浅谈MyBatis原生批量插入的坑与解决方案
目录
- 原生批量插入的“坑”
- 解决方案
- 分片 Demo 实战
- 原生批量插入分片实现
- 总结
前面的文章咱们讲了 MyBatis 批量插入的 3 种方法:循环单次插入、MyBatis Plus 批量插入、MyBatis 原生批量插入,详情请点击《MyBatis 批量插入数据的 3 种方法!》
但之前的文章也有不完美之处,原因在于:使用 「循环单次插入」的性能太低,使用「MyBatis Plus 批量插入」性能还行,但要额外的引入 MyBatis Plus 框架,使用「MyBatis 原生批量插入」性能最好,但在插入大量数据时会导致程序报错,那么,今天咱们就会提供一个更优的解决方案。
原生批量插入的“坑”
首先,我们来看一下 MyBatis 原生批量插入中的坑,当我们批量插入 10 万条数据时,实现代码如下:
import com.example.demo.model.User;
import com.example.demo.service.impl.UserServiceImpl;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.ArrayList;
import java.util.List;
@SpringBootTest
class UserControllerTest {
// 最大循环次数
private static final int MAXCOUNT = 100000;
@Autowired
private UserServiceImpl userService;
/**
* 原生自己拼接 SQL,批量插入
*/
@Test
void saveBatchByNative() {
long stime = System.currentTimeMillis(); // 统计开始时间
List<User> list = new ArrayList<>();
for (int i = 0; i < MAXCOUNT; i++) {
User user = new User();
user.setName("test:" + i);
user.setPassword("123456");
list.add(user);
}
// 批量插入
userService.saveBatchByNative(list);
long etime = System.currentTimeMillis(); // 统计结束时间
System.out.println("执行时间:" + (etime - stime));
}
}
核心文件 UserMapper.xml 中的实现代码如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.demo.mapper.UserMapper">
<insert id="saveBatchByNative">
INSERT INTO `USER`(`NAME`,`PASSWORD`) VALUES
<foreach collection="list" separator="," item="item">
(#{item.name},#{item.password})
</foreach>
</insert>
</mapper>
当我们开心地运行以上程序时,就出现了以下的一幕:
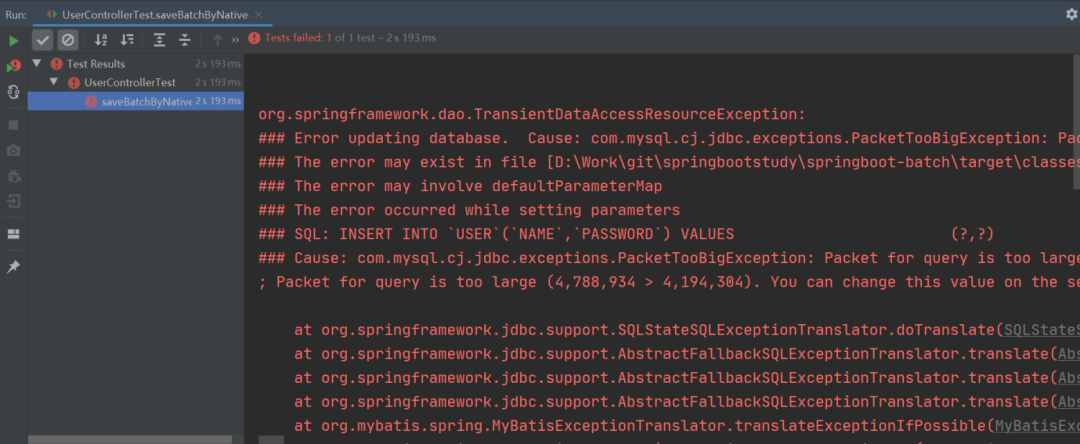
沃,程序竟然报错了!
这是因为使用 MyBatis 原生批量插入拼接的插入 SQL 大小是 4.56M,而默认情况下 MySQL 可以执行的最大 SQL 为 4M,那么在程序执行时就会报错了。
解决方案
以上的问题就是因为批量插入时拼接的 SQL 文件太大了,所以导致 MySQL 的执行报错了。那么我们第一时间想到的解决方案就是将大文件分成 N 个小文件,这样就不会因为 SQL 太大而导致执行报错了。也就是说,我们可以将待插入的 List 集合分隔为多个小 List 来执行批量插入的操作,而这个操作过程就叫做 List 分片。
有了处理思路之后,接下来就是实操了,那如何对集合进行分片操作呢?
