Go语言Mock使用基本指南详解
当前的实践中问题
在项目之间依赖的时候我们往往可以通过mock一个接口的实现,以一种比较简洁、独立的方式,来进行测试。但是在mock使用的过程中,因为大家的风格不统一,而且很多使用minimal implement的方式来进行mock,这就导致了通过mock出的实现各个函数的返回值往往是静态的,就无法让caller根据返回值进行的一些复杂逻辑。
首先来举一个例子
package task
type Task interface {
Do(int) (string, error)
}
通过minimal implement的方式来进行手动的mock
package mock
type MinimalTask struct {
// filed
}
func NewMinimalTask() *MinimalTask {
return &MinimalTask{}
}
func (mt *MinimalTask) Do(idx int) (string, error) {
return "", nil
}
在其他包使用Mock出的实现的过程中,就会给测试带来一些问题。
举个例子,假如我们有如下的接口定义与函数定义
package pool
import "github.com/ultramesh/mock-example/task"
type TaskPool interface {
Run(times int) error
}
type NewTask func() task.Task
我们基于接口定义和接口构造函数定义,封装了一个实现
package pool
import (
"fmt"
"github.com/pkg/errors"
"github.com/ultramesh/mock-example/task"
)
type TaskPoolImpl struct {
pool []task.Task
}
func NewTaskPoolImpl(newTask NewTask, size int) *TaskPoolImpl {
tp := &TaskPoolImpl{
pool: make([]task.Task, size),
}
for i := 0; i < size; i++ {
tp.pool[i] = newTask()
}
return tp
}
func (tp *TaskPoolImpl) Run(times int) error {
poolLen := len(tp.pool)
for i := 0; i < times; i++ {
ret, err := tp.pool[i%poolLen].Do(i)
if err != nil {
// process error
return errors.Wrap(err, fmt.Sprintf("error while run task %d", i%poolLen))
}
switch ret {
case "":
// process 0
fmt.Println(ret)
case "a":
// process 1
fmt.Println(ret)
case "b":
// process 2
fmt.Println(ret)
case "c":
// process 3
fmt.Println(ret)
}
}
return nil
}
接着我们来写测试的话应该是下面
package pool
import (
"github.com/golang/mock/gomock"
"github.com/stretchr/testify/assert"
"github.com/ultramesh/mock-example/mock"
