pytorch下tensorboard的使用程序示例
目录
- 一、tensorboard程序实例:
- 1.代码
- 2.在命令提示符中操作
- 3.在浏览器中打开网址
- 4.效果
- 二、writer.add_scalar()与writer.add_scalars()参数说明
- 1.概述
- 2.参数说明
- 3.writer.add_scalar()效果
- 4.writer.add_scalars()效果
我们都知道tensorflow框架可以使用tensorboard这一高级的可视化的工具,为了使用tensorboard这一套完美的可视化工具,未免可以将其应用到Pytorch中,用于Pytorch的可视化。这里特别感谢Github上的解决方案: https://github.com/lanpa/tensorboardX。
一、tensorboard程序实例:
1.代码
from torch.utils.tensorboard import SummaryWriter # 用于将数据写入tensorboard
import csv # 用于从本地csv中读取数据
'''从csv读取数据,用于后续显示在tensorboard中'''
fileAddr = 'models/211016_101208/reward.csv' # 待读取的文件地址
file = open(fileAddr, 'r') # 打开文件
data = csv.reader(file) # 从文件中读取数据,但此时data是{reader}格式
next(data) # 忽略数据的第一行,这是csv的表头。
'''csv数据读取完毕'''
'''将data数据写入tensorboard'''
tensorboard_logs_addr = "logs_tensorboard/211021" # 设定tensorboard文件存放的地址
writer = SummaryWriter(tensorboard_logs_addr)
for index, data1 in enumerate(data): # 开始写入文件。
# 一个图中写入多组数据,共用y轴
writer.add_scalars('adv_data/Rewards Per Episodes',
{'agent0':float(data1[0]),
'agent1':float(data1[1]),
'agent2':float(data1[2]),}, index)
# 一个图中写入一组数据
writer.add_scalar('adv_data/step number per episode', int(data1[4]), index)
# 一个图中写入一组数据
writer.add_scalar('gda_data/Rewards per episode', float(data1[3]), index)
writer.add_scalar('gda_data/step number per episode', int(data1[4]), index)
writer.close() # 完成后关闭
运行以上代码,便会在文件夹logs_tensorboard/211021中生成tensorboard数据。
2.在命令提示符中操作
# 打开命令提示符后默认在c盘,固先转换到d盘
C:\Users\wf>d:
# 进入程序所在文件夹
D:\>cd D:\04MADDPG\40_MADDPG_torch-master -UAV_FixedSpeed
# 打开tensorboard的代码
D:\04MADDPG\40_MADDPG_torch-master -UAV_FixedSpeed>tensorboard --logdir=logs_tensorboard/211021
完
说明:
tensorboard --logdir=logs_tensorboard/211021
tensorboard --logdir= 是不可更改的;
logs_tensorboard/211021 是tensorboard文件存放的地址;logs_tensorboard文件夹的上一层就是程序所在文件夹;
3.在浏览器中打开网址
http://localhost:6006/
4.效果

二、writer.add_scalar()与writer.add_scalars()参数说明
writer.add_scalar() 一副图中只有一组数据
writer.add_scalars() 一副图中有多组数据,但共用x轴
1.概述
将数据写入tensorboard只有以下代码:
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("tensorboard文件存放地址")
# 将数据写入tensorboard文件,规定写入的形式
writer.add_scalar() 或 writer.add_scalars()
writer.close()
2.参数说明
writer.add_scalar('TAG', Y-DATA, X-DATA)
writer.add_scalars('TAG', {'Line1':Line1-Y-DATA,
'Line2':Line2-Y-DATA,
'Line3':Line3-Y-DATA,