分片操作的实现方式有很多种,这个我们后文再讲,接下来我们使用最简单的方式,也就是 Google 提供的 Guava 框架来实现分片的功能。
分片 Demo 实战
要实现分片功能,第一步我们先要添加 Guava 框架的支持,在 pom.xml 中添加以下引用:
<!-- google guava 工具类 --> <!-- https://mvnrepository.com/artifact/com.google.guava/guava --> <dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>31.0.1-jre</version> </dependency>
接下来我们写一个小小的 demo,将以下 7 个人名分为 3 组(每组最多 3 个),实现代码如下:
import com.google.common.collect.Lists;
import java.util.Arrays;
import java.util.List;
/**
* Guava 分片
*/
public class PartitionByGuavaExample {
// 原集合
private static final List<String> OLD_LIST = Arrays.asList(
"唐僧,悟空,八戒,沙僧,曹操,刘备,孙权".split(","));
public static void main(String[] args) {
// 集合分片
List<List<String>> newList = Lists.partition(OLD_LIST, 3);
// 打印分片集合
newList.forEach(i -> {
System.out.println("集合长度:" + i.size());
});
}
}
以上程序的执行结果如下:
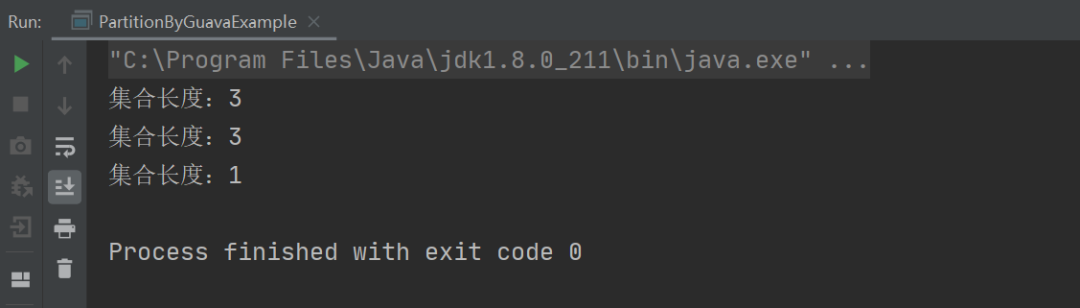
从上述结果可以看出,我们只需要使用 Guava 提供的 Lists.partition 方法就可以很轻松的将一个集合进行分片了。
原生批量插入分片实现
那接下来,就是改造我们的 MyBatis 批量插入代码了,具体实现如下:
@Test
void saveBatchByNativePartition() {
long stime = System.currentTimeMillis(); // 统计开始时间
List<User> list = new ArrayList<>();
// 构建插入数据
for (int i = 0; i < MAXCOUNT; i++) {
User user = new User();
user.setName("test:" + i);
user.setPassword("123456");
list.add(user);
}
// 分片批量插入
int count = (int) Math.ceil(MAXCOUNT / 1000.0); // 分为 n 份,每份 1000 条
List<List<User>> listPartition = Lists.partition(list, count);
// 分片批量插入
for (List<User> item : listPartition) {
userService.saveBatchByNative(item);
}
long etime = System.currentTimeMillis(); // 统计结束时间
System.out.println("执行时间:" + (etime - stime));
}
执行以上程序,最终的执行结果如下:
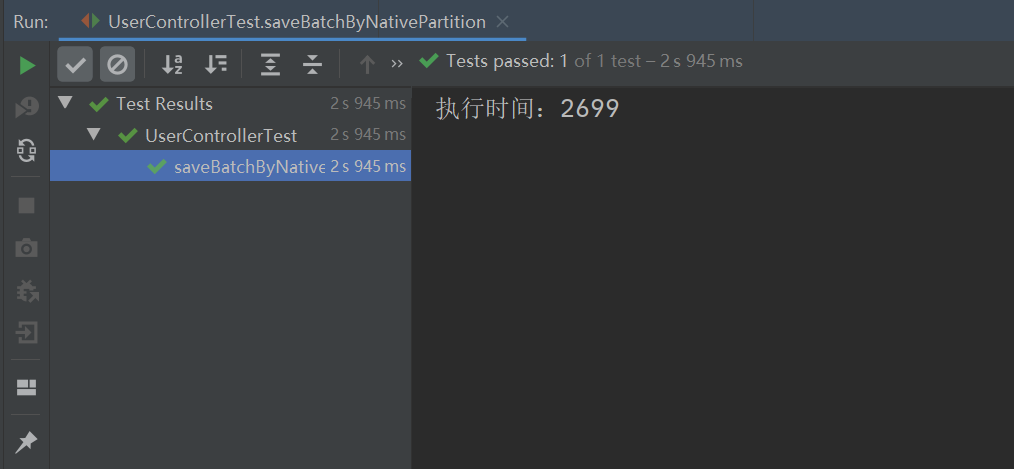
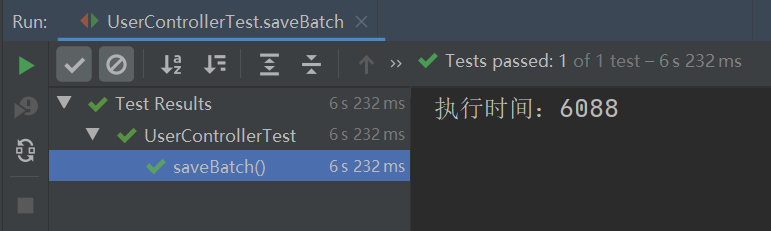
从上图可以看出,之前批量插入时的异常报错不见了,并且此实现方式的执行效率竟比 MyBatis Plus 的批量插入的执行效率要高,MyBatis Plus 批量插入 10W 条数据的执行时间如下:
总结
本文我们演示了 MyBatis 原生批量插入时的问题:可能会因为插入的数据太多从而导致运行失败,我们可以通过分片的方式来解决此问题,分片批量插入的实现步骤如下:
- 计算出分片的数量(分为 N 批);
- 使用 Lists.partition 方法将集合进行分片(分为 N 个集合);
- 循环将分片的集合进行批量插入的操作。
到此这篇关于浅谈MyBatis原生批量插入的坑与解决方案的文章就介绍到这了,更多相关MyBatis原生批量插入内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Mybatis批量插入数据返回主键的实现
响应效果(id为主键): { "data": [ {"studentName": "张三","classNo": "一班","id": 111}, {"studentName": "李四","classNo": "二班","id": 112}, {"studentName&quo