"github.com/ultramesh/mock-example/task"
"testing"
)
type TestSuit struct {
name string
newTask NewTask
size int
times int
}
func TestTaskPoolRunImpl(t *testing.T) {
testSuits := []TestSuit{
{
nam
e: "minimal task pool",
newTask: func() task.Task { return mock.NewMinimalTask() },
size: 100,
times: 200,
},
}
for _, suit := range testSuits {
t.Run(suit.name, func(t *testing.T) {
var taskPool TaskPool = NewTaskPoolImpl(suit.newTask, suit.size)
err := taskPool.Run(suit.size)
assert.NoError(t, err)
})
}
}
这样通过go test自带的覆盖率测试我们能看到TaskPoolImpl实际被测试到的路径为
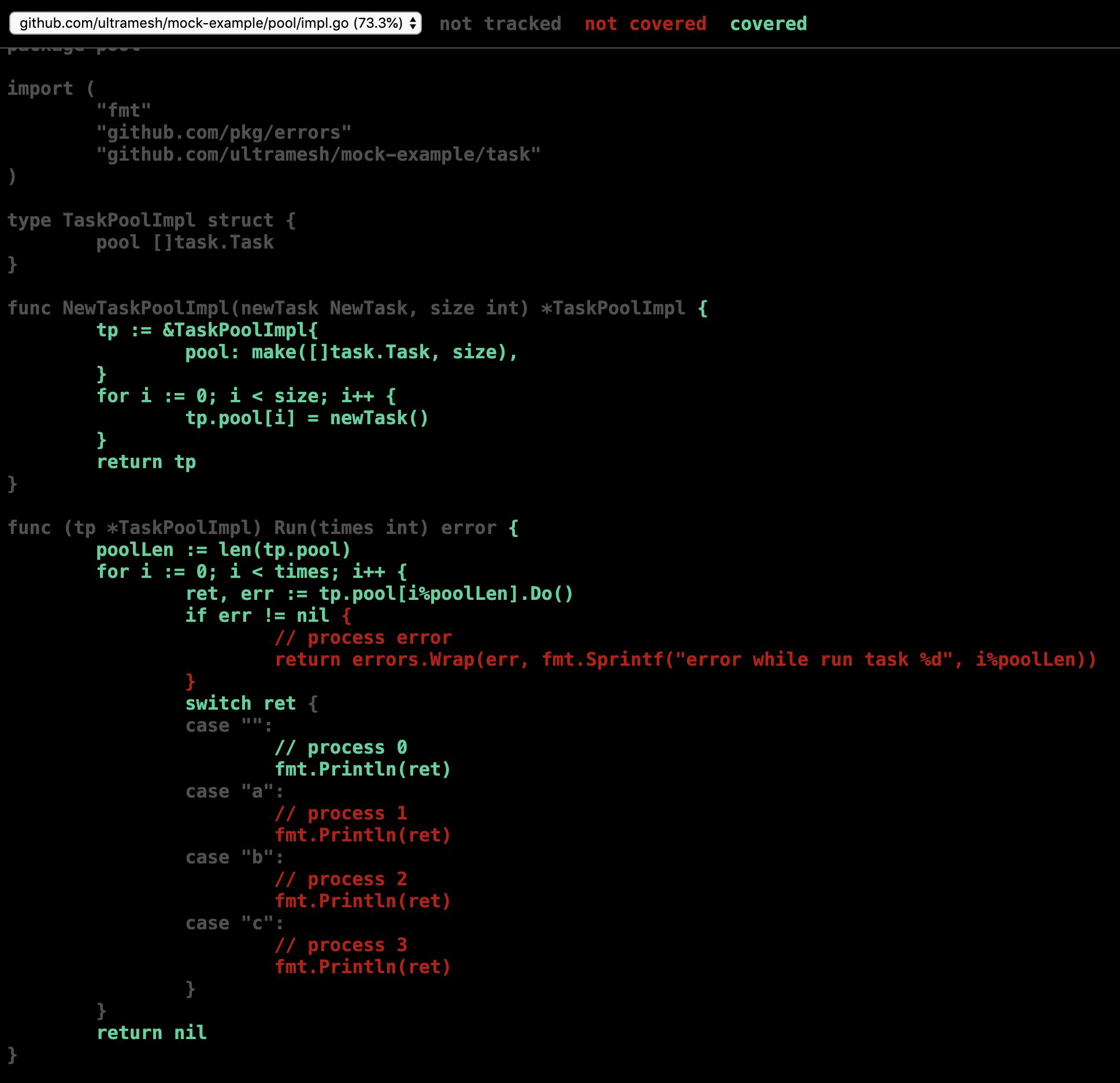
可以看到的手动实现MinimalTask的问题在于,由于对于caller来说,callee的返回值是不可控的,我们只能覆盖到由MinimalTask所定死的返回值的路径,此外mock在我们的实践中往往由被依赖的项目来操作,他不知道caller怎样根据返回值进行处理,没有办法封装出一个简单、够用的最小实现供接口测试使用,因此我们需要改进我们mock策略,使用golang官方的mock工具——gomock来进行更好地接口测试。
gomock实践
我们使用golang官方的mock工具的优势在于
- 我们可以基于工具生成的mock代码,我们可以用一种更精简的方式,封装出一个minimal implement,完成和手工实现一个minimal implement一样的效果。
- 可以允许caller自己灵活地、有选择地控制自己需要用到的那些接口方法的入参以及出参。
还是上面TaskPool的例子,我们现在使用gomock提供的工具来自动生成一个mock Task
mockgen -destination mock/mock_task.go -package mock -source task/interface.go
在mock包中生成一个mock_task.go来实现接口Task
首先基于mock_task.go,我们可以实现一个MockMinimalTask用于最简单的测试
package mock
import "github.com/golang/mock/gomock"
func NewMockMinimalTask(ctrl *gomock.Controller) *MockTask {
mock := NewMockTask(ctrl)
mock.EXPECT().Do().Return("", nil).AnyTimes()
return mock
}
于是这样我们就可以实现一个MockMinimalTask用来做一些测试
package pool
import (
"github.com/golang/mock/gomock"
"github.com/stretchr/testify/assert"
"github.com/ultramesh/mock-example/mock"
"github.com/ultramesh/mock-example/task"