... ... ,}, X-DATA)
其中:
- 运行一次writer.add_scalar()或writer.add_scalar()生成一张图像;
- 如果后面运行的writer.add_scalar()的标签和前面的相同,会覆盖掉旧的图像;
参数说明:
TAG 是当前绘制图像的分类标签,可以设置2级标签;如A1/B1,A1/C1,A2/B2;
当两张图像的第一级标签相同时,两张图象会放在一行;
当两张图像的第一级标签不同时,两张图象会放在不同的组,即两张图像上下放;
Y-DATA 是图像中Y轴的数据
Line1-Y-DATA 是图像中Line1的Y轴数据
Line2-Y-DATA 是图像中Line2的Y轴数据
Line3-Y-DATA 是图像中Line3的Y轴数据
X-DATA 是图像中X轴的数据
Line1、Line2、Line3是同一张图像中,几个曲线的名称,他们共用X轴
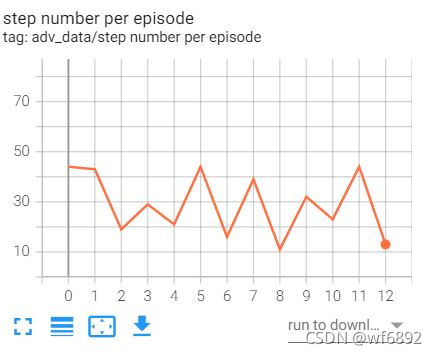
3.writer.add_scalar()效果
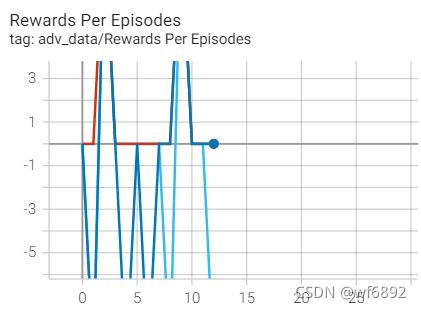
4.writer.add_scalars()效果
到此这篇关于pytorch下tensorboard的使用的文章就介绍到这了,更多相关pytorch tensorboard使用内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Pytorch中TensorBoard及torchsummary的使用详解
1.TensorBoard神经网络可视化工具 TensorBoard是一个强大的可视化工具,在pytorch中有两种调用方法: 1.from tensorboardX import SummaryWriter 这种方法是在官方还不支持tensorboard时网上有大神写的 2.from torch.utils.tensorboard import SummaryWriter 这种方法是后来更新官方加入的 1.1 调用方法 1.1.1 创建接口SummaryWriter 功能:创建接口 调用方法:
-
pytorch使用tensorboardX进行loss可视化实例
最近pytorch出了visdom,也没有怎么去研究它,主要是觉得tensorboardX已经够用,而且用起来也十分的简单 pip install tensorboardX 然后在代码里导入 from tensorboardX import SummaryWriter 然后声明一下自己将loss写到哪个路径下面 writer = SummaryWriter('./log') 然后就可以愉快的写loss到你得这个writer了 niter = epoch * len(train_loader) +
-
在Pytorch中简单使用tensorboard
一.tensorboard的简要介绍 TensorBoard是一个独立的包(不是pytorch中的),这个包的作用就是可视化您模型中的各种参数和结果. 下面是安装: pip install tensorboard 安装 TensorBoard 后,这些实用程序使您可以将 PyTorch 模型和指标记录到目录中,以便在 TensorBoard UI 中进行可视化. PyTorch 模型和张量以及 Caffe2 网络和 Blob 均支持标量,图像,直方图,图形和嵌入可视化. SummaryWrite
-
教你如何在Pytorch中使用TensorBoard
什么是TensorboardX Tensorboard 是 TensorFlow 的一个附加工具,可以记录训练过程的数字.图像等内容,以方便研究人员观察神经网络训练过程.可是对于 PyTorch 等其他神经网络训练框架并没有功能像 Tensorboard 一样全面的类似工具,一些已有的工具功能有限或使用起来比较困难 (tensorboard_logger, visdom等) .TensorboardX 这个工具使得 TensorFlow 外的其他神经网络框架也可以使用到 Tensorboard
-
pytorch下tensorboard的使用程序示例
目录 一.tensorboard程序实例: 1.代码 2.在命令提示符中操作 3.在浏览器中打开网址 4.效果 二.writer.add_scalar()与writer.add_scalars()参数说明 1.概述 2.参数说明 3.writer.add_scalar()效果 4.writer.add_scalars()效果 我们都知道tensorflow框架可以使用tensorboard这一高级的可视化的工具,为了使用tensorboard这一套完美的可视化工具,未免可以将其应用到Pytorc
-
PyTorch 中的傅里叶卷积实现示例
卷积 卷积在数据分析中无处不在.几十年来,它们一直被用于信号和图像处理.最近,它们成为现代神经网络的重要组成部分.如果你处理数据的话,你可能会遇到错综复杂的问题. 数学上,卷积表示为: 尽管离散卷积在计算应用程序中更为常见,但在本文的大部分内容中我将使用连续形式,因为使用连续变量来证明卷积定理(下面讨论)要容易得多.之后,我们将回到离散情况,并使用傅立叶变换在 PyTorch 中实现它.离散卷积可以看作是连续卷积的近似,其中连续函数离散在规则网格上.因此,我们不会为这个离散的案例重新证明卷积定理
