+x2) / 2)
spot_dict[(x1, y, x, y+gap)] = cur_len + 1
spot_dict[(x, y, x2, y+gap)] = cur_len + 2
return new_image, spot_dict
这里的fine_tune_y也是我后来加上去的,也是为了让每一列尽量把车位划分的准确些。

从这个效果上来看,基本上就把车位一个个的划分开了,划分开之后,会发现,这里面有些并不是车位, 但依然给框住了。这样统计个数的时候,以及后面给信息停车的时候会受到影响,所以我这里又一一排查,去掉了这些无效的车位。
# 去掉多余的停车位
invalid_spots = [10, 11, 33, 34, 37, 38, 61, 62, 93, 94, 95, 97, 98, 135, 137, 138, 187, 249,
250, 253, 254, 323, 324, 327, 328, 467, 468, 531, 532]
valid_spots_dict = {}
cur_idx = 1
for k, v in spot_dict.items():
if v in invalid_spots:
continue
valid_spots_dict[k] = cur_idx
cur_idx += 1
这样,还可以把处理好的车位信息进行可视化,再进行微调,不过,我这里由于之前的一些微调操作,感觉效果还可以,就没有做任何调整啦。
# 把每一个有效停车位标记出来
tmp_img = test_image.copy()
for k, v in valid_spots_dict.items():
cv2.rectangle(tmp_img, (int(k[0]), int(k[1])),(int(k[2]),int(k[3])), (0,255,0) , 2)
cv_imshow('valid_pot', tmp_img)
效果如下:
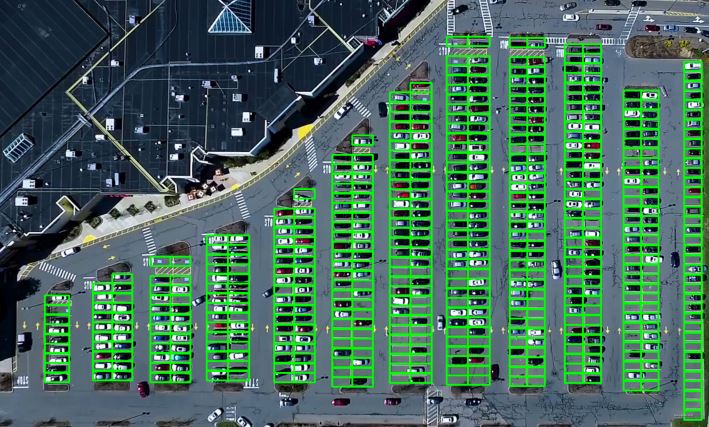
如果要想让后面模型对于每个车位预测的更加准确,这里的划分一定要尽量的细致和标准。 否则如果矩形框和真实的车位对应不上,比如矩形框卡在了两个车位中间这种,这样划分出的车位拿给模型看,就很容易判断出错。
另外,最终的这个字典很重要,因为这个字典里面保存的是各个车位的位置信息。 有了这个东西,拿到一帧图片,就可以直接把每个车位标定出来,拿给模型预测。 并且对于同一停车场,这个每个车位是固定的。所以这个也不会变,视频的所有图像共用。 这样能保证实时性。
3.7 为CNN生成预测图片
有了各个车位的具体位置信息,下面直接按照这里面的左边把每个车位切割出来,就能得到后面CNN的训练和验证的数据集了。
def save_images_for_cnn(image, spot_dict, folder_name = '../cnn_pred_data'):
for spot in spot_dict.keys():
(x1, y1, x2, y2) = spot
(x1, y1, x2, y2) = (int(x1), int(y1), int(x2), int(y2))
# 裁剪
spot_img = image[y1:y2, x1:x2]
spot_img = cv2.resize(spot_img, (0, 0), fx=2.0, fy=2.0)
spot_id = spot_dict[spot]
filename = 'spot_{}.jpg'.format(str(spot_id))
# print(spot_img.shape, filename, (x1,x2,y1,y2))
cv2.imwrite(os.path.join(folder_name, filename), spot_img)
save_images_for_cnn(test_image, valid_spots_dict)
这样,就把模型的训练数据集准备好。 在文件中组织成这个样子:
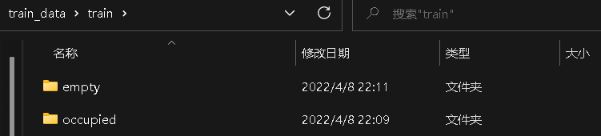
每个目录里面,就是划分出来的一张张小的车位图像,不过这里是人为划分到了有车还是无车里面。所以后面的模型其实做一个二分类任务,给定这样一张车位的小图像,预测下是不是空的即可。
下面开始说模型的细节。
4. 模型的训练和预测
由于目前的样本非常少,不足以训练一个大模型到收敛,所以这里采用的迁移学习技术,用的预训练模型。
模型这里和视频中不一样的是,我统一采用pytorch写的模型训练和测试代码,原因是最近正在尝试pytorch复现cv里面的各个经典网络,这个项目正好让我拿来练手。另外一个就是感觉keras搭建的灵活度不够,在数据预处理方面不如torchvision里面transforms用起来方便。 基于这两个原因, 我这里直接用pytorch,采用的resnet34预训练模型,使用这个的原因是这两天正好把resnet复现了一遍,稍微熟悉了一点罢了,正好能学以致用,没有啥偏爱。
由于这里的代码非常多,这里就不过多罗列了,简单说下逻辑即可,感兴趣的可以看具体项目。
首先是训练模型。
4.1 模型训练
这个整体逻辑倒是可以看下:
def train_model():
# 获取dataloader
data_root = os.getcwd()