"testing"
)
type TestSuit struct {
name string
newTask NewTask
size int
times int
}
func TestTaskPoolRunImpl(t *testing.T) {
testSuits := []TestSuit{
//{
// name: "minimal task pool",
// newTask: func() task.Task { return mock.NewMinimalTask() },
// size: 100,
// times: 200,
//},
{
name: "mock minimal task pool",
newTask: func() task.Task { return mock.NewMockMinimalTask(ctrl) },
size: 100,
times: 200,
},
}
for _, suit := range testSuits {
t.Run(suit.name, func(t *testing.T) {
var taskPool TaskPool = NewTaskPoolImpl(suit.newTask, suit.size)
err := taskPool.Run(suit.size)
assert.NoError(t, err)
})
}
}
我们使用这个新的测试文件进行覆盖率测试
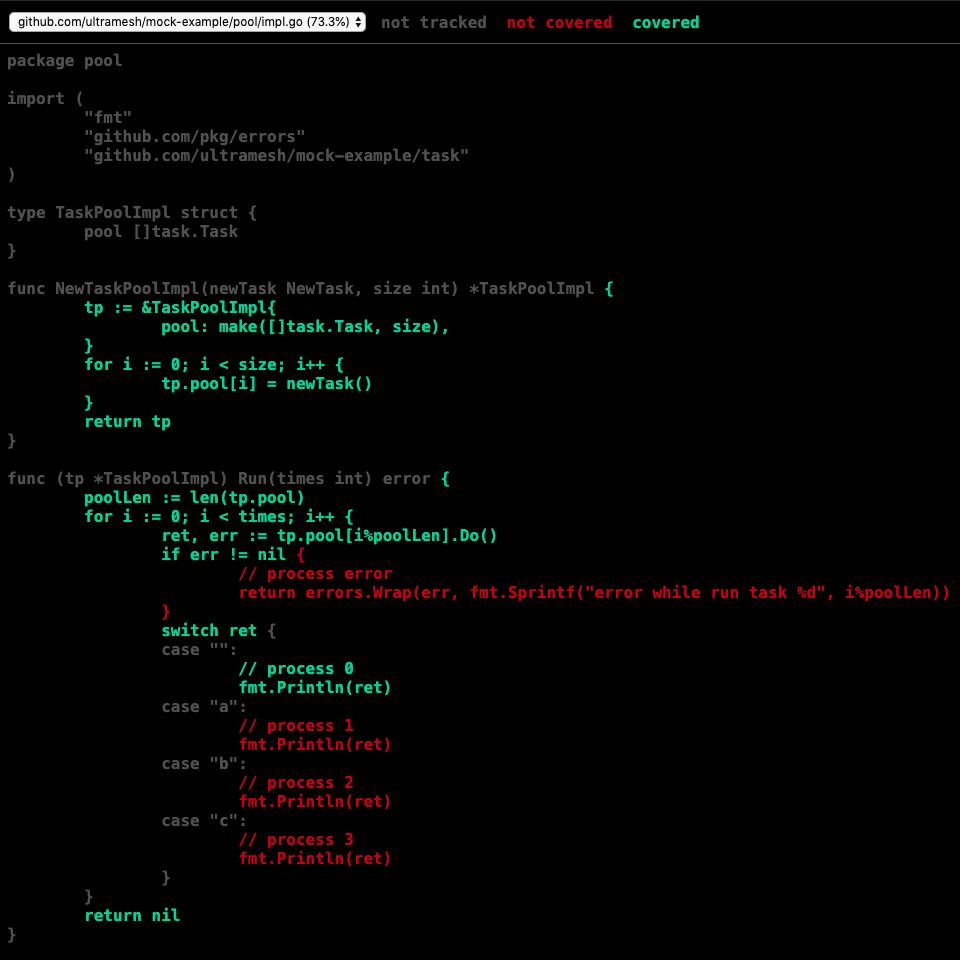
可以看到测试结果是一样的,那当我们想要达到更高的测试覆盖率的时候应该怎么办呢?我们进一步修改测试
package pool
import (
"errors"
"github.com/golang/mock/gomock"
"github.com/stretchr/testify/assert"
"github.com/ultramesh/mock-example/mock"
"github.com/ultramesh/mock-example/task"
"testing"
)
type TestSuit struct {
name string
newTask NewTask
size int
times int
isErr bool
}
func TestTaskPoolRunImpl_MinimalTask(t *testing.T) {
ctrl := gomock.NewController(t)
defer ctrl.Finish()
testSuits := []TestSuit{
//{
// name: "minimal task pool",
// newTask: func() task.Task { return mock.NewMinimalTask() },
// size: 100,
// times: 200,
//},
{
name: "mock minimal task pool",
newTask: func() task.Task { return mock.NewMockMinimalTask(ctrl) },
size: 100,
times: 200,
},
{
name: "return err",
newTask: func() task.Task {
mockTask := mock.NewMockTask(ctrl)
// 加入了返回错误的逻辑
mockTask.EXPECT().Do(gomock.Any()).Return("", errors.New("return err")).AnyTimes()
return mockTask
},
size: 100,