-
简单的手工hibernate程序示例
本文讲述了简单的手工hibernate程序示例.分享给大家供大家参考.具体如下: 今天学习了下hibernate,写了个小的手工程序,总结下, 首先创建数据库表: 复制代码 代码如下: create table increment_testr(id bigint not null, name char(10), primary key(id)); eclipse下,新建工程. 新建数据库表的映射,这里使用手工方式完成: IncrementTester.java public class Incr
-
php获取网页请求状态程序示例
对于网页返回状态代码一般情况下我们都会去查自己网站状态码是不是200或错误页面是不是404代码,并且多数情况下我们的查看方法就是使用站长工具或ff浏览器等来查看,极少有人想到自己写一个查看状态代码的功能. 本文就此简述php获取网页请求状态程序示例如下: 方法一,使用 fsockopen(不推荐使用curl_getinfo!) 复制代码 代码如下: function get_http_code($url="localhost", $port=80, $fsock_timeout=10)
-
使用Py2Exe for Python3创建自己的exe程序示例
最近使用Python 3.5写了一个GUI小程序,于是想将该写好的程序发布成一个exe文件,供自己单独使用.至于通过安装的方式使用该程序,我没有探索,感兴趣的读者可以自己摸索. 1 介绍 我使用的开发环境是python3.4(实际上我是在另一个64位的台式机上,用python3.5开发的,不过代码不用任何修改即可在python3.4上运行),该环境由Anaconda提供.我开发的小GUI软件为mergeDocGui,该程序功能完备,调试通过,等待转成直接使用的exe程序,以在Windows操作系
-
pytorch下使用LSTM神经网络写诗实例
在pytorch下,以数万首唐诗为素材,训练双层LSTM神经网络,使其能够以唐诗的方式写诗. 代码结构分为四部分,分别为 1.model.py,定义了双层LSTM模型 2.data.py,定义了从网上得到的唐诗数据的处理方法 3.utlis.py 定义了损失可视化的函数 4.main.py定义了模型参数,以及训练.唐诗生成函数. 参考:电子工业出版社的<深度学习框架PyTorch:入门与实践>第九章 main代码及注释如下 import sys, os import torch as t fr
-
用什么库写 Python 命令行程序(示例代码详解)
一.前言 在近半年的 Python 命令行旅程中,我们依次学习了 argparse . docopt . click 和 fire 库的特点和用法,逐步了解到 Python 命令行库的设计哲学与演变.本文作为本次旅程的终点,希望从一个更高的视角对这些库进行横向对比,总结它们的异同点和使用场景,以期在应对不同场景时能够分析利弊,选择合适的库为己所用. 本系列文章默认使用 Python 3 作为解释器进行讲解.若你仍在使用 Python 2,请注意两者之间语法和库的使用差异哦~ 二.设计理念 在讨论
-
解决pytorch下出现multi-target not supported at的一种可能原因
在使用交叉熵损失函数的时候,target的形状应该是和label的形状一致或者是只有batchsize这一个维度的. 如果target是这样的[batchszie,1]就会出现上述的错误. 改一下试试,用squeeze()函数降低纬度, 如果不知道squeeze怎么用的, 可以参考这篇文章.pytorch下的unsqueeze和squeeze用法 这只是一种可能的原因. 补充:pytorch使用中遇到的问题 1. load模型参数文件时,提示torch.cuda.is_available() i
-
Pytorch用Tensorboard来观察数据
目录 1.Tensorboard 1.使用add_scalar()输入代码 2.使用add_image()输入代码 上一章讲数据的处理,这一章讲数据处理之后呈现的结果,即你有可能看到Loss的走向等,这样方便我们调试代码. 1.Tensorboard 有两个常用的方法: 一个是add_scalar()显:示曲线 一个是add_image()显示图像 首先安装Tensorboard 在你的编译环境(conda activate XXX)中输入命令 pip install tensorboard 1
-
python神经网络Pytorch中Tensorboard函数使用
目录 所需库的安装 常用函数功能 1.SummaryWriter() 2.writer.add_graph() 3.writer.add_scalar() 4.tensorboard --logdir= 示例代码 所需库的安装 很多人问Pytorch要怎么可视化,于是决定搞一篇. tensorboardX==2.0 tensorflow==1.13.2 由于tensorboard原本是在tensorflow里面用的,所以需要装一个tensorflow.会自带一个tensorboard. 也可以不