image_path = os.path.join(data_root, "train_data")
train_data_path = os.path.join(image_path, "train")
val_data_path = os.path.join(image_path, "test")
train_loader, validat_loader, train_num, val_num = get_dataloader(train_data_path, val_data_path,
data_transform_pretrain, batch_size=8)
# 创建模型 注意这里没指定类的个数,默认是1000类
net = resnet34()
model_weight_path = 'saved_model_weight/resnet34_pretrain_ori_low_torch_version.pth'
# 使用预训练的参数,然后进行finetune
net.load_state_dict(torch.load(model_weight_path, map_location='cpu'))
# 改变fc layer structure 把fc的输出维度改为2
in_channel = net.fc.in_features
net.fc = nn.Linear(in_channel, 2)
net.to(device)
# 模型训练配置
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0001)
epochs = 30
save_path = "saved_model_weight/resnet34_pretrain.pth"
best_acc = 0.
train_steps = len(train_loader)
model_train(net, train_loader, validat_loader, epochs, device, optimizer, loss_function, train_steps, val_num,
save_path, best_acc)
因为我这里采用了一些函数封装,所以这个逻辑应该稍微清晰些,首先pytorch模型训练,要先把数据封装成dataloader的格式,后面模型训练的时候,是从这个类里面读取数据。关于dataloader与dataset的原理这里就不过多整理。之前我详细在pytorch基础那里整理过了。
不过这里的细节,就是data_transform_pretrain, 也就是数据预处理操作。
data_transform_pretrain = {
"train": transforms.Compose([
transforms.RandomResizedCrop(224), # 对图像随机裁剪, 训练集用,验证集不用
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
# 这里的中心化处理参数需要官方给定的参数,这里是ImageNet图片的各个通道的均值和方差,不能随意指定了
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
]),
"val": transforms.Compose([
# 验证过程中,这里也进行了一点点改动
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
]),
"test": transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
}
这里由于是采用的官方训练好的resnet网络,我们这里中心化要参考官方给定的参数,因为它预训练是ImageNet这个大数据集上训练的,所以这里每个通道的均值和方差,我们最好别随意指定。用人家官方给出的。
有了dataloader,接下来创建模型, 这里是直接使用的resnet34, 把预训练的模型参数导入进来。导入的时候,会发现我这个参数名字的文件有个low_torch_version, 是因为之前导入的时候出现了报错:
xxx.pt is a zip archive(did you mean to use torch.jit.load()?)“
这个报错的原因是,官方预训练保存的模型参数使用的pytorch版本是1.6以上,PyTorch的1.6版本将torch.save切换为使用新的基于zipfile的文件格式。
torch.load仍然保留以旧格式加载文件的功能。 如果希望torch.save使用旧格式,请传递kwarg _use_new_zipfile_serialization = False。
我电脑本子的pytorch版本是1.0,所以导入1.6以上版本保存的模型参数,就会报这样的错误。 那么,我怎么解决的呢? 那就是从我服务器上,运行了下面这个代码
model_weight_path = "saved_models/resnet34_pretrain_ori.pth"
state_dict = torch.load(model_weight_path)