times: 200,
isErr: true,
},
}
for _, suit := range testSuits {
t.Run(suit.name, func(t *testing.T) {
var taskPool TaskPool = NewTaskPoolImpl(suit.newTask, suit.size)
err := taskPool.Run(suit.size)
if suit.isErr {
assert.Error(t, err)
} else {
assert.NoError(t, err)
}
})
}
}
这样我们就能够覆盖到error的处理逻辑
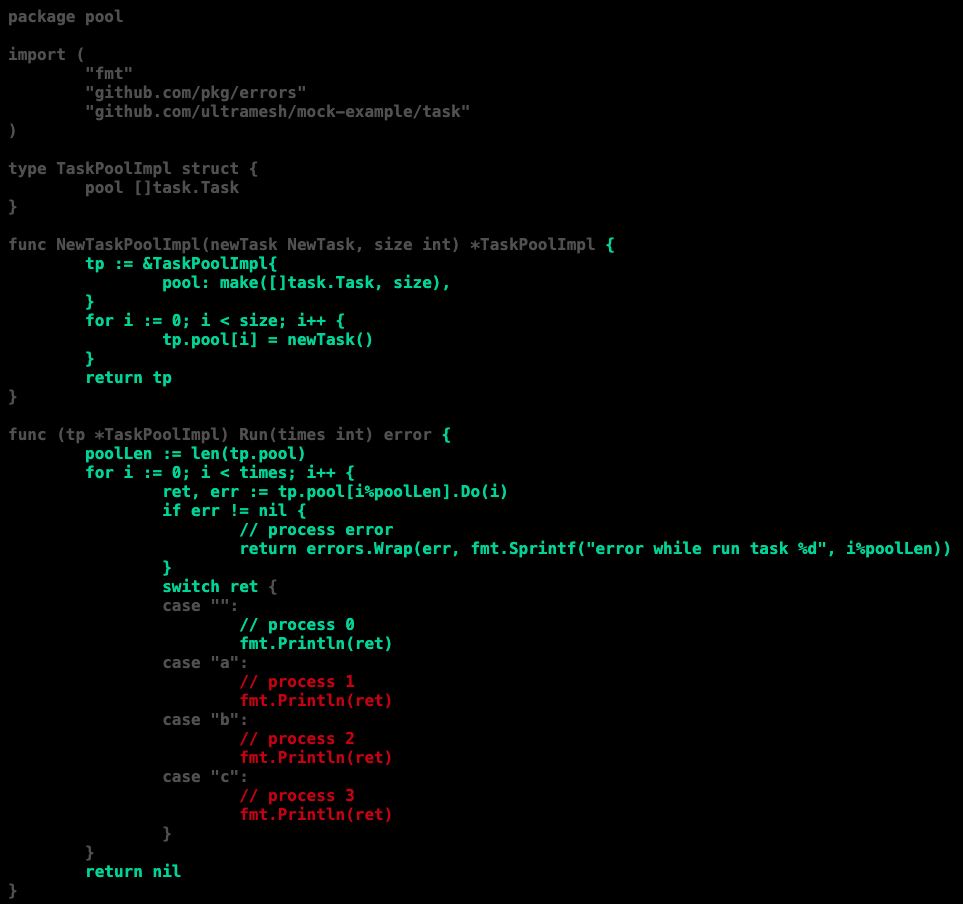
甚至我们可以更trick的方式来将所有语句都覆盖到,代码中的testSuits改成下面这样
package pool
import (
"errors"
"github.com/golang/mock/gomock"
"github.com/stretchr/testify/assert"
"github.com/ultramesh/mock-example/mock"
"github.com/ultramesh/mock-example/task"
"testing"
)
type TestSuit struct {
name string
newTask NewTask
size int
times int
isErr bool
}
func TestTaskPoolRunImpl_MinimalTask(t *testing.T) {
ctrl := gomock.NewController(t)
defer ctrl.Finish()
strs := []string{"a", "b", "c"}
count := 0
size := 3
rounds := 1
testSuits := []TestSuit{
//{
// name: "minimal task pool",
// newTask: func() task.Task { return mock.NewMinimalTask() },
// size: 100,
// times: 200,
//},
{
name: "mock minimal task pool",
newTask: func() task.Task { return mock.NewMockMinimalTask(ctrl) },
size: 100,
times: 200,
},
{
name: "return err",
newTask: func() task.Task {
mockTask := mock.NewMockTask(ctrl)
mockTask.EXPECT().Do(gomock.Any()).Return("", errors.New("return err")).AnyTimes()
return mockTask
},
size: 100,
times: 200,
isErr: true,
},
{
name: "check input and output",
newTask: func() task.Task {
mockTask := mock.NewMockTask(ctrl)
// 这里我们通过Do的设置检查了mackTask.Do调用时候的入参以及调用次数
// 通过Return来设置发生调用时的返回值
mockTask.EXPECT().Do(count).Return(strs[count%3], nil).Times(rounds)
count++
return mockTask
},
size: size,