-

详解mybatis批量插入10万条数据的优化过程
数据库 在使用mybatis插入大量数据的时候,为了提高效率,放弃循环插入,改为批量插入,mapper如下: package com.lcy.service.mapper; import com.lcy.service.pojo.TestVO; import org.apache.ibatis.annotations.Insert; import java.util.List; public interface TestMapper { @Insert("") Integer test
-
mybatis 批量将list数据插入到数据库的实现
随着业务需要,有时我们需要将数据批量添加到数据库,mybatis提供了将list集合循环添加到数据库的方法.具体实现代码如下: 1.mapper层中创建 insertForeach(List < Fund > list) 方法,返回值是批量添加的数据条数 package com.center.manager.mapper; import java.util.List; import org.apache.ibatis.annotations.Mapper; import com.center.
-
MyBatis批量插入(insert)数据操作
在程序中封装了一个List集合对象,然后需要把该集合中的实体插入到数据库中,由于项目使用了Spring+MyBatis的配置,所以打算使用MyBatis批量插入,由于之前没用过批量插入,在网上找了一些资料后最终实现了,把详细过程贴出来. 实体类TrainRecord结构如下: public class TrainRecord implements Serializable { private static final long serialVersionUID = -12069604621179
-
mybatis foreach批量插入数据:Oracle与MySQL区别介绍
下面给大家介绍mybatis foreach批量插入数据:Oracle与MySQL不同点: •主要不同点在于foreach标签内separator属性的设置问题: •separator设置为","分割时,最终拼接的代码形式为:insert into table_name (a,b,c) values (v1,v2,v3) ,(v4,v5,v6) ,... •separator设置为"union all"分割时,最终拼接的代码形式为:insert into table
-
mybatis中批量插入的两种方式(高效插入)
MyBatis简介 MyBatis是一个支持普通SQL查询,存储过程和高级映射的优秀持久层框架.MyBatis消除了几乎所有的JDBC代码和参数的手工设置以及对结果集的检索封装.MyBatis可以使用简单的XML或注解用于配置和原始映射,将接口和Java的POJO(Plain Old Java Objects,普通的Java对象)映射成数据库中的记录. 一.mybiats foreach标签 foreach的主要用在构建in条件中,它可以在SQL语句中进行迭代一个集合.foreach元素的属性主
-
Mybatis批量插入返回成功的数目实例
Mybatis批量插入返回影响的行数 环境: postgresql 9.6.5 spring 4.1 mybatis3 junit4 log4j ThesisMapper.xml: <!-- 批量插入 --> <insert id="insertList" parameterType="java.util.List"> insert into public.thesis (name) values <foreach collection
-
浅谈MyBatis原生批量插入的坑与解决方案
目录 原生批量插入的"坑" 解决方案 分片 Demo 实战 原生批量插入分片实现 总结 前面的文章咱们讲了 MyBatis 批量插入的 3 种方法:循环单次插入.MyBatis Plus 批量插入.MyBatis 原生批量插入,详情请点击<MyBatis 批量插入数据的 3 种方法!> 但之前的文章也有不完美之处,原因在于:使用 「循环单次插入」的性能太低,使用「MyBatis Plus 批量插入」性能还行,但要额外的引入 MyBatis Plus 框架,使用「MyBati
-
浅谈Mybatis版本升级踩坑及背后原理分析
1.背景 某一天的晚上,系统服务正在进行常规需求的上线,因为发布时,提示统一的pom版本需要升级,于是从 1.3.9.6 升级至 1.4.2.1. 当服务开始上线后,开始陆续出现了一些更新系统交互日志方面的报警,属于系统辅助流程,报警下图所示, 具体系统数据已脱敏,内容是Mybatis相关的报警,在进行类型转换的时候,产生了强转错误. 更新开票请求返回日志, id:{#######}, response:{{"code":XXX,"data":{"call
-