torch.save(state_dict, 'saved_models/resnet34_pretrain_ori_low_torch_version.pth', _use_new_zipfile_serialization=False)
我服务器上的pytorch版本是1.10的版本,是能导入这个参数的,导入完了重新保存,指定官方给定的参数即可。
这个问题解决之后,下面就说下预训练模型了, 导入参数之后,我们需要修改网络最后的一层,因为resnet本身做的是1000分类,最后一层神经元个数是1000,我们这里需要做二分类,所以需要改成2。
另外,就是迁移学习的三种方式:
- 载入权重后重新训练所有参数 – 硬件设施好
- 载入权重后只训练最后几层参数,前面的层进行冻结, 或者是前面几层的学习率降低, 后面全连接层的学习率变大,即分组调整学习率
- 载入全中后在原网络基础上再添加一层全连接层, 仅训练最后一个全连接层
我这里采用的全部训练的方式,但是这里有必要整理下,如果是想只训练后面几层,或者前面层和后面层不同学习率训练的时候,应该怎么做:
# 创建模型 注意这里没指定类的个数,默认是1000类
net = resnet34()
model_weight_path = 'saved_model_weight/resnet34_pretrain_ori_low_torch_version.pth'
# 使用预训练的参数,然后进行finetune
net.load_state_dict(torch.load(model_weight_path, map_location='cpu'))
# 改变fc layer structure 把fc的输出维度改为2
in_channel = net.fc.in_features
net.fc = nn.Linear(in_channel, 2)
net.to(device)
# 模型训练配置
loss_function = nn.CrossEntropyLoss()
# 训练的时候,也可以冻结掉卷积层的参数, 也可以指定不同层的参数使用不同的学习率进行训练
res_params, conv_params, fc_params = [], [], []
# named_parameters()能返回每一层的名字以及参数,是一个字典
for name, param in net.named_parameters():
# layer 系列是残差层
if ('layer' in name):
res_params.append(param)
# 全连接层
elif ('fc' in name):
fc_params.append(param)
else:
param.requires_grad = False
params = [
{'params': res_params, 'lr': 0.0001},
{'params': fc_params, 'lr': 0.0002},
]
optimizer = optim.Adam(params)
这里修改优化器的参数即可。
这样完事之后,调用模型训练的函数,直接进行训练即可。这个脚本就是常规操作了,这里就不贴代码了。
4.2 模型预测
有了保存好的模型, 我们拿来一帧图像,根据停车位字典划分出一个个的停车位来,然后通过模型预测是不是空的,如果是空的, 在原图上进行标记出来即可。
所以下面是整个项目的核心预测:
def predict_on_img(img, spot_dict, model, class_indict, make_copy=True, color=[0, 255, 0], alpha=0.5, save=True):
# 这个是停车场的全景图像
if make_copy:
new_image = np.copy(img)
overlay = np.copy(img)
cnt_empty, all_spots = 0, 0
for spot in tqdm(spot_dict.keys()):
all_spots += 1
(x1, y1, x2, y2) = spot
(x1, y1, x2, y2) = (int(x1), int(y1), int(x2), int(y2))
spot_img = img[y1:y2, x1:x2]
spot_img_pil = Image.fromarray(spot_img)
label = model_infer(spot_img_pil, model, class_indict)
if label == 'empty':
cv2.rectangle(overlay, (int(x1), int(y1)), (int(x2), int(y2)), color, -1)
cnt_empty += 1
cv2.addWeighted(overlay, alpha, new_image, 1 - alpha, 0, new_image)
# 显示结果的
cv2.putText(new_image, "Available: %d spots" % cnt_empty, (30, 95),
cv2.FONT_HERSHEY_SIMPLEX,
0.7, (255, 255, 255), 2)
cv2.putText(new_image, "Total: %d spots" % all_spots, (30, 125),
cv2.FONT_HERSHEY_SIMPLEX,