times: size * rounds,
isErr: false,
},
}
var taskPool TaskPool
for _, suit := range testSuits {
t.Run(suit.name, func(t *testing.T) {
taskPool = NewTaskPoolImpl(suit.newTask, suit.size)
err := taskPool.Run(suit.times)
if suit.isErr {
assert.Error(t, err)
} else {
assert.NoError(t, err)
}
})
}
}
这样我们就可以覆盖到所有语句
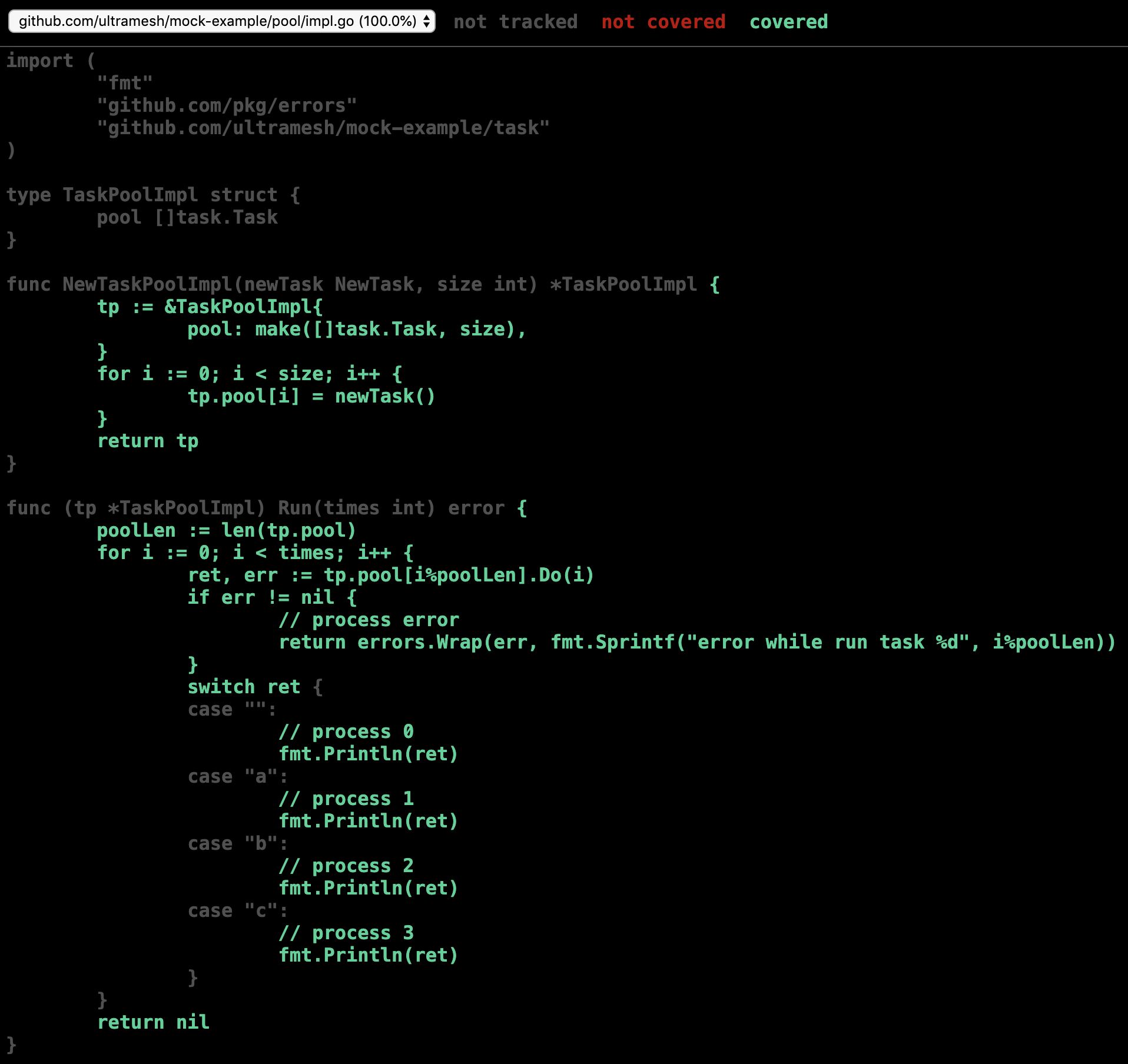
思考Mock的意义
之前和一些同学讨论过,我们为什么要使用mock这个问题,发现很多同学的觉得写mock的是约定好接口,然后在面向接口做开发的时候能够方便测试,因为不需要接口实际的实现,而是依赖mock的Minimal Implement就可以进行单元测试。我认为这是对的,但是同时也觉得mock的意义不仅仅是如此。
在我看来,面向接口开发的实践中,你应该时刻对接口的输入和输出保持敏感,更进一步的说,在进行单元测试的时候,你需要知道在给定的用例、输入下,你的包会对起使用的接口方法输入什么,调用几次,然后返回值可能是什么,什么样的返回值对你有影响,如果你对这些不了解,那么我觉得或者你应该去做更多地尝试和了解,这样才能尽可能通过mock设计出更多的单测用例,做更多且谨慎的检查,提高测试代码的覆盖率,确保模块功能的完备性。
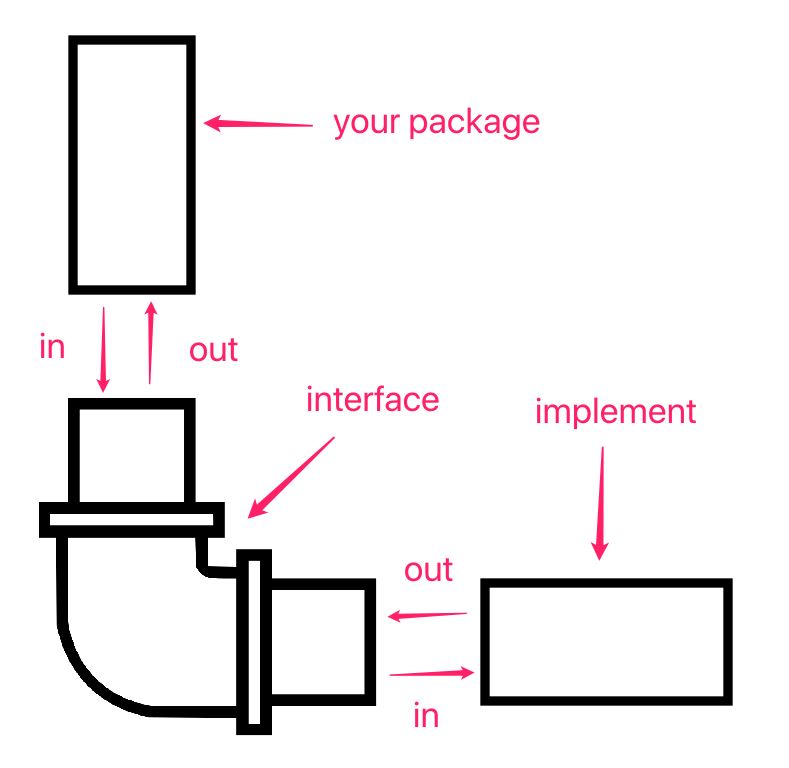
Mock与设计模式
mock与单例
客观来讲,借助go语言官方提供的同步原语sync.Once,实现单例、使用单例是很容易的事情。在使用单例实现的过程中,单例的调用者往往逻辑中依赖提供的get方法在需要的时候获取单例,而不会在自身的数据结构中保存单例的句柄,这也就导致我们很难类比前面介绍的case,使用mock进行单元测试,因为caller没有办法控制通过get方法获取的单例。
既然是因为没有办法更改单例返回,那么解决这个问题最简单的方式就是我们就应改提供一个set方法来设置更改单例。假设我们需要基于上面的case实现一个单例的TaskPool。假设我们定义了PoolImpl实现了Pool的接口,在创建单例的时候我们可能是这么做的(为了方便说明,这里我们用最早手工写的基于MinimalTask来写TaskPool的单例)
package pool
import (
"github.com/ultramesh/mock-example/mock"
"github.com/ultramesh/mock-example/task"
"sync"
)
var once sync.Once
var p TaskPool
func GetTaskPool() TaskPool{
once.Do(func(){
p = NewTaskPoolImpl(func() task.Task {return mock.NewMinimalTask()},10)
})
return p
}
这个时候问题就来了,假设某个依赖于TaskPool的模块中有这么一段逻辑
package runner
import (
"fmt"
"github.com/pkg/errors"
"github.com/ultramesh/mock-example/pool"
)
func Run(times int) error {
// do something
fmt.Println("do something")