浅谈Mybatis分页插件,自定义分页的坑
场景:PageHelper 的默认分页方案是 select count(0) from (你的sql) table_count 由于查询数据比较大时,导致分页查询效率低下. 优化:使用自定义的count查询.. 废话不多说,对应代码如下: 这个时候会使用自定义的 count sql进行统计查询. 然后一般分页默认使用 PageHelper.startPage(); 作者优化:如果获取的数量大于实际数量,则进行pageNum优化. 所以 最好建议重载 startPage. 不进行优化!!! 要不然
-
浅谈Mybatis+mysql 存储Date类型的坑
场景: 把一个时间字符串转成Date,存进Mysql.时间天数会比实际时间少1天,也可能是小时少了13-14小时 Mysql的时区是CST(使用语句:show VARIABLES LIKE '%time_zone%'; 查) 先放总结: 修改方法: 1. 修改数据库时区 2. 在jdbc.url里加后缀 &serverTimezone=GMT%2B8 3. 代码里设置时区,给SimpleDateFormat.setTimeZone(...) 例外:new Date() 可以直接存为正确时间,其他
-
浅谈Mybatis Plus的BaseMapper的方法是如何注入的
目录 Mybatis Plus的BaseMapper的方法 Mybatis Plus的初始化方法 MybatisPlusAutoConfiguration中的SqlSessionFactory BaseMapper方法的注入的过程 总结 Mybatis Plus的BaseMapper的方法 我们在用的时候经常就是生产自定义的Mapper继承自BaseMapper,然后我们就可以使用了,但是有没想过BaseMapper里的方法是怎么被注入到mybatis里的,也没看到什么xml啊,今天我们就来看看
-
浅谈MyBatis Plus主键设置策略
根据一次插入失败报错来了解下MyBatis Plus主键设置策略今天学习使用MyBatis Plus,发现使用代码生成器生成对应的实体类.Service和Mapper后,在保存数据时报错 com.baomidou.mybatisplus.exceptions.MybatisPlusException: java.lang.reflect.InvocationTargetException at com.baomidou.mybatisplus.MybatisSqlSessionTemplate$
-
浅谈mybatis中的#和$的区别
1. #将传入的数据都当成一个字符串,会对自动传入的数据加一个双引号.如:order by #user_id#,如果传入的值是111,那么解析成sql时的值为order by "111", 如果传入的值是id,则解析成的sql为order by "id". 2. $将传入的数据直接显示生成在sql中.如:order by $user_id$,如果传入的值是111,那么解析成sql时的值为order by user_id, 如果传入的值是id,则解析成的sql为ord
-
浅谈Mybatis SqlSession执行流程
目录 Mybatis执行SQL流程 SqlSession Executor Mybatis之Executor Mybatis之StatementHandler 进入ResultSetHandler Mybatis执行SQL流程 在看源码之前,我们需要了解一些基本知识,如果您没有阅读Mybatis SqlSessionFactory 初始化原理,可以先阅读Mybatis SqlSessionFactory 初始化原理这篇文章,这用更有助于我们理解接下来的文章 在看源码之前,我们需要了解一些基本知识
-
浅谈angularjs module返回对象的坑(推荐)
通过将module中不同的部件拆分到不同的js文件中,在组装的时候发现module存在一个奇怪的问题,不知道是不是AngularJS的bug.至今没有找到解释. 问题是这样的,按照理解,angular.module('app.main', []);这样一句话相当于从app.main命名空间返回出一个app对象.那么,不论在任何js文件中,我通过该方法获得的app变量所储存的指针都应该指向唯一的一个堆内存,而这个内存中存储的就是这个app对象.这种操作在module的js文件,和controlle
-
浅谈JS原生Ajax,GET和POST
javascript/js的ajax的GET请求: <script type="text/javascript"> /* 创建 XMLHttpRequest 对象 */ var xmlHttp; function GetXmlHttpObject(){ if (window.XMLHttpRequest){ // code for IE7+, Firefox, Chrome, Opera, Safari xmlhttp=new XMLHttpRequest(); }else