0.7, (255, 255, 255), 2)
if save:
filename = 'with_marking_predict.jpg'
cv2.imwrite(filename, new_image)
# cv_imshow('new_image', new_image)
return new_image
模型预测的核心,就是model_infer函数,这个也是模型预测的常规操作,这里不过多解释了。
视频的话,无非就是多帧图像,对于每一帧过一下这个函数,就能进行视频的实时预测:
def predict_on_video(video_path, spot_dict, model, class_indict, ret=True):
cap = cv2.VideoCapture(video_path)
count = 0
while ret:
ret, image = cap.read()
count += 1
if count == 5:
count = 0
new_image = predict_on_img(image, spot_dict, model, class_indict, save=False)
cv2.imshow('frame', new_image)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
cap.release()
这就是整个项目啦。
5. 小结
终于看到了一个小麻雀项目了,虽然可能有些简单,但是却能把图像处理加模型训练预测,这一套机制都给利用起来,对我这样的初学者还算友好。通过这个项目,在图像预处理方面学习到了二值化中的InRange, 霍夫直线检测,定点标定技术,mask矩阵进行区域锁定,以及通过坐标进行区域提取等。在模型方面学习到了resnet,复习了pytorch迁移学习。 又认识了几个新的库glob, shutil, PIL等。所以,收获颇多,感觉cv越来越有意思了哈。
这个项目感觉实际场景中挺有意义的,开脑洞幻想下未来如果智慧交通普及了,在智能停车场的运作下, 通过摄像头实时检测停车场车位的空余状况并标定好位置,把这个信息传到无人车系统,然后无人车根据信息自动规划停车路线,直接锁定车位自动把车停好。避免了停车场的拥挤(可能现在我们停车转好几圈找不到一个停车位,还有可能堵死在里面不好出来)。并且停车场的空余情况能通过大屏幕一目了然,节省了用户找车位,停车的时间。
好吧, 只是提前开了下脑洞,至于能不能成, 未来会给我们答案
本次项目代码地址https://github.com/zhongqiangwu960812/OpenCVLearning
到此这篇关于OpenCV停车场车位实时检测项目实践的文章就介绍到这了,更多相关OpenCV停车场车位实时检测内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python计算机视觉OpenCV库实现实时摄像头人脸检测示例
目录 设备准备: 实现过程 调用模型库文件 打开摄像头 人脸检测 设置退出机制 程序运行 全部代码 OpenCV 是一个C++库,目前流行的计算机视觉编程库,用于实时处理计算机视觉方面的问题,它涵盖了很多计算机视觉领域的模块.在Python中常使用OpenCV库实现图像处理. 本文将介绍如何在Python3中使用OpenCV实现实时摄像头人脸检测: 设备准备: USB摄像头 接入PC电脑USB口,并调试正常打开视频.如果电脑内置了电脑摄像头,测试一下摄像头能否正常使用. 下载特征分类模型: XM
-
OpenCV-Python 摄像头实时检测人脸代码实例
参考 OpenCV摄像头使用 代码 import cv2 cap = cv2.VideoCapture(4) # 使用第5个摄像头(我的电脑插了5个摄像头) face_cascade = cv2.CascadeClassifier(r'haarcascade_frontalface_default.xml') # 加载人脸特征库 while(True): ret, frame = cap.read() # 读取一帧的图像 gray = cv2.cvtColor(frame, cv2.COLOR_
-
OpenCV+python实现实时目标检测功能
环境安装 安装Anaconda,官网链接Anaconda 使用conda创建py3.6的虚拟环境,并激活使用 conda create -n py3.6 python=3.6 //创建 conda activate py3.6 //激活 3.安装依赖numpy和imutils //用镜像安装 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple numpy pip install -i https://pypi.tuna.tsinghua
-
python版opencv摄像头人脸实时检测方法
OpenCV版本3.3.0,注意模型文件的路径要改成自己所安装的opencv的模型文件的路径,路径不对就会报错,一般在opencv-3.3.0/data/haarcascades 路径下 import numpy as np import cv2 face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml') cap = cv2.VideoCapture(0) while True: ret,img = ca