// call pool
p := pool.GetTaskPool()
err := p.Run(times)
if err != nil {
return errors.Wrap(err, "task pool run error")
}
// do something
fmt.Println("do something")
return nil
}
那么这个Run函数的单测应该怎么写呢?这里的例子还比较简单,要是TaskPool的实现还要依赖一些外部配置文件,实际情形就会更加复杂,当然我们在这里不讨论这个情况,就是举一个简单的例子。在这种情况下,如果单例仅仅只提供了get方法的话是很难进行解耦测试的,如果使用GetTaskPool势必会给测试引入不必要的复杂性,我们还需要提供一个单例的实现者提供一个set方法来解决单元测试解耦的问题。将单例的实现改成下面这样,对外暴露一个单例的set方法,那么我们就可以通过set方法来进行mock。
import (
"github.com/ultramesh/mock-example/mock"
"github.com/ultramesh/mock-example/task"
"sync"
)
var once sync.Once
var p TaskPool
func SetTaskPool(tp TaskPool) {
p = tp
}
func GetTaskPool() TaskPool {
once.Do(func(){
if p != nil {
p = NewTaskPoolImpl(func() task.Task {return mock.NewMinimalTask()},10)
}
})
return p
}
使用mockgen生成一个MockTaskPool实现
mockgen -destination mock/mock_task_pool.go -package mock -source pool/interface.go
类似的,基于前面介绍的思想我们基于自动生成的代码实现一个MockMinimalTaskPool
package mock
import "github.com/golang/mock/gomock"
func NewMockMinimalTaskPool(ctrl *gomock.Controller) *MockTaskPool {
mock := NewMockTaskPool(ctrl)
mock.EXPECT().Run(gomock.Any()).Return(nil).AnyTimes()
return mock
}
基于MockMinimalTaskPool和单例暴露出的set方法,我们就可以将TaskPool实现的逻辑拆除,在单测中只测试自己的代码
package runner
import (
"github.com/golang/mock/gomock"
"github.com/stretchr/testify/assert"
"github.com/ultramesh/mock-example/mock"
"github.com/ultramesh/mock-example/pool"
"testing"
)
func TestRun(t *testing.T) {
ctrl := gomock.NewController(t)
defer ctrl.Finish()
p := mock.NewMockMinimalTaskPool(ctrl)
pool.SetTaskPool(p)
err := Run(100)
assert.NoError(t, err)
}
到此这篇关于Go语言Mock使用基本指南详解的文章就介绍到这了,更多相关Go语言Mock使用内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

使用Gomock进行单元测试的方法示例
在开发过程中往往需要配合单元测试,但是很多时候,单元测试需要依赖一些比较复杂的准备工作,比如需要依赖数据库环境,需要依赖网络环境,单元测试就变成了一件非常麻烦的事情.举例来说,比如我们需要请求一个网页,并将请求回来的数据进行处理.在刚开始的时候,我通常都会先启动一个简单的http服务,然后再运行我的单元测试.可是这个单元测试测起来似乎非常笨重.甚至在持续集成过程中,我还为了能够自动化测试,特意写了一个脚本自动启动相应的服务.事情似乎需要进行一些改变. mock对象就是为了解决上面的问题而诞生的,
-
用gomock进行mock测试的方法示例
在开发过程中往往需要配合单元测试,但是很多时候,单元测试需要依赖一些比较复杂的准备工作,比如需要依赖数据库环境,需要依赖网络环境,单元测试就变成了一件非常麻烦的事情.举例来说,比如我们需要请求一个网页,并将请求回来的数据进行处理.在刚开始的时候,我通常都会先启动一个简单的http服务,然后再运行我的单元测试.可是这个单元测试测起来似乎非常笨重.甚至在持续集成过程中,我还为了能够自动化测试,特意写了一个脚本自动启动相应的服务.事情似乎需要进行一些改变. mock对象就是为了解决上面的问题而诞生的,
-
Go语言Mock使用基本指南详解
当前的实践中问题 在项目之间依赖的时候我们往往可以通过mock一个接口的实现,以一种比较简洁.独立的方式,来进行测试.但是在mock使用的过程中,因为大家的风格不统一,而且很多使用minimal implement的方式来进行mock,这就导致了通过mock出的实现各个函数的返回值往往是静态的,就无法让caller根据返回值进行的一些复杂逻辑. 首先来举一个例子 package task type Task interface { Do(int) (string, error) } 通过mini
-
C语言 指针与数组的详解及区别
C语言 指针与数组的详解及对比 通俗理解数组指针和指针数组 数组指针: eg:int( *arr)[10]; 数组指针通俗理解就是这个数组作为指针,指向某一个变量. 指针数组: eg:int*arr[10]; 指针数组简言之就是存放指针的数组: --数组并非指针&&指针并非数组 (1)定义一个外部变量: eg:int value=10; int *p=&value; 举例:当需要在一个函数中用这个变量时:externa int*p;而非extern int p[]; 分析:当用:e
-
C语言动态内存分配的详解
C语言动态内存分配的详解 1.为什么使用动态内存分配 数组在使用的时候可能造成内存浪费,使用动态内存分配可以解决这个问题. 2. malloc和free C函数库提供了两个函数,malloc和free,分别用于执行动态内存分配和释放. (1)void *malloc(size_t size); malloc的参数就是需要分配的内存字节数.malloc分配一块连续的内存.如果操作系统无法向malloc提供更多的内存,malloc就返回一个NULL指针. (2)void free(void *poi
-
C语言memset函数使用方法详解
C语言memset函数使用方法详解 一.函数原形 void * memset(void*s, int ch,size_t n) 二.函数作用 将以s内存地址为首的连续n个字节的内容置成ch,一般用来对大量结构体和数组进行清零 三.常见错误 1.搞反了 ch 和 n的位置 对char[20]清零,一定是 memset(a,0,20); 2.过度使用memset 3.其实这个错误严格来讲不能算用错memset,但是它经常在使用memset的场合出现 int fun(strucy someth