-
opencv+mediapipe实现人脸检测及摄像头实时示例
目录 单张人脸关键点检测 单张图像人脸检测 摄像头实时关键点检测 单张人脸关键点检测 定义可视化图像函数 导入三维人脸关键点检测模型 导入可视化函数和可视化样式 读取图像 将图像模型输入,获取预测结果 BGR转RGB 将RGB图像输入模型,获取预测结果 预测人人脸个数 可视化人脸关键点检测效果 绘制人来脸和重点区域轮廓线,返回annotated_image 绘制人脸轮廓.眼睫毛.眼眶.嘴唇 在三维坐标中分别可视化人脸网格.轮廓.瞳孔 import cv2 as cv import mediapi
-
使用OpenCV对车道进行实时检测的实现示例代码
项目介绍 下图中的两条线即为车道: 我们的任务就是通过 OpenCV 在一段视频(或摄像头)中实时检测出车道并将其标记出来.其效果如下图所示: 这里使用的代码来源于磐怼怼大神,此文章旨在对其代码进行解释. 实现步骤 1.将视频的所有帧读取为图片: 2.创建掩码并应用到这些图片上: 3.图像阈值化: 4.用霍夫线变换检测车道: 5.将车道画到每张图片上: 6.将所有图片合并为视频. 代码实现 1.导入需要的库 import os import re import cv2 import numpy
-
OpenCV停车场车位实时检测项目实践
目录 1. 写在前面 2. 整体流程梳理 3. 数据预处理 3.1 背景过滤 3.2 Canny边缘检测 3.3 停车场区域提取 3.4 霍夫变换检测直线 3.5 以列为单位,划分停车位 3.6 锁定每个停车位 3.7 为CNN生成预测图片 4. 模型的训练和预测 4.1 模型训练 4.2 模型预测 5. 小结 1. 写在前面 今天整理OpenCV入门的第三个实战小项目,前面的两篇文章整理了信用卡数字识别以及文档OCR扫描, 大部分用到的是OpenCV里面的基础图像预处理技术,比如轮廓检测,边缘
-
OpenCV 视频中火焰检测识别实践
主要完成两个视频中火焰的检测,主要结合RGB判据和HIS判据,设定合适的阈值条件,检测出火焰对应像素的区域,将原图二值化,经过中值滤波以及数学形态学的膨胀运算等图像处理,消除一些噪声及离散点,连通一些遗漏的区域.基于OpenCV的开源库,在VS2013平台上,实现了两个视频中火焰的检测. 利用OpenCV有强大的图像处理库,直接将图像分离为RGB三通道,设置条件限制,找到火焰的像素位置,将原图处理成二值图像.对于火焰检测,本文结合RGB判据和HIS判据,分割出火焰的区域.一般用于人眼观看的颜色模
-
树莓派上利用python+opencv+dlib实现嘴唇检测的实现
目录 1.安装相关库文件 2.代码部分 3.实验效果 树莓派上利用python+opencv+dlib实现嘴唇检测 项目的目标是在树莓派上运行python代码以实现嘴唇检测,本来以为树莓派的硬件是可以流畅运行实时检测的,但是实验的效果表明树莓派实时检测是不可行,后面还需要改进. 实验的效果如下: 1.安装相关库文件 这里需要用的库有opencv,numpy,dlib. 1.1 安装opencv pip3 install opencv-python 1.2 安装numpy 树莓派中自带了numpy
-
nodejs+socket.io实现p2p消息实时发送的项目实践
目录 常见的消息通知: 实现思路与步骤等 其他方法介绍 技术实现与相关包介绍 包介绍 技术实现 服务端 客户端 常见的消息通知: 常见的站内通知类别(括号里是对自己目前项目出现情况的分析,读者忽略): 公告 Announcement (通道加入新的组织.某组织或用户新上传了某数据摘要.系统凌晨需要版本更新等事件) 提醒 Remind(用户之间.系统与用户之间) 资源订阅提醒(关注的数据摘要更新了内容.评论等) 资源发布提醒(我发布的数据摘要被评论了,被关注了,被申请交易了) 系统提醒 私信 Ma
-
Opencv实现眼睛控制鼠标的实践
如何用眼睛来控制鼠标?一种基于单一前向视角的机器学习眼睛姿态估计方法.在此项目中,每次单击鼠标时,我们都会编写代码来裁剪你们的眼睛图像.使用这些数据,我们可以反向训练模型,从你们您的眼睛预测鼠标的位置.在开始项目之前,我们需要引入第三方库. # For monitoring web camera and performing image minipulations import cv2 # For performing array operations import numpy as np #
-
Android 中使用 dlib+opencv 实现动态人脸检测功能
1 概述 完成 Android 相机预览功能以后,在此基础上我使用 dlib 与 opencv 库做了一个关于人脸检测的 demo.该 demo 在相机预览过程中对人脸进行实时检测,并将检测到的人脸用矩形框描绘出来.具体实现原理如下: 采用双层 View,底层的 TextureView 用于预览,程序从 TextureView 中获取预览帧数据,然后调用 dlib 库对帧数据进行处理,最后将检测结果绘制在顶层的 SurfaceView 中. 2 项目配置 由于项目中用到了 dlib 与 open