-
C/C++语言宏定义使用实例详解
C/C++语言宏定义使用实例详解 1. #ifndef 防止头文件重定义 在一个大的软件工程里面,可能会有多个文件同时包含一个头文件,当这些文件编译链接成 一个可执行文件时,就会出现大量"重定义"的错误.在头文件中实用#ifndef #define #endif能避免头文件的重定义. 方法:例如要编写头文件test.h 在头文件开头写上两行: #ifndef TEST_H #define TEST_H //一般是文件名的大写 头文件结尾写上一行: #endif 这样一个工程文件里同时
-
Java语言实现数据结构栈代码详解
近来复习数据结构,自己动手实现了栈.栈是一种限制插入和删除只能在一个位置上的表.最基本的操作是进栈和出栈,因此,又被叫作"先进后出"表. 首先了解下栈的概念: 栈是限定仅在表头进行插入和删除操作的线性表.有时又叫LIFO(后进先出表).要搞清楚这个概念,首先要明白"栈"原来的意思,如此才能把握本质. "栈"者,存储货物或供旅客住宿的地方,可引申为仓库.中转站,所以引入到计算机领域里,就是指数据暂时存储的地方,所以才有进栈.出栈的说法. 实现方式是
-
易语言的输入字类型详解
在程序中书写输入字时,可以使用一个半角符号来引导该输入字,以指定其类型.各输入字的类型引导符号为: 首拼及全拼输入字: 分号(";") 如: ;qz(1.23) 或 ;quzheng(1.23) 双拼输入字: 冒号(":") 如: :quvg(1.23) 英文输入字: 单引号(" '") 如: 'int(1.23) 系统具有一个当前默认输入法状态,如果某输入字前没有加上类型引导符号,则默认是属于该输入法的输入字.系统安装完毕后,当前默认输入法为&
-
易语言操作数据库“取错误信息”命令详解
如果执行某数据库命令失败,在其后执行本命令可以取回错误信息文本.如果该数据库命令执行成功,执行本命令将返回空文本. 语法: 文本型 取错误信息 () 例程: 说明: 首先把要操作的数据库打开,然后执行"写()"命令,程序将改写"改写字段编辑框"中输入的字段名,改写内容为"改写内容编辑框"的内容.如果改写成功,会弹出信息框显示"写入数据成功":如果改写失败,会弹出信息框提示失败,将本次操作的错误码和错误信息取出,并显示在信息框中
-
易语言“是否支持多用户”命令详解
检查本支持库所提供的数据库功能是否支持多用户同时对数据库操作.如果支持,返回真,否则返回假. 语法: 逻辑型 是否支持多用户 () 例程: 说明: 是否支持多用户命令,是检查当前的数据库,是否支持多用户同时进行操作,在检查数据库前,要先把待检查的数据库打开,如果本数据库支持多用户则返回真,否则,返回假. 用存放返回值的变量存放是否支持多用户命令的返回值,最后,用信息框查看本命令的返回值.如果此数据库支持多用户,信息框会显示"真",否则,显示"假". 到此这篇关于易语
-
易语言操作数据库“替换打开”命令详解
打开指定的数据库文件.成功返回真,并自动关闭当前数据库后将当前数据库设置为此数据库,失败返回假. 语法: 逻辑型 替换打开 (数据库文件名,[在程序中使用的别名],[是否只读],[共享方式],[保留参数1],[数据库密码],[索引文件表],- ) 参数名 描 述 数据库文件名 必需的:文本型. 在程序中使用的别名 可选的:文本型.别名为在后面的程序中引用本数据库时可使用的另一个名称.欲引用一个已经被打开的数据库可以使用该数据库本身的名称(数据库名称为数据库文件名的无路径和后缀部分.譬如 c:\m